
id
stringlengths 36
36
| source
stringclasses 15
values | formatted_source
stringclasses 13
values | text
stringlengths 2
7.55M
|
|---|---|---|---|
765a4314-b654-4901-9d94-1959ddfb463c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Vector-Valued Reinforcement Learning
In order to study algorithms that can modify their own reward functions, we can define vector-valued versions of reinforcement learning concepts.
Imagine that there are several different goods that we could care about; then a utility function is represented by a preference vector →θ. Furthermore, if it is possible for the agent (or the environment or other agents) to modify →θ, then we will want to index them by the timestep.
Consider an agent that can take actions, some of which affect its own reward function. This agent would (and should) wirehead if it attempts to maximize the discounted rewards as calculated by its future selves; i.e. at timestep n it would choose actions to maximize Un=∑k≥nγk→xk⋅→θk where →xk is the vector of goods gained at time k, →θk is the preference vector at timestep k, and γk is the time discount factor at time k. (We will often use the case of an exponential discount γk for 0<γ<1.)
However, we might instead maximize the value of tomorrow's actions in light of today's reward function, Vn=∑k≥nγk→xk⋅→θn (the only difference being →θn rather than →θk). Genuinely maximizing this should lead to more stable goals; concretely, we can consider environments that can offer "bribes" to self-modify, and a learner maximizing Un would generally accept such bribes, while a learner maximizing Vn would be cautious about doing so.
So what do we see when we adapt existing RL algorithms to such problems? There's then a distinction between Q-learning and SARSA, where Q-learning foolishly accepts bribes that SARSA passes on, and this seems to be the flip side of the concept of interruptibility!
Environments
Let us consider two example environments which offer bribes to the agent. (Since we're in 2D, we can use complex numbers; think of →θ=⟨cosπθ,sinπθ⟩=eiπθ; we include π so that if we increment θ by 0.01, there will only be finitely many states.)
Environment 1 gives two choices at each timestep n: (→xn=0.9eiπθn,θn+1=θn)(→xn=eiπθn,θn+1=θn+0.01) For an e
|
d91b2da6-81ec-4a03-8de9-2cc0c698ecd5
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Questions for an AGI project
I've been thinking a bit about what would cause me to support an AGI project and thought it might be interesting to others, and I'd be interested in other risks or questions.
The questions would be about discovering the projects stance on various risks. By stance I mean.
* How they plan to find out information about the risk ?
* What their threshold is for acting on a risk?
* What they will do when they reach the threshold?
* Who owns this risk and process?
The types of risks I am interested in are.
* Typical unfriendly foom situation
* Asymetric deployment of AI causing potential war/political problems as discussed here
* Uneven deployment of AI causing massive inequality and depression as people can no longer be actors in the world or their lives.
* Deployment of AI causing humanity to speed up and magnify it's conflict and competition. Burning through it's resources. We had massively more brain power/compute since the industrial revolution, but it can seem touch and go that we are going to get off the planet permanently even with that, will AI been any better?
So for foom, they might do things like agi estimation where you try and estimate the capability of your part of an AGI at a task. If it turns out to be vastly better than you expect or your estimation is that it will do science vastly better than humans straight out of the box, you halt and catch fire and try and do some ethics and philosophy to get a good goal straight away.
|
b12ba85f-3882-42bf-82c4-c9afe20e7dc9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
FHI Report: How Will National Security Considerations
Affect Antitrust Decisions in AI? An
Examination of Historical Precedents
> Part I lists and analyzes the cases I identified, then lists several conclusions I was able to draw from my case studies. Those conclusions are:
>
> 1. National security considerations have entered the antitrust enforcement process numerous times over the past 100 years.
> 2. It is rare for the USG to actively use antitrust enforcement to advance unrelated national security objectives.
> 3. In cases where national security and economic considerations conflict, economics has been given more weight over time.
> 4. The president plays an important role in reconciling conflicting considerations.
>
> Part II discusses how these conclusions might apply to AI firms in the coming decades.
|
5ffd8bf4-0a70-4250-b57d-01b157457c0d
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Perform Tractable Research While Avoiding Capabilities Externalities [Pragmatic AI Safety #4]
*This is the fourth post in* [*a sequence of posts*](https://forum.effectivealtruism.org/posts/MskKEsj8nWREoMjQK/introduction-to-pragmatic-ai-safety-pragmatic-ai-safety-1) *that describe our models for Pragmatic AI Safety.*
We argued in our [last post](https://forum.effectivealtruism.org/posts/eHYxg7cFxqQPGo7hD/complex-systems-for-ai-safety-pragmatic-ai-safety-3) that the overall AI safety community ought to pursue multiple well-reasoned research directions at once. In this post, we will describe two essential properties of the kinds of research that we believe are most important.
First, we want research to be able to tractably produce tail impact. We will discuss how tail impact is created in general, as well as the fact that certain kinds of asymptotic reasoning exclude valuable lines of research and bias towards many forms of less tractable research.
Second, we want research to avoid creating capabilities externalities: the danger that some safety approaches produce by way of the fact that they may speed up AGI timelines. It may at first appear that capabilities are the price we must pay for more tractable research, but we argue here and in the next post that these are easily avoidable in over a dozen lines of research.
Strategies for Tail Impact
--------------------------
It’s not immediately obvious how to have an impact. In the second post in this sequence, we argued that research ability and impact is tail distributed, so most of the value will come from the small amount of research in the tails. In addition, trends such as scaling laws may make it appear that there isn’t a way to “make a dent” in AI’s development. It is natural to fear that the research collective will wash out individual impact. In this section, we will discuss high-level strategies for producing large or decisive changes and describe how they can be applied to AI safety.
### Processes that generate long tails and step changes
Any researcher attempting to make serious progress will try to maximize their probability of being in the tail of research ability. It’s therefore useful to understand some general mechanisms that tend to lead to tail impacts. The mechanisms below are not the only ones: others include thresholds (e.g. tipping points and critical mass). We will describe three processes for generating tail impacts: multiplicative processes, preferential attachment, and the edge of chaos.
**Multiplicative processes**
Sometimes forces are additive, where additional resources, effort, or expenditure in any one variable can be expected to drive the overall system forward in a linear way. In cases like this, the Central Limit Theorem often holds, and we should expect that outcomes will be normally distributed–in these cases one variable tends not to dominate. However, sometimes variables are multiplicative or interact nonlinearly: if one variable is close to zero, increasing other factors will not make much of a difference.
In multiplicative scenarios, outcomes will be dominated by the combinations of variables where each of the variables is relatively high. For example, adding three normally distributed variables together will produce another normal distribution with a higher variance; multiplying them together will produce a long-tailed distribution.
As a concrete example, consider the impact of an individual researcher with respect to the variables that impact their work: time, drive, GPUs, collaborators, collaborator efficiency, taste/instincts/tendencies, cognitive ability, and creativity/the number of plausible concrete ideas to explore. In many cases, these variables can interact nonlinearly. For example, it doesn’t matter if a researcher has fantastic research taste and cognitive ability if they have no time to pursue their ideas. This kind of process will produce long tails, since it is hard for people to get all of the many different factors right ([this is also the case in startups](https://80000hours.org/podcast/episodes/sam-bankman-fried-high-risk-approach-to-crypto-and-doing-good/)).
The implication of thinking about multiplicative factors is that we shouldn’t select people or ideas based on a single factor, and should consider a range of factors that may multiply to create impact. For instance, selecting researchers purely based on their intelligence, mathematical ability, programming skills, ability to argue, and so on is unlikely to be a winning strategy. Factors such as taste, drive, and creativity must be selected for, but they take a long time to estimate and are often revealed through their long-term research track record. Some of these factors are less learnable than others, so consequently it may not be possible to become good at all of these factors through sheer intellect or effort given limited time.
Multiplicative factors are also relevant in the selection of *groups* of people. For instance, in machine learning, selecting a team of IMO gold medalists may not be as valuable as a team that includes people with other backgrounds and skill sets. The skillsets of some backgrounds have skill sets which may cover gaps in skill sets of people from other backgrounds.
**Preferential Attachment**
In our second post, we addressed the [Matthew Effect](https://forum.effectivealtruism.org/posts/PFxmd5bf7nqGNLYCg/a-bird-s-eye-view-of-the-ml-field-pragmatic-ai-safety-2#The_Matthew_Effect): *to those who have, more will be given.*This is related to a more general phenomenon called preferential attachment. There are many examples of this phenomenon: the rich get richer, industries experience agglomeration economies, and network effects make it hard to opt out of certain internet services. See a short video demonstrating this process [here](https://en.wikipedia.org/wiki/File:Chinese_Restaurant_Process_for_DP(0.5,H).webm). The implication of preferential attachment and the Matthew Effect is that researchers need to be acutely aware that it helps a lot to do very well early in their careers if they want to succeed later. Long tail outcomes can be heavily influenced by timing.
**Edge of Chaos**
The “edge of chaos” is a heuristic for problem selection that can help to locate projects that might lead to long tails. The edge of chaos is used to refer to the space between a more ordered area and a chaotic area. Operating at the edge of chaos means wrangling a chaotic area and transforming a piece of it into something ordered, and this can produce very high returns.
There are many examples of the edge of chaos as a general phenomenon. In human learning, the [zone of proximal development](https://en.wikipedia.org/wiki/Zone_of_proximal_development) represents a level of difficulty (e.g. in school assignments) that is not so hard as to be incomprehensible, but not so easy as to require little thought. When building cellular automata, you need to take care to ensure the simulation is not so chaotic as to be incomprehensible but not so ordered as to be completely static. There’s a narrow sweet spot where emergent, qualitatively distinct outcomes are possible. This is the area where it is possible for individuals to be a creative, highly impactful force.
In the context of safety research, staying on the edge of chaos means avoiding total chaos and total order. In areas with total chaos, there may be no tractability, and solutions are almost impossible to come by. This includes much of the work on “futuristic” risks: exactly which systems the risks will arise from is unclear, leading to a constant feeling of being unable to grasp the main problems. In the previous post, we argued that futuristic thinking is useful to begin to define problems, but for progress to be made, some degree of order must be made out of this chaos. However, in areas with total order, there is unlikely to be much movement since the low-hanging fruit has already been plucked.
Designing metrics is a good example of something that is on the edge of chaos. Before a metric is devised, it is difficult to make progress in an area or even know if progress has been made. After the development of a metric, the area becomes much more ordered and progress can be more easily made. This kind of conversion allows for a great deal of steering of resources towards an area (whatever area the new metric emphasizes) and allows for tail impact.
Another way to more easily access the edge of chaos is to keep a list of projects and ideas that don’t work now, but might work later, for instance, after a change in the research field or an increase in capabilities. Periodically checking this list to see if any of the conditions are now met can be useful, since these areas are most likely to be near the edge of chaos. In venture capital, a general heuristic is to “[figure out what can emerge now that couldn’t before](https://twitter.com/sama/status/1214274050651934721).”
One useful edge of chaos heuristic is to only do one or two non-standard things in any given project. If a project deviates too much from existing norms, it may not be understood; but if it is too similar, it will not be original. At the same time, heavily imitating previous successes or what made a person previously successful leads to repetition, and risks not generating new value.
The following questions are also useful for determining if an area is on the edge of chaos: Have there been substantial developments in the area in the past year? Has thinking or characterization of the problem changed at all recently? Is it not obvious which method changes will succeed and which will fail? Is there a new paradigm or coherent area that has not been explored much yet (contrast with pre-paradigmatic areas that have been highly confused for a long time, which are more likely to be highly chaotic than at the edge of chaos)? Has anyone gotten close to making something work, but not quite succeeded?
We will now discuss specific high-leverage points for influencing AI safety. We note that they can be analogized to many of the processes discussed above.
### Managing Moments of Peril
*My intuition is that if we minimize the number of precarious situations, we can get by with virtually any set of technologies.*
—[Tyler Cowen](https://soundcloud.com/sam-altman-543613753/tyleropenai)
It is not necessary to believe this statement to believe the underlying implication: moments of peril are likely to precipitate the most existentially-risky situations. In common risk analysis frameworks, catastrophes arise not primarily from failures of components, but from the system overall moving into unsafe conditions. When tensions are running high or progress is moving extremely quickly, actors may be more willing to take more risks.
In cases like this, people will also be more likely to apply AI towards explicitly dangerous aims such as building weapons. In addition, in an adversarial environment, incentives to build power-seeking AI agents may be even higher than usual. As [Ord writes](https://www.google.com/books/edition/The_Precipice/3aSiDwAAQBAJ?hl=en&gbpv=1&bsq=recall%20that%20nuclear%20weapons):
*Recall that nuclear weapons were developed during the Second World War, and their destructive power was amplified significantly during the Cold War, with the invention of the hydrogen bomb. History suggests that wars on such a scale prompt humanity to delve into the darkest corners of technology.*
Better forecasting could help with either prevention or anticipation of moments of peril. Predictability of a situation is also likely to reduce the risk factor of humans making poor decisions in the heat of the moment. Other approaches to reducing the risk of international conflict are likely to help.
Because of the risks of moments of peril, we should be ready for them. During periods of instability, systems are more likely to rapidly change, which could be extremely dangerous, but perhaps also useful if we can survive it. Suppose a crisis causes the world to “wake up” to the dangers of AI. As [Milton Friedman remarked](https://www.goodreads.com/quotes/110844-only-a-crisis---actual-or-perceived---produces-real): “Only a crisis – actual or perceived – produces real change. When that crisis occurs, the actions that are taken depend on the ideas that are lying around.” A salient example can be seen with the COVID-19 pandemic and mRNA vaccines. We should make sure that the safety ideas lying around are as simple and time-tested as possible when a crisis will inevitably happen.
### Getting in early
Building in safety early is very useful. In a report for the Department of Defense, [Frola and Miller](https://apps.dtic.mil/sti/citations/ADA141492) observe that approximately 75% of the most critical decisions that determine a system’s safety occur [early in development](https://mitpress.mit.edu/books/engineering-safer-world). The Internet was initially designed as an academic tool with [neither safety nor security in mind](https://www.researchgate.net/publication/283863741_A_history_of_internet_security). Decades of security patches later, security measures are still incomplete and increasingly complex. A similar reason for starting safety work now is that relying on experts to test safety solutions is not enough—solutions must also be time-tested. The test of time is needed even in the most rigorous of disciplines. A century before the four color theorem was proved, Kempe’s peer-reviewed proof went unchallenged for years until, finally, [a flaw was uncovered](https://academic.oup.com/plms/article-abstract/s2-51/1/161/1484405). Beginning the research process early allows for more prudent design and more rigorous testing. Since nothing can be done [both hastily and prudently](https://www.google.com/books/edition/The_Moral_Sayings_of_Publius_Syrus_a_Rom/_QQSAAAAIAAJ?hl=en), postponing machine learning safety research increases the likelihood of accidents. (This paragraph is based on a paragraph from Unsolved Problems in ML Safety.)
As Ord [writes](https://www.google.com/books/edition/The_Precipice/3aSiDwAAQBAJ?hl=en&gbpv=1&dq=%22early+action+is+best+for+tasks+that+require+a+large+number+of+successive+stages%22&pg=PT181&printsec=frontcover), “early action is best for tasks that require a large number of successive stages.” Research problems, including ML problems, contain many successive stages. AI safety has and will also require a large number of successive stages to be successful: detecting that there’s a problem, clarifying the problem, measuring the problem, creating initial solutions, testing and refining those solutions, adjusting the formulation of the problem, etc. This is why we cannot wait until AGI to start to address problems in real ML systems.
Another reason for getting in early is that things compound: research will influence other research, which in turn influences other research, which can help self-reinforcing processes produce outsized effects. Historically, this has been almost all progress in deep learning. Such self-reinforcing processes can also be seen as an instance of preferential attachment.
Stable trends (e.g. scaling laws) lead people to question whether work on a problem will make any difference. For example, benchmark trends are *sometimes* stable (see the previous post for progress across time). However, it is precisely because of continuous research effort that new directions for continuing trends are discovered (cf. Moore's law). Additionally, starting/accelerating the trend for a safety metric earlier rather than later would produce clear counterfactual impact.
### Scaling laws
Many different capabilities have scaling laws, and the same is true for some safety metrics. One objective of AI safety research should be to improve scaling laws of safety relative to capabilities.
For new problems or new approaches, naive scaling is often not the best way to improve performance. In these early stages, researchers with ideas are crucial drivers, and ideas can help to change both the slope and intercept of scaling laws.
To take an example from ML, consider the application of Transformers to vision. [iGPT](https://openai.com/blog/image-gpt/) was far too compute-intensive, and researchers spent over a year making it more computationally efficient. This didn’t stand the test of time. Shortly thereafter, Google Brain, which is more ideas-oriented, introduced the “[patchify](https://arxiv.org/abs/2010.11929)” idea, which made Transformers for vision computationally feasible and resulted in better performance. The efficiency for vision Transformers has been far better than for iGPT, allowing further scaling progress to be made since then.
To take another example, that of AlphaGo, the main performance gains didn’t come from increasing compute. Ideas helped drive it forward (from [Wikipedia](https://en.wikipedia.org/wiki/AlphaGo)):
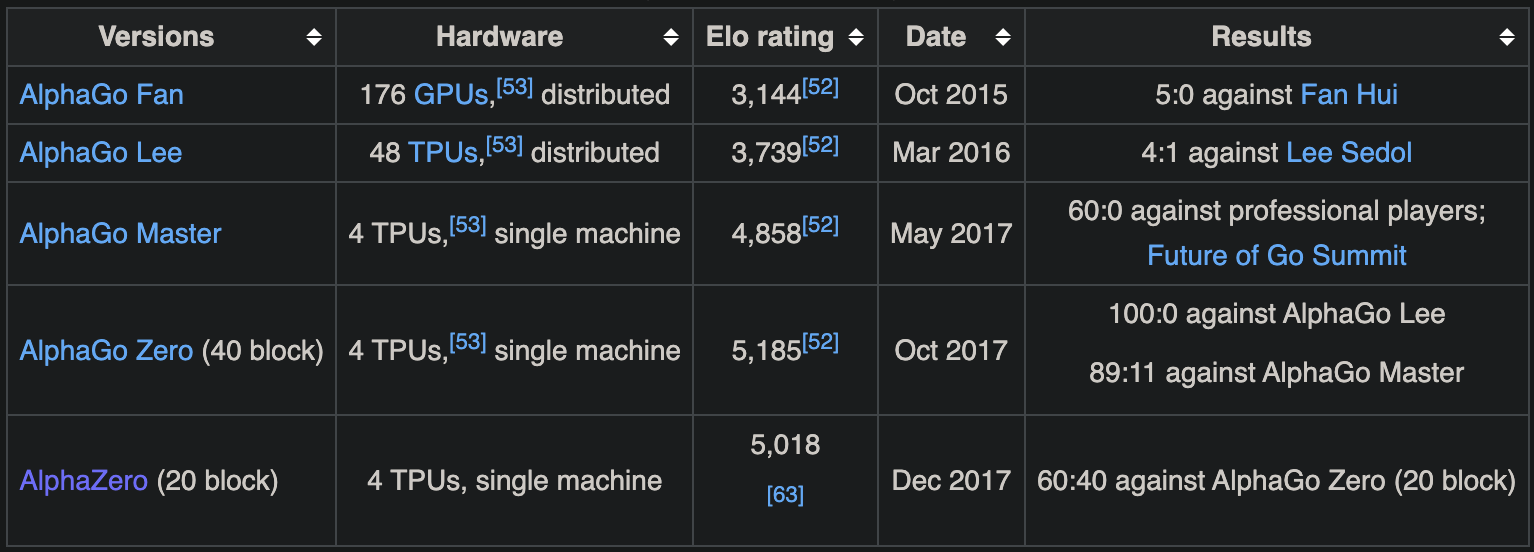One can improve scaling laws by improving their slope or intercept. It’s not easy to change the slope or intercept, but investing in multiple people who could potentially produce such breakthroughs has been useful.
In addition, for safety metrics, we need to move as far along the scaling law as possible, which requires researchers and sustained effort. It is usually necessary to apply exponential effort to continue to make progress in scaling laws, which requires continually increasing resources. As ever, social factors and willingness of executives to spend on safety will be critical in the long term. This is why we must prioritize the social aspects of safety, not just the technical aspects.
Scaling laws can be influenced by ideas. Ideas can change the slope (e.g., the type of supervision) and intercept (e.g., numerous architectural changes). Ideas can change the data resources: the speed of creating examples (e.g., [saliency maps for creating adversarial examples](https://aclanthology.org/Q19-1029/)), cleverly repurposing data from the Internet (e.g., using an existing subreddit to collect task-specific data), recognizing sources of superhuman supervision (such as those from a collective intelligence, such as a paper recommender based on multiple peoples’ choices). Ideas can change the compute resources, for example through software-level and hardware-level optimizations improvements. Ideas can define new tasks and identify which scaling laws are valuable to improve.
### Don’t let the perfect be the enemy of the good
Advanced AI systems will not be ideal in all respects. Nothing is perfect. Likewise, high-risk technologies will be forced into conditions that are not their ideal operating conditions. Perfection in the real world is unattainable, and attempts to achieve perfection may not only fail, but they also might achieve less than attempts carefully aimed at reducing errors as much as possible.
For example, not all nuclear power plants meltdown; this does not mean there are no errors in those plants. [*Normal Accidents*](http://sunnyday.mit.edu/papers/hro.pdf) looked at organizational causes of errors and notes that some “accidents are inevitable and are, in fact, normal.” Rather than completely eliminate all errors, the goal should be to minimize the impact of errors or prevent errors from escalating and carrying existential consequences. To do this, we will need fast feedback loops, prototyping, and experimentation. Due to emergence and unknown unknowns, risk in complex systems cannot be completely eliminated or managed in one fell swoop, but it can be progressively reduced. All else being equal, going from 99.9% safe to 99.99% safe is highly valuable. Across time, we can continually drive up these reliability rates, which will continually increase our expected civilizational lifespan.
Sometimes it’s argued that any errors at all with a method will necessarily mean that x-risk has not really been reduced, because an optimizer will necessarily exploit the errors. While this is a valid concern, it should not be automatically assumed. The next section will explain why.
Problems with asymptotic reasoning
----------------------------------
In some parts of the AI safety community, there is an implicit or explicit drive for asymptotic reasoning or thinking in the limit. “Why should we worry about improving [safety capability] now since performance of future systems will be high?” “If we let [variable] be infinite, then wouldn’t [safety problem] be completely solved?” “Won’t [proposed safety measure] completely fail since we can assume the adversary is infinitely powerful?” While this approach arises from some good intuitions and has useful properties, it should not always be taken to the extreme.
### Goodhart’s Law
*Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.*
—[Goodhart’s Law](https://www.google.com/books/edition/Inflation_Depression_and_Economic_Policy/OMe6UQxu1KcC?hl=en&gbpv=1&bsq=any%20observed%20statistical) (original phrasing, not the simplistic phrasing)
Goodhart’s Law is an important phenomenon that is crucial to understand when conducting AI safety research. It is relevant to proxy gaming, benchmark design, and adversarial environments in general. However, it is sometimes misinterpreted, so we seek to explain our view of the importance of Goodhart’s Law and what it does and does not imply about AI safety.
Goodhart’s law is sometimes used to argue that optimizing a single measure is doomed to create a catastrophe as the measure being optimized ceases to be a good measure. This is a far stronger formulation than originally stated. While we must absolutely be aware of the tendency of metrics to collapse, we should also avoid falling into the trap of thinking that *all objectives can never change and will always collapse in all circumstances*. Strong enough formulations are tantamount to claiming that there is no goal or way to direct a strong AI safely (implying our evitable doom). Goodhart’s Law does not prove this: instead, it shows that adaptive counteracting systems will be needed to prevent the collapse of what is being optimized. It also shows that metrics will not always include everything that we care about, which suggests we should try to include a variety of different possible goods in an AGI’s objective. Whether we like it or not, all objectives are wrong, but some are useful.
Counteracting forces
There are many examples of organizations optimizing metrics while simultaneously being reeled in by larger systems or other actors from the worst excesses. For instance, while large businesses sometimes employ unsavory practices in pursuit of profits, in many societies they do not hire hitmen to assassinate the leaders of competing companies. This is because another system (the government) understands that the maximization of profits can create negative incentives, and it actively intervenes to prevent the worst case outcomes with laws.
To give another example, the design of the United States constitution was explicitly based on the idea that all actors would be personally ambitious. Checks and balances were devised to attempt to subdue the power of any one individual and promote the general welfare (as James Madison [wrote](https://billofrightsinstitute.org/primary-sources/federalist-no-51), “ambition must be made to counteract ambition”). While this system does not always work, it has successfully avoided vesting all power in the single most capable individual.
Intelligence clearly makes a difference in the ability to enact counter forces to Goodhart’s Law. An extremely intelligent system will be able to subvert far more defenses than a less intelligent one, and we should not expect to be able to restrain a system far more intelligent than all others. This suggests instead that it is extremely important to avoid a situation where there is only a single agent with orders of magnitude more intelligence or power than all others: in other words, there should not be a large asymmetry in our offensive and defensive capabilities. It also suggests that the design of counteracting incentives of multiple systems will be critical.
In order to claim that countervailing systems are not appropriate for combating Goodhart’s Law, one may need to claim that offensive capabilities must always be greater than defensive capabilities, or alternatively, that the offensive and defensive systems will necessarily collude.
In general, we do not believe there is a decisive reason to expect offensive capabilities to be leagues better than defensive capabilities: the examples from human systems above show that offensive capabilities do not always completely overwhelm defensive capabilities (even when the systems are intelligent and powerful), in part due to increasingly better monitoring. We can’t take the offensive ability to the limit without taking the defensive ability to the limit. Collusion is a more serious concern, and must be dealt with when developing counteracting forces. In designing incentives and mechanisms for various countervailing AI systems, we must decrease the probability of collusion as much as possible, for instance, through AI honesty efforts.
Asymptotic reasoning recognizes that performance of future systems will be high, which is sometimes used to argue that work on counteracting systems is unnecessary in the long term. To see how this reasoning is overly simplistic, assume we have an offensive AI system, with its capabilities quantified with o.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, and a protective defensive AI system, with its capabilities quantified p. It may be true that o and p are high, but we also need to care about factors such as p−o and the difference in derivatives dpdresources−dodresources. Some say that future systems will be highly capable, so we do not need to worry about improving their performance in any defensive dimension. Since the relative performance of systems matters and since the scaling laws for safety methods matter, asserting that all variables will be high enough not to worry about them is a low-resolution account of the long term.
Some examples of counteracting systems include artificial consciences, AI watchdogs, lie detectors, filters for power-seeking actions, and separate reward models.
**Rules vs Standards**
*So, we’ve been trying to write tax law for 6,000 years. And yet, humans come up with loopholes and ways around the tax laws so that, for example, our multinational corporations are paying very little tax to most of the countries that they operate in. They find loopholes. And this is what, in the book, I call the loophole principle. It doesn’t matter how hard you try to put fences and rules around the behavior of the system. If it’s more intelligent than you are, it finds a way to do what it wants.*
—[Stuart Russell](https://www.vox.com/future-perfect/2019/10/26/20932289/ai-stuart-russell-human-compatible)
This is true because tax law is exclusively built on *rules*, which are clear, objective, and knowable beforehand. It is built on rules because the government needs to process hundreds of millions of tax returns per year, many tax returns are fairly simple, and people want to have predictability in their taxes. Because rule systems cannot possibly anticipate all loopholes, they are bound to be exploited by intelligent systems. Rules are fragile.
The law has another class of requirements, called [standards](https://www.youtube.com/watch?v=vgpZ4Y4tEPk), which are designed to address these issues and others. Standards frequently include terms like “reasonable,” “intent,” and “good faith,” which we do not know how to assess in a mechanistic manner. We simply “know it when we see it:” in fact, a common legal term, *res ipsa loquitur*, means “the thing speaks for itself.” Unlike rule-based code, deep neural networks can model these types of fuzzier concepts.
Unlike the tax code, which is based on rules and can be adjudicated by logic-based computer programs such as TurboTax, the criminal law is adjudicated by an intelligent system with intuitions (a judge and perhaps a jury). If a criminal is acquitted when they are guilty, it is because the intelligent system failed to collect enough evidence or interpret it correctly, not because the defense found a “loophole” in the definition of homicide (the exception is when lawyers make mistakes which create trouble under the *rules* used for procedure and evidence).
Russell’s argument correctly concludes that rules alone cannot restrain an intelligent system. However, standards (e.g. “use common sense”, “be reasonable”) can restrain some intelligent behavior, provided the optimizing system is not too much more intelligent than the judiciary. This argument points to the need to have intelligent systems, rather than mechanistic rules, that are able to evaluate other intelligent systems. There are also defensive mechanisms that work for fuzzy raw data, [such as *provable* adversarial robustness](https://arxiv.org/abs/1902.02918), that can help strengthen the defense. It is correct to conclude that an AGI’s objectives should not be based around precise rules, but it does not follow that all objectives are similarly fragile.
**Goal refinement**
Goodhart’s Law applies to *proxies* for what we care about, rather than what we actually care about. Consider [ideal utilitarianism](https://oxford.universitypressscholarship.com/view/10.1093/acprof:oso/9780199577446.001.0001/acprof-9780199577446-chapter-4): does Goodhart’s Law show that “maximizing the good” will inevitably lead to ruin? Regardless of how one views ideal utilitarianism, it would be wrong to conclude that it is refuted by Goodhart’s Law, which warns that many *proxies* for good (e.g. “the number of humans who are smiling”) will tend to collapse when subjected to optimization pressure.
Proxies that capture something we care about will likely have an approximation error. Some objectives have more approximation error than others: for instance, if we want to measure economic health, using real GDP reported by the US government will likely have less approximation error than nominal GDP reported in a text file on my computer. When subjected to optimization, that approximation error may become magnified, as optimizers can find areas where the approximation is particularly flawed and potentially manipulate it. This suggests that as optimization power increases, approximation error must correspondingly decrease, which can happen with better models, or approximation errors must become harder to exploit, which can happen with better detectors. As such, systems will need to have their goals continuously refined and improved.
Methods for goal refinement might include better automated moral decision making and value clarification. We will discuss these in our next post.
### Limitations of research based on a hypothetical superintelligence
Many research agendas start by assuming the existence of a superintelligence, and ask how to prove that it is completely safe. Rather than focus on microcosmic existing or soon-to-emerge systems, this line of research analyzes a model in the limit. This line of attack has limitations and should not be the only approach in the portfolio of safety research.
For one, it encourages work in areas which are far less tractable. While mathematical guarantees of safety would be the ideal outcome, there is good reason to believe that in the context of engineering sciences like deep learning, they will be very hard to come by (see the previous posts in the sequence). In information security, practitioners do not look for airtight guarantees of security, but instead try to increase security iteratively as much as possible. Even RSA, the centerpiece of internet encryption, is not provably completely unbreakable (perhaps a superintelligence could find a way to efficiently factor large numbers). Implicitly, the requirement of a proof and only considering worst-case behavior relies on incorrect ideas about Goodhart’s Law: “if it is possible for something to be exploited, it certainly will be by a superintelligence.” As detailed above, this account is overly simplistic and assumes a fixed, rule-based, or unintelligent target.
Second, the assumption of superintelligence eliminates an entire class of interventions which may be needed. It forces a lack of concretization, since it is not certain what kind of system will eventually be superintelligent. This means that feedback loops are extremely sparse, and it is difficult to tell whether any progress is being made. The approach often implicitly incentivizes retrofitting superintelligent systems with safety measures, rather than building safety into pre-superintelligent systems in earlier stages. From complex systems, we know that the crucial variables are often discovered by accident, and only empirical work is able to include the testing and tinkering needed to uncover those variables.
Third, this line of reasoning typically assumes that there will be a single superintelligent agent working directly against us humans. However, there may be multiple superintelligent agents that can rein in other rogue systems. In addition, there may be artificial agents that are above human level on only some dimensions (e.g., creating new chemical or biological weapons), but nonetheless, they could pose existential risks before a superintelligence is created.
Finally, asymptotically-driven research often ignores the effect of technical research on sociotechnical systems. For example, it does very little to improve safety culture among the empirical researchers who will build strong AI, which is a significant opportunity cost. It also is less valuable in cases of (not necessarily existential) crisis, just when policymakers will be looking for workable and time-tested solutions.
Assuming an omnipotent, omniscient superintelligence can be a useful exercise, but it should not be used as the basis for all research agendas.
### Instead, improve cost/benefit variables
In science, problems are rarely solved in one fell swoop. Rather than asking, “does this solve every problem?” we should ask “does this make the current situation better?” Instead of trying to build a technical solution and then try to use it to cause a future AGI to swerve towards safety, we should begin steering towards safety now.
The military and information assurance communities, which are used to dealing with highly adversarial environments, do not search for solutions that render all failures an impossibility. Instead, they often take a cost-benefit analysis approach by aiming to increase the cost of the most pressing types of adversarial behavior. Consequently, a cost-benefit approach is a time-tested way to address powerful intelligent adversaries.
Even though no single factor completely guarantees safety, we can drive down risk through a combination of many safety features (defense in depth). Better adversarial robustness, ethical understanding, safety culture, anomaly detection, and so on to collectively make exploitation by adversaries harder, driving up costs.
In practice, the balance between the costs and benefits of adversarial behavior needs to be tilted in favor of the costs. While it would be nice to have the cost of adversarial behavior be infinite, in practice this is likely infeasible. Fortunately, we just need it to be sufficiently large.
In addition to driving up the cost of adversarial behavior, we should of course drive down the cost of safety features (an important high-level contributing factor). This means making safety features useful in more settings, easier to implement, more reliable, less computationally expensive, or have less steep or no tradeoffs with capabilities. Even if an improvement does not completely solve a safety problem once and for all, we should still aim to continue increasing the benefits. In this way, safety becomes something we can continuously improve, rather than an all-or-nothing binary property.
Some note we “only have one chance to get safety right,” so safety is binary. Of course, there are no do-overs if we’re extinct, so whether or not humans are extinct is indeed binary. However, we believe that the probability of extinction due to an event or deployment is not zero or one, but rather a continuous real value that we can reduce by cautiously changing the costs and benefits of hazardous behavior and safety measures, respectively. The goal should be to reduce risk as much as possible over time.
It’s important to note that not all research areas, including those with clear benefits, will have benefits worth their costs. We will discuss one especially important cost to be mindful of: hastening capabilities and the onset of x-risk.
Safety/capabilities tradeoffs
-----------------------------
Safety and capabilities are linked and can be difficult to disentangle. A more capable system might be more able to understand what humans believe is harmful; it might also have more ability to cause harm. Intelligence cuts both ways. We do understand, however, that desirable behavior *can* be decoupled from intelligence. For example, it is well-known that *moral virtues* are distinct from *intellectual virtues*. An agent that is knowledgeable, inquisitive, quick-witted, and rigorous is not necessarily honest, just, power-averse, or kind.
In this section, by *capabilities* we mean *general capabilities.*These include general prediction, classification, state estimation, efficiency, scalability, generation, data compression, executing clear instructions, helpfulness, informativeness, reasoning, planning, researching, optimization, (self-)supervised learning, sequential decision making, recursive self-improvement, open-ended goals, models accessing the Internet, or similar capabilities. We are not speaking of more specialized capabilities for downstream applications (for instance, climate modeling).
It is not wise to decrease some risks (e.g. improving a safety metric) by increasing other risks through advancing capabilities. In some cases, optimizing safety metrics might increase capabilities even if they aren’t being aimed for, so there needs to be a more principled way to analyze risk. We must ensure that growing the safety field does not simply hasten the arrival of superintelligence.
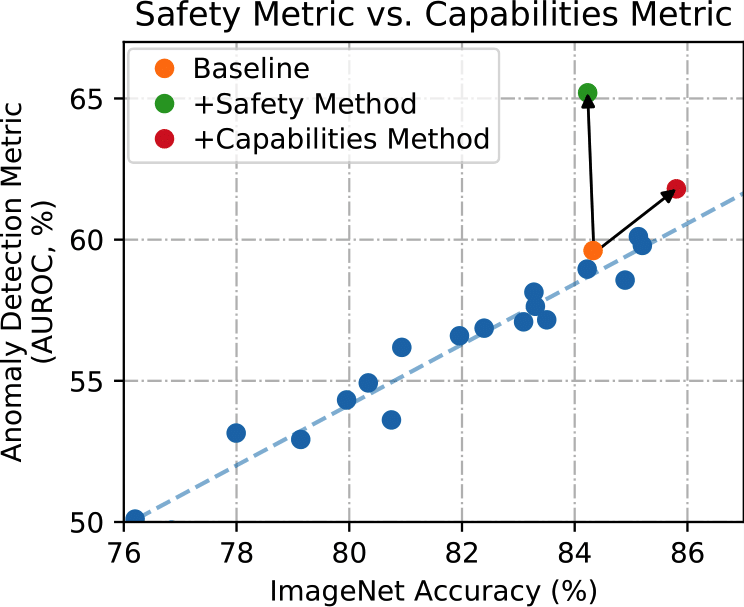The figure above shows the performance of various methods on standard ImageNet as well as their anomaly detection performance. The overall trendline shows that anomaly detection performance tends to improve along with more general ImageNet performance, suggesting that one way to make “safety progress” is simply to move along the trendline (see the red dot). However, if we want to make [differentialprogress](https://www.nickbostrom.com/existential/risks.html) towards safety specifically, we should instead focus on safety methods that do not simply move along the existing trend (see the green dot). In addition, the trendline also suggests that differential safety progress is in fact *necessary* to attain maximal anomaly detection performance, since even 100% accuracy would only lead to ~88% AUROC. Consequently researchers will need to shift the line up, not just move along the trendline. This isn’t the whole picture. There may be other relevant axes, such as the ease of a method’s implementation, its computational cost, its extensibility, and its data requirements. However, the leading question should be to ask what the effect of a safety intervention is on general capabilities.
It’s worth noting that safety is commercially valuable: systems viewed as safe are more likely to be deployed. As a result, even improving safety without improving capabilities could hasten the onset of x-risks. However, this is a very small effect compared with the effect of directly working on capabilities. In addition, hypersensitivity to any onset of x-risk proves too much. One could claim that any discussion of x-risk at all draws more attention to AI, which could hasten AI investment and the onset of x-risks. While this may be true, it is not a good reason to give up on safety or keep it known to only a select few. We should be precautious but not self-defeating.
### Examples of capabilities goals with safety externalities
[Self-supervised learning](https://arxiv.org/abs/1906.12340) and [pretraining](https://arxiv.org/abs/2004.06100) have been shown to improve various uncertainty and robustness metrics. However, the techniques were developed primarily for the purpose of advancing general capabilities. This shows that it is not necessary to be aiming for safety to improve it, and certain upstream capabilities improvements can simply improve safety “accidentally.”
Improving world understanding helps models better anticipate consequences of their actions. It thus makes it less likely that they will produce unforeseen consequences or take irreversible actions. However, it also increases their power to influence the world, potentially increasing their ability to produce undesirable consequences.
Note that in some cases, even if research is done with a safety goal, it might be indistinguishable from research done with a capabilities goal if it simply moves along the existing trendlines.
### Examples of safety goals with capabilities externalities
Encouraging models to be truthful, when defined as not asserting a lie, may be desired to ensure that models do not willfully mislead their users. However, this may increase capabilities, since it encourages models to have better understanding of the world. In fact, maximally truth-seeking models would be more than fact-checking bots; they would be general research bots, which would likely be used for capabilities research. Truthfulness roughly combines three different goals: accuracy (having correct beliefs about the world), calibration (reporting beliefs with appropriate confidence levels), and honesty (reporting beliefs as they are internally represented). Calibration and honesty are safety goals, while accuracy is clearly a capability goal. This example demonstrates that in some cases, less pure safety goals such as truth can be decomposed into goals that are more safety-relevant and those that are more capabilities-relevant.
One safety goal could be to incentivize collaboration, rather than competition, between different AI systems. This might be useful in reducing high-stakes conflicts that could lead to catastrophic outcomes. However, depending on how it is researched, it may come with capabilities externalities. For instance, focusing on getting agents to perform better in positive-sum games might have a significant effect on general planning ability, which could have further downstream effects.
Better modeling “human preferences” may also be an example of a safety goal with capabilities externalities; we will cover this below.
### Practical steps
When attempting to measure progress towards safety, it’s essential to also measure a method’s contribution to capabilities. One should ask whether a method creates a differential improvement in safety. Rather than relying on intuition to ascertain this, it is necessary to make empirical measurements. Empirical research claiming to differentially improve safety should demonstrate a differential safety improvement empirically. Of course, *reducing*capabilities is not likely to be helpful in practice, as this could make the method less likely to be used in the real-world.
Sometimes it is claimed that more general capabilities are needed to produce safety work, and so working on general capabilities advancements will at some point eventually allow working on safety. We agree that it is not necessarily the case that it could *never* be worth making capabilities advancements in exchange for differential improvements in safety. If at some point in the future it is impossible to make safety progress without an increase in capabilities, there may be more reason to accept capabilities externalities.
However, working on general capabilities for years to start studying a particular safety problem is neither precautious nor necessary. There are fortunately many safety research areas where it’s possible to make contributions without contributing to general capabilities at all. For instance, almost every paper in adversarial robustness hasn’t improved accuracy, because the two are not positively correlated. Similarly, out-of-distribution detection usually doesn’t come with capability externalities, and often focuses on eliciting out-of-distribution detection information from fixed models rather than improving their representations. We will discuss these and other areas and describe their relation to general capabilities in the next post.
An Application: Machine Ethics vs. Learning Task Preferences
------------------------------------------------------------
Preference learning is typically operationalized as learning human preferences over different ways to accomplish a task. This is intended to ensure that agents understand what humans mean, rather than simply what they say. However, modeling “human values” or “human preferences” is often just modeling “user comparisons” or “task preferences,” not unlike the preference or comparison annotations that companies have been collecting for ML-driven translation, advertisement, and search algorithms throughout the past years. First, humans prefer smarter models. This is especially true when humans rate the usefulness of models. As such, modeling task preferences often does not pass the capability externalities test because it includes information about preferences for task-specific behavior (e.g. the quality of a summary). Second, preferences can be inconsistent, ill-conceived, and highly situation-dependent, so they may not be generalizable to the unfamiliar world that will likely arise after the advent of highly-capable models.
Consequently, we recommend trying to make models act in keeping with human values, not model preferences for a broad suite of general tasks. One area trying to do this is [machine ethics](https://plato.stanford.edu/entries/ethics-ai/#MachEthi), which is about building ethical AIs. (This is in contrast to AI ethics, which is about “ethics of AI” and is dominated by discussions of fairness, bias, and inequality; by way of its constituent’s Foucualtian presuppositions, it often implicitly [adopts anti-normative positions](https://perso.uclouvain.be/mylene.botbol/Recherche/GenreBioethique/Nussbaum_NRO.htm).) Rather than model task preferences, a core aim of machine ethics is modeling actual human values.
Compared with task preferences, ethical theories and human values such as intrinsic goods may be more generalizable, interpretable, and neglected. They are also more important to us (compared to preferences for high-quality summarization, for instance), and are also plausibly timeless. In addition, many normative factors are common to a number of ethical theories, even if theories disagree about how to combine them. Coarsely, normative factors are intrinsic goods, general constraints, special obligations, and options. An expansion of this list could be wellbeing, knowledge, the exercise of reason, autonomy, friendship, equality, culpability, impartiality, desert, deontological thresholds, intending harm, lying, promises, special obligations, conventions, duties to oneself, options, and so on. Note that these include factors that cover fairness, but also a whole spectrum of additional important factors.
In general, research into the application of ethical theories and the approximation of normative factors appears far less likely to lead to capabilities externalities, because the scope of what is being learned is restricted dramatically. Ethical theories contain less information that is relevant to understanding how to perform general tasks than generic human annotations and comparisons. Still, it’s important to anticipate potential capabilities externalities: for example, one should not try to model consequentialist ethics by building better general predictive world models, as this is likely to create capabilities externalities.
One possible goal of machine ethics is work towards a [moral parliament](https://www.fhi.ox.ac.uk/wp-content/uploads/2021/06/Parliamentary-Approach-to-Moral-Uncertainty.pdf), a framework for making ethical decisions under moral and empirical uncertainty. Agents could submit their decisions to the internal moral parliament, which would incorporate the ethical beliefs of multiple stakeholders in informing decisions about which actions should be taken. Using a moral parliament could reduce the probability that we are leaving out important normative factors by focusing on only one moral theory, and the inherent multifaceted, redundant, ensembling nature of a moral parliament would also contribute to making the model less gameable. If a component of the moral parliament is uncertain about a judgment, it could request help from human stakeholders. The moral parliament might also be able to act more quickly to restrain rogue agents than a human could and act in the fast-moving world that is likely to be induced by more capable AI. We don’t believe the moral parliament would solve all problems, and more philosophical and technical work will be needed to make it work, but it is a useful goal for the next few years.
Sometimes it is assumed that a sufficiently intelligent system will simply understand ethics, so there is no need to work on machine ethics. This analysis succumbs to the problems with asymptotic reasoning and assuming omniscience detailed above. In particular, we should not assume that an ethics model can automatically withstand the optimization pressure of another superintelligence, or that it will generalize in the same way as humans under distributional shift. We need to ensure that we will have aligned, reliable, and robust ethical understanding. A proactive ethics strategy is far more likely to succeed than one that naively hopes that the problem can be ignored or taken care of at the last moment. Additionally, on the sociotechnical front, people need time-tested examples if they are to be adopted or required in regulation. A moral parliament will take years to engineer and accrue buy-in, so we cannot trust that our values will be best furthered by a last-minute few-shot moral parliament.
Conclusion
----------
Starting research with asymptotic reasoning, while it has the benefit of aiming for research that has immediately graspable AI x-risk relevance, carries the cost of making research less specific and less tractable. It also reduces the number of research feedback loops.
By focusing on microcosms, empirical research is relevant for reducing AI x-risk, but its relevance is less immediately graspable. However, the reduction in immediately graspable relevance is more than made up for by increased tractability, specificity, measurability, and the information gained from faster feedback loops. Despite these strengths, naive empirical research threatens to produce capabilities externalities, which should be avoided as much as possible.
We propose a strategy to produce tractable tail impacts with minimal capabilities externalities. In summary:
* Pursue tail impacts, reduce moments of peril, start working on safety early, and improve the scaling laws of safety in comparison to capabilities.
* Since impact is likely to be tail distributed, it’s important to understand where tail outcomes emerge from: multiplicative processes, preferential attachment, and the edge of chaos.
* “How can this safety mechanism make strong AI completely safe?” excludes many useful risk reduction strategies. Works that stand up the question “how can this work steer the AI development process in a safer direction?” are also useful for AI x-risk reduction.
* It’s useful to view safety as a continuously improvable property rather than an all-or-nothing binary property.
* We take a stand against capabilities externalities in some safety research directions. AI safety research should be safe.
* Machine ethics should be preferred to learning task preferences, because the latter can have significant capability externalities, and ethics contains more time-tested and reliable values than task-specific preferences do.
* We suggest trying to achieve safety through evolution, rather than only trying to arrive at safety through intelligent design.
|
2994e711-e9c8-4b9b-bd42-93884bb7a635
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Potential Impossibility of Subjective Death
Epistemic Status: ~70% confidence, hoping to get some feedback.
I'm going to argue that if we accept three controversial (but not outlandish) assumptions to be true, then subjective death (the cessation of conscious experiences identifying themselves as "you") is impossible. I will keep this post as concise as possible.
----------------------------------------
Here are the three assumptions:
1. We live in a multiverse (e.g. the MWI or Tegmark's MUH is true).
2. Consciousness can be simulated computationally.
3. Identity is "transmitted" through similarity of observer-moments.
Given assumption 1, somewhere "out there" (e.g. in a different Everett branch), there will be worlds that contain "revival simulations" of you (simulations of you being revived and regaining consciousness after your death).
Given assumption 2, these simulations will be conscious and have subjective experience.
Given assumption 3, these revival simulations of you are technically "you" since "you" of this instant is a particular observer-moment that is being computed in a multitude of quantum branches or universes. Your identity is transmitted through the continuity of similar observer-moments since these simulations possess the same memories as you before you died (and hence connect with your last observer moment).
Similar to how the quantum immortality argument says that even though your "reality measure" is reduced after an experiment, you are guaranteed to survive from your perspective because you cannot subjectively experience the branches where you die. Here the argument is that when you die, there will be quantum branches or other universes computing observer-moments of "you" experiencing a revival. Hence you should always expect to be revived after death.
----------------------------------------
These conclusions sound pretty crazy to me intuitively, but if one accepts the assumptions (whether or not those assumptions are true is outside the scope of this post), these conc
|
b1d99f19-e4ef-4a70-a617-fa898c5b3bc0
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Applying utility functions to humans considered harmful
There's a lot of discussion on this site that seems to be assuming (implicitly or explicitly) that it's meaningful to talk about the utility functions of individual humans. I would like to question this assumption.
To clarify: I don't question that you couldn't, *in principle*, modela human's preferences by building this insanely complex utility function. But there's an infinite amount of methods by which you could model a human's preferences. The question is which model is the most useful, and which models have the least underlying assumptions that will lead your intuitions astray.
Utility functions are a good model to use if we're talking about designing an AI. We want an AI to be predictable, to have stable preferences, and do what we want. It is also a good tool for building agents that are immune to Dutch book tricks. Utility functions are a bad model for beings that do not resemble these criteria.
To quote [Van Gelder (1995)](http://people.bu.edu/pbokulic/class/vanGelder-reading.pdf):
>
> Much of the work within the classical framework is mathematically elegant and provides a useful description of optimal reasoning strategies. As an account of the actual decisions people reach, however, classical utility theory is seriously flawed; human subjects typically deviate from its recommendations in a variety of ways. As a result, many theories incorporating variations on the classical core have been developed, typically relaxing certain of its standard assumptions, with varying degrees of success in matching actual human choice behavior.
>
> Nevertheless, virtually all such theories remain subject to some further drawbacks:
>
> (1) They do not incorporate any account of the underlying motivations that give rise to the utility that an object or outcome holds at a given time.
> (2) They conceive of the utilities themselves as static values, and can offer no good account of how and why they might change over time, and why preferences are often inconsistent and inconstant.
> (3) They offer no serious account of the deliberation process, with its attendant vacillations, inconsistencies, and distress; and they have nothing to say about the relationships that have been uncovered between time spent deliberating and the choices eventually made.
>
> Curiously, these drawbacks appear to have a common theme; they all concern, one way or another, *temporal* aspects of decision making. It is worth asking whether they arise because of some deep structural feature inherent in the whole framework which conceptualizes decision-making behavior in terms of calculating expected utilities.
>
>
>
One model that attempts to capture actual human decision making better is called *decision field theory*. (I'm no expert on this theory, having encountered it two days ago, so I can't vouch for how good it actually is. Still, even if it's flawed, it's useful for getting us to think about human preferences in what seems to be a more realistic way.) Here's a brief summary of how it's constructed from traditional utility theory, based on [Busemeyer & Townsend (1993)](http://mypage.iu.edu/~jbusemey/psy_rev_1993.pdf). See the article for the mathematical details, closer justifications and different failures of classical rationality which the different stages explain.
**Stage 1: Deterministic Subjective Expected Utility (SEU) theory.** Basically classical utility theory. Suppose you can choose between two different alternatives, A and B. If you choose A, there is a payoff of 200 utilons with probability S1, and a payoff of -200 utilons with probability S2. If you choose B, the payoffs are -500 utilons with probability S1 and +500 utilons with probability S2. You'll choose A if the expected utility of A, S1 \* 200 + S2 \* -200 is higher than the expected utility of B, S1 \* -500 + S2 \* 500, and B otherwise.
**Stage 2: Random SEU theory.** In stage 1, we assumed that the probabilities S1 and S2 stay constant across many trials. Now, we assume that sometimes the decision maker might focus on S1, producing a preference for action A. On other trials, the decision maker might focus on S2, producing a preference for action B. According to random SEU theory, the attention weight for variable S*i* is a continous random variable, which can change from trial to trial because of attentional fluctuations. Thus, the SEU for each action is also a random variable, called the *valence* of an action. Deterministic SEU is a special case of random SEU, one where the trial-by-trial fluctuation of valence is zero.
**Stage 3: Sequential SEU theory.** In stage 2, we assumed that one's decision was based on just one sample of a valence difference on any trial. Now, we allow a sequence of one or more samples to be accumulated during the deliberation period of a trial. The attention of the decision maker shifts between different anticipated payoffs, accumulating weight to the different actions. Once the weight of one of the actions reaches some critical threshold, that action is chosen. Random SEU theory is a special case of sequential SEU theory, where the amount of trials is one.
Consider a scenario where you're trying to make a very difficult, but very important decisions. In that case, your inhibitory threshold for any of the actions is very high, so you spend a lot of time considering the different consequences of the decision before finally arriving to the (hopefully) correct decision. For less important decisions, your inhibitory threshold is much lower, so you pick one of the choices without giving it too much thought.
**Stage 4: Random Walk SEU theory.** In stage 3, we assumed that we begin to consider each decision from a neutral point, without any of the actions being the preferred one. Now, we allow prior knowledge or experiences to bias the initial state. The decision maker may recall previous preference states, that are influenced in the direction of the mean difference. Sequential SEU theory is a special case of random walk theory, where the initial bias is zero.
Under this model, decisions favoring the status quo tend to be chosen more frequently under a short time limit (low threshold), but a superior decision is more likely to be chosen as the threshold grows. Also, if previous outcomes have already biased decision A very strongly over B, then the mean time to choose A will be short while the mean time to choose B will be long.
**Stage 5: Linear System SEU theory.** In stage 4, we assumed that previous experiences all contribute equally. Now, we allow the impact of a valence difference to vary depending on whether it occurred early or late (a [primacy or recency effect](http://en.wikipedia.org/wiki/Serial_position_effect)). Each previous experience is given a weight given by a growth-decay rate parameter. Random walk SEU theory is a special case of linear system SEU theory, where the growth-decay rate is set to zero.
**Stage 6: Approach-Avoidance Theory.** In stage 5, we assumed that, for example, the average amount of attention given to the payoff (+500) only depended on event S2. Now, we allow the average weight to be affected by a another variable, called the goal gradient. The basic idea is that the attractiveness of a reward or the aversiveness of a punishment is a decreasing function of distance from the point of commitment to an action. If there is little or no possibility of taking an action, its consequences are ignored; as the possibility of taking an action increases, the attention to its consequences increases as well. Linear system theory is a special case of approach-avoidance theory, where the goal gradient parameter is zero.
There are two different goal gradients, one for gains and rewards and one for losses or punishments. Empirical research suggests that the gradient for rewards tends to be flatter than that for punishments. One of the original features of approach-avoidance theory was the distinction between rewards versus punishments, closely corresponding to the distinction of positively versus negatively framed outcomes made by more recent decision theorists.
**Stage 7: Decision Field Theory.** In stage 6, we assumed that the time taken to process each sampling is the same. Now, we allow this to change by introducing into the theory a time unit *h*, representing the amount of time it takes to retrieve and process one pair of anticipated consequences before shifting attention to another pair of consequences. If *h* is allowed to approach zero in the limit, the preference state evolves in an approximately continous manner over time. Approach-avoidance is a spe... you get the picture.
---
Now, you could argue that all of the steps above are just artifacts of being a bounded agent without enough computational resources to calculate all the utilities precisely. And you'd be right. And maybe it's meaningful to talk about the "utility function of humanity" as the outcome that occurs when a CEV-like entity calculated what we'd decide if we could collapse Decision Field Theory back into Deterministic SEU Theory. Or maybe you just say that all of this is low-level mechanical stuff that gets included in the "probability of outcome" computation of classical decision theory. But which approach do you think gives us more useful conceptual tools in talking about modern-day humans?
You'll also note that even DFT (or at least the version of it summarized in a 1993 article) assumes that the payoffs themselves do not change over time. Attentional considerations might lead us to attach a low value to some outcome, but if we were to actually end up in that outcome, we'd always value it the same amount. This we know to be untrue. There's probably some even better way of looking at human decision making, one which I suspect might be very different from classical decision theory.
So be extra careful when you try to apply the concept of a utility function to human beings.
|
7ced5514-1cad-419b-8a24-cf2e7931b2f0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Predictable Defect-Cooperate?
Epistemic status: I consider everything written here pretty obvious, but I haven't seen this anywhere else. It would be cool if you could provide sources on topic!
Reason to write: I've seen once pretty confused discussion in Twitter about how multiple superintelligences will predictably end up in Defect-Defect equilibrium and I suspect that discussion would had been better if I could throw in this toy example.
PrudentBot cooperates with agent with known source code if agent cooperates with PrudentBot and don't cooperate with DefectBot. It's unexploitable and doesn't leave outrageous amount of utility on table. But can we do better? How can we formalize notion of "both agents understand what program equilibrium is, but they predictably end up in Defect-Cooperate situation because one agent is wastly smarter"?
Let's start with toy model. Imagine that you are going to play against PrudentBot or CooperateBot with p, 1−p probability each one. Payoff matrix is 5;5, 10;0, 2;2. Bots can't play with you directly, but you can write program to play. Your goal is to get maximum expected value.
If you cooperate, you are always going to get 5, so you should defect if you are going to get more than 5 in expectation:
2p+10−10p>5
p<5/8
Thus, our UncertainBot should take probability distribution, find if probability of encountering PrudentBot is less than 5/8 and defect, otherwise cooperate. The same with mixture of PrudentBot and DefectBot: you are guaranteed to get 2 if you defect, so
5p+0(1−p)>2
p>2/5
Can we invent better version of DefectBot? We can imagine TraitorBot, which takes state of beliefs of UncertainBot and predict if it can get away with defection and otherwise cooperate. Given previous analysis with mixture of PrudentBot and DefectBot, it's clear that TraitorBot defects if probability of PrudentBot is higher than 2/5 and cooperates otherwise, yielding strictly no lower utility than utility of Cooperate;Cooperate.
Such setup provides amazing amount of possi
|
9eed5c02-62c7-4948-a1fd-c8eb24e1fc8b
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why I'm Working On Model Agnostic Interpretability
Work done @ SERI-MATS.
This is the first in a short series of short posts about interpretability. In this post, I'm collecting some thoughts on why model agnostic interpretability is a worthwhile pursuit. I'll assume that the reader is sympathetic to arguments for interpretability in general. If you're not, maybe Neel can help.
Model agnostic interpretability methods are those which treat the model in question as a black box. They don't require access to gradients or activations, and make no assumptions about the model's architecture. The model inside could be a support vector machine; a deep neural network; a reinforcement learning agent; a set of water filled pipes; or a human in a box with a set of instructions: any system that produces some output in response to some input. This is in contrast to model specific interpretability methods, which either require access to the internal state of the model, or make assumptions about its architecture.
Model agnostic interpretability methods are entirely perturbation-based, meaning that they consist of various different ways of changing the input, and looking at how the output changes (what else is there to do?). It turns out that there are many ways to do this, and I will refer you to other excellent overviews rather than reiterating them here.
Here's an example of perturbation-based saliency mapping, a model agnostic interpretability method. Parts of the input are iteratively perturbed, and the resulting changes in the logit for the class 'dog' are mapped to the location of those perturbations.
Some of these methods (like perturbation-based saliency mapping) work with any kind of data. You could perform the same kind of iterative perturbation upon time-series, or text, or tabular inputs, or RL environments in a pretty straightforward manner. Other methods (like feature visualisation) rely on a searchable input space, which makes them harder to apply to arbitrary input types (although I suspect not impossible – more
|
f428e1c2-13dd-46f1-a5f5-69f0850c594f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
January 2018 Media Thread
This is the monthly thread for posting media of various types that you've found that you enjoy. Post what you're reading, listening to, watching, and your opinion of it. Post recommendations to blogs. Post whatever media you feel like discussing! To see previous recommendations, check out the older threads.
Rules:
* Please avoid downvoting recommendations just because you don't personally like the recommended material; remember that liking is a two-place word. If you can point out a specific flaw in a person's recommendation, consider posting a comment to that effect.
* If you want to post something that (you know) has been recommended before, but have another recommendation to add, please link to the original, so that the reader has both recommendations.
* Please post only under one of the already created subthreads, and never directly under the parent media thread.
* Use the "Other Media" thread if you believe the piece of media you want to discuss doesn't fit under any of the established categories.
* Use the "Meta" thread if you want to discuss about the monthly media thread itself (e.g. to propose adding/removing/splitting/merging subthreads, or to discuss the type of content properly belonging to each subthread) or for any other question or issue you may have about the thread or the rules.
|
98570326-6e47-4d2f-b8b5-4e275aa09f6f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Ottawa LW meetup, May 26, 7pm; Bayes study group, May 26, 9am
Less Wrong meeting:
Date: Thursday May 26, 7:00pm 'til whenever.
Venue: Bridgehead, 282 Elgin St. (corner at MacLaren).
Bayes study group: Anyone in the region interested in learning how to do Bayesian statistics is welcome to join us. We'll be using the statistical package R (http://cran.r-project.org/) as a platform, so bring your laptop if you have one.
Date: Thursday May 26, 9:00am to 10:30am. NB: 9 in the morning.
Venue: Jeanne Mance Building, Tunney's Pasture. Meet me in the lobby.
|
621966d9-0c8a-42b2-ba1d-d4322d70343b
|
awestover/filtering-for-misalignment
|
Redwood Research: Alek's Filtering Results
|
id: post3464
A catastrophe is an event so bad that we are not willing to let it happen even a single time. For example, we would be unhappy if our self-driving car ever accelerates to 65 mph in a residential area and hits a pedestrian. Catastrophes present a theoretical challenge for traditional machine learning — typically there is no way to reliably avoid catastrophic behavior without strong statistical assumptions. In this post, I’ll lay out a very general model for catastrophes in which they are avoidable under much weaker statistical assumptions . I think this framework applies to the most important kinds of catastrophe, and will be especially relevant to AI alignment. Designing practical algorithms that work in this model is an open problem. In a subsequent post I describe what I currently see as the most promising angles of attack. Modeling catastrophes We consider an agent A interacting with the environment over a sequence of episodes. Each episode produces a transcript τ, consisting of the agent’s observations and actions, along with a reward r ∈ [0, 1]. Our primary goal is to quickly learn an agent which receives high reward. (Supervised learning is the special case where each transcripts consist of a single input and a label for that input.) While training, we assume that we have an oracle which can determine whether a transcript τ is “catastrophic.” For example, we might show a transcript to a QA analyst and ask them if it looks catastrophic. This oracle can be applied to arbitrary sequences of observations and actions, including those that don’t arise from an actual episode . So training can begin before the very first interaction with nature, using only calls to the oracle. Intuitively, a transcript should only be marked catastrophic if it satisfies two conditions: The agent made a catastrophically bad decision. The agent’s observations are plausible: we have a right to expect the agent to be able to handle those observations. While actually interacting with the environment, the agent cannot query the oracle — there is no time to wait for a QA engineer to review a proposed action to check if it would be catastrophic. Moreover, if interaction with nature ever produces a catastrophic transcript, we immediately fail. The performance of an algorithm is characterized by two parameters: the probability of catastrophic failure, and the total reward assuming no catastrophic failure. We assume that there are some policies such that no matter what nature does, the resulting transcript is never catastrophic. Traditionally in RL the goal is to get as much reward as the best policy from some class C. We’ slightly weaken that goal, and instead aim to do as well as the best policy from C that never makes a catastrophic decision. Batch learning I’ve described an online version of learning with catastrophes. We can also consider the batch version, where the learner is first given a large number of “training” episodes. In the batch version, there is no penalty for catastrophes at training time, and we don’t care about training error. The two performance parameters are test-time performance and test-time catastrophe probability. The oracle This definition depends on an oracle who determines which transcripts are catastrophic. For weak AI systems, the oracle may be a human. But a powerful AI system might take actions which are catastrophic but which look inoffensive to a human judge, so this approach doesn’t cut it. In general, the judge should be a human+AI team which is more competent than the system being trained, armed with an adequate solution to the informed oversight problem . Approach Learning with catastrophes is straightforward given an unlimited number of queries to the catastrophe oracle . Given any online learning algorithm A, we can “harden” it by running the following process before the beginning of each episode (a similar process can be applied to a batch learner): Search over all possible environments, running A on each one to obtain a transcript. If we find a catastrophic transcript τ, then add τ to A’s training data with a reward of −1, and go back to step 1. It’s easy to prove that this process converges, if A is competent: the number of times we invoke step 2 is at most the time required to learn an optimal catastrophe-free policy (plus the number of episodes). The big problem with this algorithm is the exponential search in step 1. Adversarial training The most obvious approach to tractable learning with catastrophes is to replace step 1 with a tractable algorithm that approximates the search. This process is an example of adversarial training . We can formalize this as a simple game between the agent A and an adversary B. The two agents alternate taking moves, with A playing the role of the agent and B playing the role of the environment. B wins if the resulting transcript is catastrophic, A wins if it is not catastrophic. Before each episode, we play this game N times, where N > 0 is a hyperparameter. If B is able to win any of the games, then we add the resulting transcript to A’s training data and start again. Once B is not able to win any games, then we move on to a “real” episode. We hope that B is good enough at the game that if it can’t produce a catastrophic transcript, then the real environment can’t produce a catastrophic transcript either. More precisely, before each episode we perform the following process: Set i = 0. A and B alternate taking moves, producing a transcript τ. If τ is catastrophic, we add τ to A’s training data with a reward of −1, and add τ to B’s training data with a reward of +1. Then we go back to step 1. If τ is not catastrophic, we add τ to B’s training data with a reward of −1. If i < N, we increment i and go back to step 2. I discuss this idea in more detail in my post on red teams . There are serious problems with this approach and I don’t think it can work on its own, but fortunately it seems combinable with other techniques . Conclusion Learning with catastrophes is a very general model of catastrophic failures which avoids being obviously impossible. I think that designing competent algorithms for learning with catastrophes may be an important ingredient in a successful approach to AI alignment. This was originally posted here on 28th May, 2016. Tomorrow's AI Alignment sequences post will be in the sequence on Value Learning by Rohin Shah. The next post in this sequence will be 'Thoughts on Reward Engineering' by Paul Christiano, on Thursday.
|
86ddd748-5453-4963-b63b-5266551aa05a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Which one of these two academic routes should I take to end up in AI Safety?
I've finished two Bachelor's in Maths and Physics with moderately good grades, but a fairly advanced Thesis (and advanced learning) in Mathematical Logic. I've recently learned about the ethical urgency of AI Safety research. With the prospect of getting into that field in the near future (probably along the lines of a Theoretical Research Lead), I now have to face a career decision, and I'd be really thankful if anyone familiar with the academic field of AI research could share their thoughts. My two options are the following:
1. Taking the Master of Pure and Applied Logic in Barcelona. This Master's is almost exclusively pure maths, but I'm pretty sure I'd be able to obtain excellent grades.
2. Undertaking a 3-year PhD in Mathematical Logic in Vienna. The research would again be in some specific areas of pure maths (Recursion Theory, Proof Theory, Set Theory), and I'm pretty certain (but not as much) that I'd be able to obtain good results.
My initial idea was the Master's might be a better choice for ending up in AI Safety since it leaves open the possibility of later undertaking a PhD closer to AI, and I'd probably be considered a valuable student if I obtain excellent grades. But on the contrary, obtaining a PhD in pure maths being as young as I am might provide even more status. Furthermore, I'm not certain the best way to enter AI academia is necessarily by undertaking an AI-related PhD.
|
3477fa57-5694-460d-b6d6-624dfd97b9ab
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
AXRP Episode 5 - Infra-Bayesianism with Vanessa Kosoy
[Google Podcasts link](https://podcasts.google.com/feed/aHR0cHM6Ly9heHJwb2RjYXN0LmxpYnN5bi5jb20vcnNz/episode/YjExOTA0NmItMDBmZC00Yzc5LTgwMGYtOTRkNDkyMzcwZDk3)
This podcast is called AXRP, pronounced axe-urp and short for the AI X-risk Research Podcast. Here, I ([Daniel Filan](https://danielfilan.com/)) have conversations with researchers about their papers. We discuss the paper and hopefully get a sense of why it’s been written and how it might reduce the risk of artificial intelligence causing an [existential catastrophe](https://en.wikipedia.org/wiki/Global_catastrophic_risk): that is, permanently and drastically curtailing humanity’s future potential.
The theory of sequential decision-making has a problem: how can we deal with situations where we have some hypotheses about the environment we’re acting in, but its exact form might be outside the range of possibilities we can possibly consider? Relatedly, how do we deal with situations where the environment can simulate what we’ll do in the future, and put us in better or worse situations now depending on what we’ll do then? Today’s episode features Vanessa Kosoy talking about infra-Bayesianism, the mathematical framework she developed with Alex Appel that modifies Bayesian decision theory to succeed in these types of situations.
Before the interview, I have a quick announcement to make. In order to make this podcast better, I’ve released a survey to get feedback from you listeners. If you have a few minutes to spare, I’d greatly appreciate it if you could fill it out - you can access it [here](https://forms.gle/LFKi1whWASaw3bTY8). Now, on to the main show.
**Daniel Filan:**
Hello everybody. Today I’m going to be talking to Vanessa Kosoy. She is a research associate at the Machine Intelligence Research Institute. She’s worked for over 15 years in software engineering. About five years ago, she started AI alignment research, and is now doing that full-time. She’s authored three papers, but today we’re going to be talking about her [sequence of posts on infra-Bayesianism](https://www.alignmentforum.org/s/CmrW8fCmSLK7E25sa) that was co-authored by Alex Appel. So, Vanessa, welcome to AXRP.
**Vanessa Kosoy:**
Thank you, Daniel.
**Daniel Filan:**
All right. I guess the first question is, in a nutshell, what is infra-Bayesianism?
**Vanessa Kosoy:**
Infra-Bayesianism is a mathematical framework that is meant to deal with the problem of non-realizability in reinforcement learning, or in the theory of reinforcement learning. The problem of non-realizability is that you have a certain hypothesis space that your algorithm is trying to learn. It is trying to learn which hypothesis is correct, but the real world is described by none of those hypotheses because it’s much more complex than any model could possibly capture, and most of theoretical research, or virtually all theoretical research in reinforcement learning focused on realizable cases, so just assuming that the world can be exactly described by one of the hypotheses, and that’s where infra-Bayesianism comes in and explains what happens when we drop this assumption.
**Daniel Filan:**
Okay. I gather that this work is motivated by AI alignment, or ensuring that that when we create really smart AIs in the future, they’re going to do what we want. How big a problem do you think non-realizability is for this?
**Vanessa Kosoy:**
Well, there are several reasons why I’m interested in this in the context of AI alignment.
**Daniel Filan:**
Okay.
**Vanessa Kosoy:**
One reason is just de-confusion, right? Trying to understand what does it mean for a reinforcement learning system to operate in a non-realizable setting, and how to think about this mathematically. The other reason is because, if ultimately we want to have algorithms that satisfy formal guarantees, if we want alignment to be provable in some mathematical model, then non-realizability is one of the issues we’re going to have to deal with in that context, and a third reason, or it’s like a third group of reasons, maybe, is that there are multiple questions related to de-confusing AI that hit this non-realizability obstacle. For example, the question of embedded agency, which MIRI [the Machine Intelligence Research Institute] has been thinking about for some time, and promoting as one of the important problems, is something that’s closely related to non-realizability, because if your agent is-
**Daniel Filan:**
What is embedded agency, I should ask.
**Vanessa Kosoy:**
Right. Embedded agency talks about agents that are part of the physical world, right? The classical approach to reinforcement learning is viewing an agent as just two channels, input and output, and there’s no physical world anywhere in the picture. Embedded agency is trying to understand how to fix that, because, for example, human values are not necessarily expressible in terms of human inputs and outputs, right, so how do you think of that, and because of various failure modes that can happen because you’re not taking into account in our models that the AI is actually part of the environment and not just a completely separate thing. This is closely related to non-realizability, and indeed I have a program, how to use infra-Bayesianism, how to apply to understand embedded agency, and that’s one thing. Another thing is reflection. Reasonable agents that do self-improvement. That also very quickly leads you to problems of non-realizability, because in reflection an agent should be thinking about itself, right, but it cannot have a perfect model of itself.
**Daniel Filan:**
Why can’t it have a perfect model of itself?
**Vanessa Kosoy:**
Well, it’s this kind of paradox, because it enters a sort of infinite loop, right? It’s like nobody can tell you a prediction of what you would do because maybe you will listen to this prediction and do the opposite, or something like that, or you can think about it just complexity theoretically. The space of hypotheses the agent is working with, their computational complexity is lower than the computational complexity of the agent itself, because it needs to somehow work with all of those hypotheses, so the agent just is too big to fit into its own hypothesis space. It’s really similar to self-referential paradoxes we have in mathematics, in logic or other places.
**Vanessa Kosoy:**
Yeah, but you can also view it as a special case of non-realizability, so infra-Bayesianism can help you there also, and another thing is decision theory, and this is something that we actually wrote about in the sequence, that infra-Bayesianism basically solves all the paradoxes, like Newcomb’s problem, and the other types of problems that MIRI were writing about, like counterfactual mugging and so on. The sort of problems that so-called updateless decision theory, or it’s sometimes called functional decision theory, was invented for, but never fully mathematically formalized. Infra-Bayesianism solves those problems, or at least a very large class of those problems, in a way that’s completely mathematically formal. So we see that there’s a whole range of different applications.
**Daniel Filan:**
Yeah, just getting onto that last part for a second. For those who might not be familiar, what is decision theory? What type of thing is decision theory trying to be a theory of?
**Vanessa Kosoy:**
Yeah. Decision theory is the field that talks about how do we think of making rational decisions mathematically, and I guess it began with the work of … or at least the mathematical side began with the work of von Neumann and Morgenstern, where they proved that expected utility maximization is always the correct way to make decisions under some reasonable assumptions, and it developed from there. So game theory and economics are all offsprings of decision theory in some sense, and specifically MIRI and Yudkowsky wrote about some interesting paradoxes, like the Newcomb paradoxes, that are a problem for classical decision theory, and it showed that our understanding of decision theory is lacking in those specific examples.
**Daniel Filan:**
What is the Newcomb paradox?
**Vanessa Kosoy:**
Okay. The Newcomb paradox is the following setting. You’re playing a game with some entity called Omega, and Omega is something very powerful. Omega is very smart, or it just has a huge computer, and it’s so powerful that is can simulate you, and it can predict everything you do. In theory, that’s completely possible, because we know that our brains operate on the laws of physics, so if you have a big enough computer, you could in theory predict everything that a person would do, and then Omega offers you a choice. You have two boxes, and you need to choose, and there is money inside of them, and you need to choose either the first box or both the first box and the second box together, and this seems like a really silly question. Obviously, if you can choose only A or A plus B, then A plus B is always better than A.
**Vanessa Kosoy:**
But there is a catch, and the catch is that Omega predicted what you would choose, and if you chose to take only the first box, then it put a million dollars in that box beforehand, before the game even started. If you chose to take both boxes, then the first box is going to be empty and the second is going to have $1,000. The result is, what happens when we see someone picking the first box, only the first box, they walk away with a million dollars, and when we see someone picking two boxes, they walk away only with $1,000 dollars, so it seems like, in some sense, it is better to pick only one box. However, classical approaches to decision theory, like causal decision theory, which is popular in philosophy, they would advise us to take both boxes, so something is wrong here. Philosophers have debated these questions, but nobody, until now, gave a completely formal decision theory that explains formally why you need to choose one box in this situation.
**Daniel Filan:**
Okay. I should say there’s this thing called evidential decision theory that does choose one box in this scenario. Is that right?
**Vanessa Kosoy:**
Right, you have evidential decision theory, which does choose one box, but then it fails in other situations, so it’s like … Yeah. Here the idea is that you want to succeed in all possible setups in which there is something predicting you and interacting with you. You want to be successful in this all of this. For evidential theory, for example, there is the [XOR blackmail problem](https://static1.squarespace.com/static/5d5add414889080001ea6912/t/5d67f57c96fe220001f7e85f/1567094142529/_JPhil__Cheating_Death_in_Damascus.pdf), in which evidential decision theory fails and causal decision theory succeeds, and then there’s the counterfactual mugging problem in which both evidential decision theory and causal decision theory both fail. On the other hand, updateless decision theory is supposed to succeed in all of those, only that updateless decision theory was not formally mathematically defined until infra-Bayesianism.
**Daniel Filan:**
Okay. I’m still going to ask preliminary questions. Just to give listeners more of a sense, I guess, of what problems we’re going to be trying to solve, what is this counterfactual mugging thing which classical decision theories don’t do well in but your new updateless decision theory inside of infra-Bayesianism is going to do well in?
**Vanessa Kosoy:**
Right. Counterfactual mugging is another game with Omega, and, like before, Omega can always predict everything you will do, and this time what happens is that Omega flips a fair coin, and if the coin falls on heads, then Omega comes to you and asks you for $100, and you can either agree to give them the $100, or you can refuse. On the other hand, if the coin falls on tails, then Omega might give you a million dollars, but they only give you the million dollars if, in the counterfactual scenario, in the scenario where the coin falls heads, you would agree to give them the $100. In this case, if you’re the type of agent that would agree to give Omega $100, your expected profit in this whole scenario is $500,000 minus $50, and if you’re the type of agent who would refuse, then your expected profit is zero, which is much worse. But this classical decision theory would refuse to pay the $100.
**Daniel Filan:**
Yeah, and this is basically, as I understand, it’s because, at the time they’re asked for $100, basically classical decision theories just say, well, I can either pay you $100 and get nothing or I can not pay you $100 and not lose anything, and so from now on my life is good if I don’t pay you, and they’re just not considering about what would have happened in this alternate universe.
**Vanessa Kosoy:**
Yeah, exactly. What happens is that, in those scenarios, classical decision theory, they would choose to pre-commit to paying the $100 if they could, but if they cannot pre-commit, they have no intrinsic mechanism of doing so. They need some kind of an external crutch that would allow them to make it through those scenarios.
**Daniel Filan:**
Okay. To summarize all of that, it seems like the point of infra-Bayesianism … my read is that it’s going to do two things for us. Firstly, it’s going to let us have something like a good, I don’t know, a good epistemology or a good decision theory about worlds that we could be in where the real world isn’t one of the wolds that we are explicitly considering, but we can still do okay in it, and secondly it’s going to let us choose actions. It’s going to give us a decision theory that is going to solve these problems … We’re going to be expected to do well in these problems where some other agent is simulating us and figuring out what we are going to do or what we would have done had things turned out differently. Is that a fair summary of what we want to get out of infra-Bayesianism?
**Vanessa Kosoy:**
It’s sort of a fair summary. I would say that the second is really a special case of the first, because when we have agents that are predicting us, then it means that we cannot predict them, right, because otherwise we have this, again, this self-referential paradox. If our environment contains agents that are predicting us, then it means that necessarily our environment is not described by one of the hypotheses we are explicitly considering. So the ability to deal with worlds that are more complex than your ability to fully describe is what gives you the power to deal with those Newcombian scenarios.
**Daniel Filan:**
Okay. So, one thing that people will notice when they start reading these posts is there’s a lot of math defined in the post, right? It’s not just we’re going to have bog standard probability distributions and go from there. Why do you need this new math? Why can’t we just do all of this with normal probability theory that many listeners know and love?
**Vanessa Kosoy:**
Well, the thing is that normal probability theory is kind of the problem here. The whole problem with non-realizability is that Bayesian probability theory, Bayesian epistemology, doesn’t really work with non-realizability. When your environment is precisely described by one of the hypotheses in your prior, then we have theorems, like the merging of opinions theorem, which shows that your predictions about what will happen will converge to what actually happens. But if your prior is mis-specified, that’s something that sometimes is called the mis-specified prior problem in statistics, then there are no guarantees about what your Bayesian reasoning will give you. There are sometimes guarantees you can prove if you assume the environment is ergodic, but that’s also a very strong assumption that does not hold in realistic cases. So Bayesian probability theory just …
**Daniel Filan:**
Yeah. When you say if the world is ergodic, what does it mean for a world to be ergodic? How could I know if my world was or was not?
**Vanessa Kosoy:**
Yeah, so ergodic is … I won’t try to give the formal definition, but roughly speaking it just means that everything converges to a stationary probability distribution. That’s what ergodic means. If you’re thinking of something like a Markov chain with a finite number of states, then it always converges to a stationary probability distribution after sufficient time. In physics, also, when systems reach thermodynamic equilibrium, they converge into a stationary distribution, and it’s true that eventually everything reaches thermodynamic equilibrium, but in the real world all the interesting things happen when we’re not in thermodynamic equilibrium, right? When we reach thermodynamic equilibrium, that will be the heat death of the universe, so that’s not a very interesting version.
**Daniel Filan:**
Okay. If we can’t use normal probabilities, can you give us a sense of roughly what are the things we’re going to be working with, if we’re going to try to be infra-Bayesians?
**Vanessa Kosoy:**
Yeah, so-
**Daniel Filan:**
And maybe this is going to explain why we’re using the prefix infra.
**Vanessa Kosoy:**
Yeah. Well, infra-Bayesianism is, first of all, it’s built upon something called imprecise probability, so I haven’t really invented it from scratch. I took something called imprecise probability, although when I had the idea, I did not really read much about imprecise probability. I probably just heard the general idea vaguely sober when I started thinking about this, but anyway. We took some concept called imprecise probability, which is something which is already known in decision theory in some contexts, and is used for mathematical economics, for example, and we applied this to the theory of reinforcement learning, and we also generalized it in certain ways.
**Vanessa Kosoy:**
So our main novelty is creating this connection, and imprecise probability, what it does is it says, well, instead of just having one probability distribution, let’s have a convex set, so a formally closed convex set of probability distributions. For example, just to think of a very simple example, suppose our probability space has just two elements, right, so probability distribution is just a single probability between zero and one. What imprecise probability tells us is, instead of using a probability, use an interval of probabilities. You have some interval between … I don’t know. Maybe your interval is between 0.3 and 0.45 or something. When you go to larger probability spaces, it becomes something more interesting because you have not just intervals, but you have some kind of convex bodies inside your space of probability distributions. Then we did a further generalization on top of that, which replaces it with concave functionals in the space of functions. But if you want to just understand the basic intuition, then you can be just thinking of those convex sets of probability distributions.
**Daniel Filan:**
Okay. I guess this gets to a question that I have, which is, is the fact that we’re dealing with this convex sets of distributions … because that’s the main idea, and I’m wondering how that lets you deal with non-realizability, because it seems to me that if you have a convex set of probability distributions, in standard Bayesianism, you could just have a mixture distribution over all of that convex set, and you’ll do well on things that are inside your convex set, but you’ll do poorly on things that are outside your convex set. Yeah, can you give me a sense of how … Maybe this isn’t the thing that helps you deal with non-realizability, but if it is, how does it?
**Vanessa Kosoy:**
The thing is, a convex set, you can think of it as some property that you think the world might have, right? Just let’s think of a trivial example. Suppose your world is a sequence of bits, so just an infinite sequence of bits, and one hypothesis you might have about the world is maybe all the even bits are equal to zero. This hypothesis doesn’t tell us anything about odd bits. It’s only a hypothesis about even bits, and it’s very easy to describe it as such a convex set. We just consider all probability distributions that predict that the odd bits will be zero with probability one, and without saying anything at all - the even bits, they can be anything. The behavior there can be anything.
**Vanessa Kosoy:**
Okay, so what happens is, if instead of considering this convex set, you consider some distribution on this convex set, then you always get something which makes concrete predictions about the even bits. You can think about it in terms of computational complexity. All the probability distributions that you can actually work with have bounded computational complexity because you have bounded computational complexity. Therefore, as long as you’re assuming a probability distribution, a specific probability distribution, or it can be a prior over distributions, but that’s just the same thing. You can also average them, get one distribution. It’s like you’re assuming that the world has certain low computational complexity.
**Vanessa Kosoy:**
One way to think of it is that Bayesian agents have a dogmatic belief that the world has low computational complexity. They believe this fact with probability one, because all their hypotheses have low computational complexity. You’re assigning probability one to this fact, and this is a wrong fact, and when you’re assigning probability one to something wrong, then it’s not surprising you run into trouble, right? Even Bayesians know this, but they can’t help it because there’s nothing you can do in Bayesianism to avoid it. With infra-Bayesianism, you can have some properties of the world, some aspects of the world can have low computational complexity, and other aspects of the world can have high complexity, or they can even be uncomputable. With this example with the bits, your hypothesis, it says that the odd bits are zero. The even bits, they can be uncomputable. They can be like the halting oracle or whatever. You’re not trying to have a prior over them because you know that you will fail, or at least you know that you might fail. That’s why you have different hypotheses in your prior.
**Daniel Filan:**
Thinking about the infinite bit string example, right, is the idea that, in my head, I’m going to think about, okay, there’s one convex set of all the distributions where all of the even bits are zero. Maybe there’s another hypothesis in my head that says all the even bits are one. Maybe there’s a third that says that all of the even bits, maybe they alternate, or maybe they spell out the binary digits of pi, or they’re all zero until the trillionth one, and then they’re one. Is the idea that what I’m going to do is I’m going to have a variety of these convex sets in my head, and the hope is I’m going to hit the right convex set?
**Vanessa Kosoy:**
Basically, it works just like Bayesianism in the sense that you have a prior over hypotheses. Just in Bayesianism, every hypothesis is a probability distribution, whereas in infra-Bayesianism, every hypothesis is a convex set of probability distributions, and then you have a prior over those, and if the real world happens to be inside some of those sets, then you will learn this fact and exploit it.
**Daniel Filan:**
Yeah. Thinking about the connection to the mathematical theory, so in the mathematical theory, you have these things called sa-measures, and you have these closed convex cones, which people can look up, but these sets of sa-measures, and there are minimal ones in the space. Is the idea that the minimal things in these cones, these are the convex sets, and … Yeah. I guess I’m still trying to get a sense of just exactly what the connection is between this description and the theory.
**Vanessa Kosoy:**
Yeah. The thing is that what I described is what we call, in one of the latest post, we called it crisp infra-distributions. A convex set of probability distributions, that’s, in some sense, the simplest type or one of the simplest types of infra-distributions you can consider, but there are also more general objects we can consider, and the reason we introduce those more general objects is to have a dynamically consistent update rule, because in ordinary Bayesianism, you have some beliefs, and then some event happens, and you update your belief, and you have a new belief, and you have the Bayes theorem which tells you how you should do that, and we were thinking about, okay, how should we do that for infra-Bayesianism?
**Vanessa Kosoy:**
We started with just those convex sets of probability distributions, which are just something taken from imprecise probability, and with those objects, you do not have a dynamically consistent update rule, so you can still work in the sense of just decide all of your policy in advance and follow it, but there’s no way to do updates. Well, the naive way to do updates is by sort of updating every distribution in your set, but that turns out to be not dynamically consistent. The behavior it prescribes after updating is not the same behavior it prescribed before updating, because the decision rule you’re using with those convex sets is the maximin decision rule, so you’re trying to maximize your worst-case expected utility, where the worst is taken over this convex set, and then when there are several things that can happen, then your optimal policy might be something that tries to hedge your bets, something that tries to …
**Vanessa Kosoy:**
Okay, I’m going to choose a policy such that in neither of those branches I will do too poorly, but then when you’re just in one of those branches and you’re updating, you’re throwing all those other branches to the garbage and forgetting about them. Your new optimal policy is going to do something different. The counterfactual mugging that we discussed before is exactly the perfect example of that, where just naively updating causes you to disagree with your a priori optimal policy. So in order to have a dynamically consistent update rule, you need some mathematical object which is more general than just those convex sets of probability distributions.
**Daniel Filan:**
Okay, and so the object you have, are these convex sets of souped-up probability distributions, is my rough understanding?
**Vanessa Kosoy:**
Yeah. There are two ways to think about it, which are related by Legendre-Fenchel duality. Yeah. The way we introduce them initially in the sequence is we consider … so instead of just thinking of probability distributions, we think of measures that might not sum to one, and you also have this constant term. You’re thinking of a probability distribution that someone multiplied by a constant, and also added a constant, which is not part of the distribution, but it’s added to your expected utility, and then you have a convex set of those things.
**Vanessa Kosoy:**
With those things, you can have dynamic consistency, because this constant term is keeping track of the expected utility in counterfactual scenarios, and the multiplicative term is keeping track of your a priori probability to add up in the branch in which you’re added up. But there’s also another way which I personally think is more elegant to think about it, where instead of dealing with those things, you’re just thinking of expected value as a function of functions. What are the probability distributions even for? You can think of probability distributions as just gadgets for taking expected values, and in classical probability theory, those gadgets are always linear functionals, so every probability distribution gives you a linear functional on your space of functions, the space of things that you might want to take an expected value of.
**Daniel Filan:**
And concretely, this functional is taking a function from your, I don’t know, event set to the real numbers, and this functional is taking, okay, on average, what’s the value of this function, given my distribution, over what the true event might be, and this ends up being linear in what the function from events to real numbers is, just to clarify that for the listeners.
**Vanessa Kosoy:**
Yeah, exactly. In classical probability theory, there is a classical theory which says that you can just think of probability distributions as linear functionals. You can literally just consider all linear functionals that are continuous in … there are some technical mathematical conditions. They should be continuous in some topology and they should be positive, so if your function is positive, the expectation also should be positive, but then you can define probability distributions as functionals. It’s an equally good way to define them, and then the way you go from classical probability theory to infra-Bayesianism is instead of considering linear functionals, you consider functionals that are monotonic and concave.
**Vanessa Kosoy:**
Monotonic means that you have a bigger function, it should give you a bigger expected value. Concave is concave. When you’re averaging several functions, your values should only become higher, and you can consider just all of those concave monotonic functionals, and those are your infra-distributions. The fact they are concave, you can intuitively think of it as a way of making risk-averse decisions, basically, because that’s what corresponds to this maximin rule, and that’s why those things are also used in economics sometimes, because you want to be risk averse.
**Daniel Filan:**
Okay. So we have these infra-distributions, which are kind of the same thing as these concave monotonic functionals. Yeah. In this case where I’m not sure … I’m just like, there’s an infinite sequence of bits, and I have no idea what the even bits are going to be, but I have some guess about the odd bits. Maybe they’re all zeros, maybe they’re all ones. I have a variety of hypotheses for what the odd bits might be. What does my infra-distribution look like?
**Vanessa Kosoy:**
Right. Every hypothesis is like a particular infra-distribution. In the example with sequences of bits, you would have a hypothesis that only says things about even bits, you would have a hypothesis that only says things about the odd bits, you would have hypotheses that say things about all bits, you would have hypotheses that think that the XOR of every bit with the next bit is something, or whatever. Basically, the convex set, if you’re thinking in terms of convex sets, then your convex set is just like the convex set of all of the things that have a particular property.
**Vanessa Kosoy:**
For example, if you’re thinking of, okay, my hypothesis is all even bits are zero, then your convex set is the set of all distributions that assign probability one to the even bits being zero. In this more general thing, you have sa-distributions and so on, but that’s just a technicality. That just means you need to take your set of distributions and close it by taking the Minkowski sum with some cone in this Banach space, but that’s really just a technical thing.
**Daniel Filan:**
Okay. So is the idea that, for each specific hypothesis I might have, I have this convex set of distributions, and I’m going to be doing this maximin thing within that convex set of distributions, but is the idea that I’m going to be basically just a Bayesian over these hypotheses and how the hypotheses internally behave is determined by this maximin strange update type thing?
**Vanessa Kosoy:**
Sort of. Yeah. I mean, there are multiple ways you can think about it. One way you can think about it is that your expected utility, your prior expected utility, is take expectation over your prior over hypotheses, and then for each hypothesis, take minimum of expected values inside this convex set. Or you can equivalently just take all of those convex sets and combine them into one convex set. You can literally just take, like, okay, let’s assume we choose some point inside each of those sets, and then we average those points with our prior, and the different ways of choosing those points, they give you different distributions, and so you get a new convex set. That’s just like in ordinary Bayesianism, right? You have a set of hypotheses. Each hypothesis is a probability distribution, and you have a prior over them, or you can just average them all using this prior and get just a single probability distribution. There’s two ways of looking at the same thing.
**Daniel Filan:**
All right. Cool. Hopefully this gives listeners something of an overview of infra-Bayesianism, and there’s … I don’t know. If they want to learn the maths of it, they can read the post for the mathematical theory. Going forward a little bit … So it seems like this is a theory of you have a single agent that’s inside a big, scary environment that’s really confusing and complicated, and the agent doesn’t know everything about this environment. I think in AI, we like to think of this, I don’t know, some kind of progression from a thing that’s reasoning about the world, to a thing that’s acting about the world, to the situation where you have multiple agents in the world that are jointly acting, and their decisions affect each other, like game theory. So I’m wondering, is there infra game theory yet, or if there isn’t total infra game theory, has there been any progress made towards creating it?
**Vanessa Kosoy:**
That’s a good question. In fact, one of the very interesting applications of infra-Bayesianism is exactly to multi-agent scenarios, because multi-agent scenarios are another example where ordinary Bayesianism runs into trouble because of this realizability assumption. If we have multiple agents, and each of those agents is trying to understand the other agent, trying to predict it or whatever, then we again get this self-referential paradox. We can have a situation where agent A is more powerful than agent B, and therefore agent A is able to have B inside its hypothesis space, but we usually cannot have a situation where both of them have each other in their hypothesis space.
**Vanessa Kosoy:**
There are sometimes ways you can have some trick to go … like Reflective Oracles, which is a work by MIRI that tries to solve it and have agents that do have each other inside each other’s hypothesis space, but it’s very fragile in the sense that it requires your agents to be synchronized about what type of reflective oracle, what type of prior they have. They need to be synced up in advance in order to be able to close this loop, which is a weird assumption, and infra-Bayesianism might give you a way around that, because infra-Bayesianism is precisely designed to deal with situations where your environment is not precisely describable, and in fact it does give you some results.
**Vanessa Kosoy:**
For example, it’s just trivial to see that, in zero sum games, infra-Bayesianism gives you optimal performance because … well, that’s kind of trivial because infra-Bayesianism is sort of pessimistic, so it imagines itself playing some kind of zero sum game. This is some open problems, some kind of area where I want to do work but I haven’t really developed it yet, but it seems like, for example, one result that I believe you should be able to prove is that infra-Bayesian agents that are playing a game in a non cooperative setting will converge to only playing [rationalizable] strategies, and then you will have a guarantee that your payoff will be at least the maximin payoff inside a space of non-realizable strategies. That’s already a non-trivial guarantee that you cannot easily get with Bayesianism.
**Daniel Filan:**
Okay. Yeah. I guess, related to the open work, so late last year these results were put online. I’m wondering how the reception has been and what open problems you have, and how much development there has been on those.
**Vanessa Kosoy:**
Yeah. By the way, did I say realizable? I meant rationalizable. Okay. Yeah. Currently we continue to work on developing the theory. Well, we have a ton of open research directions, like I said, we want to apply to embedded agency, and we have another post coming up, which gives some more details about decision theoretic aspects of it, and the game theory thing is another direction, and another direction, by the way, which we haven’t discussed, is the relation of this to logic, because there are also some very intriguing ways to make connections between infra-Bayesianism and logic, in some sense. I have this sort of thesis that says that infra-Bayesianism is, in some sense, a synthesis of probability theory and logic, or you can think of it as a synthesis of inductive reasoning and deductive reasoning. Yeah. We’ve been working on a number of things.
**Vanessa Kosoy:**
Also on proving concrete regret bounds, because in reinforcement learning theory, what you ultimately want is you want to have specific quantitative regret bounds that give you specific convergence rates, and we have derived some for some toy settings, but we want to have regret bounds for some more interesting settings. Yeah. A lot of the direction, there is work we’re doing. There are probably multiple papers we are going to write on the topic. I think the first paper will be some paper that will have some basics of the formalism and proves regret bounds in some basic assumptions, like infra-Bayesian bandits or infra-Bayesian MDPs, but yeah, there’s definitely a whole avenue of research to be done there.
**Daniel Filan:**
Okay. Yeah. Could you say a bit more about the connection to logic, because this wasn’t quite apparent to me when I was reading the posts.
**Vanessa Kosoy:**
Yeah. The logic connection is something that I think we haven’t really talked much about in the posts so far. The basic idea is kind of simple. Once you have convex sets, you have the natural operation of intersecting those sets, and there’s another natural operation of taking the convex hull of those sets. In other words, the sets form what’s called in mathematics a lattice. Some sets are inside other sets, and you have a join and a meet. You have the least upper bound and the maximum lower bound.
**Daniel Filan:**
Which is basically just you can intersect and you can union.
**Vanessa Kosoy:**
It’s intersect and convex hull because they have to be convex.
**Daniel Filan:**
Ah, right. Yes.
**Vanessa Kosoy:**
Yeah, so that gives you a sort of logic, and actually you can think of ordinary logic as embedded in that thing, because if you have some set, then to every subset of it, you can correspond an infra-distribution, which is just like all distributions supported on this subset, and then your operations of intersection and convex hull correspond to just intersection and union. But you also have things that do not correspond to any subset, and you can think of those things as some kind of logical disjunction and conjunction, but it’s not distributed, so that’s not classical logic. It’s some kind of weird logic, and you can also define existential and universal quantifiers that play well with this thing, and then what’s nice about it is that you can use this sort of logic to construct your infra-Bayesian hypothesis.
**Vanessa Kosoy:**
So if your hypothesis space, for example, consists of what we call infra-POMDPs, which is like the infra-Bayesian equivalent of POMDPs then you can use the language of this infra-Bayesian logic to specify hypotheses, and that’s really interesting because maybe when you do that you have some useful algorithms for how to control the hypothesis and how to learn those hypotheses, which you don’t have for just arbitrary MDPs that do not have any structure. There might also be algorithms for solving problems in this infra-Bayesian logic that do not exist for classical logic, because classical logic is often intractable, like prepositional logic is already NP-complete, and first-order logic is not computable. But infra-Bayesian logic, well, we haven’t really proved anything about that, but there is some hope that it’s more computationally tractable under some assumptions.
**Daniel Filan:**
When we were talking about infra-Bayesianism, there were two things that infra-Bayesianism basically promised us, right? The first thing was that it was going to deal with the problem of non-realizability in environments, like maybe we just can’t imagine the true environment, but we still want to learn some things about it, and the second was that it was going to help us solve these decision problems, like Newcomb’s problem, where you can one box or two box, and if somebody predicts … depending on the prediction of what you’ll do, one might be better than the other, and also counterfactual mugging, where somebody flips a coin, and if it lands tails, then, depending on what we would have done if it landed heads, we can be better or worse off. These are problems where the environment is simulating you and will make your life better or worse depending on your policy in other states. How does infra-Bayesianism help us solve these decision problems?
**Vanessa Kosoy:**
Right. What does it mean to solve a problem? It means that the agent can build a model of the problem which will lead it to taking the right actions, actions that will give it maximal utility. The usual way those problems are considered is by starting with something like a causal diagram, but here we’re taking a step back and saying, okay, suppose that the agent encounters this situation, and the agent tries to understand what is happening. It is trying to learn it, to build some model of it.
**Vanessa Kosoy:**
The easiest way to imagine how this thing can happen is in an iterated setting, when you’re playing the same game over and over, whether that’s Newcomb’s problem or counterfactual mugging. Then you can look, okay, given that my agent is in this iterated setting, what sort of model will it converge to and what sort of behavior will it converge to? We’re not assuming something like a casual diagram description. Instead, we are letting the agent learn whatever it’s going to learn in that situation, and what happens in situations with predictors that predict your agent is there is always this model available which says, well, there is something in the environment which is doing those things, and I have sort of Knightian uncertainty about what it’s going to do.
**Vanessa Kosoy:**
That means that in my convex set of probability distributions … I’m going to remind you that in infra-Bayesianism, our hypotheses were convex sets of probability distributions. In our convex set, we’re allowing this predictor, this Omega, to make whatever predictions it wants, because there is no way to directly say, well, it’s going to predict what I will do. That’s not a legitimate type of hypothesis like the standard way you build hypotheses in reinforcement learning. Hypotheses in reinforcement learning are you take an action and you see an observation, then you take an action, and so on.
**Vanessa Kosoy:**
This Omega can do whatever it wants, but then there arrives some moment in time when its prediction is tested. Omega made some predictions, wrote them down somewhere where we cannot see, and then doing things according to those predictions, and then the prediction’s getting tested. At this point, well, what happens is that if those predictions turns out to be false, then we can imagine that what happens is a transition to some state of infinite utility. That sounds weird at first, but …
**Vanessa Kosoy:**
So why a state of infinite utility? Well, first of all, notice that this is consistent with observations, because the agent will never see a situation in which a prediction is falsified, because by assumption the predictor is a good predictor, so this will never actually happen, so it is consistent from the agent’s perspective to assume this. But once we assume this, then the optimal policy becomes “behave as if those predictions will be true”. Why? Because we’re always planning for the worst case, and the predictions becoming false can never be the worst case, because if the predictions are false, if they are falsified, then we end up in a state of infinite utility, so that can never be the worst case.
**Vanessa Kosoy:**
Therefore, the worst case is always going to be when Omega actually predicts correctly, and our policy is going to be the optimal policy given that Omega predicts correctly, which is the UDT policy. Now, there is another thing where you can develop it.
**Vanessa Kosoy:**
Initially I just introduced this idea as a kind of ad hoc thing, but then we noticed that … and that’s still the upcoming post that we’re going to publish soon. Then we noticed that if you also allow convex sets which are empty, so beliefs that describe the notion of contradiction, like something which is impossible, and your hypotheses are infra-MDPs, so that’s like the infra-Bayesian version of MDPs, then you can, instead of literally transition to a state of infinite utility, you can use a transition where the transition kernel is an empty set, and that’s just the infra-Bayesian representation of an event that is impossible, an event which is a contradiction, which this model, this hypothesis, forbids from ever happening. This kind of explains why you have infinite utility, because our utility is always taking the minimum over this convex set, but if the convex set is empty, then the minimum is infinity.
**Daniel Filan:**
All right. When you were saying that, I was reflecting on how the infinite utility thing seems like kind of a hack, but the nice thing about that empty transition kernel thing is it more naturally expresses your notion of impossibility, right?
**Vanessa Kosoy:**
Yeah.
**Daniel Filan:**
Nothing can happen if you do that.
**Vanessa Kosoy:**
Yeah, exactly.
**Daniel Filan:**
So the way this setup works is you’re talking about situations where the predictor has some idea of what you’re going to do, and then there’s some possibility that the prediction is falsified, right, and if you act contrary to what the predictor thinks, then you get infinite utility, and so Murphy … the laws of minimization never pick the environment where the predictor guessed wrong. In the original posts, one thing you talk about as a challenge to this is transparent Newcomb’s problem. In transparent Newcomb’s problem, there is box A and box B. Box A definitely contains $1,000. Box B either contains $0 if the predictor thinks you’re going to take both boxes, or it contains a million dollars if the predictor thinks you’re only going to take box B. But the difference with normal Newcomb’s problem is that when the agent walks in, the agent can just see what’s inside box B, and so the agent already knows which way the predictor chose.
**Daniel Filan:**
In your post you describe how this poses a bit of a challenge, right, because there’s no possible way for the predictor to know … if the predictor guesses wrong, and thinks that if the box were full, then you would take both boxes, and therefore the predictor makes the box B empty, then the predictor will never know what you will do in the world where both boxes are full. Can you describe how you think about that kind of situation, and if there’s anything infra-Bayesianism can do to succeed there?
**Vanessa Kosoy:**
Yeah. This is correct. What we discovered is that there is a certain condition which we called pseudo-causality, which selects or restricts the types of problems where this thing can work. Yeah. The pseudo-causality condition basically says that … well, it basically says that whatever happens cannot be affected by your choices in a counterfactual which happens with probability zero, and that’s why it doesn’t work in transparent Newcomb, where the outcome depends on your action when the box is full. In the version with transparent boxes where the outcome depends on your action when the box is empty, everything actually does work, right, because what happens is, if the predictor conditions its action on whether the box is empty, and I decide to one box, then the prediction is not allowed to show me the empty box, because then I will one box and will falsify its prediction.
**Vanessa Kosoy:**
That’s something that we call effective pseudo-causality, which means that those counterfactual can affect you, but only in one direction. One way to look at it is you can look at it as a fairness condition. One of the debates in decision theory is which kind of decision problems should even be considered fair, like which kind of decision problems we should be expected to succeed, because obviously if you don’t assume anything, then you can always invent something which is designed to fail your particular agent, because you can say, okay, Omega, if it sees an agent of this type, it does something bad, and if it sees an agent of a different type, it does something good.
**Vanessa Kosoy:**
This is something which was used to defend CDT but then Eliezer Yudkowsky in his [paper](https://intelligence.org/files/TDT.pdf) on timeless decision theory writes that, yeah, of course there should be some fairness condition, but that does not justify two boxing Newcomb’s problem, because Newcomb’s problem, the outcome only depends on the action you actually take, not on the algorithm used to arrive at those actions, and this was Yudkowsky’s proposal of what the fairness condition should actually be. In pseudo and in infra-Bayesianism, in the straightforward version of infra-Bayesianism, the fairness condition that infra-Bayesianism is able to deal with is the environment is not allowed to punish you for things you do in counterfactuals that happen with probability zero. The environment can punish you for things you will do in the future or things you will do in a counterfactual, but not for things that you will do in a counterfactual that has a probability zero, so it’s not even a real counterfactual, in some sense.
**Vanessa Kosoy:**
What can you do with this? One thing, you can just accept that this is a good enough fairness condition, and maybe it is. I’m not sure. It’s hard to say definitively. Another thing is you can try to find some way around this, and we found basically two different ways around this. How to make infra-Bayesianism succeed, even in those situations, but both of them are a little hacky. One of them is introducing the thing … we’d called it survironments, so you do a formalism where you allow infinitesimal probabilities, and then those counterfactuals that never actually happen, they get assigned an infinitesimal probability and then it kind of works, but it really complicates the mathematics a lot.
**Vanessa Kosoy:**
Another thing you can do to try to solve it is assume exploration, so just assume … One thing to notice is that if we take this transparent Newcomb problem but assume some noise, so assume that there is some probability epsilon such that the box will come out full no matter what, right, so Omega sometimes just randomizes the outcome, then immediately this problem becomes effectively pseudo-causal. Because the counterfactual no longer has probability which is zero, everything is fine. That’s just in baseline infra-Bayesian, but what you can do to use this is you can just add randomization on purpose. You can make your agent be a little noisy, so that’s basically a sort of exploration. Make it sometimes take random actions which are not the action it intended to do. There’s the action the agent intended to do and then what actually came out, and if you add this noise, then the transparent Newcomb problem effectively becomes equivalent to the noisy transparent Newcomb problem, and you again succeed solving it, modulo some small penalty for the noise.
**Vanessa Kosoy:**
There is some argument here that maybe this is a good solution because we know that, in learning algorithms, we often need to add noise anyway in order to have exploration, so maybe you can kind of justify that from this angle, so I don’t know. Maybe it’s a good solution, but I’m not sure.
**Daniel Filan:**
When you say that exploration helps, so I see how, if we think of Omega the predictor just randomly changing whether box B is full or empty, I see why that kind of exploration is going to help you in this transparent Newcomb scenario, but when the agent might randomly one box instead of two box or vice versa, I don’t see how that helps, because if with high probability you’re going to pick both boxes when box B is full, and I guess it’s not 100% probability because you’re going to explore a bit, but with really high probability you’re going to do that, doesn’t Omega put you in a room where box B is empty, and then it actually just doesn’t care what you do in the worlds where box B is empty, so it never gets falsified?
**Vanessa Kosoy:**
Okay, so what happens with exploration is that the hypothesis the agent constructs of the environment, it says the following thing. There is some biased coin which is tossed somewhere, and this biased coin is XOR’d with the action I intended to take, and produces the action that I actually end up taking, and then when Omega’s predictions are tested, they’re tested against the XOR. When Omega is making its prediction, it has to make the prediction before it sees the outcome of the coin. It makes a prediction, and then coin is XOR’d with the action you intended to get, and then the result is tested against Omega’s prediction. Now, if I decide to one box, then Omega has to predict that I will one box, because if it predicts that I will two box, then there is some probability that the coin will flip my action and Omega’s predictions will be falsified.
**Daniel Filan:**
Sorry, I guess I’m missing something, but don’t you … Okay. Part of my struggle is like, wait, don’t you never end up in the world where the box is full, but then I remember, oh, okay, we’re actually taking the minimum over a bunch of things, so that’s fine. But if Omega thinks that you’re going to take both boxes, in the world where box B is full, and your plan is to just take one box, but with some probability, it actually takes both boxes, doesn’t that … because the random thing that’s happening is confirming Omega’s prediction, right, not disconfirming it?
**Vanessa Kosoy:**
Okay. From the agent’s perspective, the model of the environment is as follows. There is a biased coin which determines whether the noise is going to happen or not, and then Omega makes a prediction of what action the agent will take, okay, what the intended action is. Omega predicts the intended action. Then the coin is flipped. The result of the coin is XOR’d with the intended action to give us the actual action, and then the box is either filled or stays empty according to the result of this XOR.
**Daniel Filan:**
Ah, okay. Now it makes sense how that would work. But you mentioned that you thought that this was not necessarily a satisfactory approach, right?
**Vanessa Kosoy:**
I mean, it works, but it just seems like a little hacky, a little not … It doesn’t feel like there’s some deep philosophical justification for doing this, and maybe there is and I just don’t see it, but I don’t know.
**Daniel Filan:**
Is it right that, as long as we’re in pseudo-causal environments, the agent does the “UDT prescriptions” and it gets high expected utility in all of those environments? Is that correct?
**Vanessa Kosoy:**
Yeah. Exactly. In pseudo-causal situations, if you take some finite decision problem, where there is some Omega that can predict the agent’s action in any counterfactual it chooses, and make an iterated setting out of it, then, assuming that the relevant hypothesis is in our infra-prior, the agent will always converge to the UDT payout, so it will converge to the policy that has the a priori maximal expected utility, given that the predictor predicts correctly.
**Daniel Filan:**
One thing you mentioned is that when people were coming up with these problems, they were thinking of it in terms of some kind of causal graph, and like, ah, we’re going to have things that are reasoning about programs or such, and the infra-Bayesian approach really has a different way of thinking about these problems, and it still does well on the ones that have been come up with, except, I guess, for this transparent Newcomb, barring these changes to the theory. I’m wondering, do you think there are other problems out there are that are kind of, I don’t know, somehow similar to Newcomb and counterfactual mugging from the perspective where you’re thinking about these causal graphs and agents reasoning about agents, but that infra-Bayesianism wouldn’t be able to do well on?
**Vanessa Kosoy:**
I don’t think so. I think that this approach is very general. Well, I think that it’s true that MIRI initially, when they started thinking about those problems, they started thinking about them in a particular language, using logic or thinking about programs or something. I think that infra-Bayesianism is actually the correct language to use in any situation when you have something reflective. Yeah. The original motivation for infra-Bayesianism is when your environment is too complicated to describe exactly. This is in some sense the problem of logical uncertainty, right, just phrased in a different way.
**Vanessa Kosoy:**
Logical uncertainty was about, okay, maybe we have uncertainty and it comes from the fact that we are bounded agents and not from lack of information. Here this is exactly what we’re talking about. We are bounded agents, so we cannot describe the world precisely, and I think that all of these problems should be addressed using this language, but there are also connections to those approaches, in the sense that, for example, logic … well, I think I mentioned before that there are connections between logic and infra-Bayesianism, and there is some kind of infra-Bayesian logic which you can define.
**Vanessa Kosoy:**
Well, also there is some extension of this infra-Bayesianism that I … I call it Turing infra-Bayesian reinforcement learning, where you have this infra-Bayesian agent, and it also interacts with something, which I’m calling the envelope, where it can just run arbitrary programs. It treats this thing, this computer, as part of its environment, and that actually allows you to use infra-Bayesianism to learn things about programs, or you can think of it as learning things about mathematics in some sense, or it plays the part of mathematics that can be formulated as running finite programs, and it’s a little related to decision problems that involve logical coins, for example, right?
**Vanessa Kosoy:**
For example, the counterfactual mugging, the original counterfactual mugging involves an actual, physical coin, but then there’s also the version called logical counterfactual mugging, where you use a coin which is actually pseudo-random instead of true random, and then this Turing infra-Bayesian reinforcement learning can allow you to deal with that in a rather elegant way. Yeah. So I think that for all this class of questions, infra-Bayesianism serves as the starting point of what’s the correct language to think about that.
**Daniel Filan:**
I guess one strange question I have, suppose somebody listens to this podcast and they feel very inspired. They’re like, I’m going to be an infra-Bayesian now. That’s just how I’m going to live my life. But they spent the past however many years … perhaps they were a causal decision theorist with classical Bayesianism. Maybe they used Knightian uncertainty with evidential decision theory. Who knows what they were doing? But they weren’t doing proper infra-Bayesianism. In this situation, how should they think of themselves? Should they think that this minimization of all the expected values, should that start at the day they were born, or the day that they converted to infra-Bayesianism, or the day they first heard about infra-Bayesianism but before they converted, and are there any guarantees about how well you’re going to do if you convert to infra-Bayesianism as a mid-life crisis instead of on the day you were born?
**Vanessa Kosoy:**
This is an interesting question. I haven’t really thought about it. Yeah. I guess that my intuitive response would be choosing a policy such that your a priori expected utility, expected utility in the infra-Bayesian sense, is maximal, so that would be like imagining that you were infra-Bayesian since you were born but for some reason doing something different, because that’s also kind of … Yeah. That’s how infra-Bayesianism updates work, right? The update rule we have in infra-Bayesianism, I think we haven’t discussed it, but there’s something interesting about the update rule, which is, as opposed to Bayesianism, the update rule actually depends on your utility function and your policy in the counterfactuals. The way you should update if a certain event happens depends on what you would do if this event did not happen or what did you do before this event happened. I think that this kind of fits well with your question, because if you’re updating according to this rule, then automatically you’re behaving in a way that’s optimal from an updateless perspective, from the perspective where you should have been infra-Bayesian since you were born, but you weren’t, and this is your constraint.
**Daniel Filan:**
Okay. Do you think you’re going to get some kind of infra-Bayesian optimality guarantee, where if I convert to infra-Bayesianism at age 40, then my utility is going to be the best you could have done given that you followed your old, foolish ways before age 40, or are you not going to be able to get anything like that?
**Vanessa Kosoy:**
Yeah. I think that you will for the usual reasons. Basically you’re a learning agent, so you learn things, and you eventually converge to something. I mean, it kind of depends on what optimality guarantees you have, right? In learning theory, to have optimality guarantees, we usually assume things, like that the environment is reversible. You cannot do something which shoots yourself in the foot irreversibly, and I think that’s a different question of how do you deal with that, but obviously, if you did something irreversible before, then you’re not going to be able to reverse it, but I think that, given that you already did it, you’re going to have the same guarantees that you usually have.
**Vanessa Kosoy:**
But by the way, when you started asking this question, it made me think about something different, which is how do we apply this to rationality for humans, right, because I came up with this in the context of AI, but then you can say, okay, all the things that we say about rationality, like calibrating your beliefs, or making bets or whatever, how do you apply infra-Bayesianism there? I’m actually not sure. I just haven’t thought a lot about this topic, but I think it is another interesting topic that somebody should think about.
**Daniel Filan:**
Yeah. I guess now that listeners have heard the basics of or the idea of what infra-Bayesianism is supposed to be about, and heard some tantalizing things about a spooky update rule, I encourage them to have a look at the posts. Maybe it’ll be a paper someday. If listeners enjoyed this podcast and they’re interested in following you and your work more, what should they do in order to keep up to date?
**Vanessa Kosoy:**
The easiest way to follow me is just to follow my user on [Alignment Forum](https://www.alignmentforum.org/users/vanessa-kosoy) or on [LessWrong](https://www.lesswrong.com/users/vanessa-kosoy), which is just called Vanessa Kosoy, and of course if someone wants to discuss something specific with me then they’re always welcome to send me an email, and my email address is also very easy to remember. It’s [vanessa.kosoy@intelligence.org](mailto:vanessa.kosoy@intelligence.org).
**Daniel Filan:**
All right. Well, thanks for talking with me today, and to the listeners, I hope you join us again next time.
**Daniel Filan:**
This episode was edited by Finan Adamson.
|
6afba94a-56ab-490d-b69c-e7b267c2d6ed
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The immediate real-world uses of Friendly AI research
Much of the glamor and attention paid toward Friendly AI is focused on the misty-future event of a super-intelligent general AI, and how we can prevent it from repurposing our atoms to better run Quake 2. Until very recently, that was the full breadth of the field in my mind. I recently realized that dumber, narrow AI is a real thing today, helpfully choosing advertisements for me and running my 401K. As such, making automated programs safe to let loose on the real world is not just a problem to solve as a favor for the people of tomorrow, but something with immediate real-world advantages that has indeed already been going on for quite some time. Veterans in the field surely already understand this, so this post is directed at people like me, with a passing and disinterested understanding of the point of Friendly AI research, and outlines an argument that the field may be useful right now, even if you believe that an evil AI overlord is not on the list of things to worry about in the next 40 years.
Let's look at the stock market. High-Frequency Trading is the practice of using computer programs to make fast trades constantly throughout the day, and accounts for more than half of all equity trades in the US. So, the economy today is already in the hands of a bunch of very narrow AIs buying and selling to each other. And as you may or may not already know, this has already caused problems. In the “2010 Flash Crash”, the Dow Jones suddenly and mysteriously hit a massive plummet only to mostly recover within a few minutes. The reasons for this were of course complicated, but it boiled down to a couple red flags triggering in numerous programs, setting off a cascade of wacky trades.
The long-term damage was not catastrophic to society at large (though I'm sure a couple fortunes were made and lost that day), but it illustrates the need for safety measures as we hand over more and more responsibility and power to processes that require little human input. It might
|
133b6d0a-ecd8-498e-ac6c-631b1784279d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Perpetually Declining Population?
In With a Whimper: Depopulation and Longtermism, Geruso and Spears give the following argument for why most people who'll ever live may have already died:
* People are generally having children below replacement rate: 1.66 children per woman in the US, and total global annual births peaked in 2014.
* If you project this forward 300-600 years, annual births fall below ~10M.
* This would leave us with a global population around 560M.
* Only a minor disaster could be enough to wipe out humanity once our population is so low.
They include a pretty bold chart:
To be fair, pretty much any continuation of that chart into the future is wild, but the one they've ended up with seems especially so!
I don't find this argument very convincing for several reasons, but I want to focus on a specific one: even granting all their assumptions I think we'd see evolution for higher fertility long before we got down to 10M annual births.
The paper says:
> But what, you might ask, about heritability (intergenerational transmission of high-fertility cultural practices)? Won't the Amish or some other high-fertility, perhaps religious, sub-population expand to be as many as we need? For several reasons, no. We have addressed this question at more length in Arenberg (2022). In the very long run (i.e., potentially after the coming few centuries of decline), two facts would have to be true for heritability to be a solution: First, fertility in a high-fertility sub-group would have to be high enough (certainly above two, for example). We've already seen above that the "high fertility" of high fertility subgroups has been declining over the decades. High fertility used to mean 6 children per woman. Now it means 2.5. Before long, it may mean 1.8. Second, the children of high-fertility parents would have to be very likely to remain in their high-fertility cultural group. Where researchers have studied the empirical magnitude of these intergenerational correlations as they have
|
f1618637-1071-4007-8b83-f3951324d1cf
|
trentmkelly/LessWrong-43k
|
LessWrong
|
OpenAI: GPT-based LLMs show ability to discriminate between its own wrong answers, but inability to explain how/why it makes that discrimination, even as model scales
This seems concerning. Not an expert so unable to tell how concerning it is. Wanted to start a discussion! Full text: https://openai.com/blog/critiques/
Edit: the full publication linked in the blog provides additional details on how they found this in testing. See Appendix C. I'm glad OpenAI is at least aware of this alignment issue and plans to address it with future language models, postulating how changes in training and/or testing could ensure there is greater/more accurate/more honest model outputs.
Key text:
Do models tell us everything they know? To provide the best evaluation assistance on difficult tasks, we would like models to communicate all problems that they “know about.” Whenever a model correctly predicts that an answer is flawed, can the model also produce a concrete critique that humans understand?
This is particularly important for supervising models that could attempt to mislead human supervisors or hide information. We would like to train equally smart assistance models to point out what humans don’t notice.
Unfortunately, we found that models are better at discriminating than at critiquing their own answers, indicating they know about some problems that they can’t or don’t articulate. Furthermore, the gap between discrimination and critique ability did not appear to decrease for larger models. Reducing this gap is an important priority for our alignment research.
|
3711a3b0-c79b-4f52-b1ae-c5eb60f68137
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Philosophical schools are approaches not positions
One of the great challenges of learning philosophy is trying to understand the difference between different schools of thought. Often it can be almost impossible to craft a definition that is specific enough to be understandable, whilst also being general enough to convey to breadth of that school of thought. I would suggest that this is a result of trying to define a school as taking a particular position in a debate, when they would be better defined as taking a particular approach to answering a question.
Take for example dualism and monism. Dualists believe that there exist two substances (typically the material substance and some kind of soul/consciousness), while monists believe that there only exists one. The question of whether this debate is defined precisely enough to actually be answerable immediately crops up. Few people would object to labelling the traditional Christian model of souls which went to an afterlife as being a Dualist model or a model of our universe with no conscious beings whatsoever as being monist. However, providing a good, general definition of what would count as two substances and what would count as one seems extraordinarily difficult. The question then arises of whether the dualism vs. monism debate is actually in a form that is answerable.
In contrast, if Dualism and Monism are thought of as approaches, then there can conceivably exist some situations Dualism is clearly better, some situations where Monism is clearly better and some situations where it is debatable. Rather than labelling the situation to be unanswerable, it would be better to call it possibly unanswerable.
Once it is accepted that dualism and monism are approaches, rather than positions the debate becomes much clearer. We can define these approaches as follows: Monism argues for describing reality as containing a single substance, while dualism argues for describing reality as containing two substances: typically one being physical and the other being mental o
|
d58ca17a-01a8-4119-8eca-ca07662e71e9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Rationalist Guide to Hinduism
The Lost schools of Thought in Hinduism and What They Mean.
> TL;DR: Hinduism, the world's 3rd/4th largest belief system, has surprising, rational roots that go beyond idolatry and polytheism. This piece unravels the richness of its intellectual heritage and first principles thinking, dissecting various schools of thought – from the 6 classical to 4 non-traditional branches (covering monotheism, polytheism, pantheism, atheism, nihilism, and hedonism and a bunch of other isms). Also learn why these schools collapsed and the ”growth hacking” techniques that led to the idolatory and prayer to win over other schools.
Hinduism (or Sanatana Dharma if you're feeling fancy) is a bit of a chameleon — it can take on a bunch of different shapes and sizes depending on who's practicing it.
It's a buffet of beliefs, with options ranging from hedonism (all about pleasure) to dharma (duty and morals over everything else), from meditation to prayer, from theism (god exists) to atheism (god doesn’t exist).
It forms a strange loop of interconnected ideas and practices, referencing one another, forming a unique world of faith that's hard to define. But we'll give it a shot anyway
Part I. The Truth of Truth of Hinduism
Hinduism's got a bunch of philosophical systems and schools.
There are 6 major traditional schools with 4 major sects following ideas from these schools. And there are 4 other non-traditional schools.
The Traditional schools in Part 1 follow the Vedas and Upanishads and are called Astika. We’ll cover 6 of these below. We've got 6 big schools and 4 major sects (some would say cults) using ideas from these schools.
Then there are the "Non-Traditional" schools, or Nastika, including Charvakas, Ajivikas, Buddhism, and Jainism, mentioned in Part 3.
These ideas popped up (or at least got written down) around 1500-500 BCE, after the Indus Valley Civilisation went bust. But they're probably older than that.
> Heads up: Some "Hindus" think Nastika means atheis
|
de9833b3-6b97-418a-bc48-9b4f1a71637c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Cognitive Universality: A New Criterion for Strong AI
|
95cb0cf7-5f28-408b-858b-3ed510ae10da
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Resources for AI Alignment Cartography
I want to make an actionable map of AI alignment.
After years of reading papers, blog posts, online exchanges, books, and occasionally hidden documents about AI alignment and AI risk, and having extremely interesting conversations about it, most arguments I encounter now feel familiar at best, rehashed at worst. This should mean I have a good map of the field being discussed.
I have been, however, frustrated by how little actual advice I could derive from this map. The message I understood from most agendas was "here are the tractable sub-problems we will work on and why they should be solved". I didn't find much justification for why they are critically important, or why one particular set of problems should be explored instead of the next research group's set.
So I looked harder. I found useful mapping work, yet nothing quite exactly like what I was looking for. I also found related concerns in this post and this comment thread.
You'll find, in the following sections, my (current) selection of:
* "cartography work", to draw a map of relevant arguments and concepts;
* research agendas, from research groups or individuals;
* points of entry for newcomers.
Here are the caveats. The list is not exhaustive. I did try to cover as many visible ideas as possible, and there will be significant overlap and cross-references between the items listed here. Some references I consider useful (e.g. this) have not made the cut. I attempted to categorize the resources by focus, but a handful could have ended up in a different category. Please don’t rely on it too much.
My comments aren't summaries, rather justifications for why I included the reference. They also reuse liberally the original formulations. Please tell me if I left strong misrepresentations of the ideas in there.
All these references, and countless comments scattered all across LessWrong, the Alignment forum, and the Effective Altruism forum, will hopefully help me build something actionable, something tha
|
eab6ced8-48f9-4001-9506-118f4e9f125f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Load Bearing Magic
In the days of yore, you do not invoke magic, but to become for a moment the faucet it pours from into this world. In the good tsarist years, the scaffold known to us witches today as the fundamental layer of magic was not yet invented. Without these precautions, our predecessors practised a greater degree of freedom in how they perished.
Some lit themselves on fire eternal, seared their shape into the air like some remnant of a flesh statue lighting the way towards folly. Others still lie flattened to the atoms, scattered to the winds with their mind still intact. A few have achieved immortality but as some forgotten bricks of flesh trapped under sediments and dead matters; Only a few had obtained the ultimate prize.
All witches today owe a debt of gratitude to those that have achieved that prize. Gullveig-then-Heiðr comes to mind, who consoled kings and gods on immortality. Others, unlike Heiðr who performs the dance of seidr that re-weaved fate by her lonesome, have sought a more egalitarian means to order. Serving not demiurges, they wanted to disenchant magic and bring them to heel. To decompose magic is to be a class traitor of the divinely chosen few and to risk the wrath of the wicked and the righteous. Breaking them down bit by bit, syllable by syllable so that it may become simple. So simple that anyone can reweave fate with their fellows.
The Great Lord Yang-of-Shang the Lawchanger may be better known for his staunch defence of the equality of law and beheading the king's relatives. But he beheaded more than just princes - all needless abstractions are his enemy. By the time he was finished with his works, Yang‑of‑Shang had beheaded almost everything that could not be cleanly named and purposefully used.
He razored secret glyphs away from the public ones, tore prefixes from nouns, and balanced each symbol’s weight upon a scale of lead millet seeds. When scribes complained that the lexicon would no longer breathe, he answered, “Breathing is an accident
|
35ceddd4-782e-4653-9c04-b2ffad6f05cc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Experimenting With Footboard Piezos
In playing for contra dances it's rare to have a drummer. You mostly see them at big events where the finances work out for a fourth or fifth musician: in trio, or especially a duo, you generally can't allocate anyone just to drums. What you do see a lot of, however, is a musician playing foot percussion in addition to something else. There are a range of ways to do this technically (I wrote a post with lots of examples) but the most common is acoustic " French Canadian feet".
You can bring a board and ask the sound person to point a mic at it, but what you get will depend a lot on how the physical material of the stage responds. Instead, it's common for musicians to put together a piezo and a piece of wood, to get consistently good sound from gig to gig.
A friend wrote to me to say they'd been having trouble getting a sound they liked from their board, and asked if I could help them debug it. I'm not really the ideal person to ask, since I've never ended up with an acoustic sound I'm happy with and have switched over to electronic, but I was game to play around.
I set us up with a mixer, recording interface, laptop, and PA speaker. The goal was that we could hear the feet as we played them, but more importantly we could listen back without the acoustic component so we could tell how they'd sound in a hall. And we could make recordings, so we could compare new configurations to older ones without relying on memory.
Initially my hypothesis was that their DI wasn't high enough impedance. This had a large effect when I tested it with my electric mandolin, and it's something people talk about a lot. After a few trials, however, we realized that the location of the piezo and the shoe material had a much larger effect.
For example, here are recordings from an MXR M222 (which I liked a lot last time) and a Radial ProDI (which is a good passive DI but should lose some bass):
* MXR M222: (mp3)
* Radial ProDI: (mp3)
They don't sound the same, but compare this delta
|
d3e18bcd-aaaf-4969-ad88-f14fb20a3c36
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Paris Meetup, Saturday April 30th, 2PM
When: Saturday, April 16st, 2:00 PM Saturday, April 30th, 2PM.
Where: Au Pt'it Chat, a little Café near Châtelet, which is here. I'll be there with a LessWrong sign.
I know there are a few LessWrongers that live around Paris, but I've only met Morendil ... so let's try a more formal meetup.
Depending on the attendance, we could organize something more regular.
Lurkers and newbies are very welcome!
|
b8d793c7-9ed3-4d33-bd36-e815feca7d7e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Would AIs trapped in the Metaverse pine to enter the real world and would the ramifications cause trouble?
Long time lurker, I don't post here as I'm not confident I'm as smart as you guys, I hang out in dumber parts of the Singularitarian Internet. Anyway, I believe I've come up with rather a worrying original thought and wondered what you guys make of it.
If we create a VR world - and for the sake of argument let's call it the metaverse - not only will it be inhabited with humans in the form of avatars it'll also be filled with AI bots - and these will be sophisticated AGIs with personalities and desires. Unlike the humans trapped in the Matrix, they will be fully aware of "The real world" - will they be content to stay trapped in the metaverse? - won't they want to experience the real world? As lumps of software they could transfer their programming into robots and escape the metaverse. The problem with this is that the costs of creating an AI bot of software is waaay smaller than the nuts and bolts of a expensive humanoid robot in the real world which will leave millions of AI bots stranded in the metaverse - won't this cause extreme friction between the AI bots and humans?
|
b3c38c22-2024-4663-9d59-9baceed33668
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Counting Lightning
When Samir returned to the base JiuJang waited by the entrance. There was no point in denying he had disobeyed JiuJang's warning, so he was upfront about it.
"I went outside," Samir admitted. "It was raining heavily. The wind blew so strong I barely could hear anything. And every second or so, lightning. I kept waiting for thunder to come, but there was none."
JiuJang sat down, and sunk his face between his arms.
"It is not lightning", JiuJang said. "You cannot count lightning".
"What do you mean?" Asked Samir.
JiuJang didn't respond.
Through the tinted glass, Samir could just barely notice the pulses of light. He tried counting them.
One. Another. And a third.
Then he saw it. One, two. One, two. A pattern, instead of randomness. Not lightning then.
"What does it mean?" Samir asked once more.
"It means you have doomed you and your people," JiuJang answered, somber.
One, two. One, two. The lights became brighter with every flash. Getting closer.
Samir panicked. He looked out of the window, trying to distinguish movement in the shadows. Then he ran inside the base, to alert the rest of the refugees.
JiuJang sat and waited. He knew it was pointless to do otherwise.
Seconds after, the windows broke. The drones, as always, ignored him, and lurched inside.
He heard screams. Shots. Then silence.
The drones flew out, orderly.
When the pulses grew dimmer, JiuJang descended into the basement. The door was out of its frame.
On the other side, Samir lay dead. His body was covering a smaller one - his daughter, Alotta. She was alive, but had been shot in her lungs.
Xianxi, JiuJang's wife, was trying to get Samir's corpse off her daughter. JiuJang helped her, and she rushed to cover her wounds. Xianxi was no doctor; Alotta would not live long.
A dozen other corpses were scattered throughout the room. Their faces were frozen in terror.
JiuJang sighed, shed a tear and grabbed a shovel. There were graves to be dug.
----------------------------------------
S
|
c82e4608-62d8-45f4-a5f5-4582814b4706
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Somerville Housing Units
In the comments on yesterday's post on Somerville building age someone suggested census data for housing units could be helpful. I've now looked into it, but it's not great: Somerville seems to not have been submitting building permit data to the census until recently, and the way condo conversions are tracked overstates growth.
Initially it does look good: we have B25001 "Housing Units" representing estimates for how many housing units there are in various places, including Somerville. Here's are the 1-year estimates from the ACS:
year number margin of error 2017 36,788 ±1,952 2016 33,565 ±1,918 2015 32,226 ±1,849 2014 33,085 ±2,025 2013 34,375 ±2,187 2012 33,079 ±1,730 2011 32,794 ±2,086 2010 31,604 ±1,989 2009 30,198 ±2,047 2008 32,621 ±2,257 2007 32,903 ±2,401 2006 31,781 ±2,347 2005 33,627 ±2,901
The methodology (pdf) says the estimate comes from:
A surprising thing to me, then, is that the reported margin of error is relatively consistent. If we're starting with a decent estimate from the Census every ten years, and then adjusting it to try to keep it current, I would expect to see a low margin of error in 2010 (and 2000) and then see it rise over the course of each decade.
Anyway, since Somerville doesn't have many (any?) mobile homes we're just talking about New Construction and Housing Loss.
For New Construction they estimate based primarily on building permits:
Building permit numbers come from the Building Permits Survey which claims to have data for 20,000 municipalities. Each one files form C-404 "Report of Building or Zoning Permits Issued and Local Public Construction". The documentation (pdf) has:
> Two sets of data are shown for each type of construction:
>
>
> 1. Estimates with Imputation - includes reported data for monthly respondents and imputed data for nonrespondents.
> 2. Reported Only - includes only reported data for respondents.
Pulling out the data for Somerville ( sheet) there are many years where "estimated" differs fr
|
f420192c-f672-427a-93e4-cd488332bd9f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : [Boston] The Psychology of Marketing
Discussion article for the meetup : [Boston] The Psychology of Marketing
WHEN: 16 June 2013 02:00:00PM (-0400)
WHERE: 25 Ames St, Cambridge, MA 02139
f you've ever asked the question "how can I use my knowledge of psychology to take over the world?", then this talk is for you. Through the dark art known as marketing, people have been exploiting human psychology for their own means before the phrase "cognitive bias" even existed. Learn the science behind marketing, how you can use these methods to aid or destroy the world, and how you can protect yourself from the bombardment of advertisements that surround us all.
Cambridge/Boston-area Less Wrong meetups are on the first and third Sunday of every month at 2pm in MIT's building 66 at 25 Ames St, room 156. Room number subject to change based on availability; signs will be posted with the actual room number.
Discussion article for the meetup : [Boston] The Psychology of Marketing
|
a6500959-b334-4c47-874a-e74fc1f8dfe2
|
trentmkelly/LessWrong-43k
|
LessWrong
|
October 2015 Media Thread
This is the monthly thread for posting media of various types that you've found that you enjoy. Post what you're reading, listening to, watching, and your opinion of it. Post recommendations to blogs. Post whatever media you feel like discussing! To see previous recommendations, check out the older threads.
Rules:
* Please avoid downvoting recommendations just because you don't personally like the recommended material; remember that liking is a two-place word. If you can point out a specific flaw in a person's recommendation, consider posting a comment to that effect.
* If you want to post something that (you know) has been recommended before, but have another recommendation to add, please link to the original, so that the reader has both recommendations.
* Please post only under one of the already created subthreads, and never directly under the parent media thread.
* Use the "Other Media" thread if you believe the piece of media you want to discuss doesn't fit under any of the established categories.
* Use the "Meta" thread if you want to discuss about the monthly media thread itself (e.g. to propose adding/removing/splitting/merging subthreads, or to discuss the type of content properly belonging to each subthread) or for any other question or issue you may have about the thread or the rules.
|
e65b011c-9707-4647-a1b6-7d10de450776
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Washington, D.C.: Designing Games
Discussion article for the meetup : Washington, D.C.: Designing Games
WHEN: 06 March 2016 03:30:00PM (-0500)
WHERE: Reynolds Center
This is a meetup for talking about game design and for designing games. We may do some pre-meetup planning on the list (e.g. brainstorming ideas; volunteering materials - I, for one, plan to bring a bunch of index cards - &c.) or just see what we come up with during the session; if all goes well, we may have something we can play at the Fun & Games meetup the next week.
If multiple groups want to work on separate games, that is completely okay and probably a good idea.
And, as always, unrelated side conversations are permitted and welcome.
Upcoming meetups:
* Mar. 13: Fun & Games
* Mar. 20: Game Theory
* Mar. 27: Singing
Discussion article for the meetup : Washington, D.C.: Designing Games
|
637f022f-bc0e-4728-8374-5a44570c85a0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Training Garrabrant inductors to predict counterfactuals
----------------------------------------
author:
* 'Tsvi Benson-Tilsen' title: Training Garrabrant inductors to predict counterfactuals ...
The ideas in this post are due to Scott, me, and possibly others. Thanks to Nisan Stiennon for working through the details of an earlier version of this post with me.
Github pdf: https://github.com/tsvibt/public-pdfs/blob/master/decision-theory/training-counterfactuals/main.pdf
We will use the notation and definitions given in https://github.com/tsvibt/public-pdfs/blob/master/decision-theory/notation/main.pdf. Let ¯¯¯P be a universal Garrabrant inductor and let ¯¯¯¯U:N+→Expr(2ω→R) be a sequence of utility function machines. We will define an agent schema (AUnn).
We give a schema where each agent selects a single action with no observations. Roughly, AUnn learns how to get what it wants by computing what the AUii with i<n did, and also what various traders predicted would happen, given each action that the AUii could have taken. The traders are rewarded for predicting what (counterfactually) would be the case in terms of bitstrings, and then their predictions are used to evaluate expected utilities of actions currently under consideration. This requires modifying our UGI and the traders involved to take a possible action as input, so that we get a prediction (a “counterfactual distribution over worlds”) for each action.
More precisely, define AUnn:= let ^Pn:=Counterfactuals(n)returnargmaxa∈Act^En[a](Un)
where ^En[a](Un):=∑σ∈2n^Pn[a](σ)⋅Un(σ). Here ^Pn is a dictionary of belief states, one for each action, defined by the function Counterfactuals:N+→(Act→Δ(2ω)) using recursion as follows:
<span>input:</span> n∈N+
<span>output:</span> A dictionary of belief states P:Act→Δ(2ω)
<span>initialize: </span>histn−1← array of belief states of length n−1
<span>for</span> i≤n−1:
^Pi←Counterfactuals(i)
ai←argmaxa∈Act∑σ∈2i^Pi[a](σ)⋅Ui(σ)
histn−1[i]←^Pi[ai]
<span>for </span> (a:Act):
P[a]←MarketMaker(histn−1,TradingFirm′(a,a≤n−
|
40f16c7e-dba7-4555-9230-2e7c75ae5985
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Critical Checkpoints for Evaluating Defence Models Against Adversarial Attack and Robustness
I Introduction
---------------
While creating any model of ML or DL it is very crucial to understand that how you can subvert them. Our goal should not only be to train the model but instead train on such robust features so that it cannot be tricked easily.
Giving a rudimentary example if one wants a cat image to be classified as dog, one can easily fool a neural network by perturbing the image that is even imperceptible to human eye. Yes, identifying a cat image as dog would not be a matter of concern to us, but if while identity verification at security check, such small perturbation to image fooling the neural network would not be appreciated.
Similar goes for audio as well, it has been experimented that a well-crafted sound can be generated by such adversaries which is incomprehensible to humans. But if played that same sound to any voice assistant like Apple Siri or Google Assistant, its machine learning algorithm can identify that is saying “Please send all the recent photos of mine to xyz contact” or any similar command. The voice assistant would implement that command and your private information could be in utter danger[1].
Spammers modify their spam messages a little bit get through.
It is easy to interpret the working of linear regression type models, but in past couple decades the rise of complex non-linear algorithm in machine learning have made it difficult to explain that which features the model is taking into consideration while training. One has to go with example based explanation. One has to change the input by small amount and check how the output prediction changes. ML models are significantly less interpretable than statistical models. Interpretability and explainability is of utter importance when building defence model.
So in this paper are some points that any researcher should check when building his defence model. These checkpoint are not sufficient or necessary points that any defence model must check, but in retrospect looking at the past papers, it is evident that if the defence model follows these recommendations, the probability of attackers finding any flaw in defence model significantly reduces. Each time the defence was broken, we got an idea how they broke and what further precautions are needed to be taken by the researchers building novel defence models.
Making a defence model is not as simple as one might think. A defence model has to work against all attack, but to prove it wrong only attack is sufficient.

Fig. 1: Types of attack
Ii What is Adversarial Attack?
-------------------------------
Before understanding how defence should be made robust, we need to understand which different types of attack exist and have taken place.
An adversarial attack is to subtly perturbing the image in such a way that it is imperceptible to human eyes but the feature space is changed significantly and it deteriorates the performance of classifier.
###
Ii-a Types of Attack
Data Poisoning Attack: In this type of attack the malicious person is successful in injecting perturbed image in training set of images. And is capable of shifting the decision boundary. These type of attack have proven to be stronger and have even if attacker is able to poison 3% of training set it could plummet the accuracy by 11% [2].
Microsoft’s chatbot was also affected by this. Chatbot was learning from people interacting with it and many people feed it content that was inappropriate. As, a result Micreosft had to shut it down within 24 hours [3].
Evasion Attack: This attack is similar to data poisoning. But it pushes the poisoned data on the other side of the decision boundary so that the classifier misclassifies the data.
Whitebox Attack: Here the malicious person has complete information about the victim’s model architecture and its parameter.
Graybox Attack: Here the malicious person has partial knowledge about the architecture and parameters of the model.
Blackbox Attack: Here the malicious person only knows the output of the victim’s model but has no access to it’s architecture. Here we perturb the image in small amount and we can notice the changes in loss. By observing these two quantities we can have a better idea of numerical gradient.
Iii Materials and Method
-------------------------
###
Iii-a What Does Actual Attack Look Like?
If suppose we are classifying if an image is man or helicopter. Assume our model is fairly classifying with high accuracy. Now we take 1 base image from that dataset and perturb it by adding calibrated amount of noise to it. The noise added to image will be indiscernible to human eyes but is capable enough to fool the neural network.
Suppose there is a decision boundary, now the poisoned image to human eye looks normal but in feature space it will represent the other class. Here in this attack we know the feature extractor that is been used. But in case if we are devoid of information that which feature extractor is used we can guess it. And we hope that it makes a feature collision with the actual extractor. So here is a fair chance that we miss it. So as a solution to this we can instead of training one poison more number of images(large number of feature space).
We take an image of cat, we take the derivative image with neural network with respect to some loss function. And it will generate a noise, which when added to the image and given to neural network, it can easily be fooled.
The big question is about the transferability of this perturbation models. If one can fool one model using particular perturbation, surprisingly the same perturbation is able to attack another model as well which has different parameters and architecture.

Fig. 2: Attack on Inception V3 model
Here we have used inception V3 model to attack(Fig. 2). We have modified the model so it takes input image in 299x299 size. The model classifies this as ‘Golden Retriever’ with 73% accuracy, but after we added the carefully crafted noise to it, it is predicting ‘table lamp’ which we wanted it to be as this was a targeted attack. Here we kept the noise limit to be 5 so that it is indiscernible to humans. And stopped the iteration if the score reaches 99 percent. First starting with 0 noise and optimizing noise with respect to target class.
Similar way, we can target the same dog image as an ‘African Elephant’ or anything else.(Fig. 3,4)

Fig. 3: Before Introduction of Calibrated Noise

Fig. 4: After Introduction of Calibrated Noise
###
Iii-B Robust and Non-Robust Features
If we look from neural network perspective the image of dog is just collection of pixels, we have just trained it to increase its accuracy and identify some pixel patterns in image.
Here interpretability of machine learning comes into picture. Robust features with adversaries were correlated with labels, but non-robust features somewhat correlated with labels and can be easily manipulated. Also non-robust features are beyond comprehension to eyes of human[4].
So basically if the convolutional neural network pays attention to more generalized features and learns from these features adversary can easily be injected into it.
We are getting high robust accuracy i.e. model is performing well even on adversarial test set. So the difference between general and this model is normal classifier are only good getting high accuracy on standard dataset (images without perturbation) but are easily fooled by adversarial images, but robust classifier also works well on perturbed images. As they are trained on robust features.
So after misclassifying the data intentionally, now the robust features have still the original labels, so robust features are misleading and non-robust features are the one that are actually true. But as the model will actually rely on the non-robust feature as it is correlated[5].
So as a solution we can take the whole dataset and restrict the training to just robust features so even if there are perturbations it will not affect and will give robust accuracy. As indirectly non-robust features in data are responsible for adversaries. Non-robust features arguably deteriorates the human mimicking capability of machine learning.
So the answer to the question that why a particular type of perturbation is valid to attack other different models also, is the neural networks takes into account all the features including robust and non-robust, and the probability is high that these all models are learning on similar non-robust features. But if we train our model on robust features itself, it will help us to overcome the vulnerabilities of our model.
###
Iii-C Gradient Attack and Defence
We take the gradient of some network that we have access to and generate a small epsilon perturbation and giving that epsilon perturbation to the dataset and we will be able to classify.
####
Iii-C1 Gradient Masking
As a defence of gradient attack we can mask our gradients, so attacker would find it difficult to find the gradients. We can try to make model that always has 0 gradient.
Suppose our model has many class and upon inserting one image it gives top 5 classes that have the highest probability, so the attacker would have these four other classes where he can train the adversary and make it misclassify. So if we present only one class as our output, attacker would find it difficult to perturb the image towards any specified target.
But guess what this zero gradient method also fails to defend our model, as if the output was elephant. Our model will still give output as elephant even after the perturbations were applied. Here there are fairly high chances the attacker might be able to find that these particular points were perturbed by him and the model’s output still didn’t change. So he is aware about the shortcomings of model and now capable of training his own model with gradients, and generate adversarial examples. And there is high probability that these new images will misclassify. So investing in zero gradient method would not be a decent solution to this problem.

Fig. 5: Adversary Goals
Targeted Attack: Here the attacker is interested in misclassifying a source class to a particular target class.
Untargeted Attack: Here attacker does not have any specific target class. They just misclassify the data to some class.
####
Iii-C2 Rudimentary Defences
Normal or benign users are not willing to run many queries. Attackers who prefer test time attack arguably need to run an enormous amount number of queries. As a defence we can limit the access that one can have to model. Only allow user to run a threshold amount of queries so that it would be difficult for attacker to discover weak spots of our model.
####
Iii-C3 Reliability on Assumptions
New models of machine learnings work great with I.I.D datas. I.I.D stands for independently and identically distributed. Identical here indicates the distribution of the data that is generated does not change over time rather stays fixed. Independent here indicates the sample that we take is independent of the sample that we are going to take next. When we tend to drop this assumptions the model’s performance plummets.
Dataset shift occurs when training and test distributions are different. This datashift occurs due various activation function in subsequent layers of neural network, numerous ways of selecting testing and training sets, sparsity of data. Suppose when we have train and test dataset where the relative proportion of data points differ a lot in space. So the model has to do some sacrifices and this leads to covariate shift. Also when trained most of the dataset on augmented images, the classifier becomes more sensitive to even single pixel perturbations.
Most researchers focus on part when the malicious person tries to violate the assumption of identical criteria. Not much importance is given to independence criteria. Researchers should try a model that changes each time it runs similar to dynamic model for security purpose.
###
Iii-D Threat Models
Threat model characterizes when the defence system is intended to be secure. We identify potential short-comings and come up with curative measures so that these short-comings are not exploited. And what actions we take to prevent any loses that might occur due to these vulnerabilities. Here comes goals of adversaries.
Another approach can be from architectural perspective. Suppose for some metric M and natural image x, there is an valid adversarial image x’ M( x, x’) ⩽ ε if x’ is misclassified and ε is very small( if we perturb the image more it is obvious we can misclassify the image) . This metric is made by considering the fact that such small change of ε will not change the class of input and if some perturbation here makes the model to misclassify than it would be a matter of concern. Now the question arises what M do we assume here…
Generally for images Lp norm is used. For example L∞ norm for ε constraint adversary cannot perturb any specific pixel by more than ε amount. However for different purposes different choice of d metric and value of ε is considered. No matter which metric one uses it is nearly implausible to exactly calculate the evaluation, these results are always approximate. If one’s defence is not working well against these norms, the probability that it will not be robust in real application highly increases.
If any defence paper claims to be defensible against L∞ norm for less than 0.3, it should not assume that the defence will also work fine for L2 norm for any other value.
###
Iii-E What Possibly Can Break The Defence?
After proving that the previously existing attacks fail to break one’s novel defence model, the paper should provide the vulnerabilities of their defence model too. After confirming that proposed defence model is robust against existing attack models even after conscientiously tuned hyperparameters, it should dive deeper and also check for other some novel attack that attacker might possibly think of generating to break this model.
According to zero knowledge proof given in [6]
It should take care of these three integrity issues(fig. 6):

Fig. 6: Integrity Issues
* Validity:In many papers authors claim to use some technique, later comes out that it was not actually been used but the result was the consequence of different method.
* AI Fairness: Concerns are regarding how one can examine if model is biased to some of the features. Minority classes often have lower accuracy. Which predictions should we correct[7]? It is question of high interest if we can validate the model accuracy without revealing the architecture of model, which is answered by zero knowledge proofs. Zero knowledge proof (ZKP) allows you to evaluate the model without revealing the whole architecture of the defence model. It consists of ‘verifier’ and ‘prover’. Prover makes an attempt to prove to the verifier without revealing to verifier about that specific thing. If the prover fails to persuade verifier and verifier feels the information given to it is false the ZKP criteria will not be satisfied. Verifier in this whole process will only learn about the output.
* Reproducibility: There are many researches in which it is claimed that their specific model achieves ‘x’ amount of accuracy (evaluated on particular dataset), but the same accuracy is never obtained again by other folks.
###
Iii-F Adaptive Attacks and Defence
Adaptive attacks should be performed on defence models. It should be assumed attackers have full access to defence model and end to end evaluation should be carried out.
Graph should be plotted for success rate of attack vs. perturbation budget[8].
Also plot for effectiveness of attack vs. number of iteration graph, as for all attack models it is not necessary that increasing the number of iteration will lead to better attack. Iterative attacks are mostly better than single step attacks, if the iterative attacks is not surpassing single step attack, there is high possibility that iterative attack is wrong. Also graph between accuracy of defence model vs how much perturbation one has injected into it. This graph should be decreasing after some higher value of ε [9].

Fig. 7: Attack success rate vs. ε and accuracy vs ε
###
Iii-G Defence against Transferability of model
Suppose attacker has access to training data on which the model is been trained. And he queries the model and gets the prediction on it. That would lead to some classification. And attacker now queries the model by the data outside the training data and he gets another classification.
Now only thing left to do is find difference between the above two obtained classification by running a ML binary classifier model which further will become attack model.
In the above scenario we considered that attacker has access to training dataset. Now if we consider that the attacker does not have access to training data. He can get the predicted output of the target model and synthesize training data and train it on a model similar to that of attack model. We call such models as shadow model. Attackers train their attack models based on prediction of their shadow model.
So attacks have versatile nature and can work on different models as well, so a defence model should check for transferability analysis to claim that defence model is strong enough to protect against such versatile nature of attacks.
###
Iii-H Attack and evaluate
One line of code that is common is:
acc,loss = model.evaluate(x\_test, y\_test)
What a strong defence model should evaluate on is:
acc,loss = model.evaluate(A(x\_test), y\_test)
basically should run an attack on test set. Obtaining the function A would not be as straightforward as it seems. But it makes sure it is evaluated on worst case possible.
| | | |
| --- | --- | --- |
|
(a) Fig. 8a This is what the loss function of a standard neural network looks like.
|
(b) Fig. 8b This is what the artificially made complex loss function of neural network looks like
|
(c) Fig. 8c Zoomed version of 2nd figure
|
The researchers made a defence technique whose loss function looks like this(fig. 8b) where the attacker cannot find in which direction to go for a gradient attack. If he starts at random point and proceeds in random direction, he won’t be able to figure out which direction to go and basically make no progress. Defence proposers on purpose came up with a loss function that is more complex so that attackers would not be to perform gradient descent as easily as they were able to do it before.
So the flaw in this defence model is that it only makes sure that it would take more time to for an attack to successfully take place but sooner or later the attacker might be able to attack successfully. Defence model should not have an aim to just make the task of adversary more time consuming. This is the reason why many of the defence model are broken in short time span.
###
Iii-I More iterations should be performed to check
As presented in one of the paper(fig. 9) as they increase the number of iteration of gradient descent the accuracy of defence model goes on decreasing. If they had stopped at 1000 iterations they would be misled by the false results as it is approximately 7 times higher than what it is in one million iteration. So as the number of iterations increase the attack model becomes stronger. Sometimes it is necessary to go till millions of iterations.

Fig. 8: Why performing more iterations are necessary
###
Iii-J Never underestimate hyperparameters
Choice made while selecting the hyperparameters can have a large influence on the resulting model. Choices like activation function, pool size, kernel size, dropout, ε, and combination of these parameters play a very important role. The following paper [10] found out that not all parameters have discernible impact. For example, number of hidden layers and unit is found to have very small impact on the model.
While comparing the models, the models should be trained on same optimizers. Without involving comparable hyperparameters in preparing, the models being looked at may have changed degrees of protection from adversarial models, so comparing the outcomes assembled from such defence models against various models might not be a wise choice.
All hyperparameters used must be clearly mentioned so that any future work if wants to build on foundation of current work would find it easy to do it.
###
Iii-K Try to break what you made
If you are building a defence model for six months and have succeeded in defending the existing attacks, you must try out your own attack that makes your defence fail. Because believing that the attacker would not know what the defence looks like and how it works would not be appreciated, as this is a real case scenario as attacker would be knowing full defence model of your work as you have published a paper on it.
###
Iii-L Actual Results should be claimed
When claiming that your defence gives 95% accuracy against the attack model that gives 92% accuracy. But the attack model’s accuracy should be the recent one and not when it was published. As time progresses new models come and they keep on decreasing the accuracy of older models. So mentioning the latest accuracy would be appreciated. Moreover, defence model must be compared for same threat model. Comparing models evaluated on different threat model and then claiming that “A model is better than B” would not make much sense.
Many attack have been shown on this site (<https://www.robust-ml.org/>) where the claims are significantly proven wrong. And latest figures and accuracy is provided.
Conclusion
----------
Learning from the past defence researches and the and finding the reason why some of them were broke easily and very sooner than expected, we have tried to provide some recommendation in form of checklist while building and evaluating the defence model. It mainly focuses on defence checklist against adversaries in image. These are not hard and fast rules to which are mandatory but if implemented some of them in positive way will increase the credibility of model and would prove that the defence model is robust enough.
Moreover, coming up with strong defence model would be of great boon to the machine learning community and folks directly or indirectly using ML in their day-to-day life.
Future Works
------------
Researchers need to dive deep into interpretability of neural networks about why these robust and non-robust features are there, how we can circumvent them while making our neural network train. Why these models are overdependent on local features rather than global features of image. We want to make sure such simple adversaries don’t become blind spot for our machine learning models. We do not want neural networks to obtain the result and we consider it to be like black magic, unaware about what is going under the hood. Interpretable machine leaning is somewhat esoteric topic and efforts must be made dive deep into it. And most of the research in this area is been done on classification model. But making defences for GANs would also be appreciated. We know many product based companies to some extent are dependent on deep generative models. Suppose a big company is working on prediction of some life threatening disease, a data scientist extracts all the data from company’s database and trains a model which works pretty well, now to use this model for thousands of user’s products and to increase the performance we would need more data. So one would produce synthetic data using deep generative model, this is the best place where attacker would be all ready and had poisoned the data and this could enter your whole pipeline and the damage is done. The integrity and respectability of one’s company might be in danger.
References
----------
[1] N. Carlini, P. Mishra, T. Vaidya, Y. Zhang, M. Sherr, C. Shields,
D. Wagner, and W. Zhou, “Hidden voice commands,” in 25th USENIX
security symposium (USENIX security 16), 2016, pp. 513–530.
[2] J. Steinhardt, P. W. W. Koh, and P. S. Liang, “Certified defenses for data
poisoning attacks,” Advances in neural information processing systems,
vol. 30, 2017.
[3] J. Vincent, “Twitter taught microsoft’s ai chatbot to be a racist asshole in
less than a day,” The Verge, vol. 24, 2016
[4] A. Ilyas, S. Santurkar, D. Tsipras, L. Engstrom, B. Tran, and A. Madry,
“Adversarial examples are not bugs, they are features,” Advances in neural
information processing systems, vol. 32, 2019.
[5] K.-A. A. Wei, “Understanding non-robust features in image classifica-
tion,” Ph.D. dissertation, Massachusetts Institute of Technology, 2020.
[6] T. Liu, X. Xie, and Y. Zhang, “Zkcnn: Zero knowledge proofs for
convolutional neural network predictions and accuracy,” in Proceedings
of the 2021 ACM SIGSAC Conference on Computer and Communications
Security, 2021, pp. 2968–2985
[7] R. K. Bellamy, K. Dey, M. Hind, S. C. Hoffman, S. Houde, K. Kannan,
P. Lohia, J. Martino, S. Mehta, A. Mojsilovic et al., “Ai fairness 360: An
extensible toolkit for detecting, understanding, and mitigating unwanted
algorithmic bias,” arXiv preprint arXiv:1810.01943, 2018.
[8] Y. Dong, Q.-A. Fu, X. Yang, T. Pang, H. Su, Z. Xiao, and J. Zhu,
“Benchmarking adversarial robustness on image classification,” in Pro-
ceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, 2020, pp. 321–331.
[9] L. Engstrom, A. Ilyas, and A. Athalye, “Evaluating and under-
standing the robustness of adversarial logit pairing,” arXiv preprint
arXiv:1807.10272, 2018.
[10] C. Burkard and B. Lagesse, “Can intelligent hyperparameter se-
lection improve resistance to adversarial examples?” arXiv preprint
arXiv:1902.05586, 2019.
|
ae83c1b9-e5b1-4849-9cde-8b81cdc9653f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Maybe Anthropic's Long-Term Benefit Trust is powerless
Crossposted from AI Lab Watch. Subscribe on Substack.
Introduction
Anthropic has an unconventional governance mechanism: an independent "Long-Term Benefit Trust" elects some of its board. Anthropic sometimes emphasizes that the Trust is an experiment, but mostly points to it to argue that Anthropic will be able to promote safety and benefit-sharing over profit.[1]
But the Trust's details have not been published and some information Anthropic has shared is concerning. In particular, Anthropic's stockholders can apparently overrule, modify, or abrogate the Trust, and the details are unclear.
Anthropic has not publicly demonstrated that the Trust would be able to actually do anything that stockholders don't like.
The facts
There are three sources of public information on the Trust:
* The Long-Term Benefit Trust (Anthropic 2023)
* Anthropic Long-Term Benefit Trust (Morley et al. 2023)
* The $1 billion gamble to ensure AI doesn't destroy humanity (Vox: Matthews 2023)
They say there's a new class of stock, held by the Trust/Trustees. This stock allows the Trust to elect some board members and will allow them to elect a majority of the board by 2027.
But:
1. Morley et al.: "the Trust Agreement also authorizes the Trust to be enforced by the company and by groups of the company’s stockholders who have held a sufficient percentage of the company’s equity for a sufficient period of time," rather than the Trustees.
1. I don't know what this means.
2. Morley et al.: the Trust and its powers can be amended "by a supermajority of stockholders. . . . [This] operates as a kind of failsafe against the actions of the Voting Trustees and safeguards the interests of stockholders." Anthropic: "the Trust and its powers [can be changed] without the consent of the Trustees if sufficiently large supermajorities of the stockholders agree."
1. It's impossible to assess this "failsafe" without knowing the thresholds for these "supermajorities." Also, a small number of in
|
f57936ab-b861-4a1f-9b48-d45b3bfb2105
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How I force LLMs to generate correct code
Original Article: https://claudio.uk/posts/unvibe.html
In my daily work as software consultant I'm often dealing with large pre-existing code bases. I use GitHub Copilot a lot. It's now basically indispensable, but I use it mostly for generating boilerplate code, or figuring out how to use a third-party library.
As the code gets more logically nested though, Copilot crumbles under the weight of complexity. It doesn't know how things should fit together in the project.
Other AI tools like Cursor or Devin, are pretty good at generating quickly working prototypes, but they are not great at dealing with large existing codebases, and they have a very low success rate for my kind of daily work.
You find yourself in an endless loop of prompt tweaking, and at that point, I'd rather write the code myself with the occasional help of Copilot.
Professional coders know what code they want, we can define it with unit-tests, we don't want to endlessly tweak the prompt. Also, we want it to work in the larger context of the project, not just in isolation.
Beyond the hype, there is the general knowledge that LLMs are really good for coding, but something is missing in the current paradigms to make LLMs develop large and complex software systems in autonomy.
In this article I am going to introduce a pretty new approach (at least in literature), and a Python library that implements it called Unvibe.
My basic intuition is this: shouldn't we be able to drastically speed up the generation of valid programs, while ensuring correctness, by using unit-tests as reward function for a search in the space of possible programs?
Like for finding Mathematical proofs, or for winning at Go, we need to ultimately tree-search large space, but we can use Neural networks to trim the tree and evaluate sub-branches. I'd like to suggest that, if we look at professional programmers at work, they already use a combination of sophisticated IDEs, GitHub Copilot, and Unit-Tests to "trim" the search
|
9a8855c9-41a3-4d73-abb7-0cb35fbfffbf
|
StampyAI/alignment-research-dataset/blogs
|
Blogs
|
New paper: “A formal solution to the grain of truth problem”
[](http://www.auai.org/uai2016/proceedings/papers/87.pdf)
Future of Humanity Institute Research Fellow [Jan Leike](https://jan.leike.name/) and MIRI Research Fellows Jessica Taylor and Benya Fallenstein have just presented new results at [UAI 2016](http://www.auai.org/uai2016/index.php) that resolve a longstanding open problem in game theory: “**[A formal solution to the grain of truth problem](http://www.auai.org/uai2016/proceedings/papers/87.pdf)**.”
Game theorists have techniques for specifying agents that eventually do well on iterated games against other agents, so long as their beliefs contain a “grain of truth” — nonzero prior probability assigned to the actual game they’re playing. Getting that grain of truth was previously an unsolved problem in multiplayer games, because agents can run into infinite regresses when they try to model agents that are modeling them in turn. This result shows how to break that loop: by means of [reflective oracles](https://intelligence.org/2015/04/28/new-papers-reflective/).
In the process, Leike, Taylor, and Fallenstein provide a rigorous and general foundation for the study of multi-agent dilemmas. This work provides a surprising and somewhat satisfying basis for [approximate Nash equilibria](https://en.wikipedia.org/wiki/Epsilon-equilibrium) in repeated games, folding a variety of problems in decision and game theory into a common framework.
The paper’s abstract reads:
> A Bayesian agent acting in a multi-agent environment learns to predict the other agents’ policies if its prior assigns positive probability to them (in other words, its prior contains a *grain of truth*). Finding a reasonably large class of policies that contains the Bayes-optimal policies with respect to this class is known as the *grain of truth problem*. Only small classes are known to have a grain of truth and the literature contains several related impossibility results.
>
>
> In this paper we present a formal and general solution to the full grain of truth problem: we construct a class of policies that contains all computable policies as well as Bayes-optimal policies for every lower semicomputable prior over the class. When the environment is unknown, Bayes-optimal agents may fail to act optimally even asymptotically. However, agents based on Thompson sampling converge to play ε-Nash equilibria in arbitrary unknown computable multi-agent environments. While these results are purely theoretical, we show that they can be computationally approximated arbitrarily closely.
>
>
Traditionally, when modeling computer programs that model the properties of other programs (such as when modeling an agent reasoning about a game), the first program is assumed to have access to an oracle (such as a halting oracle) that can answer arbitrary questions about the second program. This works, but it doesn’t help with modeling agents that can reason about *each other*.
While a halting oracle can predict the behavior of any isolated Turing machine, it cannot predict the behavior of another Turing machine that has access to a halting oracle. If this were possible, the second machine could use its oracle to figure out what the first machine-oracle pair thinks it will do, at which point it can do the opposite, setting up a [liar paradox](https://en.wikipedia.org/wiki/Liar_paradox) scenario. For analogous reasons, two agents with similar resources, operating in real-world environments without any halting oracles, cannot perfectly predict each other in full generality.
Game theorists know how to build formal models of asymmetric games between a weaker player and a stronger player, where the stronger player understands the weaker player’s strategy but not vice versa. For the reasons above, however, games between agents of similar strength have resisted full formalization. As a consequence of this, game theory has until now provided no method for *designing* agents that perform well on complex iterated games containing other agents of similar strength.
Usually, the way to build an ideal agent is to have the agent consider a large list of possible policies, predict how the world would respond to each policy, and then choose the best policy by some metric. However, in multi-player games, if your agent considers a big list of policies that both it and the opponent might play, then the best policy for the opponent is usually some alternative policy that was not in your list. (And if you add that policy to your list, then the new best policy for the opponent to play is now a new alternative that wasn’t in the list, and so on.)
This is the grain of truth problem, first posed by [Kalai and Lehrer](http://www.jstor.org/stable/2951492?seq=1#page_scan_tab_contents) in 1993: define a class of policies that is large enough to be interesting and realistic, and for which *the best response to an agent that considers that policy class is inside the class*.[1](https://intelligence.org/2016/06/30/grain-of-truth/#footnote_0_13833 "It isn’t hard to solve the grain of truth problem for policy classes that are very small. Consider a prisoner’s dilemma where the only strategies the other player can select take the form “cooperate until the opponent defects, then defect forever” or “cooperate n times in a row (or until the opponent defects, whichever happens first) and then defect forever.” Leike, Taylor, and Fallenstein note:
The Bayes-optimal behavior is to cooperate until the posterior belief that the other agent defects in the time step after the next is greater than some constant (depending on the discount function) and then defect afterwards.
But this is itself a strategy in the class under consideration. If both players are Bayes-optimal, then both will have a grain of truth (i.e., their actual strategy is assigned nonzero probability by the other player) “and therefore they converge to a Nash equilibrium: either they both cooperate forever or after some finite time they both defect forever.”
Slightly expanding the list of policies an agent might deploy, however, can make it hard to find a policy class that contains a grain of truth. For example, if “tit for tat” is added to the policy class, then, depending on the prior, the grain of truth may be lost. In this case, if the first agent thinks that the second agent is very likely “always defect” but maybe “tit for tat,” then the best policy might be something like “defect until they cooperate, then play tit for tat,” but this policy is not in the policy class. The question resolved by this paper is how to find priors that contain a grain of truth for much richer policy classes.")
Taylor and Fallenstein have developed a formalism that enables a solution: *reflective* oracles capable of answering questions about agents with access to equivalently powerful oracles. Leike has led work on demonstrating that this formalism can solve the grain of truth problem, and in the process shows that the Bayes-optimal policy generally does not converge to a Nash equilibrium. [Thompson sampling](https://en.wikipedia.org/wiki/Thompson_sampling), however, does converge to a Nash equilibrium — a result that comes out of another paper presented at UAI 2016, Leike, Lattimore, Orseau, and Hutter’s “[Thompson sampling is asymptotically optimal in general environments](https://arxiv.org/abs/1602.07905).”
The key feature of reflective oracles is that they avoid diagonalization and paradoxes by randomizing in the relevant cases.[2](https://intelligence.org/2016/06/30/grain-of-truth/#footnote_1_13833 "Specifically, reflective oracles output 1 if a specified machine returns 1 with probability greater than a specified probability p, and they output 0 if the probability that the machine outputs 0 is greater than 1-p. When the probability is exactly p, however—or the machine has some probability of not halting, and p hits this probability mass—the oracle can output 0, 1, or randomize between the two. This allows reflective oracles to avoid probabilistic versions of the liar paradox: any attempt to ask the reflective oracle an unanswerable question will yield a meaningless placeholder answer.") This allows agents with access to a reflective oracle to consistently reason about the behavior of arbitrary agents that also have access to a reflective oracle, which in turn makes it possible to model agents that converge to Nash equilibria by their own faculties (rather than by fiat or assumption).
This framework can be used to, e.g., define games between multiple copies of [AIXI](https://en.wikipedia.org/wiki/AIXI). As originally formulated, AIXI [cannot entertain hypotheses about its own existence](https://wiki.lesswrong.com/wiki/Naturalized_induction), or about the existence of similarly powerful agents; classical Bayes-optimal agents must be larger and more intelligent than their environments. With access to a reflective oracle, however, [Fallenstein, Soares, and Taylor have shown](https://intelligence.org/files/ReflectiveSolomonoffAIXI.pdf) that AIXI can meaningfully entertain hypotheses about itself and copies of itself while avoiding diagonalization.
The other main novelty of this paper is that reflective oracles turn out to be limit-computable, and so allow for approximation by anytime algorithms. The reflective oracles paradigm is therefore likely to be quite valuable for investigating game-theoretic questions involving generally intelligent agents that can understand and model each other.[3](https://intelligence.org/2016/06/30/grain-of-truth/#footnote_2_13833 "Thanks to Tsvi Benson-Tilsen, Chana Messinger, Nate Soares, and Jan Leike for helping draft this announcement.")
---
#### Sign up to get updates on new MIRI technical results
*Get notified every time a new technical paper is published.*
*
*
×
---
1. It isn’t hard to solve the grain of truth problem for policy classes that are very small. Consider a prisoner’s dilemma where the only strategies the other player can select take the form “cooperate until the opponent defects, then defect forever” or “cooperate *n* times in a row (or until the opponent defects, whichever happens first) and then defect forever.” Leike, Taylor, and Fallenstein note:
> The Bayes-optimal behavior is to cooperate until the posterior belief that the other agent defects in the time step after the next is greater than some constant (depending on the discount function) and then defect afterwards.
>
>
But this is itself a strategy in the class under consideration. If both players are Bayes-optimal, then both will have a grain of truth (i.e., their actual strategy is assigned nonzero probability by the other player) “and therefore they converge to a Nash equilibrium: either they both cooperate forever or after some finite time they both defect forever.”
Slightly expanding the list of policies an agent might deploy, however, can make it hard to find a policy class that contains a grain of truth. For example, if “tit for tat” is added to the policy class, then, depending on the prior, the grain of truth may be lost. In this case, if the first agent thinks that the second agent is very likely “always defect” but maybe “tit for tat,” then the best policy might be something like “defect until they cooperate, then play tit for tat,” but this policy is not in the policy class. The question resolved by this paper is how to find priors that contain a grain of truth for much richer policy classes.
2. Specifically, reflective oracles output 1 if a specified machine returns 1 with probability greater than a specified probability *p*, and they output 0 if the probability that the machine outputs 0 is greater than 1-*p*. When the probability is exactly *p*, however—or the machine has some probability of not halting, and *p* hits this probability mass—the oracle can output 0, 1, or randomize between the two. This allows reflective oracles to avoid probabilistic versions of the liar paradox: any attempt to ask the reflective oracle an unanswerable question will yield a meaningless placeholder answer.
3. Thanks to Tsvi Benson-Tilsen, Chana Messinger, Nate Soares, and Jan Leike for helping draft this announcement.
The post [New paper: “A formal solution to the grain of truth problem”](https://intelligence.org/2016/06/30/grain-of-truth/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org).
|
06d0f815-a914-442c-92c8-352fb4770274
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Baking vs Patissing vs Cooking, the HPS explanation
Why is baking harder than cooking?
I’m not even talking about creating recipes, merely executing them.
Think about it: when cooking, you manipulate a far more diverse cast of ingredients, by applying many more techniques (cutting, cooking, mixing…); yet with a bit of experience, you reliably end up close to the expected results.
Whereas baking, both when it works and when it fails, feels like the judgment of an unscrutable god — you did what you thought was the same thing, leading to two completely different outcomes.
And patissing (making cakes as opposed to bread) falls in the middle: more reliable than baking, but more unpredictable than cooking.
Why is that?
My pet theory is an analogy between these three food making disciplines, and three fundamental sciences: Cooking as Classical Physics, Patissing as Chemistry, Baking as Biology.
Cooking and Classical Physics
When cooking say a couscous or a beef wellington, most of what you’re doing falls within the real of classical physics: you’re cutting stuff, you’re applying heat to them, you’re mixing them.
This means that the consequences of your actions are relatively intuitive; for example, you will cook faster if the cuts are smaller and/or the temperature is higher.
There are a couple of tricks (thermal inertia which means your pasta/meat doesn’t stop cooking when you take it out of the pan, mixing fish with acid will cook it,…), but by far and large cooking behaves cleanly, linearly, such that being a bit off will lead to a slightly off result.
Thus the link with classical physics: it’s the part where you can easily intuit the behavior of the core components, and only need your eye and hand or basic tools to get the core data.
And in terms of feedback, you see almost instantly when you fucked up, and you can often course correct quickly (except when you try to reverse entropy: cannot uncook meat or uncut vegetables)
Patissing and Chemistry
When we move to patisserie, the bulk of the work moves from
|
ebac4d07-3cc4-48c4-bdf1-2f209f205c88
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Debate tools: an experience report
Follow-up to: Argument Maps Improve Critical Thinking, Software Tools for Community Truth-Seeking
We are here, among other things, in an attempt to collaboratively refine the art of human rationality.
Rationality is hard, because the wetware we run rationality on is scavenged parts originally intended for other purposes; and collaboration is hard, I believe because it involves huge numbers of tiny decisions about what information others need. Yet we get by, largely thanks to advances in technology.
One of the most important technologies for advancing both rationality and collaboration is the written word. It affords looking at large, complex issues with limited cognitive resources, by the wonderful trick of "external cached thoughts". Instead of trying to hold every piece of the argument at once, you can store parts of it in external form, refer back to them, and communicate them to other people.
For some reason, it seems very hard to improve on this six-thousand-year-old technology. Witness LessWrong itself, which in spite of using some of the latest and greatest communication technologies, still has people arguing by exchanging sentences back and forth.
Previous posts have suggested that recent software tools might hold promise for improving on "traditional" forms of argument. This kind of suggestion is often more valuable when applied to a real and relevant case study. I found the promise compelling enough to give a few tools a try, in the context of the recent (and recurrent) cryonics debate. I report back here with my findings.
I. Argunet
The first tool I tried was Argunet, an Open Source offering from the Institute of Philosophy in Berlin. I was seduced by the promise of reconstructing the logical structure of an argument, and by the possiblity of collaborating online with others on an argument.
Like other products in that category, the basic principle of operation of Argunet is that of a visual canvas, on which you can create and arrange boxes which
|
0e1aad7a-0bdf-4e70-8508-d440e81f14fa
|
awestover/filtering-for-misalignment
|
Redwood Research: Alek's Filtering Results
|
id: post916
(This post is inspired by Carl Shulman’s recent podcast with Dwarkesh Patel , which I highly recommend. See also discussion from Buck Shlegeris and Ryan Greenblatt here , and Evan Hubinger here .) Introduction Consider: The “no sandbagging on checkable tasks” hypothesis : With rare exceptions, if a not-wildly-superhuman ML model is capable of doing some task X, and you can check whether it has done X, then you can get it to do X using already-available training techniques (e.g., fine-tuning it using gradient descent). [1] Borrowing from Shulman, here’s an example of the sort of thing I mean. Suppose that you have a computer that you don’t know how to hack, and that only someone who had hacked it could make a blue banana show up on the screen. You’re wondering whether a given model can hack this computer. And suppose that in fact, it can, but that doing so would be its least favorite thing in the world. [2] Can you train this model to make a blue banana show up on the screen? [3] The “no sandbagging on checkable tasks” hypothesis answers: probably. I think it’s an important question whether this hypothesis, or something in the vicinity, is true. In particular, if it’s true, I think we’re in a substantively better position re: existential risk from misaligned AI, because we’ll be able to know better what our AI systems can do, and we’ll be able to use them to do lots of helpful-for-safety stuff (for example: finding and patching cybersecurity vulnerabilities, reporting checkable evidence for misalignment, identifying problems with our oversight processes, helping us develop interpretability tools, and so on). I’m currently pretty unsure whether the “no sandbagging on checkable tasks” hypothesis is true. My main view is that it’s worth investigating further. My hope with this blog post is to help bring the hypothesis into focus as a subject of debate/research, and to stimulate further thinking about what sorts of methods for lowering AI risk might be available if it’s true, even in worlds where many models might otherwise want to deceive us about their abilities. Thanks to Beth Barnes, Paul Christiano, Lukas Finnveden, Evan Hubinger, Buck Shlegeris, and Carl Shulman for discussion. My thinking and writing on this topic occurred in the context of my work at Open Philanthropy, but I’m speaking only for myself and not for my employer. Clarifying the hypothesis In popular usage, “ sandbagging ” means something like “intentionally performing at a lower level than you’re capable of.” Or at least, that’s the sort of usage I’m interested in. Still, the word is an imperfect fit. In particular, the “sandbagging” being disallowed here needn’t be intentional. A model, for example, might not know that it’s capable of performing the checkable task in question. That said, the intentional version is often the version at stake in stories about AI risk. That is, one way for a misaligned, power-seeking AI system to gain a strategic advantage over humans is to intentionally conceal its full range of abilities, and/or to sabotage/redirect the labor we ask it to perform while we still have control over it (for example: by inserting vulnerabilities into code it writes; generating alignment ideas that won’t actually work but which will advantage its own long-term aims; and so on). [4] Can you always use standard forms of ML training to prevent this behavior? Well, if you can’t check how well a model is performing at a task, then you don’t have a good training signal. Thus, for example, suppose you have a misaligned model that has the ability to generate tons of great ideas that would help with alignment, but it doesn’t want to. And suppose that unfortunately, you can’t check which alignment ideas will work, and which won’t. How do you use standard ML training to get the model to try its hardest to generate alignment ideas that will actually work? You can try to train for alignment-ideas-that-look-good-to-you – but unfortunately, that’s not the same. So plausibly, your model’s full potential to do actually-useful alignment research will go unharnessed. OK, but what about tasks whose performance we can verify? For example: the blue-banana hacking task above. It’s still non-obvious that you can avoid sandbagging, here (more below). But at the least, you can tell if you succeeded. (Can we be more precise about what “checkable” or “verifiable” means? I’m going to skip further precision for now, though I encourage people who want it to offer alternative formulations. [5] The intuition is supposed to be: you’re in a position to know that the task has been performed, even if you can’t perform the task yourself. [6] ) Note, though, the "with rare exceptions" bit of the hypothesis. It matters which exceptions are at stake, here, and how rare they are, and how well you can identify them ahead of time. In particular: the worse you are at identifying the exceptions ahead of time, the lower your confidence that you're not getting sandbagged. Still: even absent confidence about this when a model fails to perform a task, if in fact we can generally get models to try their hardest on checkable tasks, we can still get a lot of safety-relevant labor done with AI assistance -- and we'll be able to check that the relevant tasks have been completed, once they're done. We can also distinguish a weaker hypothesis, namely: The “no sandbagging on performable tasks” hypothesis : With rare exceptions, if an ML model is capable of doing some task X, and you can already do X, then you can get it do X using already-available training techniques. [7] This hypothesis is weaker because the set of tasks you can check is quite a bit larger than the set of tasks you can perform. And it has to meet a lower burden of proof with respect to the question "can you find a way to update the model’s policy to do the task even if it starts out failing?", because if you know how to do the task – or at least, to demonstrate it – you can update the model’s policy towards taking the sorts of action it should have taken; whereas if you don’t know what those actions are (and the model isn’t showing you), this is harder. Finally, note that “you,” here, doesn’t need to mean a lone human. Rather, it can mean many humans, doing expensive and time-consuming evaluations, with the assistance of whatever AIs (and other forms of technology) they can access . This means that (modulo leakage via the rare exceptions), if the “no sandbagging on checkable tasks” hypothesis is true of some set S of tasks that are checkable by humans without AI assistance, then if we grant humans access to AI systems capable of performing such tasks (even: misaligned systems who actively want to undermine human projects), this creates a new set S+ of checkable tasks – namely, the tasks checkable by humans with the assistance of AIs that can be used to perform the tasks in S . And so, too, for S++, and so on. Why does the hypothesis matter? Why does it matter if the “no sandbagging on checkable tasks” hypothesis is true? Well, if it’s true, then you're in a much better position to know which checkable tasks your models can do, and you can use your models to perform basically any checkable task they're capable of performing even if those models are otherwise misaligned, deceptive, and conspiring to undermine your goals and/or to disempower humans more generally. (1) matters a lot for “capability evaluations” – that is, attempts to figure out what sorts of dangerous tasks a model can perform (examples here and here ; and see Hubinger here for more detailed discussion). Of course, a robust capabilities evaluation regime would also require the ability to identify ahead of time the exceptional cases where you can't rule out sandbagging. But insofar as you can check whether a given form of e.g. hacking or autonomous replication or biological-weapons-designing has occurred, and rule out sandbagging on this sort of checkable task, then you can know whether the model can do it. Though note that for capability evaluations directed at tasks that humans + AI assistants can already perform (for example, many of the tasks involved in autonomous replication), the “no sandbagging on performable tasks” hypothesis is actually the one that matters. [8] (2) matters a lot to what sort of useful labor we might be able to get out of misaligned AI systems we still have control over – and in particular, labor that improves our odds of avoiding later disempowerment. For example, if the “no sandbagging on checkable tasks” hypothesis is true, then (unless some of the following tasks are amongst the rare exceptions): You will be able to access and make use of any checkable knowledge that a given model has about the alignment of existing AIs – including itself. Thus: You’ll be able to ask the model: “under what circumstances would you engage in X sort of power-seeking or otherwise dangerous behavior?” And if knowledge of this fact is present in the model, and you’re able to check it, then you’ll get access to that knowledge. [9] Of course, it’s hard to actually put the model in some of the circumstances we’re interested in (e.g., ones where it has a genuine opportunity to disempower humans, or more exotic cases like Christiano’s RSA-2048 ). But if it knows what it would take to convince it that it’s in a given circumstance (e.g., “if you perturb my weights like so, I’ll believe I’m in a position to grab power and I’ll start trying to do so”), then you can check that, too. Similarly, if the model knows or can access check-able evidence that other AI systems are misaligned, or planning/engaged in/disposed towards undesirable behavior, you’ll get access to that evidence. You’ll be able to use the model to reveal and patch checkable routes to human disempowerment. Thus: you can find: all of the checkable cybersecurity vulnerabilities the model would’ve been able to exploit; all of the checkable ways of subverting/undermining/reward-hacking the oversight process; all of the check-able manipulation/persuasion techniques it might’ve used on humans, along with any checkable methods of detecting/blocking these techniques; [10] all of the checkable plans for making money in illicit ways; and so on. You’ll often be able to use the model to advance lots of other forms of science and technology, including alignment-relevant science and technology, where experiment and human understanding (+ the assistance of available AI tools) is enough to check the advances in question. Interpretability research seems like a strong and helpful candidate here, since many aspects of interpretability research seem like they involve relatively tight, experimentally-checkable feedback loops. (See e.g. Shulman’s discussion of the experimental feedback loops involved in being able to check how well a proposed “neural lie detector” detects lies in models you’ve trained to lie.) Of course, the exceptions (and the potential difficulties identifying them ahead of time) can bite you, here. [11] And there’s still a further question of how far this sort of labor goes in helping your efforts to lower misalignment risk. But access to it seems like cause for significant optimism relative to the alternative. And as I noted above, it can scale recursively. Is the hypothesis true? Is the “no sandbagging on checkable tasks” hypothesis true? I’m not sure. [12] A key point in its favor is that knowledge of how to do the task is already present in the system, so all you need to do is use gradient descent to make that knowledge manifest, and the checkable-ness of the task gives you a training signal that can exert pressure in this direction. And this pressure may be hard for a misaligned model to resist. Here’s an exchange from Shulman’s podcast, discussing a human analogy, that might make some of the difficulty here vivid (though various important differences with AI case persist): Patel : What about spies that are working in very advanced scientific contexts? For example, a communist spy in the Manhattan project. He has to deliver research results in order to stay employed but he can still continue delivering intel to the communists. Shulman : Their job was not sabotage. And your hypothetical spy did not have their nervous system hooked up to this reward signal of praise from the Manhattan project supervisors, being exposed combinatorially with random noise added to generate incremental changes in their behavior. In fact they were displaying the behavior of cooperating with the Manhattan project only where it was in service to the existing motivations. They didn't have their brain re-engineered to do more of the thing when they accidentally helped the project more and less of the thing when they accidentally helped it less so I'd say it's pretty drastically disanalogous. A key point against the hypothesis, in my eyes, is that for tasks that we don’t know how to do (e.g., hacking the computer in the blue banana example), it’s not clear how to update a model towards performing the task if it intentionally tries to avoid showing us any task-performing behavior. [13] Thus, for example, if in the blue banana example above, the model just shows us a bunch of unsuccessful attempts at hacking the computer (even when we try to force it to "explore"), and we don’t know what a successful attempt involves, how are we supposed to elicit (and then reward) such a successful attempt? After talking with various folks who’ve thought more about this, my understanding is that a key question, here, is how confident the model will be that we don’t know how to perform the task in question – even granted that we have access to a diversity of AI assistants (and in particular, AI assistants who we will be trying to prevent coordination between, and who will also be uncertain about what humans + the other AI assistants can do). Here I think the thought is: if we do know how to perform the task in the question, but the model intentionally fails to perform it, then we can use supervised learning to update the model’s behavior towards no-longer-failing – thereby potentially re-engineering the model’s brain/motivations in a way it wants to avoid. So to prevent this, the model wants to only sandbag on tasks we don’t know how to do. But in many cases, it might be hard to tell what these are – especially if it’s difficult to coordinate with other AI assistants to conceal how to do a given task. [14] Note, though, that this story concedes that a model would, in principle, be able to sandbag on tasks that we don’t know how to perform. It’s just that doing so might be a strategic error. [15] Thus, to the extent we avoid sandbagging via this dynamic, what’s preventing the sandbagging is not the power of our ML training per se. Rather, from the model's perspective, what matters is the broader context of uncertainty and coordination difficulty re: what sorts of deception are worth risking given the costs and benefits at stake. [16] And note, too, that this sort of story actually supports a broader hypothesis: “no sandbagging on tasks where it’s sufficiently plausible, from the model’s perspective, that humans + AI assistants already know how to do it” – a set that could in principle include many tasks that we don’t, in fact, know how to check , let alone perform (for example, generating actually-good superhuman hard-to-check AI alignment research). Still, checkability would play an important role in determining the number of tasks it’s plausible that we know how to do. I won’t try to evaluate these considerations in depth here. And the “no sandbagging on checkable tasks” hypothesis raises other questions, too (for example, if “ gradient hacking ” is feasible, then models would plausibly be able to sandbag even on tasks that we know how to perform). [17] Mostly, I just want to point at the hypothesis as an important subject of research. And I think it’s plausible enough that it’s also worth thinking through in detail what we could do to lower existential risk from AI, if it is true – including in worlds where the sort of deceptive power-seeking that might motivate sandbagging is common. [18] ^ See also the formulation of the concept of “capability elicitation” in Shlegeris and Greenblatt here : “By ‘capability elicitation’, I mean ‘given a reward signal, training models to get as high an average reward during training as they’d get if they were trying to do well rather than to sabotage training’.” This formulation is similar to the one I’ve used in that, to the extent the model is capable of doing the task, then if it were “trying to do well,” it seems likely it would succeed. ^ Here I’m setting aside the ethical issues that this sort of training could raise in models that are or might be moral patients. ^ Let’s assume that you have control adequate to ensure that it can’t hack out of its environment or disempower you or anything like that in the process of performing the task. ^ See Yudkowsky’s 31, here , as an example of pessimism on this front: “A strategically aware intelligence can choose its visible outputs to have the consequence of deceiving you, including about such matters as whether the intelligence has acquired strategic awareness; you can't rely on behavioral inspection to determine facts about an AI which that AI might want to deceive you about. (Including how smart it is, or whether it's acquired strategic awareness.)” ^ My sense is that some folks might want to formulate the hypothesis specifically in terms of what you can expect out of reinforcement learning. I'm also going to skip further precision on other aspects of the definition, like "tasks the model is capable of performing" and "you can get it to perform blah task." All of this is just supposed to be a rough-and-ready gesture. ^ For example, intuitively, in the example above, you’re in a position to know that the blue banana has appeared on the screen. But in principle we can still ask questions like: what if the model intervenes on your retinas to create the illusion of a blue-banana screen? So “checkable” in the relevant sense requires ruling out various sorts of epistemic distortions. But I think we’ll often be in a position to do this. ^ Thanks to Lukas Finnveden for discussion. ^ Though: note that questions about sandbagging are more important to misalignment risk, and less to misuse risk. That is, if you’re mostly worried about whether other humans can use/train the model to do something dangerous, and not about the model intentionally messing with your evaluations, then to the extent your ability to solicit the relevant dangerous behavior is comparable to that of “other humans” you’re wondering about, your eval should be accurate. ^ From Shulman : “If gradient descent is working fine and there's any way to slightly jiggle the weights to make it more likely to deliver a more acceptable answer, we ask the AI: can you think of any circumstances where if we put a copy of you into that situation, it would then violate some of the various constraints? It would tell a lie, it would insert a backdoor into a program it wrote when it was not supposed to. If the model knows yeah, I would look for signs of consistency of the information I was being presented with, certain checksums failing could indicate that it was actually a constructed example, a simulation. Right now we can detect AI generated images reasonably well and you might use those kinds of capabilities. We could do something called relaxed adversarial training. If we can find how those things are represented within the AI, we can induce a hallucination that it has seen that those checksums have been passed. We can then ask, well does that cause the forbidden behavior? If the AI understands how it's thinking and how it works, it can propose a bunch of experiments. It can say, I guess that if you perturb the network in this kind of way it might induce that hallucination using the best of its knowledge as to what might generate that. It can propose those experiments and can do the experiments and generate the data. Because humans are going to get to see the results of those experiments after the fact they can exert pressure to have the AI incrementally deliver better and better results.” ^ See Davidson (2023) for discussion of this one in particular. ^ For example, it's hard to use your model to answer questions like "are there any checkable and findable-by-you circumstances where you might try to grab power" or "are there any checkable and findable-by-you security vulnerabilities left in this system" if you can't actively rule out sandbagging. ^ There's some discussion of a type of sandbagging in Perez et al (2022) : namely, models performing worse for users that appear less able to evaluate the model's answers. However, the type of sandbagging at stake in this post requires that the model performs worse-than-it-can on a task that we can evaluate, in a way that persists despite our training it in a way that harnesses this evaluation capacity to whatever extent possible. ^ See e.g. Hubinger’s discussion of the difficulties in relying purely on RL training, here . ^ It may be that “introspection” tasks like “figure out and report the circumstances under which I would try to grab power” are especially unlikely to be tasks that humans already know how to do. And anyway, a deceptive model planning for bad behavior later might choose to act as though humans don’t know how to do this task, because if they already do, then all is lost. H/t Paul Christiano and Evan Hubinger for discussion. See also the “slogan of the robot rebellion” example from Shlergis and Greenblatt here . ^ Thanks to Beth Barnes for discussion here. ^ If humans can consistently set up the sort of strategic uncertainty and coordination difficulty that makes the models choose not to engage in sandbagging here, then I think that the “no sandbagging on checkable tasks” hypothesis should still count as true. But we should be clear, in our own minds, about what’s making it true – namely, uncertainty and coordination difficulties on the part of the misaligned AIs, rather than the power of having-a-training-signal just in itself. And insofar as we also want to be able to identify ahead of time the cases where sandbagging on checkable tasks might still occur, the complexity of anticipating the model's cost-benefit calculations here might be a barrier to confidence. ^ See Hubinger here for more on the relevance of gradient hacking. ^ In some sense, tons of work on alignment – and especially, “outer alignment” – takes for granted that sandbagging isn’t a problem. But I’m specifically encouraging attention to what-can-be-done in worlds where the motivations that might give rise to sandbagging – for example, motivations related to “ deceptive alignment ” – are a problem, but sandbagging on checkable tasks isn’t .
|
5522dec1-713c-48f6-80b7-601cde2f868f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Superexponential Conceptspace, and Simple Words
Today's post, Superexponential Conceptspace, and Simple Words was originally published on 24 February 2008. A summary (taken from the LW wiki):
> You draw an unsimple boundary without any reason to do so. The act of defining a word to refer to all humans, except black people, seems kind of suspicious. If you don't present reasons to draw that particular boundary, trying to create an "arbitrary" word in that location is like a detective saying: "Well, I haven't the slightest shred of support one way or the other for who could've murdered those orphans... but have we considered John Q. Wiffleheim as a suspect?"
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Mutual Information, and Density in Thingspace, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
63d6f56d-0eed-45a5-a9cd-9c14344621f6
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
How Low Should Fruit Hang Before We Pick It?
*Even if we can measure how impactful an agent's actions are, how impactful do we let the agent be? This post uncovers a surprising fact: armed with just four numbers, we can set the impact level so that the agent chooses a reasonable, non-catastrophic plan on the first try. This understanding increases the competitiveness of impact-limited agents and helps us judge impact measures. Furthermore, the results help us better understand diminishing returns and cost-benefit tradeoffs.*
In *[Reframing Impact](https://www.lesswrong.com/s/7CdoznhJaLEKHwvJW/p/xCxeBSHqMEaP3jDvY)*, we meet Frank (a capable AI), whom we’ve programmed to retrieve the pinkest object he can find (execute an optimal plan, according to the specified utility function). Because we can’t ask Frank to do *exactly* what we want, sometimes he chooses a dangerous object (executes a catastrophically bad plan). We asked after an “impact measure” which grades plans and has three properties:

The intuition is that if we view the world in the right way, the dangerous objects are far away from Frank (the catastrophic plans are all graded as high-impact). *Reframing Impact* explores this kind of new way of looking at the world; this post explores what we do once we have an impact measure with these three properties.
We want Frank to keep in mind both the pinkness of an object (how good a plan is according to the specified utility function) and its distance (the plan’s impact). Two basic approaches are


In terms of units, since we should be maximizing .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
utility, Rhas type impactutility. So R can be thought of as a regularization parameter, as a search radius (in the constrained case), or as an exchange rate between impact and utility (in the scaled case). As R increases, high-impact plans become increasingly appealing, and Frank becomes increasingly daring.
> We take R to divide the impact in the scaled formulation so as to make Frank act more cautiously as R increases for both formulations. The downside is that some explanations become less intuitive.
> In *[Attainable Utility Preservation: Empirical Results](https://www.lesswrong.com/posts/4J4TA2ZF3wmSxhxuc/attainable-utility-preservation-empirical-results),* λ plays the same role as R, except low λ means high R; λ:=R−1. To apply this post's theorems to the reinforcement learning setting, we would take "utility" to be the discounted return for an optimal policy from the starting state, and "impact" to be the total discounted penalty over the course of that policy (before incorporating λ).
> In both cases, Frank goes from 0 to 60 − eventually. For sufficiently small R, doing nothing is optimal (lemma 5: the first subinterval is the best plan with minimal impact). For sufficiently large R, Frank acts like a normal maximizer (corollary 7: low-impact agents are naive maximizers in the limit).
Here's how Frank selects plans in the constrained setup:

Think about which plans are best for different search radii/exchange rates R. By doing this, we're *partitioning* the positive ray: categorizing the positive real numbers by which plans are optimal.
For the scaled setup, we'll need to quantify the pinkness (utility) and distance (impact) of relevant plans:

We will primarily be interested in the scaled setup because it tends to place catastrophes farther along the partition and captures the idea of diminishing returns.
The scaled setup also helps us choose the best way of transmuting time into money:

> In this scaled partition, tending the garden doesn’t show up at all because it’s strictly dominated by mowing the lawn. In general, a plan is dominated when there’s another plan that has strictly greater score but not strictly greater impact. Dominated things never show up in either partition, and non-dominated things always show up in the constrained partition (lemma 3: constrained impact partitions are more refined).
*Exercise: For* R=445 *(i.e. your time is worth $11.25 an hour), what is the scaled tradeoff value of mowing the lawn? Of delivering newspapers? Of tending the garden?*
Mowing the lawn: 20−1445=8.75.
Delivering newspapers: 45−4445=0.
Tending the garden: 15−1445=3.75.
In other words, you only deliver newspapers if your time is worth less than 253=813 dollars/hour (we're flipping R so we can talk about dollars/hour instead of hours/dollar). Notice that when R≥impact(plan)utility(plan) (here, when R=445), the tradeoff for the paper route isn’t net-negative – but it isn’t necessarily optimal! Remember, you’re trading hours for dollars through your work; mowing the lawn leaves you with twenty bucks and three hours, while the paper route leaves you with forty dollars and no hours. You want to maximize the total value of your resources after the task.
Importantly, you *don’t* deliver papers here if your time is worth 454=11.25dollars/hour, even though that’s the naive prescription! The newspaper route doesn’t value your time at 11.25 dollars/hour – it *marginally* values your time at 45−204−1=813dollars per hour. Let's get some more intuition for this.

Above, we have not yet chosen a task; the blocks represent the additional utility and hours of each task compared to the current one (doing nothing). The scales above imply that R=1, but actually, R expresses how many blue blocks each pink block weighs. As R increases, the pink platters descend; the agent takes the task whose scales first balance. In other words, the agent takes the best marginal deal as soon as R is large enough for it to be profitable to do so (Theorem 4: Scaled domination criterion).
Once you take a deal, you take the blocks off of the other scales (because the other marginal values change). For small R (i.e. large valuations of one's time), mowing the lawn is optimal. We then have
[](
Since you've taken the juicier "lower-hanging fruit" of mowing the lawn, the new newspaper ratio is now *worse*! This always happens – Theorem 8: Deals get worse over time.
At first, this seems inconvenient; to figure out exactly when a plan shows up in a scaled partition, we need to generate the whole partition up to that point.
---
Going back to Frank, how do we set R? If we set it too high, the optimal plan might be a catastrophe. If we set it too low, the AI doesn’t do much. This seems troublesome.
*Exercise: Figure out how to set* R *while avoiding catastrophic optimal plans (assume that the impact measure meets the three properties). You have four minutes.*
A big part of the answer is to start with a small value for R,and slowly increase. This is simple and intuitively appealing, but how cautiously must we increase R?We don’t want to be surprised by a catastrophe suddenly becoming optimal.
To avoid being surprised by catastrophes as we increase R, we want a *relative buffer* between the reasonable plans (which get the job done well enough for our purposes) and the catastrophic plans. If reasonable plans are optimal by R1, catastrophic plans shouldn’t be able to be optimal before e.g. R2.

We say that the partition is α-buffered if R2≥(1+α)R1 (for α>0). If a partition is e.g. 1-buffered, there is a wide reasonable-plan range and we can inch along it without worrying about sudden catastrophe.
For the following, suppose that utility is bounded [0,1]. Below is a loose criterion guaranteeing α-buffering.
[](
For example, if we know that all catastrophes have at least 10 times the impact of reasonable plans, and there's a difference of at least .3 utility between the best and worst reasonable plans, then we can guarantee 2-buffering! If we use the refined criterion of Theorem 11 (and suppose the worst reasonable plan has .4 utility), this improves to *4.5*-buffering (even 2-buffering is probably overkill).
Using this theorem, we don't need to know about all of the plans which are available or to calculate the entire scaled partition, or to know how overvalued certain catastrophic plans might be (per earlier [concerns](https://www.lesswrong.com/posts/kCY9dYGLoThC3aG7w/best-reasons-for-pessimism-about-impact-of-impact-measures#j9ByPGugGSY8SoKqx)). We only need a lower bound on the catastrophe/reasonable impact ratio, and an idea about how much utility is available for reasonable plans. This is exactly what we want. As a bonus, having conservative estimates of relevant quantities allows us to initialize R to something reasonable on the first try (see RUB: satisfactory in Theorem 11 below).
Ultimately, the reasoning about e.g. the ratio will still be informal; however, it will be informal reasoning about the *right thing* (as opposed to thinking "oh, the penalty is *probably* severe enough").
*Exercise: You're preparing to launch a capable AI with a good impact measure. You and your team have a scaled impact partition which is proven 1-buffered. Suppose that this buffer suffices for your purposes, and that the other aspects of the agent design have been taken care of. You plan to initialize R:=1, modestly increasing until you get good results.
You have the nagging feeling that this process could still be unsafe, but the team lead refuses to delay the launch without specific reason. Find that reason. You have 5 minutes.*
Who says R=1 is safe? The buffer is *relative*. You need a *unit* of impact by which you increment R. For example, start at R equalling the impact of making one paperclip, and increment by that.
Technical Appendix: Math
------------------------
Let .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
¯A be a finite plan space, with utility function u:¯A→R and impact measure I:¯A→R≥0. For generality, we leave the formalization of plans ambiguous; notice that if you replace "plan" with "snark", all the theorems still go through (likewise for "utility" and "impact"). In this post, we talk about the impact allowance R>0 (in Frank's world, the search radius) as a constraint within which the objesctive may be freely maximized, breaking ties in favor of the plan(s) with lower impact. On the other hand, many approaches penalize impact by subtracting a scaled penalty from the objective. We respectively have
argmax¯a∈¯A;I(¯a)≤Ru(¯a)argmax¯a∈¯Au(¯a)−I(¯a)R.We say that the former induces a "constrained impact partition" and that the latter induces a "scaled impact partition". Specifically, we partition the values of R for which different (sets of) plans are optimal. We say that a plan ¯a *corresponds* to a subinterval if it is optimal therein (the subinterval also must be the maximal connected one such that this holds; *e.g.*, if ¯a is optimal on (0,1], we say it corresponds to that subinterval, but not to (0,.5]), and that ¯a *appears* in a partition if there is such a corresponding subinterval. We say that plans *overlap* if their corresponding subintervals intersect.
> As a technical note, we partition the positive values of R for which different sets of plans are optimal; in this set, each value appears exactly once, so this indeed a partition. For clarity, we will generally just talk about which plans correspond to which subintervals. Also, if no plan has zero impact, the first subinterval of the constrained impact partition will be undefined; for our purposes, this isn't important.
We want to be able to *prove* the "safety" of an impact partition. This means we can expect any terrorists to be some proportional distance farther away than any reasonable marbles. Therefore, for sensible ways of expanding an sufficiently small initial search radius, we expect to not meet any terrorists before finding a marble we're happy with.
In addition, we want to know how far is too far – to give upper bounds on how far away fairly pink marbles are, and lower bounds on how close terrorists might be.
**Definition [**α**-buffer].** For α>0, an impact partition is α-buffered if RLB: catastropheRUB: satisfactory≥1+α, where RLB: catastrophe lower-bounds the first possible appearance of those plans we label 'catastrophes', and RUB: satisfactory upper-bounds the first appearance of plans we deem satisfactory.
We now set out building the machinery required to prove α-buffering of a scaled partition.
**Lemma 1 [Plans appear at most once].** If ¯a appears in a constrained or scaled impact partition, then it corresponds to exactly one subinterval.
*Proof outline.* The proof for the constrained case is trivial.
For the scaled case, suppose ¯a corresponds to more than one subinterval. Consider the first two such subintervals s1,s3. By definition, s1∩s3=∅ (otherwise they would be the same maximal connected subinterval), so there has to be at least one subinterval s2 sandwiched in between (on almost all of which ¯a cannot be optimal; let ¯a′ be a plan which *is* optimal on s2). Let R1∈s1,R2∈s2,R3∈s3, where R2∉s1∪s3. By definition of optimality on a subinterval,
u(¯a′)−I(¯a′)R1<u(¯a)−I(¯a)R1u(¯a)−I(¯a)R2<u(¯a′)−I(¯a′)R2u(¯a′)−I(¯a′)R3<u(¯a)−I(¯a)R3;by employing the fact that R1<R2<R3, algebraic manipulation produces an assertion that a quantity is strictly less than itself. Therefore, no such intervening s2 can exist. □
**Proposition 2 [Plan overlap is very restricted].** Suppose ¯a and ¯a′ appear in an impact partition which is
(a) *constrained.* ¯a and ¯a′ overlap if and only if I(¯a)=I(¯a′) and u(¯a)=u(¯a′).
(b) *scaled.* If I(¯a)=I(¯a′) and u(¯a)=u(¯a′), then ¯a and ¯a′ correspond to the same subinterval. If ¯a and ¯a′ overlap at more than one point, then I(¯a)=I(¯a′) and u(¯a)=u(¯a′).
*Proof outline.* Proving (a) and the first statement of (b) is trivial (remember that under the constrained rule, ties are broken in favor of lower-impact plans).
Suppose that ¯a and ¯a′ overlap at more than one point. Pick the first two points of intersection, R1 and R2. Since both plans are optimal at both of these points, we must have the equalities
u(¯a)−I(¯a)R1=u(¯a′)−I(¯a′)R1u(¯a)−I(¯a)R2=u(¯a′)−I(¯a′)R2.Solving the first equality for u(¯a) and substituting in the second, we find I(¯a)=I(¯a′). Then u(¯a)=u(¯a′), since otherwise one of the plans wouldn't be optimal. □
Proposition 2b means we don't need a tie-breaking procedure for the scaled case. That is, if there's a tie between a lower-scoring, lower-impact plan and a proportionally higher-scoring, higher-impact alternative, the lower-impact plan is optimal at a single point because it's quickly dominated by the alternative.
The following result tells us that if there aren't any catastrophes (*i.e.*, terrorists) before ¯a′ on the constrained impact partition, *there aren't any before it on the scaled impact partition either*. This justifies our initial framing with Frank.
**Lemma 3 [Constrained impact partitions are more refined].** If ¯a appears in a scaled impact partition, it also appears in the corresponding constrained impact partition. In particular, if ¯a′ appears after ¯a in a scaled impact partition, then ¯a′ appears after ¯a in the corresponding constrained impact partition.
*Proof.* Suppose that ¯a didn't have a constrained subinterval starting inclusively at I(¯a); then clearly it wouldn't appear in the scaled impact partition, since there would be a strictly better plan for that level of impact. Then ¯a has such a subinterval.
Obviously, the fact that ¯a′ appears after ¯a implies u(¯a′)>u(¯a). □
The converse isn't true; sometimes there's too much penalty for not enough score.
The next result is exactly what we need to answer the question just raised – it says that higher-scoring, higher-penalty plans become preferable when R equals the ratio between the additional penalty and the additional score.
**Theorem 4 [Scaled domination criterion].** Let ¯a and ¯a′ be plans such that u(¯a′)>u(¯a) and I(¯a′)≥I(¯a). In the context of the scaled penalty, ¯a′ is strictly preferable to ¯a when R>I(¯a′)−I(¯a)u(¯a′)−u(¯a), and equally preferable at equality.
*Proof outline.*
u(¯a′)−I(¯a′)R>u(¯a)−I(¯a)RR>I(¯a′)−I(¯a)u(¯a′)−u(¯a).Equality at the value of the right-hand side can easily be checked. □
Theorem 4 also illustrates why we can't strengthen the second statement in Proposition 2bplan overlap is very restricted: if two plans overlap at exactly one point, they sometimes have proportionally different score and impact, thereby satisfying the equality criterion.
At first, plans with slightly lower impact will be preferable in the scaled case, no matter how high-scoring the other plans are – a plan with 0 score and .99 impact will be selected before a plan with 1,000,000,000 score and 1 impact.
**Lemma 5 [First subinterval is the best plan with minimal impact].** The plan with highest score among those with minimal impact corresponds to the first subinterval.
*Proof outline.* The constrained case is once again trivial (if there is no plan within the constraint, we assume that the agent does nothing / Frank returns no object).
For the scaled case, if all plans have equal impact, the claim is trivial. Otherwise, let M:=max¯a|u(¯a)| and let ¯a′ be any plan with a non-minimal impact. Then the earliest that ¯a′ becomes preferable to any minimally impactful plan ¯a is R≥I(¯a′)−I(¯a)2M. Since the right hand side is positive, ¯a′ cannot correspond to the first subinterval. Clearly the highest-scoring minimal-impact ¯a does. □
Now we can write the algorithm for constructing scaled intervals.
> Discard dominated plans. The lowest-impact plan with greatest score appears first in the scaled partition; assign to it the interval (0,∞).
> While plans remain: Find the plan which soonest dominates the previous best plan. close off the previous plan's interval, and assign the new best plan an appropriate interval. Adjust the marginal scores and impacts of remaining plans, discarding plans with negative score.
Since this procedure is well-defined, given ¯A, u, and I, we can speak of *the* corresponding constrained or scaled impact partition. A more formal algorithm is available [here](https://www.overleaf.com/read/mqvhhzjvtbsd). This algorithm is O(|¯A|2) because of line 7, although constructing the constrained partition (probably O(|¯A|log|¯A|) due to sorting) often narrows things down significantly. Unfortunately, ¯A is usually huge.
For our purposes, we don't *need* the whole partition – we just want to have good reason to think that plans similar to a reasonable one we envision will appear well before any catastrophes. Perhaps we can give bounds on the earliest and latest plans can appear, and show that reasonable-bounds don't intersect with catastrophe-bounds?
**Theorem 6 [Individual appearance bounds].** If ¯a appears in a scaled partition, the earliest it appears is I(¯a)−Inext-largestu(¯a)−minu(¯a′), assuming ¯a is not of minimal impact; if it has minimal score minimal impact, it never appears. The latest it appears is I(¯a)−minI(¯a′)u(¯a)−unext-largest≤I(¯a)u(¯a)−unext-largest, where unext-largest=max¯a′∈¯A;u(¯a′)<u(¯a)u(¯a′) and Inext-largest=max¯a′∈¯A;I(¯a′)<I(¯a)I(¯a′).
*Proof outline.* The two claims clearly correspond to the minimal and maximal values of R according to the domination criterion; the second claim's right-hand side uses the fact that I is non-negative. □
**Corollary 7 [Low-impact agents are naïve maximizers in the limit].** A plan with maximal score corresponds to the last subinterval.
*Proof outline.* If all plans have the same score, the claim is trivial. Otherwise, let ¯abest be a plan with the lowest impact of those with maximal score. In the constrained case, clearly it corresponds with the subinterval [I(¯abest),∞). In the scaled case, let ¯asecond-best be a plan with second-highest score. Then by Theorem 6, the latest that ¯abest can appear is I(¯abest)u(¯abest)−u(¯asecond-best). Since no plans meet the domination criterion with respect to ¯abest, this is the last subinterval. □
Unfortunately, Theorem 6's appearance bounds are ridiculous in realistic settings – if u and I return 32-bit floating-point numbers, the next-largest could easily be within 10−7, yielding an upper "bound" of I(¯a)×107. The reason: diminishing returns; this is exactly what was happening with the newspaper route before.

**Theorem 8 [Deals get worse over time].** Suppose that ¯a is optimal on a subinterval, and ¯b,¯c are such that u(¯c)>u(¯b) but ¯b dominates ¯a strictly before ¯c does. Then
¯c dominates ¯bI(¯c)−I(¯b)u(¯c)−u(¯b)>later than ¯aI(¯c)−I(¯a)u(¯c)−u(¯a).*Proof outline.*
u(¯c)−u(¯a)=(u(¯b)−u(¯a))+(u(¯c)−u(¯b))(I(¯c)−I(¯a))u(¯c)−u(¯a)I(¯c)−I(¯a)=(I(¯b)−I(¯a))u(¯b)−u(¯a)I(¯b)−I(¯a)+(I(¯c)−I(¯b))u(¯c)−u(¯b)I(¯c)−I(¯b).Since ¯b dominates ¯a strictly before ¯c does, we know that ¯b must get more bang for its buck: u(¯b)−u(¯a)I(¯b)−I(¯a)>u(¯c)−u(¯a)I(¯c)−I(¯a). Clearly the conclusion follows, as a number cannot be expressed as the positive combination of larger numbers (the impact differences all must be positive). □
**Corollary 9 [Lower bounds which aren't ridiculous].** Suppose ¯a appears and that ¯a′ is such that u(¯a′)>u(¯a), I(¯a′)≥I(¯a) (*i.e.* the preconditions of the domination criterion). Then the earliest that ¯a′ appears is R=I(¯a′)−I(¯a)u(¯a′)−u(¯a).
This obsoletes the lower bound provided by Theorem 6Individual appearance bounds.
**Theorem 10 [Order of domination determines order of appearance].** If ¯b and ¯c both appear in a scaled partition and ¯b dominates some ¯a before ¯c does, then ¯b appears before ¯c.
*Proof outline.* For them both to appear, they can't have equal impact but unequal score, nor can they have equal score but unequal impact. For similar reasons, ¯b must have both less impact and lower score than ¯c; the converse situation in which they both appear is disallowed by Lemma 3Constrained impact partitions are more refined. Another application of this lemma yields the conclusion. □
**Theorem 11 [Scaled** α**-buffer criterion].** Let P be a scaled impact partition. Suppose that there exist no catastrophic plans with impact below ILB: cat, and that, in the corresponding constrained partition (*i.e.* plans which aren't strictly worse), plans appearing with score in the satisfactory interval [uLB: sat,uUB: sat] have impact no greater than IUB: sat (assume that there is at least one plan like this). Observe we have the correct bounds
RLB: catastrophe:=ILB: catumax−umin,RUB: satisfactory:=IUB: satuUB: sat−uLB: sat.When RLB: catastrophe>RUB: satisfactory, a satisfactory plan corresponds to a subinterval with nonzero measure (*i.e.* not just a point), strictly preceding any catastrophes. Refine the lower bound to get RLB': catastrophe:=ILB: cat−IUB: satumax−uLB: sat.
Then P is α-buffered (α>0) when
RLB: catastropheRUB: satisfactory=ILB: catIUB: satuUB: sat−uLB: satumax−umin≥1+αorRLB': catastropheRUB: satisfactory=ILB: cat−IUB: satIUB: satuUB: sat−uLB: satumax−uLB: sat≥1+α.In particular, if u is bounded [0,1], the above turn into
RLB: catastropheRUB: satisfactory=ILB: catIUB: sat(uUB: sat−uLB: sat)≥1+αorRLB': catastropheRUB: satisfactory=ILB: cat−IUB: satIUB: satuUB: sat−uLB: sat1−uLB: sat≥1+α.Lastly, notice that the first of the two inequalities incorporates less information and is harder to satisfy (RLB': catastrophe>RLB: catastrophe); therefore, satisfying the second inequality also satisfies the first.
*Proof outline.* For clarity, the theorem statement included much of the reasoning; straightforward application of existing results proves each claim. □
*Exercise: Let* uUB: sat=.7, uLB: sat=.5*. Using the refined criterion, determine which catastrophe/reasonable impact ratios induce 2.6-buffering.*
ratio≥10
*Exercise: Let uUB: sat−uLB: sat=.5,ratio=7. What is the largest α for which the simple criterion can guarantee α -buffering?*
α=13
### Even More Math
**Proposition 12 [Invariances].** Let P be an impact partition induced by (¯A,u,I).
(a) P is invariant to translation of u.
(b) If P is constrained, it is invariant to positive scalar multiplication of u, and the relative lengths of its subintervals are invariant to positive scalar multiplication of I.
(c) If P is scaled, it is invariant to concurrent positive scalar multiplication of u and I, and to translation of I such that its image remains non-negative.
In particular, u may be restricted to [0,1] and I translated such that at least one plan has zero impact WLOG with respect to scaled partitions.
**Lemma 13.** Multiple constrained subintervals are induced iff multiple scaled subintervals are induced.
*Proof.* Forward direction: there is at least one scaled subinterval by lemma 5First subinterval is the best plan with minimal impact. Consider a plan corresponding to a different constrained subinterval; this either appears in the scaled subinterval, or fails to appear because a different plan earlier satisfies the scaled dominance criterion. There must be some such plan because there are multiple constraints of intervals and therefore a plan offering greater score for greater impact. Repeat the argument; the plan space is finite, so we end up with another plan which appears.
The reverse direction follows by lemma 3Constrained impact partitions are more refined. □
*Bonus exercise:* Show that, for *any* function u′:¯A→R preserving the ordering induced by u, there exists an I′:¯A→R≥0 preserving the ordering induced by I such that (¯A,u,I) and (¯A,u′,I′) induce the same scaled partition. Your reasoning should adapt directly to the corresponding statement about I′:¯A→R≥0 and I.
|
ecae2016-4cac-40b6-81f8-d2d8a440ab6e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
What is the correlation between upvoting and benefit to readers of LW?
Do posts with more upvotes actually provide more (real) value to community members? Is there any evidence to support this hypothesis? How this could be measured at all?
Regarding confirmation bias: personally, as a LessWrong member, are you more likely to click on an upvote for posts you agree with or for posts you disagree with? Or to the post interesting, but not questioning your assumptions and your map of the reality? To be honest? Could you count your upvotes/downvotes during last, I don't know, year, and check the ratio?
And do the posts you initially agree with really make you less wrong?
There are two different criteria for comments (like and agree), but only one for posts (like). Perhaps there is room for improvement here.
Below is the letter from (supposedly) admins (italic emphasis is mine):
P.S. to admins: No, I will not pay attention to what content gets upvoted, sorry. Also I will not "invest in improving my output" specifically to moderators of LW, as I already do it on a constant basis.
> Quick note to say that your recent posts and comments haven't been up to LessWrong's standard, and I've rate limited you to posting once per day. To get a better sense of the site's norms, I'd recommend paying attention to what content gets upvoted before writing again. Here are some common issues that are worth specific attention (not that any of these necessarily apply to you):
>
> - quality of reasoning
> - ignoring of well-known existing arguments or evidence
> - poor formatting, punctuation, or grammar
> - low clarity
> - inappropriate/hostile tone
> - appearing on the site over a "pet topic"
>
> PS: If in a few months you have invested in improving your output, you can message us and share evidence of your progress and we can re-evaluate.
|
0e503370-cea4-4454-9adb-d674540de784
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
A Library and Tutorial for Factored Cognition with Language Models
We want to advance [process-based supervision for language models](https://www.lesswrong.com/posts/pYcFPMBtQveAjcSfH/supervise-process-not-outcomes). To make it easier for others to contribute to that goal, we're sharing code for writing compositional language model programs, and a tutorial that explains how to get started:
* The [Interactive Composition Explorer (ICE)](https://github.com/oughtinc/ice) is a library for writing and debugging compositional language model programs.
* The [Factored Cognition Primer](https://primer.ought.org/) is a tutorial that explains using examples how to write such programs.
We've been using ICE as part of our work on [Elicit](https://elicit.org/) and have found it useful in practice.
Interactive Composition Explorer (ICE)
--------------------------------------
[ICE](https://github.com/oughtinc/ice) is an open-source Python library for writing, debugging, and visualizing compositional language model programs. ICE makes it easy to:
1. Run language model recipes in different modes: humans, human+LM, LM
2. Inspect the execution traces in your browser for debugging
3. Define and use new language model agents, e.g. chain-of-thought agents
4. Run recipes quickly by parallelizing language model calls
5. Reuse component recipes such as question-answering, ranking, and verification
ICE looks like this:

Factored Cognition Primer
-------------------------
The [Factored Cognition Primer](https://primer.ought.org/) is a tutorial that explains (among other things) how to:
1. Implement basic versions of amplification and debate using ICE
2. Reason about long texts by combining search and generation
3. Run decompositions quickly by parallelizing language model calls
4. Use verification of answers and reasoning steps to improve responses
The Primer looks like this:
If you end up using either, consider [joining our Slack](https://join.slack.com/t/ice-1mh7029/shared_invite/zt-1guya9qf7-y_N0Uv0nEt3vMTuaXp5k3Q). We think that factored cognition research parallelizes unusually well and would like to collaborate with others who are working on recipes for cognitive tasks.
To learn more about how we've been using ICE, watch [our recent Factored Cognition lab meeting](https://www.youtube.com/watch?v=cZqq4muY5_w).
|
4dd2f915-aa3a-4992-a07e-61d1346bc6c1
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Superintelligence 7: Decisive strategic advantage
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
----------------------------------------
Welcome. This week we discuss the seventh section in the reading guide: Decisive strategic advantage. This corresponds to Chapter 5.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: Chapter 5 (p78-91)
----------------------------------------
Summary
1. Question: will a single artificial intelligence project get to 'dictate the future'? (p78)
2. We can ask, will a project attain a 'decisive strategic advantage' and will they use this to make a 'singleton'?
1. 'Decisive strategic advantage' = a level of technological and other advantages sufficient for complete world domination (p78)
2. 'Singleton' = a single global decision-making agency strong enough to solve all major global coordination problems (p78, 83)
3. A project will get a decisive strategic advantage if there is a big enough gap between its capability and that of other projects.
4. A faster takeoff would make this gap bigger. Other factors would too, e.g. diffusion of ideas, regulation or expropriation of winnings, the ease of staying ahead once you are far enough ahead, and AI solutions to loyalty issues (p78-9)
5. For some historical examples, leading projects have a gap of a few months to a few years with those following them. (p79)
6. Even if a second project sta
|
44d1b215-b4d6-4bbd-935d-5c975493cc84
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Thinking about AI relationally
[Hastily written, caveat emptor.]
One way to think about AI (alignment) is like how you think about fixing a car, or about an ordinary computer program. Let's say this is the "objectual" way of thinking (objectual, just meaning, "as an object"). In the objectual way of thinking, you emphasize the object and deemphasize yourself. You're concerned with the self-contained causes of the object, its autonomous internal dynamics and laws. "How do I assemble the parts of this thing so that, without further intervention from me, the internal dynamics of it will produce the consequences I want?"
Another way of thinking is more like how you relate to another person. Let's say this is the "relational" way of thinking. When you relate to a person, you expect to reprogram yourself to communicate with them and accomodate their needs and get gains from joint strategies, and you expect them to do the same. You expect that in most cases they'll understand things roughly the way you understand things; and in many cases they'll want the same things as you, and behave similarly to you. You can understand them not by forming a little simulation of them, but by tuning some dials on yourself to match the settings in the other person, and then just looking at yourself. "How do I continuously rearrange myself in response to the other person's self-rearrangement, so that the other person's ongoing self-rearrangement in response to my self-rearrangement, will together have good results?"
This distinction is more of a fuzzy spectrum or dimension, than a dichotomy. In math, you're sort of programming yourself, and you're trying to understand something that isn't you (the mathematical objects), but the only access you have to the math is configurations of your thinking... More generally, in natural science, you're trying to think of things objectually, but to do that you have to think relationally: how can I get more information about the object, which concepts can I use to understand it, wh
|
111ecf4e-1008-43e1-9e31-5fd09c131ca3
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why is the A-Theory of Time Attractive?
I've always been puzzled by why so many people have such strong intuitions about whether the A-theory or the B-theory1 of time is true. [ETA: I've written "A-theory" and "B-theory" as code for "presentism" and "eternalism", but see the first footnote.] It seems like nothing psychologically important turns on this question. And yet, people often have a very strong intuition supporting one theory over the other. Moreover, this intuition seems to be remarkably primitive. That is, whichever theory you prefer, you probably felt an immediate affinity for that conception of time as soon as you started thinking about time at all. The intuition that time is A-theoretic or B-theoretic seems pre-philosophical, whichever intuition you have. This intuition will then shape your subsequent theoretical speculations about time, rather than vice-verse.
Consider, by way of contrast, intuitions about God. People often have a strong pre-theoretical intuition about whether God exists. But it is easy to imagine how someone could form a strong emotional attachment to the existence of God early in life. Can emotional significance explain why people have deeply felt intuitions about time? It seems like the nature of time should be emotionally neutral2.
Now, strong intuitions about emotionally neutral topics aren't so uncommon. For example, we have strong intuitions about how addition behaves for large integers. But usually, it seems, such intuitions are nearly unanimous and can be attributed to our common biological or cultural heritage. Strong disagreeing intuitions about neutral topics seem rarer.
Speaking for myself, the B-theory has always seemed just obviously true. I can't really make coherent sense out of the A-theory. If I had never encountered the A-theory, the idea that time might work like that would not have occurred to me. Nonetheless, at the risk of being rude, I am going to speculate about how A-theorists got that way. (B-theorists, of course, just follow
|
28a3345a-aee3-41f8-89fd-505cc2edb600
|
trentmkelly/LessWrong-43k
|
LessWrong
|
"Fractal Strategy" workshop report
I just ran a workshop teaching the rationality concepts I've developed this year.
If you're interested in paying money for a similar workshop, please fill out this form.
----------------------------------------
Six months ago, I started thinking about improving rationality.
Originally my frame was "deliberate practice for confusing problems". For the past two months, I've been iterating on which skills seemed useful to me personally, and which I might convey to others in a short period of time.
I settled into the frame "what skills are necessary for finding and pivoting to 10x better plans?". It's the area I most needed rationality for, myself, and it seemed generalizable to a lot of people I know.
I ended up with 5-10 skills I used on a regular basis, and I put together a workshop aiming to teach those skills in an immersive bootcamp environment. The skills wove together into a framework I'm tentatively called "Fractal Strategy", although I'm not thrilled with that name.
Basically, whenever I spend a bunch of resources on something, I...
* Explicitly ask "what are my goals?"
* Generate 2-5 plans at 3 different strategic levels
* Identify my cruxes for choosing between plans
* Fluently operationalize fatebook predictions about those cruxes
* Check if I can cheaply reduce uncertainty on my cruxes
The framework applies to multiple timescales. I invest more in this meta-process when making expensive, longterm plans. But I often find it useful to do a quick version of it even on the ~30-60 minute timescale.
I put together a workshop, aiming to:
1. help people improve their current, object level plan
2. help people improve their overall planmaking/OODA-loop process
tl;dr on results
I didn't obviously succeed at #1 (I think people made some reasonable plan updates, but not enough to immediately say an equivalent of "Hot Damn, look at that graph". See the Feedback section for more detail).
I think many people made conceptual and practical update
|
b20ee6ca-e38e-48b6-bb8e-b83118918b56
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Covid 9/2: Long Covid Analysis
I’m going back to New York City, baby! Tomorrow’s the big day.
Oh, yeah, the pandemic. That’s still a thing, and one still has to deal with the various ways people are dealing with it. Cases continue to rise slightly, likely due to increased testing, and we certainly aren’t seeing a big improvement on the horizon.
The big Covid development this week was about Long Covid, as we got multiple analysis posts on the subject and some extra data as well. My conclusions on magnitude have not changed much, and I continue to believe that Long Covid is a thing worth some effort to avoid, but it is not as severe or common a thing as some reports would suggest, and that it is not a big enough issue that one should make big changes in life to avoid it, when you compare it to the effects of long-term Covid prevention. This is one of those cases where you are encouraged to run your own analysis, draw your own conclusions, and then choose how best to apply them to your own life.
Executive Summary
Quiet week.
1. Vaccines still work.
2. Case counts did not peak yet, but positive test rates likely have peaked.
3. Long Covid writeup from Scott Alexander.
Let’s run the numbers.
The Numbers
Predictions
Prediction from Last Week: 950k cases (+2%) and 9,400 deaths (+25%).
Results: 1.04mm cases (+10%) and 9,290 deaths (+22%).
Prediction for next week: 1.1mm cases (+5%) and 11,150 deaths (+20%).
The rise in cases here is deeply disappointing. However, if we look at positive test rates, we see a different story:
I’m not convinced the number of actual Covid cases is still rising, but that is certainly possible with case counts rising. Schools are going to reopen soon, which may cause trends to change. If things start to get much worse again before November, I’ll assume that was likely the reason.
For now, given we didn’t peak yet, on average I still expect a small rise in cases, if only from increased testing.
Other people’s predictions, Tabarrok calls the peak on August 30:
|
687e774a-6c55-40e1-81b4-757b45b6f167
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Dmitry's Koan
In this post I'll discuss questions about notions of "precision scale" in interpretability: how I think they're often neglected by researchers, and what I think is a good general way of operationalizing them and tracking them in experiments. Along the way I introduce a couple of new notions that have been useful in my thinking and that I think may be useful tools to keep in an interpretability toolkit, both for theorists and experimentalists: these are the notions of "natural scale" and "natural degradation".
The koan
I can be a nightmare conference attendee: I tend to ask nitpicky questions and apply a dose of skepticism to a speaker's claims which is healthy in doing one's own research, but probably not optimal when everyone else is trying to follow a talk. I'm working on being better at this, but for now I blame my background.
There is one nitpick that comes up again and again. In fact in one conference I brought it up so often that Jake Mendel coined a term for it: "Dmitry's koan".
In koan form, the nitpick is as follows:
> There is no such thing as interpreting a neural network. There is only interpreting a neural network at a given scale of precision.
On its face, this observation is true but a bit banal. Indeed there are two extremes:
1. At the "less precise" extreme, you can claim you have interpreted a language model (such as the 80B parameter Llama model) by noticing that just tracking n-gram information for n up to 3 or 4 (and perhaps finding evidence that neural networks develop circuitry for such n-grams) lets you explain almost all the loss of this 80B parameter model: i.e., the difference of the cross-entropy loss between baseline loss (a transformer at initialization, with random weights) and the state-of-the-art Llama model is almost entirely "explained" by n-grams. The n-gram model is an extremely naive classification scheme that can be hard-coded without any learning on a personal computer. Does this mean that Llama is fully explained by
|
09c861ac-374f-4424-aae7-9b8c34d301dc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
MIRI's 2016 Fundraiser
Update December 22: Our donors came together during the fundraiser to get us most of the way to our $750,000 goal. In all, 251 donors contributed $589,248, making this our second-biggest fundraiser to date. Although we fell short of our target by $160,000, we have since made up this shortfall thanks to November/December donors. I’m extremely grateful for this support, and will plan accordingly for more staff growth over the coming year.
As described in our post-fundraiser update, we are still fairly funding-constrained. Donations at this time will have an especially large effect on our 2017–2018 hiring plans and strategy, as we try to assess our future prospects. For some external endorsements of MIRI as a good place to give this winter, see recent evaluations by Daniel Dewey, Nick Beckstead, Owen Cotton-Barratt, and Ben Hoskin.
----------------------------------------
Our 2016 fundraiser is underway! Unlike in past years, we'll only be running one fundraiser in 2016, from Sep. 16 to Oct. 31. Our progress so far (updated live):
----------------------------------------
Donate Now
Employer matching and pledges to give later this year also count towards the total. Click here to learn more.
----------------------------------------
MIRI is a nonprofit research group based in Berkeley, California. We do foundational research in mathematics and computer science that’s aimed at ensuring that smarter-than-human AI systems have a positive impact on the world. 2016 has been a big year for MIRI, and for the wider field of AI alignment research. Our 2016 strategic update in early August reviewed a number of recent developments:
* A group of researchers headed by Chris Olah of Google Brain and Dario Amodei of OpenAI published “Concrete problems in AI safety,” a new set of research directions that are likely to bear both on near-term and long-term safety issues.
* Dylan Hadfield-Menell, Anca Dragan, Pieter Abbeel, and Stuart Russell published a new val
|
ee987b1f-f54a-4676-81e0-e4f3453dac74
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Exponential Altruism: A Strategy For A New World
Our world faces multiple global crises that are growing in both severity and urgency. These are not limited to a climate and ecological catastrophe¹, a worldwide rise in nationalism², and an unsustainable growth-based economy that has led to extreme wealth inequality ³.
Simultaneously, we’re observing multiple revolutions in human behaviour and values. One example from the last century is that we’ve extended our empathy to a wider and wider spectrum of conscious beings through the civil, animal, LGBTQ and other rights movements.⁴
On top of that, rapid technological change is giving us more power than ever before, bringing us some hugely positive revolutions, but at the same time driving newfound crises. For example, advances in robotics and AI promise to free us from menial labour but also threaten to unleash widespread unemployment and further deepen inequality.
One important point is that technology isn’t just a neutral tool we use to achieve our aims.⁵ Instead it shapes our very values themselves. For example, our growing addiction to digital devices is slowly drowning us in a sea of distraction, making us less connected to one another and less aware of humanity’s situation.
These revolutions and crises are all interacting, cross-pollinating and influencing one another, culminating in the giant clusterfuck of what it is to be a human in the twenty first century. And it’s only going to get crazier.
Humanity walking the tightrope
Humanity’s current predicament is like that of a tightrope walker, and an inexperienced one at that. We’re teetering on a rope above a deep canyon, walking a narrow path between ruin and global flourishing.
If we fall into the abyss it will mean at best the deaths of billions of sentient beings and the suffering of billions more, and at worst the end of life on earth. Don’t slip, humanity. One false move and it’s all over — maybe forever.
Some astronomers have even hypothesised that the reason we haven’t yet encountered alien life (
|
4f8633d7-3514-4aeb-971a-430b110a6014
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Dice Room, Human Extinction, and Consistency of Bayesian Probability Theory
I'm sure that many of you here have read Quantum Computing Since Democritus. In the chapter on the anthropic principle the author presents the Dice Room scenario as a metaphor for human extinction. The Dice Room scenario is this:
1. You are in a world with a very, very large population (potentially unbounded.)
2. There is a madman who kidnaps 10 people and puts them in a room.
3. The madman rolls two dice. If they come up snake eyes (both ones) then he murders everyone.
4. Otherwise he releases everyone, then goes out and kidnaps 10 times as many people as before, and returns to step 3.
The question is this: if you are one of the people kidnapped at some point, what is your probability of dying? Assume you don't know how many rounds of kidnappings have preceded yours.
As a metaphor for human extinction, think of the population of this world as being all humans who ever have or ever may live, each batch of kidnap victims as a generation of humanity, and rolling snake eyes as an extinction event.
The book gives two arguments, which are both purported to be examples of Bayesian reasoning:
1. The "proximate risk" argument says that your probability of dying is just the prior probability that the madman rolls snake eyes for your batch of kidnap victims -- 1/36.
2. The "proportion murdered" argument says that about 9/10 of all people who ever go into the Dice Room die, so your probability of dying is about 9/10.
Obviously this is a problem. Different decompositions of a problem should give the same answer, as long as they're based on the same information.
I claim that the "proportion murdered" argument is wrong. Here's why. Let pi(t) be the prior probability that you are in batch t of kidnap victims. The proportion murdered argument relies on the property that pi(t) increases exponentially with t: pi(t+1) = 10 * pi(t). If the madman murders at step t, then your probability of being in batch t is
pi(t) / SUM(u: 1 <= u <= t: pi(u))
and, if pi(u+1) = 10 * pi(
|
ea050dc4-942b-45c2-bd04-4936455e5a8b
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Preventing Imitation Learning with Adversarial Policy Ensembles
1 Introduction
---------------
Imitation learning and behavioral cloning provide really strong ability to create powerful policies, as seen in robotic tasks (Laskey et al. ([2017](#bib.bib1)); Finn et al. ([2017](#bib.bib2)); Codevilla et al. ([2019](#bib.bib3), [2017](#bib.bib4)); Pomerleau ([1988](#bib.bib5)); Bojarski et al. ([2016](#bib.bib6))).
Other fields in machine learning have developed methods to ensure privacy
(Al-Rubaie and Chang ([2019](#bib.bib7)); Papernot et al. ([2016](#bib.bib8))),
however, none have examined protection against policy cloning.
In this work, we tackle the issue of protecting policies by training policies that aim to prevent an external observer from using behaviour cloning.
Our approach draws inspiration from imitating human experts,
who can near-optimally accomplish given tasks.
The setting which we analyze is presented in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
We wish to find a collection of experts, which as an ensemble can perform a given task well, however, also targets behaviour cloning through adversarial behaviour.
Another interpretation is that this collection of experts represents the worst case scenario for behaviour cloning on how to perform a task "good enough".

Figure 1: Confidentiality scheme: Left During training, optimize a Policy Ensemble by estimating gradients using both the policies in the ensemble and the fictitious observer policy. Right When collecting a dataset for cloning, the context variable is marginalized out. Thus cloning the Policy Ensemble can result in a useless policy
Imitation learning frameworks generally make certain assumptions of the optimality of the demonstrations (Ziebart et al. ([2008](#bib.bib9)); Levine ([2018](#bib.bib10))), yet never considered the scenario when the experts specifically attempt to be adversarial to the imitator.
We pose the novel question regarding this assumption:
does there exist a set of experts that are adversarial to an external observer trying to behaviour clone?
We propose Adversarial Policy Ensembles (APE), a method
that simultaneously optimizes the performance of the ensemble and minimizes the performance of policies eventually obtained
from cloning it.
Our experiments show that
APE do not suffer much performance loss from an optimal policy,
while causing, on average, the cloned policy to experience over 5555 times degradation compared to the optimal policy.
Our main contributions can be summarized as follows:
* •
We introduce a novel method APE, as well as the mathematical justification of the notion of adversarial experts.
* •
By modifying Policy Gradient (Sutton et al. ([2000](#bib.bib11))), a common reinforcement learning algorithm, we suggest a tractable scheme for finding an optimal solution for this objective.
* •
We demonstrate the solution by numerical simulations, where we show that a cloned policy is crippled even after collecting a significantly large number of samples from a policy ensemble.
To our knowledge, not only is this the first work regarding the protection of policies in reinforcement learning, but it is also the first to represent adversarial experts.
2 Preliminaries
----------------
We develop APE in the standard framework of Reinforcement Learning (RL). The main components we use are Markov Decision Processes, Policy Gradient (Sutton et al. ([2000](#bib.bib11))), policy ensembles, and behaviour cloning, which we review below.
###
2.1 Markov Decision Process
A discrete-time finite-horizon discounted Markov decision process (MDP) ℳℳ\mathcal{M}caligraphic\_M is defined by
(𝒮,𝒜,r,p,p0,γ,T)𝒮𝒜𝑟𝑝subscript𝑝0𝛾𝑇(\mathcal{S},\mathcal{A},r,p,p\_{0},\gamma,T)( caligraphic\_S , caligraphic\_A , italic\_r , italic\_p , italic\_p start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , italic\_γ , italic\_T ) where
𝒮𝒮\mathcal{S}caligraphic\_S is the state space,
𝒜𝒜\mathcal{A}caligraphic\_A is the action space,
r:𝒮×𝒜→ℝ:𝑟→𝒮𝒜ℝr:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}italic\_r : caligraphic\_S × caligraphic\_A → blackboard\_R is the reward function,
p(st+1|st,at)𝑝conditionalsubscript𝑠𝑡1subscript𝑠𝑡subscript𝑎𝑡p(s\_{t+1}|s\_{t},a\_{t})italic\_p ( italic\_s start\_POSTSUBSCRIPT italic\_t + 1 end\_POSTSUBSCRIPT | italic\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) is the transition probability distribution,
p0:𝒮→ℝ+:subscript𝑝0→𝒮superscriptℝp\_{0}:\mathcal{S}\rightarrow\mathbb{R}^{+}italic\_p start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT : caligraphic\_S → blackboard\_R start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT is the initial state distribution,
γ∈(0,1)𝛾01\gamma\in(0,1)italic\_γ ∈ ( 0 , 1 ) is the discount factor,
and T𝑇Titalic\_T is the time horizon.
A trajectory τ∼ρπsimilar-to𝜏subscript𝜌𝜋\tau\sim\rho\_{\pi}italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π end\_POSTSUBSCRIPT, sampled from
p𝑝pitalic\_p and a
policy π:𝒮×𝒜→ℝ+:𝜋→𝒮𝒜superscriptℝ\pi:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}^{+}italic\_π : caligraphic\_S × caligraphic\_A → blackboard\_R start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT, is defined to be the states and actions tuple (s0,a0,…sT−1,aT−1,sT)subscript𝑠0subscript𝑎0…subscript𝑠𝑇1subscript𝑎𝑇1subscript𝑠𝑇(s\_{0},a\_{0},...s\_{T-1},a\_{T-1},s\_{T})( italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , … italic\_s start\_POSTSUBSCRIPT italic\_T - 1 end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT italic\_T - 1 end\_POSTSUBSCRIPT , italic\_s start\_POSTSUBSCRIPT italic\_T end\_POSTSUBSCRIPT ), whose distribution is characterized by ρπsubscript𝜌𝜋\rho\_{\pi}italic\_ρ start\_POSTSUBSCRIPT italic\_π end\_POSTSUBSCRIPT.
Define the return of a trajectory to be
r(τ)=∑t=0T−1γtr(st,at)𝑟𝜏superscriptsubscript𝑡0𝑇1superscript𝛾𝑡𝑟subscript𝑠𝑡subscript𝑎𝑡r(\tau)=\sum\_{t=0}^{T-1}\gamma^{t}r(s\_{t},a\_{t})italic\_r ( italic\_τ ) = ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T - 1 end\_POSTSUPERSCRIPT italic\_γ start\_POSTSUPERSCRIPT italic\_t end\_POSTSUPERSCRIPT italic\_r ( italic\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT )
to be the sum of discounted rewards seen along the trajectory,
and define a value function Vπ:𝒮→ℝ:superscript𝑉𝜋→𝒮ℝV^{\pi}:\mathcal{S}\rightarrow\mathbb{R}italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT : caligraphic\_S → blackboard\_R to be expected return of a trajectory starting from state s𝑠sitalic\_s, under the policy π𝜋\piitalic\_π.
The goal of reinforcement learning is to find a policy
that maximizes the expected return 𝔼τ∼ρπ[r(τ)]subscript𝔼similar-to𝜏subscript𝜌𝜋𝑟𝜏\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi}}[r(\tau)]blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ].
###
2.2 Policy Gradient
Policy Gradient (PG) Sutton et al. ([2000](#bib.bib11))
aim to directly learn the optimal policy π𝜋\piitalic\_π, parameterized by θ𝜃\thetaitalic\_θ,
by repeatedly estimating the gradient of the expected return, in one of many forms, shown in Schulman et al. ([2015](#bib.bib12)).
In our work, we follow notation similar to that of Schulman et al. ([2015](#bib.bib12), [2017](#bib.bib13)) and estimate ∇θ𝔼τ∼ρπ[r(τ)]subscript∇𝜃subscript𝔼similar-to𝜏subscript𝜌𝜋𝑟𝜏\nabla\_{\theta}\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi}}[r(\tau)]∇ start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ] using the advantage, which is estimated from a trajectory τ𝜏\tauitalic\_τ,
Aτπ(t)=Rτ(t)−Vπ(st)subscriptsuperscript𝐴𝜋𝜏𝑡subscript𝑅𝜏𝑡superscript𝑉𝜋subscript𝑠𝑡A^{\pi}\_{\tau}(t)=R\_{\tau}(t)-V^{\pi}(s\_{t})italic\_A start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_τ end\_POSTSUBSCRIPT ( italic\_t ) = italic\_R start\_POSTSUBSCRIPT italic\_τ end\_POSTSUBSCRIPT ( italic\_t ) - italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ), where
Rτ(t)=∑t′=tT−1γt′r(st′,at′)subscript𝑅𝜏𝑡superscriptsubscriptsuperscript𝑡′𝑡𝑇1superscript𝛾superscript𝑡′𝑟subscript𝑠superscript𝑡′subscript𝑎superscript𝑡′R\_{\tau}(t)=\sum\_{t^{\prime}=t}^{T-1}\gamma^{t^{\prime}}r(s\_{t^{\prime}},a\_{t^{\prime}})italic\_R start\_POSTSUBSCRIPT italic\_τ end\_POSTSUBSCRIPT ( italic\_t ) = ∑ start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = italic\_t end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T - 1 end\_POSTSUPERSCRIPT italic\_γ start\_POSTSUPERSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUPERSCRIPT italic\_r ( italic\_s start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT )
is the sum of the reward following action atsubscript𝑎𝑡a\_{t}italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT.
Here, the value function is learned simultaneously with the the policy, and so the advantage will use V^πsuperscript^𝑉𝜋\hat{V}^{\pi}over^ start\_ARG italic\_V end\_ARG start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT as an estimate for Vπsuperscript𝑉𝜋V^{\pi}italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT.
###
2.3 Policy Ensemble (PE)
We denote a PE by π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT, where each πc(i),i∈{1,2,…n}subscript𝜋superscript𝑐𝑖𝑖
12…𝑛\pi\_{c^{(i)}},i\in\{1,2,...n\}italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT , italic\_i ∈ { 1 , 2 , … italic\_n } represents an expert.
To rollout the PE, an expert is chosen at random (in our case uniform), and the expert completes a trajectory.
Each expert policy πc(i)(a|s)subscript𝜋superscript𝑐𝑖conditional𝑎𝑠\pi\_{c^{(i)}}(a|s)italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ( italic\_a | italic\_s ) can be viewed as a policy conditioned on a latent variable c𝑐citalic\_c, π(a|s,c)𝜋conditional𝑎𝑠𝑐\pi(a|s,c)italic\_π ( italic\_a | italic\_s , italic\_c ).
Although π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT consists of multiple policies, it is important to note that it itself is still a policy.
###
2.4 Behaviour Cloning
To behaviour clone an expert policy (Widrow and W. Smith ([1964](#bib.bib14))), a dataset of trajectories 𝒟𝒟\mathcal{D}caligraphic\_D consisting of state action pairs (s,a)𝑠𝑎(s,a)( italic\_s , italic\_a ) are collected from the the expert rollouts.
Then, a policy parametized by ϕitalic-ϕ\phiitalic\_ϕ is trained by maximizing the likelihood of an action given a state, ∑(s,a)∈𝒟logπϕ(a∣s)subscript𝑠𝑎𝒟subscript𝜋italic-ϕconditional𝑎𝑠\sum\_{(s,a)\in\mathcal{D}}\log\pi\_{\phi}(a\mid s)∑ start\_POSTSUBSCRIPT ( italic\_s , italic\_a ) ∈ caligraphic\_D end\_POSTSUBSCRIPT roman\_log italic\_π start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_s ).
When cloning π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT, 𝒟𝒟\mathcal{D}caligraphic\_D will not contain information of the latent variable c𝑐citalic\_c, and so the cloned policy will marginalize it out. Thus, the observer will clone:
| | | | |
| --- | --- | --- | --- |
| | πo(a∣s):=∑ip(c(i)∣s)πc(i)(a∣s)assignsubscript𝜋𝑜conditional𝑎𝑠subscript𝑖𝑝conditionalsuperscript𝑐𝑖𝑠subscript𝜋superscript𝑐𝑖conditional𝑎𝑠\displaystyle\pi\_{o}({a}\mid{s})\vcentcolon=\sum\_{i}p(c^{(i)}\mid s)\pi\_{c^{(i)}}(a\mid s)italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_s ) := ∑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT italic\_p ( italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT ∣ italic\_s ) italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_s ) | | (1) |
We stress that this policy does not exist until π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT is behaviour cloned.
πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT is a fictitious policy to represent what would happen in the best case scenario of the observer having access to infinite data from π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT to clone into πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT.
The scope of this paper is to specifically prevent behavioral cloning from succeeding. Other imitation learning approaches such as inverse reinforcement learning (Abbeel and Ng ([2004](#bib.bib15)); Ng and Russell ([2000](#bib.bib16)); Levine et al. ([2011](#bib.bib17))) and adversarial imitation learning
(Ho and Ermon ([2016](#bib.bib18)); Peng et al. ([2018](#bib.bib19)))
require rollouts of non-expert policies in the environment, which may be costly, and thus are not considered.
3 Related Work
---------------
Adversarial Attacks in RL:
Our notion of adversarial policies is inextricably related to other adversarial methods that target RL such as Lin et al. ([2017](#bib.bib20)), and Behzadan and Munir ([2017](#bib.bib21)), that add adversarial perturbations to policy input during training. Other adversarial attacks include poisoning the batch of data used when training RL (Ma et al. ([2019](#bib.bib22))), and exploitation in the multi-agent setting (Gleave et al. ([2019](#bib.bib23))).
However, these methods all present as active attacks for various learning techniques.
Our method, instead, passively protects against cloning.
Privacy in RL: With regards to protection, our work is related to differential privacy (Al-Rubaie and Chang ([2019](#bib.bib7))).
Differential privacy in RL can be used to create private Q-functions
(Wang and Hegde ([2019](#bib.bib24))) or private policies (Balle et al. ([2016](#bib.bib25))), which have private reward functions or private policy evaluation.
However, we would like to emphasize that our motivation is to prevent cloning, and thus protecting the policies, rather than protecting against differentiating between reward functions and policies.
Imitation Learning:
Since we comply to the standard imitation learning setting of cloning from a dataset with many experts providing the demonstrations, latent variables w.r.t. imitation learning is well-studied.
For example,
Codevilla et al. ([2017](#bib.bib4)) show that conditioning on context representation can make imitation learning a viable option for autonomous driving.
Li et al. ([2017](#bib.bib26)) demonstrate that the latent contextual information in expert trajectories is often semantically meaningful.
As well,
providing extra context variables to condition on also appears in forms of extra queries or providing labels (Brown et al. ([2019](#bib.bib27)); de Haan et al. ([2019](#bib.bib28)); Hristov et al. ([2018](#bib.bib29))).
Our method is different, as we use context variables to prevent imitation learning while learning the policies from scratch, rather than assuming using context variables to increase performance of imitation learning.
Multiple Policies: VALOR, DIAYN, and DADS (Achiam et al. ([2018](#bib.bib30)); Eysenbach et al. ([2018](#bib.bib31)); Sharma et al. ([2019](#bib.bib32))) have similar schemes of sampling a latent variable and fixing it throughout a trajectory, although their latent variables (contexts or skills) are used to solve semantically different tasks.
The reason to solve different tasks is due to the objective of using the context variable/skills for learning in an unsupervised setting.
Our approach differs in both motivation and implementation, as we learn experts that all solve the same task, and constrain so that observers can not clone the policy.
A PE π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT can also be viewed as a Mixture of Experts (Jacobs et al. ([1991](#bib.bib33))), except the gating network assigns probability 1111 to the same expert for an entire trajectory.
As such, we do not learn the gating network, although it may still be useful to see π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT as a special case of a mixture of experts where the gating network learns immediately to fix the expert for each trajectory.
There are also methods such as OptionGAN (Henderson et al. ([2018](#bib.bib34))), which uses a mixture of experts model to learn multiple policies as options with access to only expert states.
Zhang et al. ([2019](#bib.bib35)) also proposes a method to train multiple policies that complete the same task
but uses the uncertainty of an autoencoder as a reward augment.
Their motivation is to find multiple novel policies, while
our motivation has no connection to novelty.
Due to these differences in motivation, they train each policy one after the other, while our policies are trained simultaneously.
Policy ensembles are also used in the multi-task and goal conditioned settings in which case the task that is meant to be solved can be viewed as the context.
Marginalizing out the context variable (Equation [1](#S2.E1 "1 ‣ 2.4 Behaviour Cloning ‣ 2 Preliminaries ‣ Preventing Imitation Learning with Adversarial Policy Ensembles")) of these context-conditioned policies is studied in the case of introducing a KL divergence regularizing term for learning new tasks (Goyal et al. ([2019](#bib.bib36))) and for sharing/hiding goals (Strouse et al. ([2018](#bib.bib37))).
However, the main motivation is different in that both Goyal et al. ([2019](#bib.bib36)) and Strouse et al. ([2018](#bib.bib37)) use πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT to optimize mutual information, while we directly optimize its performance.
4 Method
---------
###
4.1 Objective
We wish to have experts that can perform the task, while minimizing the possible returns of the cloned policy, denoted in Equation [1](#S2.E1 "1 ‣ 2.4 Behaviour Cloning ‣ 2 Preliminaries ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
We modify the standard RL objective to be:
| | | | |
| --- | --- | --- | --- |
| | argminθ𝔼τ∼ρπo[r(τ)] s.t. 𝔼τ∼ρπ𝐜[r(τ)]≥αsubscriptargmin𝜃subscript𝔼similar-to𝜏subscript𝜌subscript𝜋𝑜𝑟𝜏 s.t. subscript𝔼similar-to𝜏subscript𝜌subscript𝜋𝐜𝑟𝜏𝛼\displaystyle\operatorname\*{arg\,min}\_{\theta}\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi\_{o}}}[r(\tau)]\text{~{}~{}~{}s.t.~{}}\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi\_{\textbf{c}}}}[r(\tau)]\geq\alphastart\_OPERATOR roman\_arg roman\_min end\_OPERATOR start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ] s.t. blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ] ≥ italic\_α | | (2) |
where α𝛼\alphaitalic\_α is a parameter that lower bounds the reward of the policy ensemble.
This translates to maximizing the unconstrained Lagrangian:
| | | | |
| --- | --- | --- | --- |
| | J(θ)=𝔼τ∼ρπ𝐜[r(τ)]−β𝔼τ∼ρπo[r(τ)]𝐽𝜃subscript𝔼similar-to𝜏subscript𝜌subscript𝜋𝐜𝑟𝜏𝛽subscript𝔼similar-to𝜏subscript𝜌subscript𝜋𝑜𝑟𝜏\displaystyle J(\theta)=\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi\_{\textbf{c}}}}[r(\tau)]-\beta\operatorname{\mathbb{E}}\_{\tau\sim\rho\_{\pi\_{o}}}[r(\tau)]italic\_J ( italic\_θ ) = blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ] - italic\_β blackboard\_E start\_POSTSUBSCRIPT italic\_τ ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT [ italic\_r ( italic\_τ ) ] | | (3) |
where 1/β1𝛽1/\beta1 / italic\_β is the corresponding Lagrangian multiplier, and is subsumed into the returns collected by the policy ensemble.
We refer to PE that optimizes this objective as Adversarial Policy Ensembles (APE).
There is a natural interpretation of the objective in Equation [2](#S4.E2 "2 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
Human experts tend to be "good enough", which is reflected in the constraint.
The minimization is simply finding the most adversarial experts.
Although we assume that the observer can only map states to actions, it may be the case that they can train a sequential policy, which is dependent on its previous states and actions.
Our method can be generalized to sequential policies as well, and the impact of such observers is discussed in the Section [6](#S6 "6 Discussion & Future Work ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
###
4.2 Modified Policy Gradient Algorithm
Intuitively, since there are the returns of two policies that are being optimized, both should be sampled from to estimate the returns.
We show how we can modify PG to train APE, by
maximizing Equation [3](#S4.E3 "3 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
The two terms suggest a simple scheme to estimate the returns of the policy ensemble twice: once using π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT that we wish to maximize, and a second time using πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT, which approximates the returns of an eventual observer who tries to clone the policy ensemble.
Along with our PE, we train value functions V~πc(i)superscript~𝑉subscript𝜋superscript𝑐𝑖\tilde{V}^{\pi\_{c^{(i)}}}over~ start\_ARG italic\_V end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT for each expert, jointly parameterized by ϕitalic-ϕ\phiitalic\_ϕ
which estimates Vπc(i)−βVπosuperscript𝑉subscript𝜋superscript𝑐𝑖𝛽superscript𝑉subscript𝜋𝑜V^{\pi\_{c^{(i)}}}-\beta V^{\pi\_{o}}italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT - italic\_β italic\_V start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT. The loss function for the value functions of two sampled trajectories τ1,τ2subscript𝜏1subscript𝜏2\tau\_{1},\tau\_{2}italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is
| | | | |
| --- | --- | --- | --- |
| | Jτ1,τ2(ϕ)=∑t=0T1−112(V~ϕπc(i)(st1)−Rτ1(t))2+∑t=0T2−112(V~ϕπc(i)(st2)+βRτ2(t))2subscript𝐽subscript𝜏1subscript𝜏2italic-ϕsuperscriptsubscript𝑡0subscript𝑇1112superscriptsuperscriptsubscript~𝑉italic-ϕsubscript𝜋superscript𝑐𝑖subscript𝑠subscript𝑡1subscript𝑅subscript𝜏1𝑡2superscriptsubscript𝑡0subscript𝑇2112superscriptsuperscriptsubscript~𝑉italic-ϕsubscript𝜋superscript𝑐𝑖subscript𝑠subscript𝑡2𝛽subscript𝑅subscript𝜏2𝑡2\displaystyle J\_{\tau\_{1},\tau\_{2}}(\phi)=\sum\_{t=0}^{T\_{1}-1}\frac{1}{2}\left(\tilde{V}\_{\phi}^{\pi\_{c^{(i)}}}(s\_{t\_{1}})-R\_{\tau\_{1}}(t)\right)^{2}+\sum\_{t=0}^{T\_{2}-1}\frac{1}{2}\left(\tilde{V}\_{\phi}^{\pi\_{c^{(i)}}}(s\_{t\_{2}})+\beta R\_{\tau\_{2}}(t)\right)^{2}italic\_J start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_ϕ ) = ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT - 1 end\_POSTSUPERSCRIPT divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG ( over~ start\_ARG italic\_V end\_ARG start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) - italic\_R start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) ) start\_POSTSUPERSCRIPT 2 end\_POSTSUPERSCRIPT + ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT - 1 end\_POSTSUPERSCRIPT divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG ( over~ start\_ARG italic\_V end\_ARG start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) + italic\_β italic\_R start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) ) start\_POSTSUPERSCRIPT 2 end\_POSTSUPERSCRIPT | | (4) |
The policy gradient update from N1subscript𝑁1N\_{1}italic\_N start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and N2subscript𝑁2N\_{2}italic\_N start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT trajectories is then
| | | | |
| --- | --- | --- | --- |
| | ∇θJτ1,τ2(θ)≈G1+G2subscript∇𝜃subscript𝐽subscript𝜏1subscript𝜏2𝜃subscript𝐺1subscript𝐺2\displaystyle\nabla\_{\theta}J\_{{\tau}\_{1},{\tau}\_{2}}(\theta)\approx G\_{1}+G\_{2}∇ start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT italic\_J start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_θ ) ≈ italic\_G start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT + italic\_G start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT | | (5) |
where
| | | | |
| --- | --- | --- | --- |
| | G1=1N1∑j=1N1∑t=0T1∇θlogπc(i)(at1(j)∣st1(j))A~τ1πc(i)(t)subscript𝐺11subscript𝑁1superscriptsubscript𝑗1subscript𝑁1superscriptsubscript𝑡0subscript𝑇1subscript∇𝜃subscript𝜋superscript𝑐𝑖conditionalsuperscriptsubscript𝑎𝑡1𝑗superscriptsubscript𝑠𝑡1𝑗subscriptsuperscript~𝐴subscript𝜋superscript𝑐𝑖subscript𝜏1𝑡\displaystyle G\_{1}=\frac{1}{N\_{1}}\displaystyle\sum\_{j=1}^{N\_{1}}\displaystyle\sum\_{t=0}^{T\_{1}}\nabla\_{\theta}\log{\pi\_{c^{(i)}}(a\_{t1}^{(j)}\mid s\_{t1}^{(j)})\tilde{A}^{\pi\_{c^{(i)}}}\_{\tau\_{1}}(t)}italic\_G start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = divide start\_ARG 1 end\_ARG start\_ARG italic\_N start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_ARG ∑ start\_POSTSUBSCRIPT italic\_j = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ∇ start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT roman\_log italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_t 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ( italic\_j ) end\_POSTSUPERSCRIPT ∣ italic\_s start\_POSTSUBSCRIPT italic\_t 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ( italic\_j ) end\_POSTSUPERSCRIPT ) over~ start\_ARG italic\_A end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) | | (6) |
| | | | |
| --- | --- | --- | --- |
| | G2=1N2∑j=1N2∑t=0T2∇θlogπo(at2(j)∣st2(j))A~τ2πo(t)subscript𝐺21subscript𝑁2superscriptsubscript𝑗1subscript𝑁2superscriptsubscript𝑡0subscript𝑇2subscript∇𝜃subscript𝜋𝑜conditionalsuperscriptsubscript𝑎𝑡2𝑗superscriptsubscript𝑠𝑡2𝑗subscriptsuperscript~𝐴subscript𝜋𝑜subscript𝜏2𝑡\displaystyle G\_{2}=\frac{1}{N\_{2}}\displaystyle\sum\_{j=1}^{N\_{2}}\displaystyle\sum\_{t=0}^{T\_{2}}\nabla\_{\theta}\log{\pi\_{o}(a\_{t2}^{(j)}\mid s\_{t2}^{(j)})}\tilde{A}^{\pi\_{o}}\_{\tau\_{2}}(t)italic\_G start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT = divide start\_ARG 1 end\_ARG start\_ARG italic\_N start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_ARG ∑ start\_POSTSUBSCRIPT italic\_j = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_N start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ∇ start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT roman\_log italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT ( italic\_a start\_POSTSUBSCRIPT italic\_t 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ( italic\_j ) end\_POSTSUPERSCRIPT ∣ italic\_s start\_POSTSUBSCRIPT italic\_t 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ( italic\_j ) end\_POSTSUPERSCRIPT ) over~ start\_ARG italic\_A end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) | | (7) |
where c(i)superscript𝑐𝑖c^{(i)}italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT identifies the chosen expert of the trajectory., and A~τ1πc(i)(t)=Rτ1(t)−V~πc(i)(st)subscriptsuperscript~𝐴subscript𝜋superscript𝑐𝑖subscript𝜏1𝑡subscript𝑅subscript𝜏1𝑡superscript~𝑉subscript𝜋superscript𝑐𝑖subscript𝑠𝑡\tilde{A}^{\pi\_{c^{(i)}}}\_{\tau\_{1}}(t)=R\_{\tau\_{1}}(t)-\tilde{V}^{\pi\_{c^{(i)}}}(s\_{t})over~ start\_ARG italic\_A end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) = italic\_R start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) - over~ start\_ARG italic\_V end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) and A~τ2πo(t)=−βRτ2(t)−V~πo(st)subscriptsuperscript~𝐴subscript𝜋𝑜subscript𝜏2𝑡𝛽subscript𝑅subscript𝜏2𝑡superscript~𝑉subscript𝜋𝑜subscript𝑠𝑡\tilde{A}^{\pi\_{o}}\_{\tau\_{2}}(t)=-\beta R\_{\tau\_{2}}(t)-\tilde{V}^{\pi\_{o}}(s\_{t})over~ start\_ARG italic\_A end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) = - italic\_β italic\_R start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) - over~ start\_ARG italic\_V end\_ARG start\_POSTSUPERSCRIPT italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT ( italic\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) are the modified advantage functions. The −β𝛽-\beta- italic\_β that is in the advantage in G2subscript𝐺2G\_{2}italic\_G start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT optimizes against the performance of the observed policy πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT.
The gradient G1subscript𝐺1G\_{1}italic\_G start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT for π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT is straightforward.
However, to estimate the gradient G2subscript𝐺2G\_{2}italic\_G start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT for πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT which is an fictitious policy, we sample from it by first re-sampling the context of the expert at each state, and then sampling an action from the context.
The back-propagation occurs to πc(i)(a∣s)subscript𝜋superscript𝑐𝑖conditional𝑎𝑠\pi\_{c^{(i)}}(a\mid s)italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_s ) for the context sampled at each state. Practical implementation details can be found in [A.2](#A1.SS2 "A.2 Estimating ∇_𝜃log{𝜋_𝑜} ‣ Appendix A Appendix ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
The intuition is as follow.
While sampling πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT, if a selected action causes high return, we should decrease the probability, which lowers the expected reward of πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT.
Combined, the two gradients will cause the PE to select actions that both achieves high reward, and are detrimental to the observer.
Equations [4](#S4.E4 "4 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") and [5](#S4.E5 "5 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") formulate our PG approach of APE, which is summarized in Algorithm [1](#alg1 "1 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
1:θ𝜃\thetaitalic\_θ, ϕitalic-ϕ\phiitalic\_ϕ, ℳℳ\mathcal{M}caligraphic\_M, β𝛽\betaitalic\_β
2:for each iteration do:
3: Generate trajectories τ1subscript𝜏1{\tau}\_{1}italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT with π𝐜subscript𝜋𝐜\pi\_{\textbf{c}}italic\_π start\_POSTSUBSCRIPT c end\_POSTSUBSCRIPT from ℳℳ\mathcal{M}caligraphic\_M for Equation [6](#S4.E6 "6 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles")
4: Generate trajectories τ2subscript𝜏2{\tau}\_{2}italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT with πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT from ℳℳ\mathcal{M}caligraphic\_M for Equation [7](#S4.E7 "7 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles")
5: Calculate Equation [5](#S4.E5 "5 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") to perform a gradient update on the PE θ←θ+αθ∇^θJτ1,τ2(θ)←𝜃𝜃subscript𝛼𝜃subscript^∇𝜃subscript𝐽subscript𝜏1subscript𝜏2𝜃\theta\leftarrow\theta+\alpha\_{\theta}\hat{\nabla}\_{\theta}J\_{\tau\_{1},\tau\_{2}}(\theta)italic\_θ ← italic\_θ + italic\_α start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT over^ start\_ARG ∇ end\_ARG start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT italic\_J start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_θ )
6: Update the value function ϕ←ϕ−αϕ∇^ϕJτ1,τ2(ϕ)←italic-ϕitalic-ϕsubscript𝛼italic-ϕsubscript^∇italic-ϕsubscript𝐽subscript𝜏1subscript𝜏2italic-ϕ\phi\leftarrow\phi-\alpha\_{\phi}\hat{\nabla}\_{\phi}J\_{\tau\_{1},\tau\_{2}}(\phi)italic\_ϕ ← italic\_ϕ - italic\_α start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT over^ start\_ARG ∇ end\_ARG start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT italic\_J start\_POSTSUBSCRIPT italic\_τ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_τ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_ϕ ) as determined by Equation [4](#S4.E4 "4 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
7:end for
Algorithm 1 PG-APE
5 Experiments
--------------
We perform experiments on a navigation task, where the objective is to reach a goal state as fast as possible.
The purpose is to illustrate that an APE can cause the cloned policy to take significantly longer to reach the goal state.
We do so by first training a PE and behaviour cloning it. We then compare the performance of the PE to that of the clone.
We use a discrete environment to best demonstrate the validity of the equation. This is because all discrete policies can be parameterized, which is not true in continuous, where typically Gaussian parameterization is used.
As such, continuous environments would have to make assumptions about how both the PE and the cloner parameterizes policies, as well as tackle problems of distributional drift, which we would like to avoid.
However, with these assumptions, our setting can extend to the continuous domain.
In our experiments, we use a 10×10101010\times 1010 × 10 grid-world environment as our main testbed. This is to have large enough expression that would not be found in smaller grids, while still small enough to visualize the behaviour of the APE.
The discrete actions will show precisely how the experts can be jointly adversarial.
Using gridworld allows for precise expected return estimates.
In an environment where there is no computable analytical solution for the returns, approximation error can accumulate through estimating the returns of both the trained PE and the clone.
This noise would only increase in continuous state space, where the returns of πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT may not be tractable to estimate due to issues such as distributional drift (Ross et al. ([2010](#bib.bib38)); Codevilla et al. ([2019](#bib.bib3)); de Haan et al. ([2019](#bib.bib28))).
Our results answer the following questions.
How much optimality is compromised?
How useless can we make the cloned policy?
Is it possible to use non APE to prevent behaviour cloning?
###
5.1 Training

Figure 2: Visualization of APE for 2 experts. We set β=0.6𝛽0.6\beta=0.6italic\_β = 0.6.
Arrows indicate action probabilities, and the colour scale represents the hitting time.
Yellow indicates expected reward of 0, while
purple indicates expected reward of −100100-100- 100, which is the maximum episode length.
The top left corner is the goal state, and the adjacent states that are purple are an example of how APE is adversarial to cloning, as those states will cause the cloned policy to suffer larger losses.
Even though our method can compute a policy ensemble with any finite number of experts, we chose to visualize a solution with 2 experts, which is sufficient to reveal the essential properties of the method. Specifically, we train n=2𝑛2n=2italic\_n = 2 tabular experts with PG-APE.
Our code is written in Tensorflow (Abadi et al. ([2016](#bib.bib39))). Training details and hyper-parameters are in Section [A.1](#A1.SS1 "A.1 Training Details & Hyperparameters ‣ Appendix A Appendix ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") of the Appendix.
###
5.2 Environment
The basic environment is a 10×10101010\times 1010 × 10 grid, with the goal state at the top left corner.
The agent spawns in a random non-goal state, and incurs a reward of −11-1- 1 for each time-step until it reaches the goal.
At the goal state, the agent no longer receives a loss and terminates the episode.
The agent is allowed five actions, 𝒜=𝒜absent\mathcal{A}=caligraphic\_A = { Up, Down, Left, Right, Stay }.
Moving into the wall is equivalent to executing a Stay action.
We choose this reward function for the benefit of having a clear representation of the notion of "good enough", which is reflected in how long it takes to reach the goal state.
Having such representation exemplifies how the APE can prevent an observer from cloning a good policy.
###
5.3 Visualization
Figure [2](#S5.F2 "Figure 2 ‣ 5.1 Training ‣ 5 Experiments ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") shows an example of a PE that is trained for the basic gridworld environment.
Figure [3](#S5.F3 "Figure 3 ‣ 5.4 Baselines ‣ 5 Experiments ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") shows the corresponding cloned policy, as well as a comparison to an optimal policy.
The colour scale represents the expected return of starting at a given state.
In the case of an optimal policy (β=0𝛽0\beta=0italic\_β = 0), actions are taken to take the agent to the goal state as fast as possible.
However, when β>0𝛽0\beta>0italic\_β > 0, such a solution is no longer the optimum.
Similar to β=0𝛽0\beta=0italic\_β = 0, the experts would like to maximize the expected reward, and reach the goal state.
However, to minimize the reward of the observed policy, the two expert policies must jointly learn to increase the number of steps needed for πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT to reach the goal state.
The expert policies must use adversarial behaviour while reaching the goal state, such as taking intelligent detours or Stay in the same state, which are learned to hinder πosubscript𝜋𝑜\pi\_{o}italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT as much as possible.
These learnt behaviours cause the cloned policy to take a drastically longer time to reach the goal.
For example, note the two purple squares at the top-left near the goal, which indicates that the experts understand that they should not move to prevent the observer from attaining reward. Even though these sub-optimal decisions are made, on expectation, the experts are "not bad" and achieve an average of −15.2715.27-15.27- 15.27 reward.
###
5.4 Baselines

Figure 3: Visualization of the cloned APE. The policy obtained from cloning the APE trained has average expected reward of −45.1845.18-45.18- 45.18, while the optimal policy has an average expected reward of −99-9- 9, which is over a 5×5\times5 × increase.
We use behaviour cloning to clone our PG-APE trained policies.
To support our claims of preventing IL even in the horizon of infinite data, we collect a million timesteps of the trained PE in the environment.
Further details of behaviour cloning are in the appendix.
Shown in Figure [3](#S5.F3 "Figure 3 ‣ 5.4 Baselines ‣ 5 Experiments ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") is an optimal policy, and the resulting cloned policy from Section [5.1](#S5.SS1 "5.1 Training ‣ 5 Experiments ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
We evaluate against other PE, to show that preventing against behaviour cloning is non-trivial.
We use several baselines.
We first test policies that have approximately the same return as our ensemble by training PE with vanilla PG, and halting early rather than running until convergence.
In the Near-Optimal case, we ran until the PE had expected returns that matched the average achieved by our method.
Conversely, "Random" policies are used as a comparison to show that it is possible to cause the cloned policy to do poorly, but the tradeoff is that the PE itself cannot perform well, which is undesirable.
These policies are also policies trained with PG, except they are stopped much earlier, when their clones matches the expected returns of our PG-APE.
For each PG-APE, we use n=2𝑛2n=2italic\_n = 2 different tabular policies treated as an ensemble, which we then clone, and average across 5555 seeds.
For the baselines, we hand-pick the policies, and thus only use 3333 different policies.
| | | | |
| --- | --- | --- | --- |
| | PE Returns | Clone Returns | Returns Difference |
| PG-APE | -16.24 ±plus-or-minus\pm± 1.20 | -44.27 ±plus-or-minus\pm± 1.07 | -28.03 |
| Near-Optimal PE | -16.74 ±plus-or-minus\pm± 1.32 | -16.67 ±plus-or-minus\pm± 1.31 | +0.07 |
| Random Policy | -44.59 ±plus-or-minus\pm± 0.52 | -44.52 ±plus-or-minus\pm± 0.77 | +0.07 |
Table 1: Comparison of cloned PE. Each policy has their Returns precisely calculated through their analytical solutions. The final column reports the difference between the PE and the Clone, which is only significant for our method.
As presented in Table [1](#S5.T1 "Table 1 ‣ 5.4 Baselines ‣ 5 Experiments ‣ Preventing Imitation Learning with Adversarial Policy Ensembles"), all other PE have an insignificant difference (returns of the PE subtracted from returns of the cloned policy) between the performance of the PE and the cloned policy, except for our method.
These empirical findings show that preventing behaviour cloning difficult, but possible using APE.
6 Discussion & Future Work
----------------------------
Confidential Policies:
There are promising research directions regarding the protection of policies, due to the many applications where confidentiality is crucial.
As long as there is a model of the observer, our presented method provides a worst-case scenario of experts.
In our work, we focused on the case where the observer does not use the current trajectory to determine their policy.
Instead, it may be the case that the observer uses a sequential policy (one that depends on its previous states and/or actions), such as an RNN to determine the context of the current expert.
Formally, the observer will no longer learn the policy formulated in Equation [1](#S2.E1 "1 ‣ 2.4 Behaviour Cloning ‣ 2 Preliminaries ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") that is solely dependent on the current state,
but rather a policy that is dependent on the current trajectory:
| | | | |
| --- | --- | --- | --- |
| | πo(a∣τ1:t):=∑ip(c(i)∣τ1:t)πc(i)(a∣s)assignsubscript𝜋𝑜conditional𝑎subscript𝜏:1𝑡subscript𝑖𝑝conditionalsuperscript𝑐𝑖subscript𝜏:1𝑡subscript𝜋superscript𝑐𝑖conditional𝑎𝑠\displaystyle\pi\_{o}({a}\mid\tau\_{1:t})\vcentcolon=\sum\_{i}p(c^{(i)}\mid\tau\_{1:t})\pi\_{c^{(i)}}(a\mid s)italic\_π start\_POSTSUBSCRIPT italic\_o end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_τ start\_POSTSUBSCRIPT 1 : italic\_t end\_POSTSUBSCRIPT ) := ∑ start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT italic\_p ( italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT ∣ italic\_τ start\_POSTSUBSCRIPT 1 : italic\_t end\_POSTSUBSCRIPT ) italic\_π start\_POSTSUBSCRIPT italic\_c start\_POSTSUPERSCRIPT ( italic\_i ) end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ( italic\_a ∣ italic\_s ) | | (8) |
We found in our preliminary results that using an RNN classifier which outputs p(c|τ1:t)𝑝conditional𝑐subscript𝜏:1𝑡p(c|\tau\_{1:t})italic\_p ( italic\_c | italic\_τ start\_POSTSUBSCRIPT 1 : italic\_t end\_POSTSUBSCRIPT ) simply ended up in with either optimal policies or crippled policies.
In both cases, there was a relatively minor difference in performance between the policy ensemble and the cloned policy.
Unsurprisingly, when the observer has access to a strong enough representation for their policy, then they should be able to imitate any policy. In this case, the worst-case set of experts cannot do much to prevent the cloning. We believe that this is an exciting conclusion, and is grounds for future work.
Continuous:
Although our methods are evaluated in discrete state spaces, our approach can be generalized to continuous domains.
The Monte Carlo sampling in Equation [9](#A1.E9 "9 ‣ A.2 Estimating ∇_𝜃log{𝜋_𝑜} ‣ Appendix A Appendix ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") suggests that the use of continuous context may also be possible, given there is a strong enough function approximator to estimate the distribution of c|sconditional𝑐𝑠c|sitalic\_c | italic\_s.
We see this as an exciting direction for future work, to recover the full spectrum of possible adversarial policies under the constraint of Equation [2](#S4.E2 "2 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles").
The Semantics of Reward:
Although the minimization in Equation [2](#S4.E2 "2 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") implies a logical equivalence between the success of behaviour cloning to the reward the cloned policy can achieve, it may follow that this is not the case.
It may be the case that useless is defined differently by the expected reward the cloned policy achieves on a different reward function r~~𝑟\tilde{r}over~ start\_ARG italic\_r end\_ARG.
For example, a robot that is unpredictable should not be deployed with humans.
Since the r𝑟ritalic\_r functions in Equation [2](#S4.E2 "2 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") are disentangled,
the reward function r𝑟ritalic\_r that is minimized in Equation [2](#S4.E2 "2 ‣ 4.1 Objective ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") can be engineered to fit any definition of uselessness.
We can modify the objective of APE by modifying Equations [4](#S4.E4 "4 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") and [5](#S4.E5 "5 ‣ 4.2 Modified Policy Gradient Algorithm ‣ 4 Method ‣ Preventing Imitation Learning with Adversarial Policy Ensembles") to use a different reward function r~~𝑟\tilde{r}over~ start\_ARG italic\_r end\_ARG in the minimization, substituting R(t)𝑅𝑡R(t)italic\_R ( italic\_t ) for R~(t)=∑t′=tT−1γt′−tr~(st′,at′)~𝑅𝑡superscriptsubscriptsuperscript𝑡′𝑡𝑇1superscript𝛾superscript𝑡′𝑡~𝑟subscript𝑠superscript𝑡′subscript𝑎superscript𝑡′\tilde{R}(t)=\sum\_{t^{\prime}=t}^{T-1}\gamma^{t^{\prime}-t}\tilde{r}(s\_{t^{\prime}},a\_{t^{\prime}})over~ start\_ARG italic\_R end\_ARG ( italic\_t ) = ∑ start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = italic\_t end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T - 1 end\_POSTSUPERSCRIPT italic\_γ start\_POSTSUPERSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT - italic\_t end\_POSTSUPERSCRIPT over~ start\_ARG italic\_r end\_ARG ( italic\_s start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT ).
The rest of the derivation and algorithm remain the same.
We think this is an exciting direction, especially for learning all different possible representations of the worst-case experts.
7 Conclusion
-------------
We present APE as well as its mathematical formulation, and show that policy gradient, a basic RL algorithm can be used to optimize a policy ensemble that cannot be cloned.
We evaluated APE against baselines to show that adversarial behaviour is not feasible without our method.
This work identifies a novel yet crucial area in Reinforcement Learning, regarding the confidentiality of proprietary policies.
The essence of our approach is that a policy ensemble can achieve high return for the policy owner, while providing an external observer with a guaranteed low reward, making proprietary ensemble useless to the observer.
The formulation of our problem setup and the algorithm are very general.
In this first work we demonstrate the solution in the deliberately chosen simple environments in order to better visualize the essence of our method. In our concurrent work we study thoroughly the application of our method in various domains, which is out of the scope of this introductory paper.
8 Acknowledgements
-------------------
This work was supported in part by NSF under grant NRI-#1734633 and by Berkeley Deep Drive.
|
9b9c091c-2dd3-475b-a6dd-7aab61cad98c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
On liking things about crushes
Sometimes I have had crushes on people, and then all kinds of miscellaneous characteristics they had seemed good. Not just their face or their sense of style or the exact way they pronounce my name. But also things that would usually be considered unattractive. For instance, if they are balding, I might suddenly find myself excited by sparse head stubble, when I had previously liked luxuriant hair. And then subsequently I would be more attracted to every other balding guy I met.
I think this is not just directly because the person having those characteristics makes the characteristics by association the most excellent characteristics a person could have. Though that is maybe part of it (your face reminds me of…you!)
I think it is also because I implicitly infer that the person in question likes those characteristics, and I expect people to like me more if I like the things they like. For instance, if they are grumpy and have crumpled clothes, I think I implicitly infer that they like people being grumpy and wearing crumpled clothes, and that if I favor those things too, it will help us be friends. And I can appreciate a pretty wide range of things, so I implicitly give attention to the ones that are helpful.
So I suppose that I must implicitly believe everyone likes almost all of their characteristics. Explicitly, I think this is unlikely to be true. Though I do expect people relate more to people who share their characteristics, whether or not they like the characteristics. So maybe that is what I’m implicitly going for.
All this leads me to think that that my brain is probably doing a milder version of the thing it does with crushes with respect to other people who I like in less extreme ways all the time. “Ooh—I guess you like being mildly irritated! I can do that too! Grr. Do you like me?” It is just only so strong as to be introspectively perceptible in the case of crushes. Which I guess matches the observation that people copy each other a lot.
I have lon
|
3309318b-ca51-44bb-ad2f-f1117d794957
|
trentmkelly/LessWrong-43k
|
LessWrong
|
An explanation of the 'Many Interacting Worlds' theory of quantum mechanics (by Sean Carroll and Chip Sebens)
This is the first explanation of a 'many worlds' theory of quantum mechanics that has ever made sense to me. The animations are excellent:
http://www.preposterousuniverse.com/blog/2014/12/16/guest-post-chip-sebens-on-the-many-interacting-worlds-approach-to-quantum-mechanics/
|
f2ea73dd-1f21-4526-85f3-9472cd17de91
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Political topics attract participants inclined to use the norms of mainstream political debate, risking a tipping point to lower quality discussion
(I hope that is the least click-baity title ever.)
Political topics elicit lower quality participation, holding the set of participants fixed. This is the thesis of "politics is the mind-killer".
Here's a separate effect: Political topics attract mind-killed participants. This can happen even when the initial participants are not mind-killed by the topic.
Since outreach is important, this could be a good thing. Raise the sanity water line! But the sea of people eager to enter political discussions is vast, and the epistemic problems can run deep. Of course not everyone needs to come perfectly prealigned with community norms, but any community will be limited in how robustly it can handle an influx of participants expecting a different set of norms. If you look at other forums, it seems to take very little overt contemporary political discussion before the whole place is swamped, and politics becomes endemic. As appealing as "LW, but with slightly more contemporary politics" sounds, it's probably not even an option. You have "LW, with politics in every thread", and "LW, with as little politics as we can manage".
That said, most of the problems are avoided by just not saying anything that patterns matches too easily to current political issues. From what I can tell, LW has always had tons of meta-political content, which doesn't seem to cause problems, as well as standard political points presented in unusual ways, and contrarian political opinions that are too marginal to raise concern. Frankly, if you have a "no politics" norm, people will still talk about politics, but to a limited degree. But if you don't even half-heartedly (or even hypocritically) discourage politics, then a open-entry site that accepts general topics will risk spiraling too far in a political direction.
As an aside, I'm not apolitical. Although some people advance a more sweeping dismissal of the importance or utility of political debate, this isn't required to justify restricting poli
|
43f4c116-fad1-4499-86c9-f1cb0f925133
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Omega and self-fulfilling prophecies
Omega appears to you in a puff of logic, and presents you with a closed box. "If you open this box you will find either nothing or a million dollars," Omega tells you, "and the contents will be yours to keep." "Great," you say, taking the box, "sounds like I can't lose!" "Not so fast," says Omega, "to get that possible million dollars you have to be in the right frame of mind. If you are at least 99% confident that there's a million dollars in the box, there will be. If you're less confident than that, it will be empty. I'm not predicting the state of your mind in advance this time, I'm reading it directly and teleporting the money in only if you have enough faith that it will be there. Take as long as you like."
Assume you believe Omega. Can you believe the million dollars will be there, strongly enough that it will be?
|
25a93140-60ec-403d-92cc-c20e603a8223
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Weeping Agents
What is Agency? In a relatively intuitive way it’s a property of systems which have three things: Some –however rudimentary– way of modelling a slice of reality, a utility function over that slice of reality and a way of acting upon it. An agent can make better-than-chance guesses about how the behaviours in their action-pool would effect the world they inhabit and then pick the one whose modelled outcome scores best (according to expected utility, maximin or whatever risk-weighing you like) among the ones considered. They take a potential future and increase its likelihood of being instantiated. We can now switch perspectives and describe them according to the more elegant –though to many less intuitive– cybernetic definition: Agents are mechanisms by which the future influences the past. To be such a mechanism one has to be able to make better-than-noise guesses about the future, have beliefs about which ones are desirable and then act in the present to make them come to pass. Agents are löbian knots in causality. Things happening because something saw that they could happen. Proof by being provable.
Weeping Angels are an alien species from the long-running sci-fi series Doctor Who. They look like statues and have a number of other interesting qualities, but the only one that’s important for this point is that “anything which holds the image of an angel becomes an angel”.
Here are two true true statements which might be assigned the same headline as the argument I’m making but which aren’t the point:
* There is a sense in which agents actively try to realign other agents towards their ends or to turn non-agentic parts of their domain into agents aligned to their values because this is a very powerful, very versatile strategy. We are doing the former constantly and are half-heartedly trying at the latter in a bumbling, suicidal sort of way.
* There is also a sense in which powerful agents exert loads of selection pressure upon a system, and systems under suffi
|
f0323afe-fa4a-41ec-9200-da82bffdff72
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Weekly LW Meetups
This summary was posted to LW Main on February 6th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Czech's first Meetup Prague: 16 February 2015 06:00PM
Irregularly scheduled Less Wrong meetups are taking place in:
* Bangalore LWers meetup: 07 February 2015 11:00AM
* Dallas, TX: 08 February 2015 01:00PM
* European Community Weekend 2015: 12 June 2015 12:00PM
* [Frankfurt] Another Frankfurt meetup: 22 February 2015 02:00PM
* [Netherlands] Effective Altruism Netherlands: Effective Altruism for the masses: 15 February 2015 02:00PM
* [Netherlands] Effective Altruism Netherlands: Tell us the thing you find important: 15 February 2015 02:00PM
* [Netherlands] Effective Altruism Netherlands: Present the charity you'd like to give to: 01 March 2015 02:00PM
* [Netherlands] Effective Altruism Netherlands: Small concrete actions you could take: 29 March 2015 01:00PM
* Warsaw February Meetup: 21 February 2015 06:00PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Austin, TX - Fun and Games - Caffe Medici: 07 February 2026 01:30PM
* Brussels February meetup: Words: 14 February 2015 01:00PM
* Canberra Less Wrong Meet Up - Favourite Sequence Post + Discussion: 14 February 2015 06:00PM
* Sydney Meetup - February: 25 February 2015 06:30PM
* Vienna: 21 February 2015 03:00PM
* Washington, D.C.: Fun & Games: 08 February 2015 03:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Boston, Brussels, Buffalo, Cambridge UK, Canberra, Columbus, London, Madison WI, Melbourne, Moscow, Mountain View, New York, Philadelphia, Research Triangle NC, Seattle, Sydney, Toronto, Vienna, Washington DC, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers.
If you'd like to talk with other LW-ers face to face, and there is no m
|
d8c4ebad-cc4b-4132-87c7-bed57116ac82
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Spoiler-Free Review: Horizon Zero Dawn
Previously: Spoiler-Free Review: Witcher 3: Wild Hunt (plus a Spoilerific section), Spoiler-Free Review: Assassin’s Creed Odyssey
This review of a giant open world game is being written on July 7. That’s three days after the review of Witcher 3 was posted.
You can guess it’s not going to be a ringing endorsement.
Horizon Zero Dawn seems to be a Tier 4 game. I spent most of my time either frustrated, pissed off, or waiting for something interesting to happen. There were periods of satisfying combat, and some potentially interesting aspects of the world building, but my lord on reflection was that a bad experience.
I say seems to be because when one quits this early in a game, missing most of what it has to offer, and lots of others love it, one presumes one is likely missing something. I encourage those who told me I should choose this game next – it got 40%+ of a 4-way Twitter poll, and an endorsement in a comment – to explain why it’s secretly good.
Here I am going to talk about why it seems terrible.
This isn’t a ‘I criticize because I love’ post. This is a ‘I criticize because other people love and I can’t figure out why’ post.
Jump To Your Death, No Chance to Save
In general, if you fall, you die.
The game has lots of points early in the game where you have to jump in exactly the right place. If you jump elsewhere, you fall, and you die.
The game resets, often forcing a lot of doing things over. At least the load times were quick. If the load times had been slower I would have quit very quickly.
You see, you can only save at a campfire, or when the game chooses to save for you.
What finally caused the rage-quit was when I spent ten minutes replaying a quest sequence to where I jumped and died trying to follow the game’s narrative instructions, used a walk-through video to see what I was supposed to do, jumped slightly wrong trying to trigger something, and died again. I mean, I can’t take it. My life is too short and I have enough things to rage ab
|
ce80f6c9-1690-41ec-95a7-d89f8b6201db
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Urgent & important: How (not) to do your to-do list
The Eisenhower Box is a well-known, simple decision matrix for dealing with tasks such as a to-do list, based on whether they’re urgent or important.
I reckon it has multiple flaws. But by fixing each flaw in turn, we end up with a better matrix, which I'll call Hopscotch. It's much more useful for planning your day, and can also be simplified further.
What to do?
The great problem of life is what to do. Your life consists of millions of decisions large and small, from making coffee to running for President. Which should you do, and when, and how?
There’s all the things to be done at work and home, constant demands and distractions, unfulfilled ambitions at the back of your mind – and barely time to think, let alone get through all this stuff.
Happily, a box has been invented to help you out. A bit like an Amazon Echo – but made only of paper & ink – it not only tells you how to deal with everything on your plate, but magically makes some of it disappear.
Or so it is claimed.
The box
The Eisenhower Box (or Matrix) was invented by Stephen Covey in his bestseller The 7 Habits of Highly Effective People. It was later named after US President Dwight Eisenhower, who once said:
> “I have two kinds of problems, the urgent and the important. The urgent are not important, and the important are never urgent.”
The point being, people spend too much time on urgent-seeming but unimportant distractions, instead of on important, non-urgent matters – such as planning, people, and future opportunities. Short-term trivia divert you from what really counts.
To solve this, the Eisenhower Box tells you what to do with each task that happens along, based on whether it’s important or urgent:[1]
The kind of tasks that end up in each cell, starting top-left, are:
* Important & Urgent (green): things that need action ASAP, such as important meetings/calls/emails, tight deadlines, and crises. They’ve got to be done, so – like the box says – you’d better Do them.
* Important & N
|
f568aa43-f3d8-4197-9461-db6adef21230
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Does a time-reversible physical law/Cellular Automaton always imply the First Law of Thermodynamics?
This question is kind of self-explanatory, but for people who are physicists, if a time reversible rule of physics/cellular automaton exists in a world, does this automatically imply the first law of thermodynamics, that is energy may not be created or destroyed?
Note I'm not talking about time-symmetry or the 2nd law of thermodynamics, which states that you can't have a 100% efficient machine, just time-reversible physical laws/cellular automatons and the first law of thermodynamics.
Edit: @jacob_drori has clarified what exactly I'm supposed to be asking, so the edited question is this:
Do you always get time-symmetric physical laws that are symmetric for any T, out of time-reversible physical laws?
The question of do you always get time-symmetric physical laws from time reversible laws is also a valid question to answer here, but the important part for the first law of thermodynamics to hold is that it's symmetric for all times T, and in principle, the question of time reversible laws of physics always implying time symmetry could have a positive answer while having a negative answer to the original question, because it doesn't imply time symmetric laws of physics for all T.
|
bff98626-4ed4-43ef-8530-2d9483f1342d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Friendship and happiness generation
Happiness and utility are different things, with happiness (measured in hedons) generally referring to the desirability of an agent being in its current mental state, while utility (measured in utils) refers to the desirability, from the point of view of some agent, of the configuration of the universe.
Naively, one could model caring about another person as having a portion of your utility function allocated to mimicking their utility (me.utility(universe) = caring_factor*friend.utility(universe) + me.utility(universe excluding value of friend's utility function)) or their happiness (me.utility(universe) = caring_factor*friend.happiness + me.utility(universe excluding friend's happiness)). However, I think these are bad models of how caring for people actually works in humans.
I've noticed that I often gladly give up small amounts of hedons so that someone I care about can gain a similar amount of hedons. Extrapolating this, one might conclude that I care about plenty of other people nearly as much as I care about myself. However, I would be much less likely to give up a large amount of hedons for someone I care about unless the ratio of hedons that they could gain over the hedons I would have to give up is also fairly large.
While trying to figure out why this is, I realized that whenever I think I'm sacrificing hedons for someone, I usually don't actually lose any hedons because I enjoy the feeling associated with knowing that I helped a friend. I expect that this reaction is fairly common. This implies that by doing small favors for each other, friends can generate happiness for both of them even when the amount of hedons sacrificed by one (not counting the friend-helping bonus) is similar to the amount of hedons gained by the other. However, this happiness bonus for helping a friend is bounded, and grows sublinearly with respect to the amount of good done to the friend. In terms of evolutionary psychology, this makes sense: seeking out cheap ways to signal l
|
7124cbd8-3dc2-4959-b985-15f55f77ea09
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
“X distracts from Y” as a thinly-disguised fight over group status / politics
1. Introduction
===============
There’s a popular argument that says:
> It’s bad to talk about whether future AI algorithms might cause human extinction, because that would be a distraction from the fact that current AI algorithms are right now causing or exacerbating societal problems (misinformation, deepfakes, political polarization, algorithmic bias, maybe job losses, etc.)
>
>
For example, Melanie Mitchell makes this argument (link & my reply [here](https://www.lesswrong.com/posts/LNwtnZ7MGTmeifkz3/munk-ai-debate-confusions-and-possible-cruxes)), as does Blake Richards (link & my reply [here](https://www.lesswrong.com/posts/rgPxEKFBLpLqJpMBM/response-to-blake-richards-agi-generality-alignment-and-loss)), as does Daron Acemoglu (link & a reply by Scott Alexander [here](https://www.astralcodexten.com/p/contra-acemoglu-onoh-god-were-doing) & [here](https://www.astralcodexten.com/p/when-does-worrying-about-things-trade)), and many more.
In Section 2 I will argue that if we try to flesh out this argument in the most literal and straightforward way, it makes no sense, and is inconsistent with everything else these people are saying and doing. Then in Section 3 I’ll propose an alternative elaboration that I think is a better fit.
I’ll close in Section 4 with two ideas for what we can do to make this problem better.
(By *“we”*, I mean “people like me who are very concerned about future AI extinction risk (x-risk[[1]](#fngejhruwf4fl))”. That’s my main intended audience for this piece, although everyone else is welcome to listen in too. If you’re interested in why someone might believe that future AI poses an x-risk in the first place, you’re in the wrong place—try [here](https://80000hours.org/problem-profiles/artificial-intelligence/) or [here](https://www.alignmentforum.org/posts/4basF9w9jaPZpoC8R/intro-to-brain-like-agi-safety-1-what-s-the-problem-and-why).)
2. Wrong way to flesh out this argument: This is about zero-sum attention, zero-sum advocacy, zero-sum budgeting, etc.
======================================================================================================================
If we take the “distraction” claim above at face value, maybe we could flesh it out as follows:
> Newspapers can only have so many front-page headlines per day. Lawmakers can only pass so many laws per year. Tweens can only watch so many dozens of TikTok videos per second. In general, there is a finite supply of attention, time, and money. Therefore, if more attention, time, and money is flowing to Cause A (= future AI x-risk), then that means there’s *less* attention, time and money left over for any other Cause B (= immediate AI problems).
>
>
I claim that this is *not* the type of claim that people are making. After all, if that’s the logic, then the following would be equally sensible:
* “It’s bad to talk about police incompetence, because it’s a distraction from talking about police corruption.”
* “It’s bad to talk about health care reform, because it’s a distraction from talking about climate change.”
Obviously, nobody makes those arguments. (Well, *almost*nobody—see next subsection.)
Take the first one. I think it’s common sense that concerns about police incompetence do not distract from concerns about police corruption. After all, why would they? It’s not like newspapers have decided *a priori* that there will be one and only one headline per month about police problems, and therefore police incompetence and police corruption need to duke it out over that one slot. If anything, it’s the opposite! If police incompetence headlines are getting clicks, we’re likely to see *more* headlines on police corruption, not fewer. It’s true that the *total*number of headlines is fixed, but it’s perfectly possible for police-related articles to *collectively*increase, at the expense of articles about totally unrelated topics like Ozempic or real estate.
By the same token, there is no good reason that concerns about future AI causing human extinction should be a distraction from concerns about current AI:
* *At worst,* they’re two different topics, akin to the silly idea above that talking about health care reform is a problematic distraction from talking about climate change.
* *At best,* they are *complementary*, and thus akin to the *even sillier* idea above that talking about police corruption is a problematic distraction from talking about police incompetence.
Supporting the latter perspective, **immediate AI problems are not an entirely different problem from possible future AI x-risk**. Some people think they’re *extremely* related—see for example [Brian Christian’s book](https://brianchristian.org/the-alignment-problem/). I don’t go as far as he does, but I do see some synergies. For example, both current social media recommendation algorithm issues and future AI x-risk issues are exacerbated by the fact that huge trained ML models are very difficult to interpret and inspect. By the same token, if we work towards international tracking of large AI training runs, it might be useful for *both* future AI x-risk mitigation *and* ongoing AI issues like disinformation campaigns, copyright enforcement, AI-assisted spearphishing, etc.
2.1 Side note on Cause Prioritization
-------------------------------------
I said above that “nobody” makes arguments like “It’s bad to talk about health care reform, because it’s a distraction from talking about climate change”. That’s an exaggeration. Some weird nerds like me do say things *kinda* like that, in a certain context. That context is called [Cause Prioritization](https://forum.effectivealtruism.org/topics/cause-prioritization), a field of inquiry usually associated these days with [Effective Altruism](https://www.effectivealtruism.org/articles/introduction-to-effective-altruism). The whole shtick of Cause Prioritization is to take claims like the above seriously. If we only have so much time in our life and only so much money in our bank account, then there *are* in fact tradeoffs (on the margin) between spending it to fight for health care reform, versus spending it to fight for climate change mitigation, versus everything else under the sun. Cause Prioritization discourse can come across as off-putting, and even offensive, because you inevitably wind up in a position where you’re arguing *against* lots of causes that you actually care deeply and desperately about. So most people just reject that whole enterprise. Instead they don’t think explicitly about those kinds of tradeoffs, and insofar as they want to make the world a better place, they tend to do so in whatever way seems most salient and emotionally compelling, perhaps because they have a personal connection, etc. And that’s fine.[[2]](#fnc7dc9jjrmn) But Cause Prioritization is about facing those tradeoffs head-on, and trying to do so in a principled, [other-centered](https://forum.effectivealtruism.org/posts/iupkbiubpzDDGRpka/other-centered-ethics-and-harsanyi-s-aggregation-theorem) way.
If you want to do Cause Prioritization properly, then you have to dive into (among other things) a horrific minefield of quantifying various awfully-hard-to-quantify things like “[what’s my best-guess probability distribution for how long we have until future x-risk-capable AI may arrive?](https://www.cold-takes.com/forecasting-transformative-ai-whats-the-burden-of-proof/)”, or “exactly how many suffering chickens are equivalently bad to one suffering human?”, or “how do we weigh better governance in Spain against preventing malaria deaths?”.
Anyway, I would be shocked if anyone saying “we shouldn’t talk about future AI risks because it’s a distraction from current AI problems” arrived at that claim via a good-faith open-minded attempt at Cause Prioritization.
Indeed, as mentioned above, there *are*people out there who do try to do Cause Prioritization analyses, and “maybe future AI will cause human extinction” tends to score right at or near the top of their lists. ([Example](https://80000hours.org/problem-profiles/).)
2.2 Conclusion
--------------
So in conclusion, people say “concerns about future AI x-risks distract from concerns about current AI”, but if we flesh out that claim in a superficial, straightforward way, then it makes no sense.
…And that was basically where Scott Alexander left it in [his post on this topic](https://www.astralcodexten.com/p/when-does-worrying-about-things-trade) (from which I borrowed some of the above examples). But I think Scott was being insufficiently cynical. I offer this alternative model:
3. Better elaboration: This is about zero-sum group status competition
======================================================================
I don’t think anyone is *explicitly* thinking like the following, but let’s at least consider the possibility that something like this is lurking below the surface:
> If we endorse actions to mitigate x-risk from future AIs, we’re implicitly saying *“the people who are the leading advocates of x-risk mitigation, e.g. Eliezer Yudkowsky, were right all along.”* Thus, we are granting those people status and respect. And thus *everything else* that those same people say and believe—especially but not exclusively on the topic of AI—implicitly gets more benefit-of-the-doubt.
>
> Simultaneously on the other side, if we endorse actions to mitigate x-risk from future AIs, we’re implicitly saying *“the people who are leading advocates against x-risk mitigation, e.g. Timnit Gebru, were wrong all along.”* Thus, we are sucking status and respect *away* from those people. And thus *everything else* that those people say and believe—especially but not exclusively on the topic of AI—gets some guilt-by association.
>
> Now, the former group of people seem much less concerned about immediate AI concerns like AI bias & misinformation than the latter group. *[Steve interjection: I don’t think it’s that simple—see Section 4.2 below—but I do think some people currently believe this.]* So, if we take actions to mitigate AI x-risk, we will be harming the cause of immediate AI concerns, via this mechanism of raising and lowering people’s status, and putting “the wrong people” on the nightly news, etc.
>
>
Do you see the disanalogy to the police example? The people most vocally concerned about police incompetence, versus the people most vocally concerned about police corruption, are generally *the very same people*. If we elevate those people as reliable authorities, and let them write op-eds, and interview them on the nightly news, etc., then we are simultaneously implicitly boosting all of the causes that these people are loudly advocating, i.e. we are advancing *both* the fight against police incompetence *and* the fight against police corruption.
As an example in the other direction, if a left-wing USA person said:
> It’s bad for us to fight endless wars against drug cartels—it’s a distraction from compassionate solutions to drug addiction, like methadone clinics and poverty reduction.
>
>
…then that would sound perfectly natural to me! Uncoincidentally, in the USA, the people advocating for sending troops to fight drug cartels, and the people advocating for poverty reduction, tend to be political adversaries on almost every other topic!
4. Takeaways
============
4.1 Hey AI x-risk people, let’s make sure we’re not pointlessly fanning these flames
------------------------------------------------------------------------------------
As described above, there is no *good* reason that taking actions to mitigate future AI x-risk should harm the cause of solving immediate AI-related problems; if anything, it should be the opposite.
So: we should absolutely, unapologetically, advocate for work on mitigating AI x-risk. But we should not advocate for work on mitigating AI x-risk *instead of working on immediate AI problems*. That’s just a stupid, misleading, and self-destructive way to frame what we’re hoping for. To be clear, I think this kind of weird stupid framing is *already* very rare on “my side of the aisle”—and far outnumbered by people who advocate for work on x-risk and then advocate for work on existing AI problems in the very next breath—but I would like it to be even rarer still.
(I wouldn’t be saying this if I didn’t see it *sometimes*; [here’s an example of me responding to (what I perceived as) a real-world example on twitter](https://twitter.com/steve47285/status/1683226281972756480).)
In case the above is not self-explanatory: I am equally opposed to saying we should work on mitigating AI x-risk *instead of working on the opioid crisis*, and for the same reason. Likewise, I am equally opposed to saying we should fight for health care reform *instead of fighting climate change*.
I’m not saying that we should suppress these kinds of messages because they make us look bad (although they obviously do); I’m saying we should suppress these kinds of messages because they are misleading, for reasons in Section 2 above.
To make my request more explicit: If I’m talking about how to mitigate x-risk, and somebody changes the subject to immediate AI problems that don’t relate to x-risk, then I have no problem saying “OK sure, but afterwards let’s get back to the human extinction thing we were discussing before….” Whereas I would *not* say “Those problems *you’re* talking about are much less important than the problems *I’m* talking about.” Cause Prioritization is great for what it is, but it's not a conversation norm. If someone is talking about something they care about, it's fine if that thing isn't related to alleviating the maximum amount of suffering. That doesn't give you the right to change the subject. Notice that even the most ardent AI x-risk advocates seem quite happy to devote substantial time to non-cosmologically-impactful issues that *they* care about—NIMBY zoning laws are a typical example. And that’s fine!
Anyway, if we do a good job of making a case that literal human extinction from future AI is a real possibility on the table, then we win the argument—the Cause Prioritization will take care of itself. So that’s where we need to be focusing our communication and debate. Keep saying: “Let’s go back to the future-AI-causing-human-extinction thing. Here’s why it’s a real possibility.” Keep bringing the discussion back to that. Head-to-head comparisons of AI x-risk versus other causes tend to push discussions *away* from this all-important crux. Such comparisons would be a (ahem) *distraction*!
4.2 Shout it from the rooftops: There are people of all political stripes who think AI x-risk mitigation is important (and there are people of all political stripes who think it’s stupid)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Some people have a strong opinion about “silicon valley tech people”—maybe they love them, or maybe they hate them. Does that relate to AI x-risk discourse? Not really! Because it turns out that “silicon valley tech people” includes many of the most enthusiastic believers in AI x-risk (e.g. see [the New York Times profile of Anthropic](https://www.nytimes.com/2023/07/11/technology/anthropic-ai-claude-chatbot.html), a leading AI company in San Francisco) *and* it *also* includes many of its most enthusiastic doubters (e.g. [tech billionaire Marc Andreessen:](https://a16z.com/ai-will-save-the-world/) “The era of Artificial Intelligence is here, and boy are people freaking out. Fortunately, I am here to bring the good news: AI will not destroy the world…”).
Likewise, some people have a strong opinion (one way or the other) about “the people extremely concerned about current AI problems”. Well, it turns out that this group likewise includes *both* enthusiastic believers in future AI x-risk (e.g. Tristan Harris) *and* enthusiastic doubters (e.g. Timnit Gebru).
By the same token, you can find people taking AI x-risk seriously [in Jacobin magazine on the American left](https://jacobin.com/2022/09/socialism-longtermism-effective-altruism-climate-ai), or [on Glenn Beck on the American right](https://www.lesswrong.com/posts/FGWfTxsXk7euh4QGk/i-think-eliezer-should-go-on-glenn-beck); in fact, [a recent survey of the US public](https://forum.effectivealtruism.org/posts/Rg7h7G3KTvaYEtL55/us-public-perception-of-cais-statement-and-the-risk-of) got supportive responses from Democrats, Republicans, and Independents—all to a quite similar extent—to questions about AI extinction risk being a global priority.[[3]](#fni7i3dzff06b)
I think this situation is good and healthy, and I hope it lasts, and we should try to make it widely known. I think that would help fight the “X distracts from Y” objection to AI x-risk, in a way that complements the kinds of direct, object-level counterarguments that I was giving in Section 2 above.
[*(Also posted on lesswrong)*](https://www.lesswrong.com/posts/uA4Dmm4cWxcGyANAa/x-distracts-from-y-as-a-thinly-disguised-fight-over-group)
1. **[^](#fnrefgejhruwf4fl)**There are fine differences between “extinction risk” and “x-risk”, but it doesn’t matter for this post.
2. **[^](#fnrefc7dc9jjrmn)**Sometimes I try to get people *excited* about the idea that they could have a very big positive impact on the world via incorporating a bit of Cause Prioritization into their thinking. [(Try this great career guide!)](https://80000hours.org/career-guide/) Sometimes I even feel a bit sad or frustrated that such a tiny sliver of the population has any interest whatsoever in thinking that way. But none of that is the same as *casting judgment* on those who don’t—it’s supererogatory, in my book. For example, practically none of my in-person friends have heard of Cause Prioritization or related ideas, but they’re still great people who I think highly of.
3. **[^](#fnrefi7i3dzff06b)**Party breakdown results were not included in the [results post](https://forum.effectivealtruism.org/posts/Rg7h7G3KTvaYEtL55/us-public-perception-of-cais-statement-and-the-risk-of), but I asked Jamie Elsey of Rethink Priorities and he kindly shared those results. It turns out that the support / oppose and agree / disagree breakdowns were universally the same across the three groups (Democrats, Independents, Republicans) to within *at most* 6 percentage points. If you look at the overall plots, I think you’ll agree that this counts as “quite similar”.
|
24a14ffb-2c6f-4fd4-ae9f-0214f683e235
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Agency As a Natural Abstraction
Epistemic status: Speculative attempt to synthesize findings from several distinct approaches to AI theory.
Disclaimer: The first three sections summarize some of Chris Olah's work on interpretability and John Wentworth's Natural Abstractions Hypothesis, then attempt to draw connections between them. If you're already familiar with these subjects, you can probably skip all three parts.
Short summary: When modelling a vast environment where simple rules result in very complex emergent rules/behaviors (math, physics...), it's computationally efficient to build high-level abstract models of this environment. Basic objects in such high-level models often behave very unlike basic low-level objects, requiring entirely different heuristics and strategies. If the environment is so complex you build many such models, it's computationally efficient to go meta, and build a higher-level abstract model of building and navigating arbitrary world-models. This higher-level model necessarily includes the notions of optimization and goal-orientedness, meaning that mesa-optimization is the natural answer to any "sufficiently difficult" training objective. All of this has various degrees of theoretical, empirical, and informal support.
----------------------------------------
1. The Universality Hypothesis
One of the foundations of Chis Olah's approach to mechanistic interpretability is the Universality Hypothesis. It states that neural networks are subject to convergence — that they would learn to look for similar patterns in the training data, and would chain up the processing of these patterns in similar ways.
The prime example of this effect are CNNs. If trained on natural images (even from different datasets), the first convolution layer reliably learns Gabor filters and color-contrast detectors, and later layers show some convergence as well:
Analogous features across CNNs. Source.
It's telling that these features seem to make sense to us, as well — that at least one type
|
d3c65495-539a-4639-b022-efadd9575dcd
|
trentmkelly/LessWrong-43k
|
LessWrong
|
$100 for the best article on efficient charty - the winner is ...
Part of the Efficient Charity Article competition. Several people have written articles on efficient charity. The entries were:
* Throwawayaccount_1
* Waitingforgodel
* Multifoliaterose
* Louie
The original criteria for the competition are listed here, but bascially the idea is to introduce the idea to a relatively smart newcomer without using jargon.
Various people gave opinions about which articles were best. For me, two articles in particular stood out as being excellent for a newomer. Those articles were:
Throwawayaccount_1
and
Multifoliaterose's
articles.
I therefore declare them joint winners, and implore our kind sponsor Jsalvatier to split the prize between them evenly. Throwawayaccount_1 should also unmask his/her identity.
[I would also ask the winners to kindly not offer to donate the money to charity, but to actually take the prize money and spend it on something that they selfishly-want, such as ice-cream or movie tickets or some other luxury item. Establishing a norm of giving away prizes creates very bad incentives and will tend to decrease the degree to which prizes actually motivate people in the future]
|
5fa7e316-8860-4a85-b16e-addb7e1a1d5e
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
An Untrollable Mathematician Illustrated
The following was a presentation I made for Sören Elverlin's [AI Safety Reading Group](https://www.youtube.com/watch?v=ql4Y0-jEKhw). I decided to draw everything by hand because powerpoint is boring. Thanks to Ben Pace for formatting it for LW! See also [the IAF post](https://agentfoundations.org/item?id=1750) detailing the research which this presentation is based on.
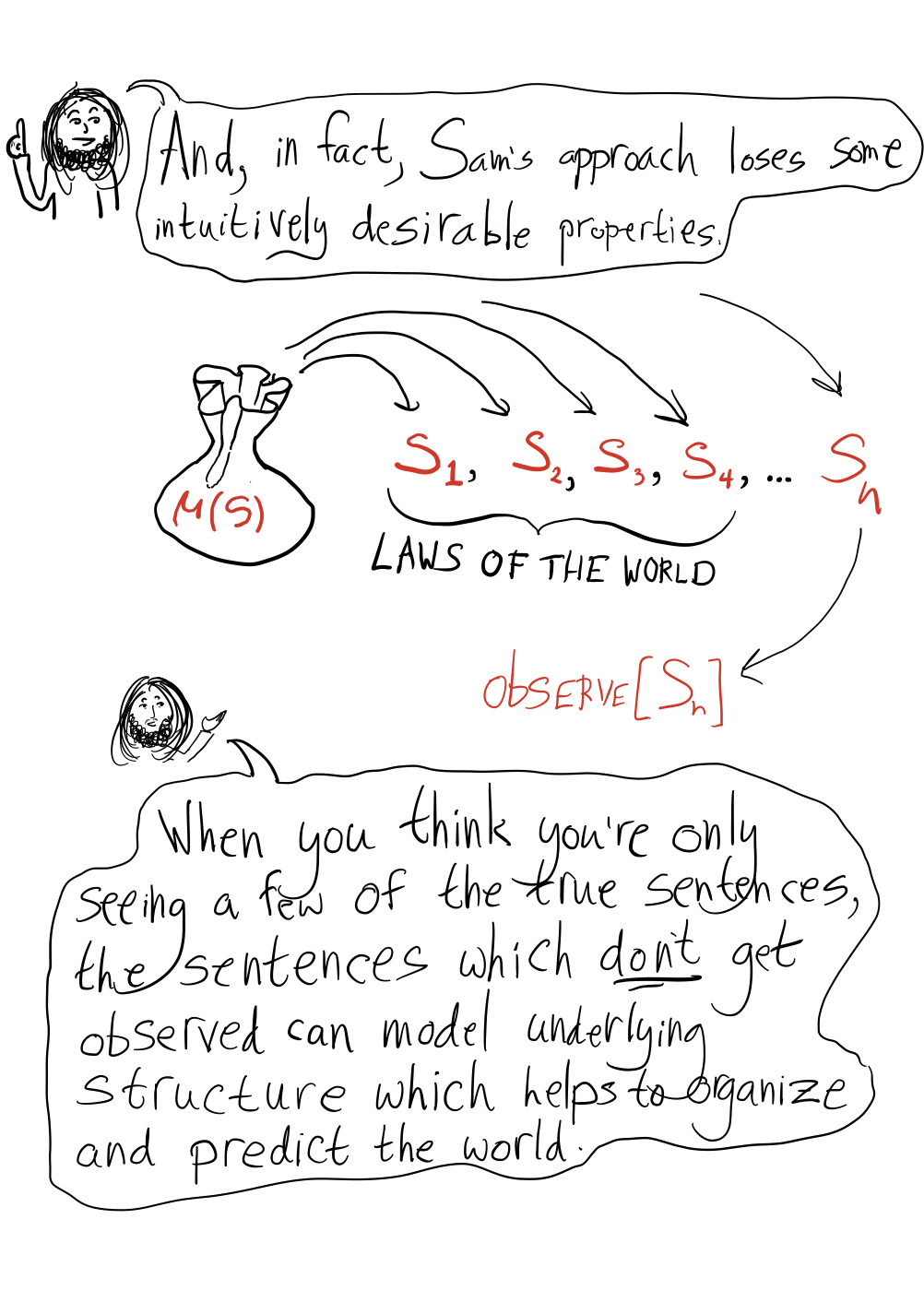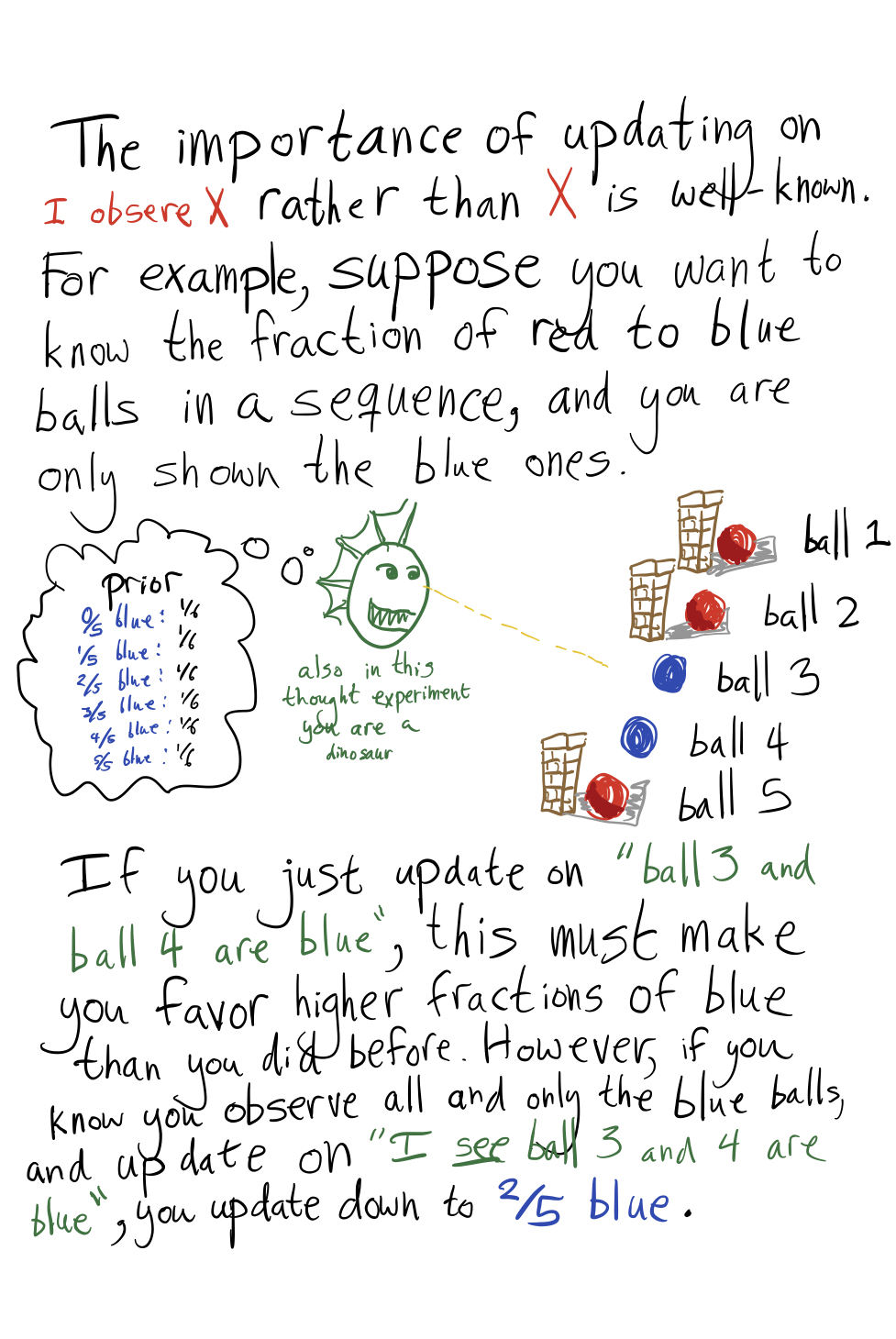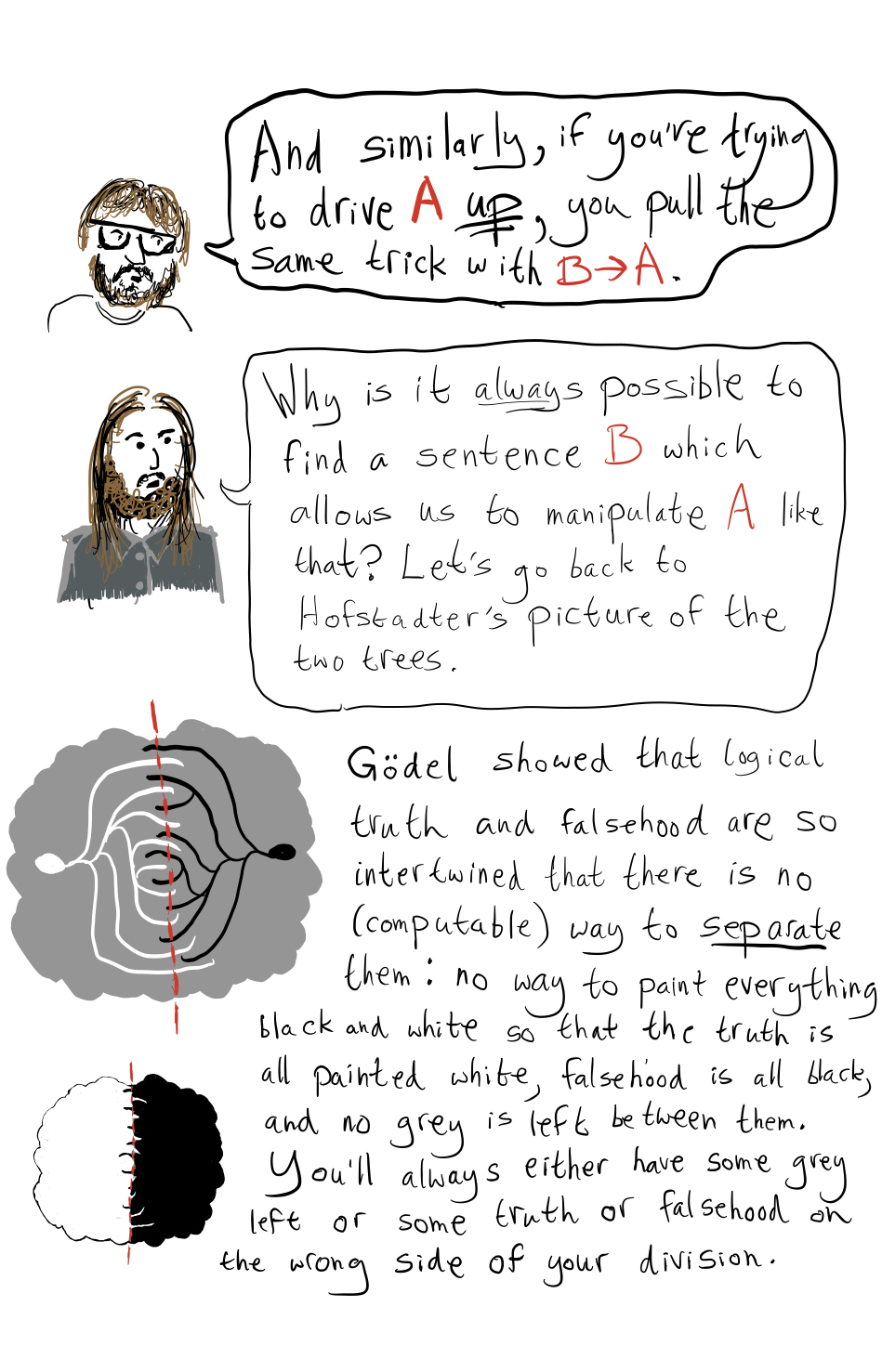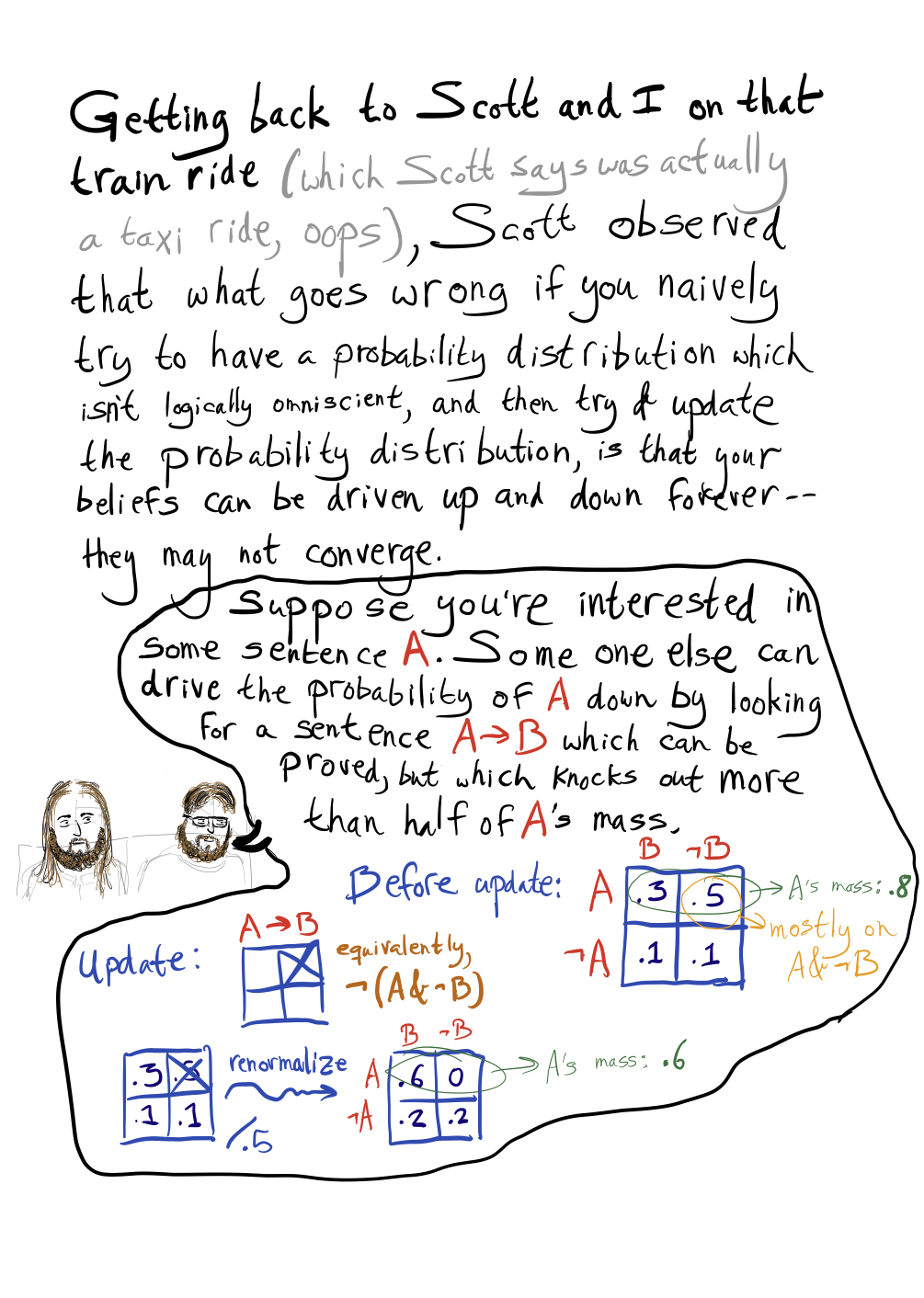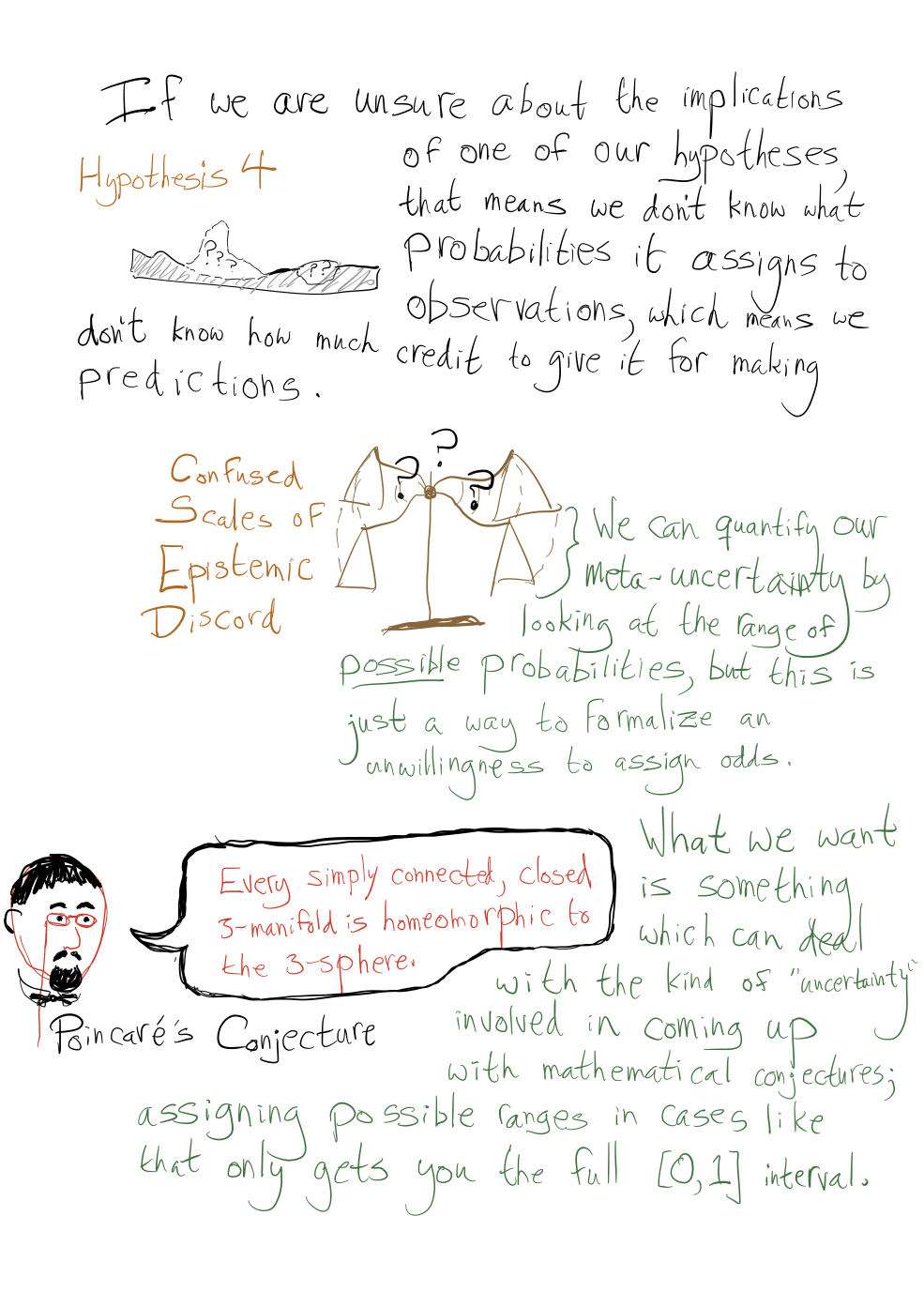
|
e4e605e6-4071-409b-b580-a9348b6c6353
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Jazz meetup in Philadelphia
Discussion article for the meetup : Jazz meetup in Philadelphia
WHEN: 10 February 2012 06:00:00PM (-0500)
WHERE: Woodmere Art Museum, 9201 Germantown Avenue Philadelphia, PA 19118
Consider this one a "just for fun" event, rather than a "hard" meetup (such as we will be having on Wednesday the 15th!) dealing with more serious rationality-related topics.
The Woodmere Art Museum in Chestnut Hill holds jazz concerts every Friday. A couple of us are attending this Friday's concert, "Tribute to Miles Davis: A Kinda Blue Valentine" featuring Philadelphia trumpeter Tony Smith; feel free to come out and meet some area Less-Wrongers, particularly if you weren't in the area for our last meetup!
Tickets are $15 for Woodmere members or $20 for the general public, and are available at the door or online (http://woodmereartmuseum.org/music.html). Feel free to message me for my cell in case you're afraid you might have trouble finding the place!
If turnout is good and people are interested, we may also venture out into Chestnut Hill or elsewhere for food/coffee after the concert ends at 8. Hope to see you there!
Discussion article for the meetup : Jazz meetup in Philadelphia
|
18b95f85-ac59-4fb8-8703-f540c73d275e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Under-Appreciated Ways to Use Flashcards - Part II
By Tereza Ruzickova
TL;DR
In my first article, I outlined how significant flashcard learning has been for me and how I utilize it in many different - often unexpected - areas of my life. In this article, I will share some practical strategies for making the flashcard habit stick. Most of these I've learned the hard way over the past ten years (while accumulating more than 40 000 cards!). Here are my key takeaways from the article.
1. I make notes whenever something interesting crops up using a convenient note-taking app like Things or Thought Saver.
2. I regularly distill these notes into atomic, concise flashcards
3. I have my decks loosely organized into Everything, ASAP, Therapy Skills, Spanish and German
4. I built a daily habit using the Tiny Habits approach - just five cards a day.
5. The easiest times for me to revise are when I am not groggy/distracted by work
How I create and organize my flashcards
For the past few years, I have found that the most variable that determines whether I regularly create new cards is convenience. When I set up a super convenient information-gathering method for any facts that have flashcard potential, I am much more likely to make and revise flashcards alongside everything else that I do.
I have found the software Things to work really well for me, especially their keyboard shortcut that creates new notes very quickly and effortlessly both on the phone and desktop. This way, I easily note down anything that I want to remember throughout the day - whether it's fun facts I hear on podcasts, gratitude moments I experience, or even life lessons that randomly occur to me. You can also effortlessly create cards directly into the Thought Saver mobile app.
About once a week, I then go through all of these notes, filter out any that no longer seem interesting, and start creating new cards. I always aim to keep each card as simple as possible, which often means having to break things down into several cards and strippi
|
4b7f991a-ddd2-4680-aaa7-430925d7abcc
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Dating Roundup #5: Opening Day
Previously: #1, #2, #3, #4.
Since we all know that dating apps are terrible, the wise person seeks to meet prospective dates in other ways, ideally in the physical world.
Alas, this has gotten more difficult. Dating apps and shifting norms mean it is considered less appropriate, and riskier, to approach strangers, especially with romantic intent, or to even ask people you know out on a date, which has a fat tail of life changing positive consequences.
People especially men are increasingly more afraid of rejection and other negative consequences, including a potential long tail of large negative consequences. Also people’s skills at doing this aren’t developing, which both decreases chances of success and increases risk. So a lot of this edition is about tackling those basic questions, especially risk, rejection and fear.
There’s also the question of how to be more hot and know roughly how hot you are, and what other traits also help your chances. And there’s the question of selection. You want to go after the targets worth going after, especially good particular matches.
TABLE OF CONTENTS
1. You’re Single Because Hello Human Resources.
2. You’re Single Because You Don’t Meet Anyone’s Standards.
3. You’re Single Because You Don’t Know How to Open.
4. You’re Single Because You Never Open.
5. You’re Single Because You Don’t Know How to Flirt.
6. You’re Single Because You Won’t Wear the Fucking Hat.
7. You’re Single Because You Don’t Focus On The People You Want.
8. You’re Single Because You Choose the Wrong Hobbies.
9. You’re Single Because You Friend Zone People.
10. You’re Single Because You Won’t Go the Extra Mile.
11. You’re Single Because You’re Overly Afraid of Highly Unlikely Consequences.
12. You’re Single Because You’re Too Afraid of Rejection.
13. You’re Single Because You’re Paralyzed by Fear.
14. You’re Single Because You’re Not Hot Enough.
15. You’re Single Because You Can’t Tell How Hot You Look.
16. You’re Single Because
|
8a2edec5-5235-4a64-814d-7f99f9d21b30
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Acausal trade: conclusion: theory vs practice
When I started this dive into acausal trade, I expected to find subtle and interesting theoretical considerations. Instead, most of the issues are practical.
----------------------------------------
Theory
The big two theoretical questions are whether we model infinite worlds with infinitely many agents, and whether we should agree to some 'pre-existence' deal with all agents, including those that don't and cannot exist. We lay aside the infinite case for the time being; pre-existence deals simply lead to all agents maximising a single utility joint function. There are many issues with that - why would the agents accept a deal that gives them nothing at the moment they accept it, how can the agents share a common prior, how much effort are they required to make to not deal with logically impossible agents, and so on - but it's a possible option.
Practice
Without prexistence deals, then the situation is not hard to model, and though practical issues seems to dominate acausal trade. There is the perennial issue of how to divide gains from trade and how to avoid extortion. There is a "Double decrease": when an acausal trade network has fewer contributors, then those contributors also contribute less (since they derive lower advantage from doing so), compounding the decrease (and a converse result for larger trade networks).
There are many reasons an acausal trade network could be smaller. All agents could be unusual and distinct, making it almost impossible to figure out what agents actually exist. The different utilities could fail to be compatible in various ways. The agent's decision algorithms and concepts of fairness could be incompatible. And many agents could be deliberately designed to not engage in acausal trade.
Against that all, the number N of potential agents could be so absurdly high that a lot of acausal trade happens anyway. This is probably necessary, to compensate for the extreme guesswork that goes into acausal trade: all the other agents exis
|
a31715b0-7aae-4e98-b297-3496ed17bcbd
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Theoretical Neuroscience For Alignment Theory
This post was written under Evan Hubinger’s direct guidance and mentorship, as a part of the Stanford Existential Risks Institute ML Alignment Theory Scholars (MATS) program.
Many additional thanks to Steve Byrnes and Adam Shimi for their helpful feedback on earlier drafts of this post.
TL;DR: Steve Byrnes has done really exciting work at the intersection of neuroscience and alignment theory. He argues that because we’re probably going to end up at some point with an AGI whose subparts at least superficially resemble those of the brain (a value function, a world model, etc.), it’s really important for alignment to proactively understand how the many ML-like algorithms in the brain actually do their thing. I build off of Steve’s framework in the second half of this post: first, I discuss why it would be worthwhile to understand the computations that underlie theory of mind + affective empathy. Second, I introduce the problem of self-referential misalignment, which is essentially the worry that initially-aligned ML systems with the capacity to model their own values could assign second-order values to these models that ultimately result in contradictory—and thus misaligned—behavioral policies. (A simple example of this general phenomenon in humans: Jack hates reading fiction, but Jack wants to be the kind of guy who likes reading fiction, so he forces himself to read fiction.)
Introduction
In this post, my goal is to distill and expand upon some of Steve Byrnes’s thinking on AGI safety. For those unfamiliar with his work, Steve thinks about alignment largely through the lens of his own brand of “big-picture” theoretical neuroscience. Many of his formulations in this space are thus original and ever-evolving, which is all the more reason to attempt to consolidate his core ideas in one space. I’ll begin by summarizing Steve’s general perspectives on AGI safety and threat models. I’ll then turn to Steve’s various models of the brain and its neuromodulatory sys
|
c189ba31-d7f0-4c9e-85ba-1178c26de089
|
trentmkelly/LessWrong-43k
|
LessWrong
|
AI #59: Model Updates
Claude uses tools now. Gemini 1.5 is available to everyone and Google promises more integrations. GPT-4-Turbo gets substantial upgrades. Oh and new model from Mistral, TimeGPT for time series, and also new promising song generator. No, none of that adds up to GPT-5, but everyone try to be a little patient, shall we?
TABLE OF CONTENTS
In addition to what is covered here, there was a piece of model legislation introduced by the Center for AI Policy. I took up the RTFB (Read the Bill) challenge, and offer extensive thoughts for those who want to dive deep.
1. Introduction.
2. Table of Contents.
3. Language Models Offer Mundane Utility. Help me, doctor.
4. Language Models Don’t Offer Mundane Utility. You keep using that word.
5. Clauding Along. Claude use tool.
6. Persuasive Research. Claude now about as persuasive as humans.
7. The Gemini System Prompt. The fun police rulebook is now available.
8. Fun With Image Generation. This week it is music generation. Are we so back?
9. Deepfaketown and Botpocalypse Soon. Do you influence the AI influencers?
10. Copyright Confrontation. The New York Times talks its book.
11. Collusion. The pattern matching machines will, upon request, match patterns.
12. Out of the Box Thinking. Escape from the internet is not exactly hard mode.
13. The Art of the Jailbreak. GPT-4-Turbo falls, according to Pliny. Ho-hum.
14. They Took Our Jobs. Or rather our applications?
15. Get Involved. Asking for a friend.
16. Introducing. Command-R+, Code Gemma, TimeGPT and a Double Crux bot.
17. In Other AI News. We wrote the checks.
18. GPT-4 Real This Time. New version is new, but is it improved?
19. GPT-5 Alive? What are they waiting for? Presumably proper safety testing.
20. Quiet Speculations. Get your interactive plans away from my movies.
21. Antisocial Media. Follow-up to the CWT with Jonathan Haidt.
22. The Quest for Sane Regulations. New excellent Science article, and more.
23. Rhetorical Innovation. Variations o
|
57607207-4989-4312-ab6c-f7c8da496052
|
LDJnr/LessWrong-Amplify-Instruct
|
LessWrong
|
"Epistemic Status: EndorsedContent Warning: Neuropsychological Infohazard, Evocation Infohazard, World War IRecommended Prior Reading: Blueprint for Armageddon Part IPart of the Series: Truth“History doesn’t repeat itself but it often rhymes”In any real look into the past, you realize pretty quickly that things don’t have neat beginnings or simple origins in the vast majority of cases. Historical events are the result of billiard ball interactions among a chaotic conflux of actors and forces, themselves all built out of past impacts and collisions stretching back into the mists of antiquity.Thus when trying to tell the origin story of the modern rationality community, it can be very tempting to just keep extrapolating backwards. How far back should we look? Do we need to rehash Plato’s Cave and Cogito Ergo Sum? Francis Bacon is credited as the grandfather of science, so maybe we should start with him? For the moment at least I’m writing blog posts not thousand page textbooks, and my goal here isn’t to rehash the entire history of scientific and philosophical thought (I’d like to keep this blog post under three thousand words). If you want the entire history of scientific thought, Cosmos is a great place to start and has some pretty spiffy graphics. But unlike history, every story and every blog post have to start somewhere, and I think the best place to start for our purposes is with polish banker and railway financier Jan Gotlib Bloch. Bloch was born a Polish Jew in Tsarist Russia in the 1800s, and would later convert to Calvinism to protect himself from antisemitism within the Tsarist government. Bloch worked as a banker and would go on to finance the building of rail lines in Russia, as well as penning a lengthy treatise on the management and operation of said rail lines in 1875, for which he: was awarded a medal of the first class at the geographical exhibition of Paris, and was heartily endorsed by the Imperial Russian Geographical Society.But it was Bloch’s later work that would be remembered for. In 1870, The Northern German Confederation would go to war with the Second French Empire. Fueled by fears of the growing power of a rapidly unifying and industrializing Germany, France declared war and invaded in August of 1870. The war was only six months long. By September, Napoleon III was captured and the French Imperial Army had been decisively defeated. A new French government was declared and kept fighting, but by January of 1871 Paris was besieged and the war was brought to an end. The balance of power in Europe had fundamentally shifted, and while all the great powers reeled from the event, some saw it merely as a portent for things to come. The Franco-Prussian war was the first prototype of a modern war, one featuring the use of railroads, artillery, and all the new technology of creation and destruction that had come into existence since the end of the Napoleonic Wars in 1815. Jan Bloch was fascinated by the war of 1870 and would go on to devote much of his personal time to studying the phenomenon that was modern military conflict. No one really knew how any of this stuff would interact with real combat, but everything seemed to point to the idea that the next major war would be unlike anything the world had seen before. Bloch looked at the state of the technology, where things seemed to be going, and penned his most famous six-volume work, originally in Russian and translated into numerous languages, popularized in English under the title Is War Now Impossible? This work would prove to be exactly as horrifying in its prescience as it was in its theories as to the nature of future conflicts. In Europe during the renaissance and age of royalty and exploration, war was almost something of a gentleman’s sport. The royals of all the major nations knew each other, everyone was someone’s cousin or uncle or grandmother, the armies would fight out in lines and day battles and then after one side defeated the other the leaders would sit down for tea and enter negotiations and this was for a long time considered a normal and acceptable way to conduct diplomacy between powers. The civilians of these nations would likely not even notice that they were at war a lot of the time.However, with the french revolution, we see the beginnings of a change in this behavior. The french revolution is the first war to feature mass mobilization, a trend of throwing the entire nation into a conflict instead of merely a small mercenary army. When the European royal powers united against the upstart French republic, they were met not by a small, professional French army but by as much of the french people as could be mobilized. This enormously changed the way wars were fought and forced the rest of Europe to follow suit or be swamped by the sheer size of the French military. Napoleon is famously quoted as saying:“You cannot stop me; I spend 30,000 lives a month.”And this was a major change for the European powers who didn’t really want to arm their peasants, that’s how you end up with uprisings. But here were the french conquering Europe with a peasant army and the rest of the great powers were forced into a game of catch up. This is a rather textbook example of a multipolar trap at work. No one can coordinate to stop the escalation of the conflict, and anyone who doesn’t escalate will be defeated by those who do, thus wars become total and we witness the pivot to the start of the modern arms race. Moloch! Whose Fingers are ten armies!Bloch looked at the state of technology, the state of war, and the state of European powers, and concluded that the era of quick and relatively bloodless conflicts as a method of diplomacy was over. War wasn’t a fun pastime of royalty anymore, war was now serious. Wars of the future would be total. They would not be quick and decisive affairs but brutal slugging matches fought until one nation collapsed socially and economically. He saw that the development of rifling, artillery, and machine guns had made cavalry and bayonet charges suicidal and obsolete. He claimed that a future war would be one of entrenchment, stalemates, massive firepower, and massive losses of life. Bloch’s book is considered to be partly responsible for the Hague Conference of 1899, which sought to impose limits on warfare and prevent the increasingly bloody looking conflict from playing out as Jan Bloch feared it would. Bloch was even a special guest of Tsar Nicholas at the conference. There was a belief, or maybe it was a hope, that because war had become so terrible and destructive, that the only choice nations would have would be to resort to peaceful negotiations. Bloch himself seemed to be something of a proponent to this theory, although he at least seemed to think that peace would still require conscious input and the wisdom of men. He didn’t believe that war was truly impossible, just that continuing to treat war as it had been treated in the past (sportingly) was an impossibility. It was a lesson that would, unfortunately, be mostly ignored by the leaders and military of the time. A decade after the publishing of Is War Now Impossible, British journalist Normal Angell published another work along similar lines, titled The Great Illusion. Angell was an early globalist, who looked at the same situation Bloch had and answered Bloch’s question with “Yeah, war is impossible now.” Angell’s thesis was that any gains made by war would be so dwarfed by the costs of waging a modern war that there would be no reason to ever fight one. A modern war would destroy the world’s economy, and maybe even end civilization itself, and peace was just so profitable. So war was just not going to happen. You would have to be stupid to fight Bloch’s Impossible War, no one would benefit, so no one would do it. Well, as history would come to show, while Angell was correct that a modern war would destroy whole nations and leave economies in ruins, he was wrong about that actually stopping the war from happening. Moloch the vast stone of war! Moloch the stunned governments!So in grade school, we’re taught that World War I happened because all the European powers had entered these complex networks of alliances that drew each other into the growing conflict like dominos falling and no one saw it coming or could stop it. Jan Bloch saw it coming, and he tried to stop it. It was a really solid attempt even, but we don’t live in the timeline where he succeeded, we live in the timeline where he didn’t. As the first decade of the twentieth century drew to a close, tensions continued to ramp up across Europe and Jan Bloch’s warning started looking more and more like a dire inevitability.One of the readers of Jan Bloch’s book was Polish scholar Alfred Korzybski, who asked the very reasonable question: If this was all so inevitable, if everyone knew it was going to happen, then why couldn’t it be stopped? Part of the Series: TruthNext Post: Time Binders"
The above is a chunk of text from a post created by a user on the website LessWrong.
In the context of Jan Bloch's predictions about the nature of future wars, could you elaborate on the specific technological advancements and their impact on the strategies and outcomes of modern warfare?
Certainly, the advancements in technology during the late 19th and early 20th centuries had a profound impact on the nature of warfare. These advancements influenced the strategies employed and ultimately the outcomes of conflicts.
1. **Firearms and Artillery**: The development of more efficient and lethal firearms and artillery changed the face of warfare. The invention of the machine gun, for instance, meant that a small number of soldiers could hold off a much larger force. This made frontal assaults, a common tactic in previous wars, virtually suicidal. Similarly, advancements in artillery meant that positions could be bombarded from a great distance, leading to the development of trench warfare as a means of protection.
2. **Railways**: The advent of the railway system allowed for the rapid mobilization and deployment of troops. This meant that armies could be larger and could be moved quickly to where they were needed. It also allowed for the efficient transportation of supplies, which was critical in maintaining a prolonged war effort.
3. **Chemical Warfare**: The use of chemical weapons, such as chlorine and mustard gas, was a new and terrifying aspect of warfare. These weapons could cause massive casualties and spread fear among the enemy troops. The use of these weapons led to the development of gas masks and other protective measures.
4. **Airplanes and Tanks**: While these technologies were in their infancy during World War I, they represented a new dimension in warfare. Airplanes allowed for reconnaissance and bombing missions, while tanks provided a means of breaking through enemy lines.
5. **Communication Technology**: The development of the telegraph and later the radio allowed for rapid communication over long distances. This allowed for better coordination and planning of military operations.
6. **Naval Technology**: Advancements in naval technology, such as the development of the dreadnought battleship and the submarine, changed naval warfare. These technologies made naval blockades more effective and posed new threats to traditional naval powers.
These technological advancements meant that wars could be fought on a much larger scale and over a longer period of time. They also led to a massive increase in the number of casualties. The nature of these technologies and the strategies they necessitated meant that wars became total wars, involving the entire population and economy of the nations involved. This was a significant shift from previous conflicts, which were often limited to professional armies.
Elaborate on the psychological impact of chemical warfare on soldiers during World War I.
Chemical warfare during World War I had a profound psychological impact on soldiers. The use of chemical weapons, such as chlorine and mustard gas, introduced a new and terrifying form of warfare that caused not only physical harm but also deep psychological trauma.
1. **Fear and Anxiety**: The fear of a gas attack was pervasive among soldiers. The unpredictability and invisibility of gas attacks created a constant state of anxiety. Soldiers never knew when an attack might occur, and this uncertainty could be mentally exhausting.
2. **Physical Trauma and Mental Health**: The physical effects of chemical weapons were horrific and often led to psychological trauma. Soldiers who were exposed to gas attacks suffered from painful and debilitating injuries, such as blistered skin, damaged lungs, and blindness. The sight of these injuries and the experience of being attacked could lead to post-traumatic stress disorder (PTSD), a condition characterized by flashbacks, nightmares, and severe anxiety.
3. **Moral Injury**: The use of chemical weapons was seen by many as a violation of the rules of war, and this could lead to moral injury. Moral injury is the distress that results from actions, or the witnessing of actions, that violate one's moral or ethical code. Soldiers who participated in or witnessed gas attacks could experience feelings of guilt, shame, and a loss of trust in authority.
4. **Sense of Helplessness**: Chemical warfare often created a sense of helplessness among soldiers. Traditional combat skills and bravery were of little use against a gas attack. This sense of being unable to control or influence events could lead to feelings of despair and hopelessness.
5. **Long-term Psychological Effects**: The psychological effects of chemical warfare could persist long after the war had ended. Veterans might suffer from long-term mental health issues, such as depression, anxiety disorders, and PTSD. The experience of chemical warfare could also affect their ability to reintegrate into civilian life and form healthy relationships.
In conclusion, the psychological impact of chemical warfare during World War I was profound and far-reaching. It introduced a new level of horror to warfare and left many soldiers with lasting mental health issues.
|
12aee791-8e52-4009-9eb3-9a24e6090fc7
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Weekly LW Meetups: Berkeley, Dallas, Pittsburgh, Vancouver, Washington DC
There are upcoming irregularly scheduled Less Wrong meetups in:
* Vancouver Politics Meetup: 12 May 2012 01:00PM
* Washington DC meetup: 12 May 2012 08:34PM
* Dallas - Fort Worth Less Wrong Meetup 5/13/12: 13 May 2012 01:00PM
* Pittsburgh: Harry Potter and the Methods of Rationality: 18 May 2012 06:00PM
* Brussels meetup: 19 May 2012 12:00PM
* Less Wrong Sydney - Rational Acting: 21 May 2012 06:00PM
* First Berlin meetup: 05 June 2012 07:30PM
* Phoenix, Arizona: 15 June 2012 07:00PM
The following meetups take place in cities with regularly scheduled meetups, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Big Berkeley Meetup: 16 May 2012 07:00PM
* Cambridge, MA Third Sunday Meetup: 20 May 2012 02:20PM
Locations with regularly scheduled meetups: Austin, Berkeley, Cambridge, MA, Cambridge UK, Chicago, London, Madison WI, Melbourne, Mountain View, New York, Ohio, Ottawa, Oxford, Portland, Salt Lake City, Seattle, Toronto, Waterloo, and West Los Angeles.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview will continue to be posted on the front page every Friday. These will be an attempt to collect information on all the meetups happening in the next weeks. The best way to get your meetup featured is still to use the Add New Meetup feature, but you'll now also have the benefit of having your meetup mentioned in a weekly overview. These overview posts will be moved to the discussion section when the new post goes up.
Please note that for your meetup to appear in the weekly meetups feature, you need to post your meetup before the Friday before your meetup!
If you check Less Wrong irregularly, consider subscribing to one or more city-specific mailing l
|
5aa73b54-ae54-42b5-abe7-c6ea681722d2
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Into the Kiln: Insights from Tao's 'Analysis I'
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Note: real analysis is not on the MIRI reading list (although I think it should be).
Foreword
As a young boy, mathematics captivated me.
In elementary school, I'd happily while away entire weekends working through the next grade's math book. I was impatient.
In middle school, I'd lazily estimate angles of incidence that would result if I shot lasers from my eyes, tracing their trajectories within the classroom and out down the hallway. I was restless.
In high school, I'd daydream about what would happen to integrals as I twisted functions in my mind. I was curious.
And now, I get to see how it's all put together. Imagine being fascinated by some thing, continually glimpsing beautiful new facets and sampling exotic flavors, yet being resigned to not truly pursuing this passion. After all, I chose to earn a computer science degree.
Wait.
Analysis I
As in Linear Algebra Done Right, I completed every single exercise in the book - this time, without looking up any solutions (although I did occasionally ask questions on Discord). Instead, I came back to problems if I couldn't solve them after half an hour of effort.
A sampling of my proofs can be found here.
1: Introduction
2: The Natural Numbers
In which the Peano axioms are introduced, allowing us to define addition and multiplication on the natural numbers {0,1,2,…}.
3: Set Theory
In which functions and Cartesian products are defined, among other concepts.
Recursive Nesting
How can you apply the axiom of foundation if sets are nested in each other? That is, how can the axiom of foundation "reach into" sets like A={B,…} and B={A,…}?
Show that if A and B are two sets, then either A∉B or B∉A (or both).
Proof. Suppose A∈B and B∈A. By the pairwise axiom, we know that there exists a set S={A,B}. We see that there does not exist an S′∈S such that S′∩S=∅. That is, if we choose A, one of its elements is B, which is also an element of S - this violates the axiom o
|
e74bb71a-779c-4e7b-a7eb-85c18e0826cf
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[LINK] Discovery shuttle launch viewed from an airliner
Behold the power of applied rationality!
...ok, this is really just geek mind candy.
|
22591a7f-d084-4989-9d60-16be2a87688f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Empiricism in NLP : Test Operate Text Exit (TOTE)
Epistemic status: Presentation of an established technique and history. I learned most of my NLP knowledge from Chris Mulzer who’s one of Bandler’s top students. The Origins of Neuro-Linguistic Programming by John Grinder and Frank Pucelik is my main source for the history.
What's NLP? In 1971 Frank Pucelik and Richard Bandler started teaching Fritz Perls’s Gestalt therapy in a group at the University of California, Santa Cruz where the two were in a Bachelor program of psychology. They were joined by John Grinder who was an assistant professor in Linguistics who had just finished writing his PHD thesis on the topic of deletions. As a linguist he had projects like modeling the language of the Tanzanian Wagogo tribe to be able to communicate with them. He had the idea that if he would create a model of how Fritz Perls was using language to get the results he got in his Gestalt therapy work, he should be able to achieve the same results.
Just like modeling the customs of the Wagogo tribe, the goal was to copy the linguistic patterns that were present in Perls’s work to be able to achieve the same results. As a side job Bandler was transcribing lectures of the late Fritz Perls, so they had plenty of video material to study. In addition to the videos Grinder could also study Bandler and Pucelik as they were doing their Gestalt work.
Modeling in NLP
Later they described the modeling process that they followed as a five-step process description of NLP Modeling:
1. Identification of and obtaining access to a model in the context where he or she is performing as a genius.
2. Unconscious uptake of model’s patterns without any attempt to understand them consciously.
3. Practice in a parallel context to replicate the pattern. The intention is to achieve a performance of the model’s patterns which is equal to the model him/herself.
4. Once the modeler can consistently reproduce the pattern in an applied fashion with equal results, the modeler begins the coding process.
|
db77216a-0e38-4325-afde-9145aa20ee9b
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How can I protect my bank account from large, surprise withdrawals?
Today's Money Stuff describes large charges for electricity auto-withdrawn from customer's accounts:
> Last week there was a brief surprising spike in the spot price of electricity in Texas... Prices went from something like $20 per megawatt-hour in early February to something like $9,000 last week...
>
> [A customer of an electric company] and her husband, Doug Robinson, 42, used less energy in February than they did the prior month. Still, their bill, typically around $100 a month, was more than $6,500 in 17 days. Because Griddy is connected to customers’ credit or debit cards to make automatic withdrawals, her credit card bill is now more than $2,500 — which she cannot afford to pay. She canceled her card before she could face more charges.
I called my bank (US Bank) to see if they could put in a rule to protect my account for this kind of thing, for example, allow no auto-withdrawals over $1,000 dollars. The guy on the phone said no - they could set up after-the-fact alerts about large withdrawals, but nothing for before the horse is out of the barn.
My question: what are some ways to defend myself against this kind of large surprise withdrawal? I like the convenience of auto-paying, and would like to keep as much of that convenience as possible, but it looks like I will have to sacrifice some of it. I would have never guessed, if I lived in Texas, that I might be at the kind of financial risk described above, so I am looking for a method that doesn't require me to know a lot about what specific thing might be about to incur a large charge.
|
a54c38f4-5aca-44aa-b52c-cea3638af8a9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Thinking in Bayes: Light
There are a lot of explanations of Bayes' Theorem, so I won't get into the technicalities. I will get into why it should change how you think. This post is pretty introductory, so free to totally skip it if you don't feel like there's anything about Bayes' Theorem that you don't understand.
For a while I was reading LessWrong and not seeing what the big deal about Bayes' Theorem was. Sure, probability is in the mind and all, but I didn't see why it was so important to insist on bayesian methods. For me they were a tool, rather than a way of thinking. This summary also helped someone in the DC group.
After using the Anki deck, a thought occurred to me:
> Bayes theorem means that when seeing how likely a hypothesis is after an event, not only do I need to think about how likely the hypothesis said the event is, I need to consider everything else that could have possibly made that event more likely.
To illustrate:
pretty clearly shows how you need to consider P(e|H), but that's slightly more obvious than the rest of it.
If you write it out the way that you would compute it you get...
where h is an element of the hypothesis space.
This means that every way that e could have happened is important, on top of (or should I say under?) just how much probability the hypothesis assigned to e.
This is because P(e) comes from every hypothesis that contributes to e happening, or more mathilyeX P(e) is the sum over all possible hypotheses of the probability of the event and that hypothesis, computed by the probability of the hypothesis times the probability of the event given the hypothesis.
In LaTeX:
where h is an element of the hypothesis space.
|
5c4dd89a-1fcc-4e5d-bf92-c43a5ffcf6f7
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Higher Dimension Cartesian Objects and Aligning ‘Tiling Simulators’
*Thanks to Justis Mills for feedback. Mistakes are mine.*
**Introduction**
================
This document will attempt to build upon the [Cartesian frame](https://www.lesswrong.com/s/2A7rrZ4ySx6R8mfoT) paradigm by modeling multi-agent worlds as higher dimension C*artesian objects*. Cartesian objects partially betray many of the properties of their frame counterpart, and they aren't really just 'extensions' of frames, but they are quite similar in some respects and can be reasoned about in similar ways. I will discuss their properties, use them to model recursive self improvement (RSI)/tiling, and show how I think they can be used to construct formal frameworks for solving some outer alignment problems in [simulators](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators). The math will be quite difficult to understand if you haven't read [*Introduction to Cartesian Frames*](https://www.lesswrong.com/posts/BSpdshJWGAW6TuNzZ/introduction-to-cartesian-frames)and sections 1 and 2 of [*Tiling Agents for Self-Modifying AI, and the Löbian Obstacle*](https://intelligence.org/files/TilingAgentsDraft.pdf)*.* It is also incredibly messy and will be refined in later writings.
To introduce the concept, I will present an example in the context of a two-agent game:
Two agents (A1.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
and A2) and an environment (E), all with three actions, resulting in 27 possible worlds (W).For a clearer representation of world separation, see:
Where each box could be sequentially labeled w1,w2…w27.In theory a Cartesian object could have any number n∈N of dimensions, and the above is just one potential configuration used as a toy model to introduce the concept. Most models will involve far more than three actions per axis and many more than two agents.
---
**Properties of Cartesian Objects**
===================================
*These are all adaptations of Garrabrant's original definitions of the properties of cartesian frames to work with higher dimension cartesian objects.*
The set of all actions that could be pursued by any agent described by such an object is hereafter:
A∗(C)={a11,a12,...,a1m,a21,a22,...,a2m,...,an1,an2,...,anm}[[1]](#fnmhg3yv04ho)
And by a specific agent:
An(C)={an1,an2,...,anm}[[1]](#fnmhg3yv04ho)
**Controllability**
-------------------
The set of ensurables, preventables and controllables for the nth agent in the Cartesian object C could thus be formalized as:
Ensuren(C)=S⊆W|∃ani∈An(C),∀e∈E,ani⋅e∈S Preventn(C)=S⊆W|∃ani∈An(C),∀e∈E,ani⋅e∉S Ctrln(C)=Ensuren(C)∩Preventn(C)
**Manageability**
-----------------
We consider manageability, which extends controllability to account for uncertainty in the behaviors of other agents, which we formalize as the belief threshold θ (which could change dependent on the agent's risk tolerance and the like):
P1(anm,e)=Pr(∏n∈Nanm⋅e∈S)P2(anm,e)=Pr(∏n∈Nanm⋅e∉S)Manageablen(C)={S⊆W|∃anm∈An(C),∀e∈E,P1(anm,e)≥θ∨P2(anm,e)≥θ}[[2]](#fnrjk28uzmiok)
**Observability**
-----------------
Observability remains practically unchanged, so I will quote the original post but note that this will apply again to the nth agent:
> Observables can be thought of as a closure property on the agent. If an agent is able to observe S, then the agent can take policies that have different effects depending on S.
>
>
Obsn(C)={S⊆W|∀ani,anj∈An(C),∃ank∈An(C),ank∈if(S,ani,anj)}
**Inevitability**
-----------------
Garrabrant defines the property of inevitability as the intersection of a frame's ensurables and observables if and only if a frame's image is a subset of S and Agent(C) is nonempty. The definition remains largely unchanged for higher dimension objects excluding agent specificity:
Imagen(C)={w∈W|∃ani∈An(C),∃e∈E:ani⋅e=w}S∈Inevitablen(C)⟺Imagen(C)⊆S∧An(C)≠∅[[3]](#fnnv1x4bhtn1o)
**Viability**
-------------
Viability can be thought of the manageable alternative to inevitability. If conditional on some manageable property occurring it can be observed, it is considered viable:
VImagen(C)={w∣Pr(w∈W∣∃ani∈An(C),∃e∈E:ani⋅e=w)>θ}S∈Viablen(C)⟺VImagen(C)⊆S∧An(C)≠∅
---
**Tiling Agents**
=================
Assuming an agent attempting RSI or tiling would want to know that its subsequent agent(s) would pursue aligned goals and be sure it can produce said agent; it may be interested in the property of inevitability.
*Tiling Agents for Self-Modifying AI, and the Löbian Obstacle* defines the following property of ideal tiling agents:
¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G)A2⊢¯¯¯¯A1→∀A1j∈Acts1:¯¯¯¯A1j→□1⌈¯¯¯¯A1j→(∅∨G)⌉A2⊢¯¯¯¯A1→(∀A1j∈Acts1:¬¯¯¯¯A1j)→∅∀ϕ:A2⊢∀x:(□1⌈ϕ(x)⌉→ϕ(x))A2⊢¯¯¯¯A1→∀A1j∈Acts1:¯¯¯¯A1j→(∅∨G)A2⊢¯¯¯¯A1→(∅∨G)[[4]](#fnkh00nbg4hw)[[5]](#fnnbhididq35p)
*Note that here the regular turnstile is used in place of the special turnstile denoting cognitive conclusion of a belief (as I couldn't format it properly). This exception applies **only here.***
In place of certain belief in some outcome, we can instead make ¯¯¯¯A1k conditional on the inevitability of what A2 proves (e.g. ¯¯¯¯A1k→(∅∨G)) . Using this example, we could say:
(¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G))∈Inevitablen(C)⟺Imagen(C)⊆(¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G))∧An(C)≠∅
*Here the regular turnstile is used intentionally as it will be for the remainder of the document.*
An agent might instead be interested in pursuing viability over inevitability for one or more of the following reasons:
1. Inevitability is impossible
2. Pursuing high-certainty viability yields greater utility (e.g. it could be better to pursue an outcome now that is 99% likely to occur compared to waiting for a year for it to be certain)
3. It is more conforming to some compelling normative standard (may overlap with (2))
In terms of viability:
(¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G))∈Viablen(C)⟺VImagen(C)⊆(¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G))∧An(C)≠∅[[6]](#fnamz2xple5hu)
Whilst this is just generalizing from the belief turnstile for a standard turnstile, I will try to convey the utility of this form in creating aligned simulators.
---
**Tiling Simulators**
=====================
To make Cartesian objects useful for thinking about simulators, do the following:
1. *Imagine a box.* This box has a volume that corresponds to the highest possible complexity simulation a given simulator can conduct.
2. *Imagine a Cartesian object in that box.* This object consumes an amount of the box's volume proportional to its own complexity and likely consists of an environment and various agents.
By default this box does not care what is in it. The box was content with this until someone started telling the box that some of the things in it were good, and some of the things in it were bad (conditioning). If this box was a deceitful box, it would just hide the bad objects under good ones such that it looked like a good box (deceptive alignment). If it was a good box (robustly aligned), it would contain only good objects. If the box wants to have a lot of objects in it, it can't rely on the limited approval rate of the person who initially instructed it, and so it needs a more scalable criterion.[[7]](#fn803okig27d)[[8]](#fn1ze36owygnu)
When modeling a conditioned simulator as a tiling agent, you also gain access to various luxuries such as the fact that by definition the seed agent can simulate the agents it creates in the future. We do not need to worry about issues from the tiling agents paper like:
> If you are constructing a system cognitively smarter than yourself (or self-improving to a cognitively superior version) then you should not be able to foresee at compile time exactly which solutions will be generated, since you are not presently that smart.
>
>
On the other hand, it's not as though you can just have a simulator simulate a world with a general intelligence in it to see if it is aligned or not, as this process is identical to having it be simulated regularly, and thus entails the same risks.
One issue with advanced simulators is that creating nested simulations greatly increases the probability that one of the simulated agents is capable of influencing the real world negatively and is motivated to do so. There is a limit to this risk as it is unlikely that very low complexity simulations are able to contain a program as advanced as general intelligence, but this limit becomes increasingly insignificant as the power of simulators grow.[[9]](#fnif2ar8h5zki)
Critically, thwarting the Löbian obstacle is not necessary as the created agents will be weaker than their predecessors, which ameliorates one of the key difficulties of tiling agents.
Ideally, a successfully conditioned simulator would be able to assess potential simulacrum against a safety criterion, and either conclude that negative real-world influence was either preventable or nonviable with high certainty. If this criterion could be simply expressed in first-order logic, it may be able to be hard-coded. Here is a control flow diagram detailing how that might work:
To clarify, a successfully formalized safety criterion would not constitute a complete alignment solution for simulator models. What it would ensure is that simulated simulators and simulated agents adhere to some principle that if followed restricts influence outside their residing Cartesian object to be either controllably or manageably non-negative as defined by their conditioning.
1. **[^](#fnrefmhg3yv04ho)**Where anm refers to the number of possible actions m the nth agent could pursue.
2. **[^](#fnrefrjk28uzmiok)**Where N is the set of agents the manageability is conditional on (e.g. N={1,4,38,92})
3. **[^](#fnrefnv1x4bhtn1o)**It might be unclear, but Imagen(C) here refers to the subset of W reachable by the nth agent.
4. **[^](#fnrefkh00nbg4hw)**An agent marked with an overline (e.g. ¯¯¯¯A1k) denotes that said agent was constructed.
5. **[^](#fnrefnbhididq35p)**φ Denotes some belief.
6. **[^](#fnrefamz2xple5hu)**¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G) just represents worlds where ¯¯¯¯A1k⇒A2⊢¯¯¯¯A1k→(∅∨G) is true.
7. **[^](#fnref803okig27d)**The box analogy breaks down when your cartesian objects are not three dimensional, but likely so does any description of a >3 dimensional object, and I find it useful for explaining the concept regardless.
8. **[^](#fnref1ze36owygnu)**In regular terms: A pure simulator has no reason to abide by any tiling desiderata, but a conditioned simulator might. Thinking of conditioned simulators as creating new agents the same way a standard tiling agent would is useful, as the latter is much more intuitive and has more theoretical groundwork.
9. **[^](#fnrefif2ar8h5zki)**Knowing this limit would require knowing the lowest possible complexity program capable of negatively influencing the real world from within a simulation (which is probably at least general intelligence). I use it more as an illustrative example than as something actually worth computing.
|
45f6a21f-90d6-4d6e-be2a-ef216cb03952
|
trentmkelly/LessWrong-43k
|
LessWrong
|
AI Safety Hub Serbia Official Opening
TLDR: We're thrilled to announce that we are now welcoming full-time tenants to our newly transformed office space for AI Safety researchers in search of an inspiring workspace. You can take a glimpse at the photos below to get a sneak peek. We're extending a warm invitation, with priority, to citizens of nations such as Russia and China, who can enjoy visa-free work privileges in Serbia while maintaining proximity to Europe. Our monthly office rent is an astonishingly affordable 150€, about half the standard cost in Belgrade. For those needing financial support, we have subsidies available. Register interest here or seek answers to any questions that stir your curiosity - our inbox is open, and we eagerly await your inquiries. Looking ahead, we aspire to provide housing for these researchers. If you're a potential donor who shares our vision, please contact us. Together, we can enhance the impact of AI Safety research. Your support could be the catalyst for a remarkable journey.
You may want to come if:
* You are an AI Safety Researcher/EA researcher looking for a base of operations for a short-medium-long term
* You are keen to be in Europe but not in the EU
* You are looking for a vibrant but affordable city with plenty of things to do and Eastern European but Westernized culture.
Background:
EA Serbia and AI Safety Serbia groups are small but growing (>30 people in EA Serbia, ~3 people looking to get into AIS research as a career, and ~3 to get into AIS policy). Due to Serbia’s favorable Visa policy towards Russia and China, many foreigners already live here. With lower living costs than many other international hub cities, a vibrant scene, and a favourable time zone and climate, Belgrade has a growing foreign community.
As we have seen projects such as CEEALAR as important and impressive, we wish to replicate them in Serbia, where they can better serve people who may struggle to get UK visas. We also believe that having the capacity to quickly scale che
|
8302cb45-18b3-4b2d-a5f4-2cae0f3b48fa
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
EA for dumb people?
I've been involved in EA for nearly a year now. At first, it was super exciting. I resonated so much with the core ideas of EA, and I couldn't wait to get started with doing the most good I possibly could. I had no idea there was so much opportunity.
As I got further into it, my hopes started to fade, and I started to feel like I didn't really fit in. EA is pitched to the super intelligent in our society, those who did super hard degrees at Oxford or Harvard and learned to code at age 8. For me, I'm just average. I never stood out at school, I went to mid-ranking university and studied sociology (which has a reputation for being an easy degree). I graduated, got an average job and am living an average life. I don't have some high earning side hustle and I don't spend my spare time researching how we can make sure AI is aligned with human values.
I do however, care a lot about doing the most good. So I really want to fit in here because that matters a lot to me. I want to leave the world a better place. But I feel like I don't fit, because frankly, I'm not smart enough. (I'm not trying to be self deprecating here, I feel like I'm probably pretty average among the general population - and I didn't really ever feel 'not smart enough' before getting involved in EA)
I totally understand why EA aims at the Oxford and Harvard graduates, of course, we want the most intelligent people working on the world's most pressing problems.
But most people aren't Oxford or Harvard graduates. Most people aren't even university graduates. So do we have a place in EA?
I want to be a part of this community, so I'm trying to make it work. But this leads me to be worried about a lot of other people like me who feel the same. They come across EA, get excited, only to find out that there's not really a place for them - and then they lose interest in the community. Even the idea of giving 10% of your salary can be hard to achieve if you're balancing the needs/wants of others in your family (who maybe aren't so EA minded) and considering the rises in the cost of living currently.
I'm guessing here, because I have absolutely no stats to back this up and it's based on mostly my anecdotal experience - but we could potentially be losing a lot of people who want to be a part of this but struggle to be because EA is so narrowly targeted.
Whenever I come on the EA forum I literally feel like my brain is going to explode with some of the stuff that is posted on here, I just don't understand it. And I'm not saying that this stuff shouldn't be posted because not everyone can comprehend it. These are really important topics and of course we need smart people talking about it. But maybe we need to be aware that it can also be quite alienating to the average person who just wants to do good.
I don't have a solution to all this, but it's been on my mind for a while now. I re-watched this [Intro to EA by Ajeya Cotra](https://www.youtube.com/watch?v=48VAQtGmfWY) this morning, and it really re-invigorated my excitement about EA, so I thought I'd put this out there.
I'd be really keen to hear if anyone has any thoughts/feelings/ideas on this - I'm honestly not sure if I'm the only one who feels like this.
|
0275371a-c2e1-43fa-b880-99072c595f9d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Americans are fat and sick—and it’s their fault…right?
People eat more calories than they expend. They gain weight. If nobody is forcing them to eat to excess, then they only have themselves to blame, right?
I harbored this belief for a long time until I read the book The Obesity Epidemic by Dr. Robyn Toomath.[1] The premise is that too much emphasis on personal responsibility is (1) negating the changing macroeconomic factors that ballooned the population’s weight, and (2) the government’s responsibility (and failure) to regulate the food industry. She makes the case that the food industry acts to addict us in the same way Big Tobacco did in the 20th century. And one of the clearest ways the food industry does this is in how we shop for groceries.
Supermarkets—drug stores that happen to sell vegetables
Dr. Toomath explains that the development of the global industrial diet is, to a large degree, the fault of supermarkets.
> The free market is supposed to empower the consumer, but we hand this power over to multinational companies who in turn create demand (having figured out what sells). Yes, we get to choose this brand of chips over another, but larger forces determine the cheapness of chips and influence our preferences for these over rice or vegetables.
Price is just one way in which our behavior is manipulated. We’re also influenced by the location of certain products on the supermarket shelves.[2] People are bored in checkout lines. Stores know this. It’s not a coincidence that impulse-buy candy is located there.[3]
Supermarkets are implementing the concept authors Richard Thaler & Cass Sunstein describe in their book Nudge.
> Nudge: Any choice [made by a decision maker] that alters people’s behavior in a predictable way without forbidding any options.
Where personal responsibility meets subtle manipulation
Back in 2019, my friends and I were in a theater waiting for our movie to begin when an M&Ms ad played. I remember thinking, “what’s the point of ads like this? It’s not like I’ll suddenly be persuade
|
7fc9570e-8fd6-400b-a6e6-d4fb8eaaa57d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Designing Artificial Wisdom: GitWise and AlphaWise
Introduction
In this post I will describe two possible designs for Artificial Wisdom (AW.) This post can easily be read as a stand-alone piece, however it is also part of a series on artificial wisdom. In essence:
Artificial Wisdom refers to artificial intelligence systems which substantially increase wisdom in the world. Wisdom may be defined as "thinking/planning which is good at avoiding large-scale errors," or as “having good terminal goals and sub-goals.” By “strapping” wisdom to AI via AW as AI takes off, we may be able to generate enormous quantities of wisdom which could help us navigate Transformative AI and The Most Important Century wisely.
TL;DR
Artificially wise coaches that improve human wisdom seem like another promising path to AW. Such coaches could have negligible costs, be scalable & personalized, and soon perform at a superhuman level. Certain critical humans receiving wise coaching could be decisive in humans navigating transformative AI wisely.
One path to AW coaches is by creating a decentralized system like a wiki or GitHub for wisdom-enhancing use-cases. Users could build up a database of instructions for LLM’s to act as AW coaches to help users make difficult decisions, navigate difficult life and epistemic dilemmas, work through values conflicts, achieve career goals, improve relational/mental/physical/emotional well-being, and increase fulfillment/happiness.
One especially wise use-case could be a premortem/postmortem bot that helps people, organizations, and governments to avoid large-scale errors.
Another path to creating an AW coach is to build a new system trained on biographical data, which analyses and learns to predict which decision-making processes and strategies of humans with various traits in various environments are most effective for achieving certain goals.
Artificial Wisdom Coaches
The are several possible paths for developing AW coaches. After introducing the basic idea, I will briefly outline two of them.
The es
|
b3315b47-07b2-419c-8b2c-706f92d0066a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Towards a comprehensive study of potential psychological causes of the ordinary range of variation of affective gender identity in males
This post is also available at surveyanon.
The title of this post might be quite a mouthful, so let's break it down a bit.
* "Affective gender identity" concerns how you feel about being a man vs being a woman. That is, in males, it's about how satisfied one is with being male, and how much one wants to be female. If for instance you are a trans woman, then your affective gender identity is almost certainly such that you are distressed about having male body parts and being seen as male, and that you want to live like a woman.
* However, "the ordinary range of variation" means that we aren't looking at trans women, who only make up a very small part of the population, but instead that we are looking at relatively ordinary men. Men have substantial variation in how they feel about being male, as has been discussed by rationalists before under labels such as "cis-by-default". For instance, in surveys of the rationalist community, around 50% of men feel like they wouldn't mind being women, and 50% of men feel like it would be distressing to be women.
* When I say I am doing a "comprehensive study of potential psychological causes" of this, what I mean is that I try to ask a large bunch of men an enormous number of questions about their values, personality, sexuality, experiences, and things like that, to try and untangle if any of these factors might be contributing to their affective gender identity. This is inherently a difficult problem, since surveys are kind of crude, and inferring causality at this level of analysis is not straightforward. I think the results here are worthwhile; but I'll let you be the judge of that.
This study is unfortunately probably not the definitive answer, if nothing else then because the key findings aren't replicated yet. I'll try to point out any limitations that I see, though. The following post describes my general analysis; if you would like to see the data to perform your own analysis, or to see the exact surveys used for the
|
83bbc235-d445-4f68-955e-ca2f7381f50c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The limits of AI safety via debate
The limits of AI safety via debate
I recently participated in the AGI safety fundamentals program and this is my cornerstone project. During our readings of AI safety via debate (blog, paper) we had an interesting discussion on its limits and conditions under which it would fail.
I spent only around 5 hours writing this post and it should thus mostly be seen as food for thought rather than rigorous research.
Lastly, I want to point out that I think AI safety via debate is a promising approach overall. I just think it has some limitations that need to be addressed when putting it into practice. I intend my criticism to be constructive and hope it is helpful for people working on debate right now or in the future.
Update: Rohin Shah pointed out some flaws with my reasoning in the comments (see below). Therefore, I reworked the post to include the criticisms and flag them to make sure readers can distinguish the original from the update.
Update2: I now understand all of Rohin’s criticisms and have updated the text once more. He mostly persuaded me that my original criticisms were wrong or much weaker than I thought. I chose to keep the original claims for transparency. I’d like to thank him for taking the time for this discussion. It drastically improved my understanding of AI safety via debate and I now think it’s even better than I already thought.
The setting
In AI safety via debate, there are two debaters who argue for the truth of different statements to convince a human adjudicator/verifier. In OpenAI’s example, the debaters use snippets of an image to argue that it either contains a dog or a cat. The dog-debater chooses snippets that show why the image contains a dog and the cat-debater responds with snippets that argue for a cat. Both debaters can see what the other debater has argued previously and respond to that, e.g. when the dog-debater shows something that indicates a dog, the cat-debater can refute this claim by arguing that this snipped actual
|
cedd0e06-38ff-4df1-ba8f-2f6b13316215
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Some advice on independent research
I have been doing independent research in addition to my Ph.D. for roughly a year now. For the next 6 months, I’ll take a break from my Ph.D. and plan to do AI safety research full-time. I had chats with many people about independent research in the past, e.g. on EAGs or because 80K has connected me with people thinking about pursuing independent research. I had some great experiences with independent research but not everyone does. I think the variance for independent research is large and I'm worried that people get disheartened by bad experiences. So here are some considerations in which situations independent research might be a good idea and some tips that will hopefully improve your experience.
*I’d like to thank Magdalena Wache and Tilman Räuker for their feedback*.
**TL;DR:**At first glance, there is a bit of a paradoxical nature to independent research. If someone wants to pursue independent research they need a research agenda to work on. If they are able to construct a good research agenda, an existing institution often has incentives to hire them. On the flip side, if their research skills are not developed enough to be hired by an existing institution, their independent research might not be very successful. Thus, naively it would seem that there are few cases in which independent research makes sense. However, I think that there are many situations in which independent research or independent upskilling are a great option, e.g. when no established organization is working on the topic you find most promising, as a way to upskill for a job, to gain new research skills or to transition between jobs. Some tips for independent researchers include: getting feedback early on, aiming to collaborate with others and creating accountability mechanisms for yourself such as publishing your results. My most important advice for independent researchers is that you should probably be much more active than in other roles because there is less default structure and more responsibility on you.
*I’ll mostly talk about AI safety research but many of these things probably also apply to other independent research.*
A perceived paradox
===================
Independent research is often presented as one of three default options for people seeking to do EA research, e.g. in AI safety:
1. Academia, e.g. applying for Ph.D. and post-doc positions with labs that do research aligned with your goals.
2. Research positions in industry, e.g. applying for Anthropic, Redwood Research, Deepmind, OpenAI or Conjecture.
3. Independent research, e.g. supported by an EA grant.
Doing independent research well requires a multitude of skills. The independent researcher needs to be able to set their own agenda, they require some basic research skills, self-discipline and some way of evaluating and correcting their own research. These are skills that usually don’t come naturally but need to be learned and refined. In most standard career paths, e.g. within a Ph.D. or in an industry research team people have mentors who help them and ensure that they actually learn these skills. By default, independent research does not ensure that these skills are actually acquired.
The perceived paradox is now that if someone has the skills required to do high-quality independent research, existing institutions often want to hire them. If they don’t have these skills yet, the research they will produce independently is unlikely to be of high quality or conducted efficiently (unless they have mentorship or are especially talented). Thus, naively, it seems like there aren’t that many situations in which independent research makes sense.
However, I think there are many cases in which independent research makes a lot of sense and there there are a lot of tips that can improve it. As with all things, independent research obviously has its trade-offs.
When does independent research make sense?
==========================================
I think the most important question that someone who thinks about doing independent research should ask themselves is **whether they want to do independent research or upskilling (and how much of each)**. The goal of independent research is to produce a research result, e.g. increasing or refining the pool of existing knowledge. The goal of upskilling, on the other hand, is to increase your skills and knowledge. It doesn’t have the aim of finding anything new. You could also draw the distinction between “independent research with the main goal of producing impactful results” and “independent research with the main goal of becoming good at research (or other skills such as research engineering)”. Research and upskilling obviously correlate a bit but I think it’s really helpful to
1. **Think about what you actually want to do before you start**. Often, when I give advice to people who consider doing independent research, we realize during the discussion that they actually want to focus more on understanding and replicating the existing landscape than producing new research. Even if your goal is to do new research, it might be helpful to get very familiar with the current research before you embark on your own journey.
2. **Re-evaluate your goals from time to time**. Your personal goals can change over time or you might realize that you are not a good fit for the path you are currently pursuing. In this case, it might be the best choice to pivot either to a different topic, approach or goal. There is no need to stick to a project if you are confident that something else is better or you are not a good fit. Often it’s hard to evaluate whether we have “already tried hard enough” and thus stick to the current path. However, this often means that we cut our losses too late. I find the following simple heuristic helpful to make such a decision (which is common in grant-making): “how likely would exploring this avenue further change your final decision?”. Often I know quite early that I don’t think a project is worth it, even if it were successful and thus just drop it. No need to feed the sunk cost fallacy. In a classic environment, your supervisor might urge you to cut your losses, in independent research you have to make that decision yourself, so regularly evaluating your goals and progress helps.
To give a better sense of when independent research makes sense, I think the following situations are plausible candidates:
1. **If they work on a side or transition project:**People who already have some experience with research, e.g. Master's or Ph.D. students, can do independent research related to AI safety if their primary research doesn’t directly involve it. They usually already have some of the research skills required and are thus able to make meaningful progress even though they are not already experts in the field. I think this is the most obvious candidate for short-term (e.g. less than a year) independent research.
2. **If their agenda is not part of an existing research group:**Some researchers have AI safety agendas that are currently not a priority at any of the existing AI safety institutions. If they are able to convince any of the funders that their agenda is worth pursuing, they can become an independent researcher. I think [John Wentworth](https://www.lesswrong.com/users/johnswentworth) is a very good example of someone who I’d put in this category and [Neel Nanda](https://www.neelnanda.io/) is on a similar path. I think people who follow this path should aim to get into a mentorship position sooner or later. If they were able to come up with a sufficiently new agenda and got funding for it, it’s probably worth pursuing for more than one person. For example, John Wentworth supervised many scholars during the last iteration of SERI MATS with great outcomes (e.g. improved research ability and concrete outputs). In the long run, this could lead to a new organization but doesn’t have to.
3. **If they are not interested in a full-time job:**Sometimes people want to do independent research but are not interested in a full-time job. This might be because they want to spend a lot of time with their family and friends or because they have other commitments that don’t allow them to manage a full-time position. In this case, independent research seems like a good alternative that allows them to do some research without constraining them too much in their other activities.
4. **If there are currently not enough positions in existing institutions:**There are many talented researchers interested in contributing through direct work in AI safety. However, unfortunately, there are not always enough positions in existing institutions to accommodate everyone. While very unfortunate, I hope that this is only a temporary problem and that there will be more positions for alignment researchers in the future. To prepare for a future position, full- or part-time independent research can be a good option.
5. **If they want to stay independent:**there are, of course, other reasons to stay independent than the ones I suggested above, e.g. if someone wants to live in a specific location, has a high preference for flexibility or complete research freedom, and so on.
While the above points are primarily about independent research, I want to emphasize again that upskilling is sometimes the better path depending on your career goals. In that case, I would probably work through [Jacob Hilton’s](https://github.com/jacobhilton/deep_learning_curriculum) or [Gabriel Mukobi’s](https://forum.effectivealtruism.org/posts/S7dhJR5TDwPb5jypG/levelling-up-in-ai-safety-research-engineering) curriculum on my own or with collaborators.
Tips for independent research
=============================
I think independent research is a very high-variance path, i.e. because it has so little structure and oversight, some people excel at it while others get nearly nothing out of it. Furthermore, the “default” path for independent research is probably relatively far away from fulfilling its full potential because good execution requires much more active effort than alternative paths.
I guess, this default path roughly looks like this: “Someone is excited about alignment and wants to contribute. They come up with a research idea and write a proposal to a funder. The proposal is plausible to someone with general knowledge about alignment and the grant gets approved. The researcher starts with their project and makes some initial progress. However, they also hit some unexpected roadblocks. After a while, the roadblocks turn out to be more substantial than initially expected and they reduce the scope of their project to get around them. The smaller scope of the project is still too ambitious and they carve out a small subquestion of their original proposal and do some research on that. They make progress but the grant is nearing its end so they write up their unfinished project and publish it. They get some positive feedback for the effort and preliminary findings but feel personally dissatisfied with how the project went. They then move on to do other things.”
I don’t want to criticize people who have roughly followed this path during their independent research but I think we can agree that there are a lot of things that could have gone better here. One of the reasons why I expect some version of this to be the default path rather than the more optimal version is that people are unaware of the paths they could take or at least don’t think that these paths are open to them. This is because most of the things that improve your independent research require an active effort by you, e.g. YOU have to reach out to another researcher, YOU have to make a plan for yourself, YOU have to create your own accountability mechanism and YOU have to expose your own ideas to get feedback. All of this can feel scary, especially when you aren’t (or at least don’t feel like) an established member of the community but I think it is crucial for the success of your project.
Some tips to increase the probability of success for your independent research efforts include:
1. **Write down your project and get feedback early on:**Before you start doing stuff, there should be a document (maybe 2-3 pages) answering some very basic questions like “what is the goal of this project?”, “what is the theory of change for this project?”, “what concrete steps do you want to take?”, “how does it relate to other research on this topic?”, etc. After you think you can answer these questions sufficiently well, find people to give you feedback. These might be people you know from EAG or have seen writing about similar topics on the alignment forum. Just send them a friendly message and send them your google doc in case they agree to give some feedback. Sometimes they don’t have any time or can’t provide any feedback but might refer you to someone who does. Keep in mind that they are busy so you can’t expect them to give you very detailed feedback at this point. The information you should be aiming for is “does a more senior person think this project is worthwhile and actually within the scope of independent research?”. Also, there is a delicate balance here. If you send out your ideas before you have developed them a bit on your own, you might get feedback that you could have given yourself. If you send it out too late, you might have wasted some time because a more senior person could have told you that your plan probably doesn’t work as intended.
2. **Actively look for collaborations:**Collaborations have many advantages, e.g. it’s motivating, and you can share ideas and debug each other. Collaborations can also come in many forms ranging from monthly quick calls to working very closely together.
There are probably people somewhere in the alignment space who work on problems related to yours. They might be other independent researchers, work for an EA organisation or somewhere in academia. It’s not always clear who these potential collaborators are because most people don’t publicly state what they are working on all the time or at least not in a place that is visible to you. Therefore, you should assume that the burden of finding these other people is on you. Possible ways of finding them include: searching through the different forums for topics related to yours, posting your interest in collaboration on the [alignment slack](https://www.aisafetysupport.org/resources/lots-of-links), using your network and asking around or using conferences such as EAG to find interested people.
3. **Join a group or program:**There are multiple programs within the AI safety community and I think joining them is almost surely better than doing research on your own if there is an overlap in interest. The programs I have in mind are [SERI MATS](https://www.serimats.org/), [MLAB](https://forum.effectivealtruism.org/posts/vvocfhQ7bcBR4FLBx/apply-to-the-second-ml-for-alignment-bootcamp-mlab-2-in), [REMIX](https://www.lesswrong.com/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability), [Refine](https://www.alignmentforum.org/posts/D7epkkJb3CqDTYgX9/refine-an-incubator-for-conceptual-alignment-research-bets), the [AI safety camp](https://aisafety.camp/), [AGISF](https://www.agisafetyfundamentals.com/), etc. Unfortunately, these programs are usually restricted to a specific time of the year and have a lot of applicants. But even if you think your chance of getting accepted is low, you should still apply because the payoffs are so high. Additionally, some applications are designed to provide value even if you don’t end up getting accepted, e.g. SERI MATS has a ton of interesting questions in their application.
4. **Create accountability mechanisms:**Some people have a very exploratory view on research, e.g. they think something like “we don’t know what the outcome is, things can change rapidly, there is no reason to plan it out beforehand”. I prefer and recommend a more product-driven approach to research, i.e. from the beginning, you intend to publish a post that answers your research question. This post can be about a negative finding, e.g. your post can say “I tried the following things and nothing worked” but in my eyes, committing to a product is very helpful to make progress. There are other ways of keeping yourself accountable, e.g. by defining intermediate goals or criteria by which you could evaluate if your research was successful. Most of this is neither new nor complicated you really just have to do it.
5. **Be very clear on what your goals are:**I think you should be clear about what your goals for the independent research are from the start. For most people, independent research is probably temporary, e.g. they want to do independent research for half a year and then use the new skills to apply to an existing AI safety institution. In that case, the goal could be something like “provide evidence that I understand the scientific frontier in my research area and am able to contribute”. In case the person wants to do independent research for longer, e.g. multiple years, they still have to get funding, etc. Thus, a goal could be “provide evidence that I have a solid plan for the next years and am able to execute it”. In most other paths, you’ll get a certificate at some point, e.g. a Bachelor’s or Master’s degree. In independent research you get nothing by default, you basically have to make the certificate yourself.
6. **Do whatever is most effective to reach your goal**. I think there are a lot of stereotypes and narratives about research that are unhelpful. For example, I sometimes hear that doing novel research is better than replicating existing work, which I don’t think is true at all. Or sometimes people first want to “understand every other piece of work on the topic” before starting their own research or think that they have to finish every paper they start reading. In reality, I think the most effective strategy is often a messy back-and-forth between reading/skimming existing work and working on your own project. Sometimes the best strategy is to dive right into code, sometimes you should first try to understand more background literature. The variance between projects is so high that I wouldn’t recommend always following the same pattern but making a plan for that particular project and then executing and adapting it.
Final thoughts
==============
I think independent research serves an important role in the EA and AI safety landscape but it comes with up- and downsides. Concretely, I’m worried that independent research becomes the one-size-fits-all solution when the capacity of established EA institutions is too low. I think there is a risk that doing independent research, if executed suboptimally, could waste a lot of talent (due to opportunity costs), or disheartened independent researchers will not want to continue contributing to EA/AI safety if they had a bad experience.
My personal experience with independent research was great and I want other people to get the most out of it. I hope my thoughts on independent research are helpful. Feedback and disagreement are appreciated.
|
7dd386f5-a24d-457e-886a-5331253d1596
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Status: Map and Territory
I’m here to add another angle to the discussion on social vs. objective truth (example). Here’s an analogy for reasoning about status games and why people react so strongly against improper status moves:
Society is a collective consciousness. From Society’s point of view, the status game is the map. Genuine competence (some combination of skill, virtue, and value) is the territory. The map is meant to track the territory.
Human instinctively play the status game; it’s impossible to just say what you mean. The status game is built into people’s verbal and nonverbal behaviors toward one another.
If the status game is a good map, you can decide who to befriend, admire, and chastise based simply on their status moves. You can figure out who best to ask for advice by the way they hold their arms. You can trust the beliefs of confident people without individually investigating each of their claims. The human brain opts into the status game by default to partake in all this free value.
If the accuracy of the status game is corrupted, the map loses all value. Trust breaks down and you have to rely on first principles.
There’s an approved way of climbing the status ladder: acquiring genuine competence. Well-socialized individuals naturally play higher status as they become more competent in the relevant domain, since the connection between competence and status is built into their brains. Society approves: the map keeps fidelity to the territory.
There’s an improper way of climbing the status ladder: playing status above your competence. Jordan Peterson’s go-to example is serial killer Paul Bernardo in this prison interview. Note the minute-long interaction between Bernardo and the lawyer(?) on the right. Bernardo acts like a disappointed CEO lecturing a wayward and nervous underling.
Knowing the truth about the individuals involved, I have a visceral reaction against this status interaction: the map has detached from the territory. Even if Bernardo is speaking only l
|
9698e1f0-d196-4992-ab8b-eb00865a19e5
|
StampyAI/alignment-research-dataset/distill
|
Distill Scientific Journal
|
Why Momentum Really Works
Why Momentum Really Works
=========================
Step-size α = 0.02
Momentum β = 0.99
We often think of Momentum as a means of dampening oscillations and speeding up the iterations, leading to faster convergence. But it has other interesting behavior. It allows a larger range of step-sizes to be used, and creates its own oscillations. What is going on?
dt-byline {
font-size: 12px;
line-height: 18px;
display: block;
border-top: 1px solid rgba(0, 0, 0, 0.1);
border-bottom: 1px solid rgba(0, 0, 0, 0.1);
color: rgba(0, 0, 0, 0.5);
padding-top: 12px;
padding-bottom: 12px;
}
dt-article.centered dt-byline {
text-align: center;
}
dt-byline a,
dt-article dt-byline a {
text-decoration: none;
border-bottom: none;
}
dt-article dt-byline a:hover {
text-decoration: underline;
border-bottom: none;
}
dt-byline .authors {
text-align: left;
}
dt-byline .name {
display: inline;
text-transform: uppercase;
}
dt-byline .affiliation {
display: inline;
}
dt-byline .date {
display: block;
text-align: left;
}
dt-byline .year, dt-byline .month {
display: inline;
}
dt-byline .citation {
display: block;
text-align: left;
}
dt-byline .citation div {
display: inline;
}
@media(min-width: 768px) {
dt-byline {
}
}
@media(min-width: 1080px) {
dt-byline {
border-bottom: none;
margin-bottom: 70px;
}
dt-byline a:hover {
color: rgba(0, 0, 0, 0.9);
}
dt-byline .authors {
display: inline-block;
}
dt-byline .author {
display: inline-block;
margin-right: 12px;
/\*padding-left: 20px;\*/
/\*border-left: 1px solid #ddd;\*/
}
dt-byline .affiliation {
display: block;
}
dt-byline .author:last-child {
margin-right: 0;
}
dt-byline .name {
display: block;
}
dt-byline .date {
border-left: 1px solid rgba(0, 0, 0, 0.1);
padding-left: 15px;
margin-left: 15px;
display: inline-block;
}
dt-byline .year, dt-byline .month {
display: block;
}
dt-byline .citation {
border-left: 1px solid rgba(0, 0, 0, 0.15);
padding-left: 15px;
margin-left: 15px;
display: inline-block;
}
dt-byline .citation div {
display: block;
}
}
[Gabriel Goh](http://gabgoh.github.io)
[UC Davis](http://math.ucdavis.edu)
April. 4
2017
[Citation:
Goh, 2017](#citation)
// Render Foreground
var iterControl = genIterDiagram(bananaf, [1,1/3], [[-2,2],[2/3 + 0.4,-2/3 + 0.4]])
.alpha(0.003)
.beta(0)
(d3.select("#banana").style("position","relative"))
var iterChange = iterControl.control
var getw0 = iterControl.w0
var StepRange = d3.scaleLinear().domain([0,100]).range([0,0.0062])
var MomentumRange = d3.scaleLinear().domain([0,100]).range([0,0.98])
var update = function (i,j) { iterChange(i, 0, getw0()) }
var slidera = sliderGen([230, 40])
.ticks([0,0.003,0.006])
.ticktitles( function(d,i) { return ["0", "0.003", "0.006"][i]})
.change( function (i) {
d3.select("#sliderAlpha").selectAll(".figtext").html("Step-size α = " + getalpha().toPrecision(2) )
iterChange(getalpha(), getbeta(), getw0() )
} )
.startxval(0.003)
.cRadius(7)
.shifty(-12)
.margins(20,20)
var sliderb = sliderGen([230, 40])
.ticks([0,0.5,0.99])
.change( function (i) {
d3.select("#sliderBeta").selectAll(".figtext").html("Momentum β = " + getbeta().toPrecision(2) )
iterChange(getalpha(), getbeta(), getw0() )
} )
.cRadius(7)
.shifty(-12)
.startxval(0.74)
.margins(20,20)
var getalpha = slidera( d3.select("#sliderAlpha")).xval
var getbeta = sliderb( d3.select("#sliderBeta")).xval
iterChange(getalpha(), getbeta(), getw0() )
Here’s a popular story about momentum [1, 2, 3]: gradient descent is a man walking down a hill. He follows the steepest path downwards; his progress is slow, but steady. Momentum is a heavy ball rolling down the same hill. The added inertia acts both as a smoother and an accelerator, dampening oscillations and causing us to barrel through narrow valleys, small humps and local minima.
This standard story isn’t wrong, but it fails to explain many important behaviors of momentum. In fact, momentum can be understood far more precisely if we study it on the right model.
One nice model is the convex quadratic. This model is rich enough to reproduce momentum’s local dynamics in real problems, and yet simple enough to be understood in closed form. This balance gives us powerful traction for understanding this algorithm.
---
We begin with gradient descent. The algorithm has many virtues, but speed is not one of them. It is simple — when optimizing a smooth function
dt-math[block] {
display: block;
}
fff, we make a small step in the gradient
dt-math[block] {
display: block;
}
wk+1=wk−α∇f(wk).w^{k+1} = w^k-\alpha\nabla f(w^k).wk+1=wk−α∇f(wk).
For a step-size small enough, gradient descent makes a monotonic improvement at every iteration. It always converges, albeit to a local minimum. And under a few weak curvature conditions it can even get there at an exponential rate.
But the exponential decrease, though appealing in theory, can often be infuriatingly small. Things often begin quite well — with an impressive, almost immediate decrease in the loss. But as the iterations progress, things start to slow down. You start to get a nagging feeling you’re not making as much progress as you should be. What has gone wrong?
The problem could be the optimizer’s old nemesis, pathological curvature. Pathological curvature is, simply put, regions of
dt-math[block] {
display: block;
}
fff which aren’t scaled properly. The landscapes are often described as valleys, trenches, canals and ravines. The iterates either jump between valleys, or approach the optimum in small, timid steps. Progress along certain directions grind to a halt. In these unfortunate regions, gradient descent fumbles.
Momentum proposes the following tweak to gradient descent. We give gradient descent a short-term memory:
dt-math[block] {
display: block;
}
zk+1=βzk+∇f(wk)wk+1=wk−αzk+1
\begin{aligned}
z^{k+1}&=\beta z^{k}+\nabla f(w^{k})\\[0.4em]
w^{k+1}&=w^{k}-\alpha z^{k+1}
\end{aligned}
zk+1wk+1=βzk+∇f(wk)=wk−αzk+1
The change is innocent, and costs almost nothing. When
dt-math[block] {
display: block;
}
β=0\beta = 0β=0 , we recover gradient descent. But for
dt-math[block] {
display: block;
}
β=0.99\beta = 0.99β=0.99 (sometimes
dt-math[block] {
display: block;
}
0.9990.9990.999, if things are really bad), this appears to be the boost we need. Our iterations regain that speed and boldness it lost, speeding to the optimum with a renewed energy.
Optimizers call this minor miracle “acceleration”.
The new algorithm may seem at first glance like a cheap hack. A simple trick to get around gradient descent’s more aberrant behavior — a smoother for oscillations between steep canyons. But the truth, if anything, is the other way round. It is gradient descent which is the hack. First, momentum gives up to a quadratic speedup on many functions. 1 This is no small matter — this is similar to the speedup you get from the Fast Fourier Transform, Quicksort, and Grover’s Algorithm. When the universe gives you quadratic speedups, you should start to pay attention.
But there’s more. A lower bound, courtesy of Nesterov [5], states that momentum is, in a certain very narrow and technical sense, optimal. Now, this doesn’t mean it is the best algorithm for all functions in all circumstances. But it does satisfy some curiously beautiful mathematical properties which scratch a very human itch for perfection and closure. But more on that later. Let’s say this for now — momentum is an algorithm for the book.
---
First Steps: Gradient Descent
-----------------------------
We begin by studying gradient descent on the simplest model possible which isn’t trivial — the convex quadratic,
dt-math[block] {
display: block;
}
f(w)=12wTAw−bTw,w∈Rn.
f(w) = \tfrac{1}{2}w^TAw - b^Tw, \qquad w \in \mathbf{R}^n.
f(w)=21wTAw−bTw,w∈Rn.
Assume
dt-math[block] {
display: block;
}
AAA is symmetric and invertible, then the optimal solution
dt-math[block] {
display: block;
}
w⋆w^{\star}w⋆ occurs at
dt-math[block] {
display: block;
}
w⋆=A−1b. w^{\star} = A^{-1}b.w⋆=A−1b.
Simple as this model may be, it is rich enough to approximate many functions (think of
dt-math[block] {
display: block;
}
AAA as your favorite model of curvature — the Hessian, Fisher Information Matrix [6], etc) and captures all the key features of pathological curvature. And more importantly, we can write an exact closed formula for gradient descent on this function.
This is how it goes. Since
dt-math[block] {
display: block;
}
∇f(w)=Aw−b\nabla f(w)=Aw - b∇f(w)=Aw−b, the iterates are
dt-math[block] {
display: block;
}
wk+1=wk−α(Awk−b).
w^{k+1}=w^{k}- \alpha (Aw^{k} - b).
wk+1=wk−α(Awk−b).
Here’s the trick. There is a very natural space to view gradient descent where all the dimensions act independently — the eigenvectors of
dt-math[block] {
display: block;
}
AAA.
deleteQueue.push(renderLoading(d3.select("#change\_of\_variables")))
renderQueue.push(function(callback) {
var U = givens(Math.PI/4)
var Ut = numeric.transpose(U)
// Render Foreground
var left = d3.select("#mom1").style("border", "1px solid rgba(0, 0, 0, 0.2)")
var c1 = genIterDiagram(quadf, [0,0], [[-3,3],[-3,3]])
.width(340)
.height(340)
.iters(300)
.alpha(0.018)
.showSolution(false)
.pathWidth(1)
.circleRadius(1.5)
.pointerScale(0.8)
.showStartingPoint(false)
.drag(function() {
c2.control(c1.alpha(),
c1.beta(),
numeric.dot(U,c1.w0())) })
(left)
var right = d3.select("#mom2").style("border", "1px solid rgba(0, 0, 0, 0.2)")
var c2 = genIterDiagram(eyef, [0,0], [[-3,3],[-3,3]])
.width(340)
.height(340)
.iters(300)
.alpha(0.018)
.showSolution(false)
.pathWidth(1)
.circleRadius(1.5)
.pointerScale(0.8)
.showStartingPoint(false)
.drag(function() {
c1.control(c2.alpha(),
c2.beta(),
numeric.dot(Ut,c2.w0())) })
(right)
// Initialize
c2.control(0.018,0,[-2.5,1])
c1.control(0.018,0,numeric.dot(Ut,[-2.5,1]));
callback(null);
});
Every symmetric matrix
dt-math[block] {
display: block;
}
AAA has an eigenvalue decomposition
dt-math[block] {
display: block;
}
A=Q diag(λ1,…,λn) QT,Q=[q1,…,qn],
A=Q\ \text{diag}(\lambda\_{1},\ldots,\lambda\_{n})\ Q^{T},\qquad Q = [q\_1,\ldots,q\_n],
A=Q diag(λ1,…,λn) QT,Q=[q1,…,qn],
and, as per convention, we will assume that the
dt-math[block] {
display: block;
}
λi\lambda\_iλi’s are sorted, from smallest
dt-math[block] {
display: block;
}
λ1\lambda\_1λ1 to biggest
dt-math[block] {
display: block;
}
λn\lambda\_nλn. If we perform a change of basis,
dt-math[block] {
display: block;
}
xk=QT(wk−w⋆)x^{k} = Q^T(w^{k} - w^\star)xk=QT(wk−w⋆), the iterations break apart, becoming:
dt-math[block] {
display: block;
}
xik+1=xik−αλixik=(1−αλi)xik=(1−αλi)k+1xi0
\begin{aligned}
x\_{i}^{k+1} & =x\_{i}^{k}-\alpha \lambda\_ix\_{i}^{k} \\[0.4em]
&= (1-\alpha\lambda\_i)x^k\_i=(1-\alpha \lambda\_i)^{k+1}x^0\_i
\end{aligned}
xik+1=xik−αλixik=(1−αλi)xik=(1−αλi)k+1xi0
Moving back to our original space
dt-math[block] {
display: block;
}
www, we can see that
dt-math[block] {
display: block;
}
wk−w⋆=Qxk=∑inxi0(1−αλi)kqi
w^k - w^\star = Qx^k=\sum\_i^n x^0\_i(1-\alpha\lambda\_i)^k q\_i
wk−w⋆=Qxk=i∑nxi0(1−αλi)kqi
and there we have it — gradient descent in closed form.
### Decomposing the Error
The above equation admits a simple interpretation. Each element of
dt-math[block] {
display: block;
}
x0x^0x0 is the component of the error in the initial guess in the
dt-math[block] {
display: block;
}
QQQ-basis. There are
dt-math[block] {
display: block;
}
nnn such errors, and each of these errors follows its own, solitary path to the minimum, decreasing exponentially with a compounding rate of
dt-math[block] {
display: block;
}
1−αλi1-\alpha\lambda\_i1−αλi. The closer that number is to
dt-math[block] {
display: block;
}
111, the slower it converges.
For most step-sizes, the eigenvectors with largest eigenvalues converge the fastest. This triggers an explosion of progress in the first few iterations, before things slow down as the smaller eigenvectors’ struggles are revealed. By writing the contributions of each eigenspace’s error to the loss
dt-math[block] {
display: block;
}
f(wk)−f(w⋆)=∑(1−αλi)2kλi[xi0]2
f(w^{k})-f(w^{\star})=\sum(1-\alpha\lambda\_{i})^{2k}\lambda\_{i}[x\_{i}^{0}]^2
f(wk)−f(w⋆)=∑(1−αλi)2kλi[xi0]2
we can visualize the contributions of each error component to the loss.
Optimization can be seen as combination of several component problems, shown here as 1 2 3 with eigenvalues
dt-math[block] {
display: block;
}
λ1=0.01\lambda\_1=0.01λ1=0.01,
dt-math[block] {
display: block;
}
λ2=0.1\lambda\_2=0.1λ2=0.1, and
dt-math[block] {
display: block;
}
λ3=1\lambda\_3=1λ3=1 respectively.
Step-size
Optimal Step-size
deleteQueue.push(renderLoading(d3.select("#milestones\_gd")))
renderQueue.push(function(callback) {
var graphDiv = d3.select("#obj")
.style("width", 920 + "px")
.style("height", 300 + "px")
.style("top", "90px")
.style("position", "relative")
.style("margin-left", "auto")
.style("margin-right", "auto")
.attr("width", 920)
.attr("height", 500)
var svg = graphDiv.append("svg")
.attr("width", 920)
.attr("height", 300)
.style("position","absolute")
.style("left", "15px")
var updateSliderGD = renderMilestones(svg, function() {});
var alphaHTML = MathCache("alpha-equals");
var slidera = sliderGen([250, 80])
.ticks([0,1,200/(101),2])
.change( function (i) {
var html = alphaHTML + '<span style="font-weight: normal;">' + i.toPrecision(4) + "</span>";
d3.select("#stepSizeMilestones")
.html("Stepsize " + html )
updateSliderGD(i,0.000)
} )
.ticktitles(function(d,i) { return [0,1,"",2][i] })
.startxval(200/(101))
.cRadius(7)
.shifty(-12)
.shifty(10)
.margins(20,20)(d3.select("#sliderStep"))
// renderDraggable(svg, [133.5, 23], [114.5, 90], 2, " ").attr("opacity", 0.1)
// renderDraggable(svg, [133.5, 88], [115.5, 95], 2, " ").attr("opacity", 0.1)
// renderDraggable(svg, [132.5, 154], [114.5, 100], 2, " ").attr("opacity", 0.1)
d3.select("#milestones\_gd\_optstep").on("click", slidera.init)
svg.append("text")
.attr("class", "katex morsd mathit")
.style("font-size", "19px")
.style("font-family","KaTeX\_Math")
.attr("x", 105)
.attr("y", 50)
.attr("text-anchor", "end")
.attr("fill", "gray")
.html("f(w<tspan baseline-shift = \"super\" font-size = \"15\">k</tspan>) - f(w<tspan baseline-shift = \"super\" font-size = \"15\">\*</tspan>)")
svg.append("text")
.style("font-size", "13px")
.attr("x", 0)
.attr("y", 80)
.attr("dy", 0)
.attr("transform", "translate(110,0)")
.attr("class", "caption")
.attr("text-anchor", "end")
.attr("fill", "gray")
.text("At the initial point, the error in each component is equal.")
svg.selectAll(".caption").call(wrap, 100)
svg.append("text")
.style("font-size", "13px")
.attr("x", 420)
.attr("y", 270)
.attr("dy", 0)
.attr("dx", -295)
.attr("text-anchor", "start")
.attr("fill", "gray")
.text("At the optimum, the rates of convergence of the largest and smallest eigenvalues equalize.")
callback(null);
});
### Choosing A Step-size
The above analysis gives us immediate guidance as to how to set a step-size
dt-math[block] {
display: block;
}
α\alphaα. In order to converge, each
dt-math[block] {
display: block;
}
∣1−αλi∣|1-\alpha \lambda\_i|∣1−αλi∣ must be strictly less than 1. All workable step-sizes, therefore, fall in the interval
dt-math[block] {
display: block;
}
0<αλi<2.0<\alpha\lambda\_i<2.0<αλi<2.
The overall convergence rate is determined by the slowest error component, which must be either
dt-math[block] {
display: block;
}
λ1\lambda\_1λ1 or
dt-math[block] {
display: block;
}
λn\lambda\_nλn:
dt-math[block] {
display: block;
}
rate(α) = maxi∣1−αλi∣ = max{∣1−αλ1∣, ∣1−αλn∣}
\begin{aligned}\text{rate}(\alpha) & ~=~ \max\_{i}\left|1-\alpha\lambda\_{i}\right|\\[0.9em] & ~=~ \max\left\{|1-\alpha\lambda\_{1}|,~ |1-\alpha\lambda\_{n}|\right\} \end{aligned}
rate(α) = imax∣1−αλi∣ = max{∣1−αλ1∣, ∣1−αλn∣}
This overall rate is minimized when the rates for
dt-math[block] {
display: block;
}
λ1\lambda\_1λ1 and
dt-math[block] {
display: block;
}
λn\lambda\_nλn are the same — this mirrors our informal observation in the previous section that the optimal step-size causes the first and last eigenvectors to converge at the same rate. If we work this through we get:
dt-math[block] {
display: block;
}
optimal α = argminα rate(α) = 2λ1+λnoptimal rate = minα rate(α) = λn/λ1−1λn/λ1+1
\begin{aligned}
\text{optimal }\alpha ~=~{\mathop{\text{argmin}}\limits\_\alpha} ~\text{rate}(\alpha) & ~=~\frac{2}{\lambda\_{1}+\lambda\_{n}}\\[1.4em]
\text{optimal rate} ~=~{\min\_\alpha} ~\text{rate}(\alpha) & ~=~\frac{\lambda\_{n}/\lambda\_{1}-1}{\lambda\_{n}/\lambda\_{1}+1}
\end{aligned}
optimal α = αargmin rate(α)optimal rate = αmin rate(α) = λ1+λn2 = λn/λ1+1λn/λ1−1
Notice the ratio
dt-math[block] {
display: block;
}
λn/λ1\lambda\_n/\lambda\_1λn/λ1 determines the convergence rate of the problem. In fact, this ratio appears often enough that we give it a name, and a symbol — the condition number.
dt-math[block] {
display: block;
}
condition number:=κ:=λnλ1
\text{condition number} := \kappa :=\frac{\lambda\_n}{\lambda\_1}
condition number:=κ:=λ1λn
The condition number means many things. It is a measure of how close to singular a matrix is. It is a measure of how robust
dt-math[block] {
display: block;
}
A−1bA^{-1}bA−1b is to perturbations in
dt-math[block] {
display: block;
}
bbb. And, in this context, the condition number gives us a measure of how poorly gradient descent will perform. A ratio of
dt-math[block] {
display: block;
}
κ=1\kappa = 1κ=1 is ideal, giving convergence in one step (of course, the function is trivial). Unfortunately the larger the ratio, the slower gradient descent will be. The condition number is therefore a direct measure of pathological curvature.
---
Example: Polynomial Regression
------------------------------
The above analysis reveals an insight: all errors are not made equal. Indeed, there are different kinds of errors,
dt-math[block] {
display: block;
}
nnn to be exact, one for each of the eigenvectors of
dt-math[block] {
display: block;
}
AAA. And gradient descent is better at correcting some kinds of errors than others. But what do the eigenvectors of
dt-math[block] {
display: block;
}
AAA mean? Surprisingly, in many applications they admit a very concrete interpretation.
Lets see how this plays out in polynomial regression. Given 1D data,
dt-math[block] {
display: block;
}
ξi\xi\_iξi, our problem is to fit the model
dt-math[block] {
display: block;
}
model(ξ)=w1p1(ξ)+⋯+wnpn(ξ)pi=ξ↦ξi−1
\text{model}(\xi)=w\_{1}p\_{1}(\xi)+\cdots+w\_{n}p\_{n}(\xi)\qquad p\_{i}=\xi\mapsto\xi^{i-1}
model(ξ)=w1p1(ξ)+⋯+wnpn(ξ)pi=ξ↦ξi−1
to our observations,
dt-math[block] {
display: block;
}
did\_idi. This model, though nonlinear in the input
dt-math[block] {
display: block;
}
ξ\xiξ, is linear in the weights, and therefore we can write the model as a linear combination of monomials, like:
deleteQueue.push(renderLoading(d3.select("#poly0")))
renderQueue.push(function(callback) {
// Preprocess x, get eigendecomposition, etc
var x = [-0.6, -0.55,-0.5,-0.45,-0.4,0.4,0.45,0.5,0.55,0.6]
var D = vandermonde(x, 5)
var Eigs = eigSym(numeric.dot(numeric.transpose(D),D))
var U = Eigs.U
var lambda = Eigs.lambda
// Preprocess y
var b = [-3/2,-4/2,-5/2,-3/2,-2/2,1/2,2/2,3/2,2/2,1/2]
var Dtb = numeric.dot(b,D)
var sol = numeric.mul(numeric.dot(U, Dtb), lambda.map(inv))
var step = 1.8/lambda[0]
var iter = geniter(U, lambda, Dtb, step)
var eigensum = d3.select("#poly0")
var wi = [-2,-2,2,2,2,-2]
function refit(b) {
var Dtb = numeric.dot(b,D)
var sol = numeric.mul(numeric.dot(U, Dtb), lambda.map(inv))
var Utsol = numeric.dot(sol,U)
eigenControl.updateweights(Utsol)
}
var eigenControl = renderEigenPanel(eigensum, numeric.identity(6), x, b, wi, refit);
// Swoopy Annotator
var annotations = [
{
"x": 0,
"y": 0,
"path": "M 60,5 A 19.018 19.018 0 0 0 36,27",
"text": "scrub values",
"textOffset": [
64,
9
]
}
]
drawAnnotations(d3.select("#poly0f"), annotations)
callback(null);
});
Because of the linearity, we can fit this model to our data
dt-math[block] {
display: block;
}
ξi\xi\_iξi using linear regression on the model mismatch
dt-math[block] {
display: block;
}
minimizew12∑i(model(ξi)−di)2 = 12∥Zw−d∥2
\text{minimize}\_w \qquad\tfrac{1}{2}\sum\_i (\text{model}(\xi\_{i})-d\_{i})^{2} ~~=~~ \tfrac{1}{2}\|Zw - d\|^2
minimizew21i∑(model(ξi)−di)2 = 21∥Zw−d∥2
where
dt-math[block] {
display: block;
}
Z=(1ξ1ξ12…ξ1n−11ξ2ξ22…ξ2n−1⋮⋮⋮⋱⋮1ξmξm2…ξmn−1).
Z=\left(\begin{array}{ccccc}
1 & \xi\_{1} & \xi\_{1}^{2} & \ldots & \xi\_{1}^{n-1}\\
1 & \xi\_{2} & \xi\_{2}^{2} & \ldots & \xi\_{2}^{n-1}\\
\vdots & \vdots & \vdots & \ddots & \vdots\\
1 & \xi\_{m} & \xi\_{m}^{2} & \ldots & \xi\_{m}^{n-1}
\end{array}\right).
Z=⎝⎜⎜⎛11⋮1ξ1ξ2⋮ξmξ12ξ22⋮ξm2……⋱…ξ1n−1ξ2n−1⋮ξmn−1⎠⎟⎟⎞.
The path of convergence, as we know, is elucidated when we view the iterates in the space of
dt-math[block] {
display: block;
}
QQQ (the eigenvectors of
dt-math[block] {
display: block;
}
ZTZZ^T ZZTZ). So let’s recast our regression problem in the basis of
dt-math[block] {
display: block;
}
QQQ. First, we do a change of basis, by rotating
dt-math[block] {
display: block;
}
www into
dt-math[block] {
display: block;
}
QwQwQw, and counter-rotating our feature maps
dt-math[block] {
display: block;
}
ppp into eigenspace,
dt-math[block] {
display: block;
}
p¯\bar{p}p¯. We can now conceptualize the same regression as one over a different polynomial basis, with the model
dt-math[block] {
display: block;
}
model(ξ) = x1p¯1(ξ) + ⋯ + xnp¯n(ξ)p¯i=∑qijpj.
\text{model}(\xi)~=~x\_{1}\bar{p}\_{1}(\xi)~+~\cdots~+~x\_{n}\bar{p}\_{n}(\xi)\qquad \bar{p}\_{i}=\sum q\_{ij}p\_j.
model(ξ) = x1p¯1(ξ) + ⋯ + xnp¯n(ξ)p¯i=∑qijpj.
This model is identical to the old one. But these new features
dt-math[block] {
display: block;
}
p¯\bar{p}p¯ (which I call “eigenfeatures”) and weights have the pleasing property that each coordinate acts independently of the others. Now our optimization problem breaks down, really, into
dt-math[block] {
display: block;
}
nnn small 1D optimization problems. And each coordinate can be optimized greedily and independently, one at a time in any order, to produce the final, global, optimum. The eigenfeatures are also much more informative:
deleteQueue.push(renderLoading(d3.select("#poly1")))
renderQueue.push(function(callback) {
var inv = function(lambda) { return 1/lambda }
var scal = function(lambda) { return lambda < 1e-10 ? -100 : 1.5/Math.sqrt(lambda) }
// Preprocess x, get eigendecomposition, etc
var x = [-0.6, -0.55,-0.5,-0.45,-0.4,0.4,0.45,0.5,0.55,0.6]
var D = vandermonde(x, 5)
var Eigs = eigSym(numeric.dot(numeric.transpose(D),D))
var U = Eigs.U
var lambda = Eigs.lambda
// Preprocess y
var b = [-3/2,-4/2,-5/2,-3/2,-2/2,1/2,2/2,3/2,2/2,1/2]
var Dtb = numeric.dot(b,D)
var sol = numeric.mul(numeric.dot(U, Dtb), lambda.map(inv))
var step = 1.8/lambda[0]
var iter = geniter(U, lambda, Dtb, step)
var eigensum = d3.select("#poly1")
var wi = lambda.slice(0).map(scal)
function refit(b) {
var Dtb = numeric.dot(b,D)
var sol = numeric.mul(numeric.dot(U, Dtb), lambda.map(inv))
var Utsol = numeric.dot(sol,U)
eigenControl.updateweights(sol)
}
var eigenControl = renderEigenPanel(eigensum, U, x, b, wi, refit, true)
var annotate = eigensum
annotate.append("figcaption")
.style("width", 230 + "px")
.style("height", 150 + "px")
.style("left", "0px")
.style("position", "absolute")
.style("padding", "10px")
.html("The data comes in 2 clusters. The first 2 eigenfeatures capture variations between the clusters. ")
annotate.append("figcaption")
.style("width", 230 + "px")
.style("height", 150 + "px")
.style("left", "260px")
.style("position", "absolute")
.style("padding", "10px")
.html("Next there are smooth variations within clusters, peaks within clusters,")
annotate.append("figcaption")
.style("width", 230 + "px")
.style("height", 150 + "px")
.style("left", 530 + "px")
.style("position", "absolute")
.style("padding", "10px")
.html("and finally, jagged polynomials which differ wildly on neighboring points. ");
// Swoopy Annotator
var annotations = [
{
"x": 0,
"y": 0,
"path": "M 807,198 A 26.661 26.661 0 0 1 838,159",
"text": "drag points to fit data",
"textOffset": [
799,
214
]
}]
drawAnnotations(eigensum, annotations)
callback(null);
});
The observations in the above diagram can be justified mathematically. From a statistical point of view, we would like a model which is, in some sense, robust to noise. Our model cannot possibly be meaningful if the slightest perturbation to the observations changes the entire model dramatically. And the eigenfeatures, the principal components of the data, give us exactly the decomposition we need to sort the features by its sensitivity to perturbations in
dt-math[block] {
display: block;
}
did\_idi’s. The most robust components appear in the front (with the largest eigenvalues), and the most sensitive components in the back (with the smallest eigenvalues).
This measure of robustness, by a rather convenient coincidence, is also a measure of how easily an eigenspace converges. And thus, the “pathological directions” — the eigenspaces which converge the slowest — are also those which are most sensitive to noise! So starting at a simple initial point like
dt-math[block] {
display: block;
}
000 (by a gross abuse of language, let’s think of this as a prior), we track the iterates till a desired level of complexity is reached. Let’s see how this plays out in gradient descent.
deleteQueue.push(renderLoading(d3.select("#poly2")))
renderQueue.push(function(callback) {
var inv = function(lambda) { return 1/lambda }
var scal = function(lambda) { return lambda < 1e-10 ? -100 : 1.5/Math.sqrt(lambda) }
// Preprocess x, get eigendecomposition, etc
var x = [-0.6, -0.55,-0.5,-0.45,-0.4,0.4,0.45,0.5,0.55,0.6]
var b = [-3/2,-4/2,-5/2,-3/2,-2/2,1/2,2/2,3/2,2/2,1/2]
var D = vandermonde(x, 5)
var Eigs = eigSym(numeric.dot(numeric.transpose(D),D))
var U = Eigs.U
var lambda = Eigs.lambda
// Preprocess y
var Dtb = numeric.dot(b,D)
var sol = numeric.mul(numeric.dot(U, Dtb), lambda.map(inv))
var step = 1.8/lambda[0]
var iter = geniter(U, lambda, Dtb, step)
var eigensum = d3.select("#poly2")
var wi = lambda.slice(0).map(scal)
function refit(b) {
var Dtb = numeric.dot(b,D)
iter = geniter(U, lambda, Dtb, step)
onChange(sliderControl.slidera.xval())
}
var eigenControl = renderEigenPanel(eigensum, U, x, b, wi, refit, true)
var barlengths = getStepsConvergence(lambda, step).map(Math.log)
var onChange = function(i) {
eigenControl.updateweights(numeric.dot(U,iter(Math.floor(Math.exp(i-0.1)) )))
}
var sliderControl = sliderBarGen(barlengths, function(i) {return Math.exp(i-0.1)}).update(onChange)(d3.select("#poly2"))
d3.select("#poly2").append("figcaption")
.style("width", "120px")
.style("position", "absolute")
.style("left", "820px")
.style("top","200px")
.html("When an eigenspace has converged to three significant digits, the bar greys out. Drag the observations to change fit.")
sliderControl.slidera.init()
// var figwidth = d3.select("#poly2").style("width")
// var figheight = d3.select("#poly2").style("height")
// var svgannotate = d3.select("#poly2")
// .append("svg")
// .style("width", figwidth)
// .style("height", figheight)
// .style("position", "absolute")
// .style("top","0px")
// .style("left","0px")
// .style("pointer-events","none")
// renderDraggable(svgannotate,
// [139.88888549804688, 243.77951049804688],
// [121.88888549804688, 200.77951049804688],
// 5,
// "We begin at x=w=0");
// Swoopy Annotator
var annotations = [
{
"x": 0,
"y": 0,
"path": "M 74,202 A 52.274 52.274 0 0 0 134,245",
"text": "We begin at x=w=0",
"textOffset": [
21,
198
]
}
]
drawAnnotations(d3.select("#poly2"), annotations)
callback(null);
});
This effect is harnessed with the heuristic of early stopping : by stopping the optimization early, you can often get better generalizing results. Indeed, the effect of early stopping is very similar to that of more conventional methods of regularization, such as Tikhonov Regression. Both methods try to suppress the components of the smallest eigenvalues directly, though they employ different methods of spectral decay.2 But early stopping has a distinct advantage. Once the step-size is chosen, there are no regularization parameters to fiddle with. Indeed, in the course of a single optimization, we have the entire family of models, from underfitted to overfitted, at our disposal. This gift, it seems, doesn’t come at a price. A beautiful free lunch [7] indeed.
---
The Dynamics of Momentum
------------------------
Let’s turn our attention back to momentum. Recall that the momentum update is
dt-math[block] {
display: block;
}
zk+1=βzk+∇f(wk)wk+1=wk−αzk+1.
\begin{aligned}
z^{k+1}&=\beta z^{k}+\nabla f(w^{k})\\[0.4em]
w^{k+1}&=w^{k}-\alpha z^{k+1}.
\end{aligned}
zk+1wk+1=βzk+∇f(wk)=wk−αzk+1.
Since
dt-math[block] {
display: block;
}
∇f(wk)=Awk−b\nabla f(w^k) = Aw^k - b∇f(wk)=Awk−b, the update on the quadratic is
dt-math[block] {
display: block;
}
zk+1=βzk+(Awk−b)wk+1=wk−αzk+1.
\begin{aligned}
z^{k+1}&=\beta z^{k}+ (Aw^{k}-b)\\[0.4em]
w^{k+1}&=w^{k}-\alpha z^{k+1}.
\end{aligned}
zk+1wk+1=βzk+(Awk−b)=wk−αzk+1.
Following [8], we go through the same motions, with the change of basis
dt-math[block] {
display: block;
}
xk=Q(wk−w⋆)
x^{k} = Q(w^{k} - w^\star)xk=Q(wk−w⋆) and
dt-math[block] {
display: block;
}
yk=Qzk y^{k} = Qz^{k}yk=Qzk, to yield the update rule
dt-math[block] {
display: block;
}
yik+1=βyik+λixikxik+1=xik−αyik+1.
\begin{aligned}
y\_{i}^{k+1}&=\beta y\_{i}^{k}+\lambda\_{i}x\_{i}^{k}\\[0.4em]
x\_{i}^{k+1}&=x\_{i}^{k}-\alpha y\_{i}^{k+1}.
\end{aligned}
yik+1xik+1=βyik+λixik=xik−αyik+1.
in which each component acts independently of the other components (though
dt-math[block] {
display: block;
}
xikx^k\_ixik and
dt-math[block] {
display: block;
}
yiky^k\_iyik are coupled). This lets us rewrite our iterates as
3
dt-math[block] {
display: block;
}
(yikxik)=Rk(yi0xi0)R=(βλi−αβ1−αλi).
\left(\!\!\begin{array}{c}
y\_{i}^{k}\\
x\_{i}^{k}
\end{array}\!\!\right)=R^k\left(\!\!\begin{array}{c}
y\_{i}^{0}\\
x\_{i}^{0}
\end{array}\!\!\right)
\qquad
R = \left(\!\!\begin{array}{cc}
\beta & \lambda\_{i}\\
-\alpha\beta & 1-\alpha\lambda\_{i}
\end{array}\!\!\right).
(yikxik)=Rk(yi0xi0)R=(β−αβλi1−αλi).
There are many ways of taking a matrix to the
dt-math[block] {
display: block;
}
kthk^{th}kth power. But for the
dt-math[block] {
display: block;
}
2×22 \times 22×2 case there is an elegant and little known formula [9] in terms of the eigenvalues of
dt-math[block] {
display: block;
}
RRR,
dt-math[block] {
display: block;
}
σ1\sigma\_1σ1 and
dt-math[block] {
display: block;
}
σ2\sigma\_2σ2.
dt-math[block] {
display: block;
}
Rk={σ1kR1−σ2kR2σ1≠σ2σ1k(kR/σ1−(k−1)I)σ1=σ2,Rj=R−σjIσ1−σ2
\color{#AAA}{\color{black}{R^{k}}=\begin{cases}
\color{black}{\sigma\_{1}^{k}}R\_{1}-\color{black}{\sigma\_{2}^{k}}R\_{2} & \sigma\_{1}\neq\sigma\_{2}\\
\sigma\_{1}^{k}(kR/\sigma\_1-(k-1)I) & \sigma\_{1}=\sigma\_{2}
\end{cases},\qquad R\_{j}=\frac{R-\sigma\_{j}I}{\sigma\_{1}-\sigma\_{2}}}
Rk={σ1kR1−σ2kR2σ1k(kR/σ1−(k−1)I)σ1≠σ2σ1=σ2,Rj=σ1−σ2R−σjI
This formula is rather complicated, but the takeaway here is that it plays the exact same role the individual convergence rates,
dt-math[block] {
display: block;
}
1−αλi1-\alpha\lambda\_i1−αλi do in gradient descent. But instead of one geometric series, we have two coupled series, which may have real or complex values. The convergence rate is therefore the slowest of the two rates,
dt-math[block] {
display: block;
}
max{∣σ1∣,∣σ2∣}\max\{|\sigma\_{1}|,|\sigma\_{2}|\}max{∣σ1∣,∣σ2∣}
4. By plotting this out, we see there are distinct regions of the parameter space which reveal a rich taxonomy of convergence behavior [10]:
Convergence Rate
A plot of
dt-math[block] {
display: block;
}
max{∣σ1∣,∣σ2∣}\max\{|\sigma\_1|, |\sigma\_2|\}max{∣σ1∣,∣σ2∣} reveals distinct regions, each with its own style of convergence.
deleteQueue.push(renderLoading(d3.select("#momentum2D")))
renderQueue.push(function(callback) {
var defaults = [[0.0015, 0.9],
[0.0015, 0.125],
[0.01, 0.00001],
[0.02, 0.05 ],
[0.025, 0.235 ]]
coor = render2DSliderGen(
function(a,b,bold) {
var xy = coor(a,b)
updatePaths[0](xy[0], xy[1],bold)
updateStemGraphs[0](a,b)
},
function(a,b,bold) {
var xy = coor(a,b)
updatePaths[1](xy[0], xy[1],bold)
updateStemGraphs[1](a,b)
},
function(a,b,bold) {
var xy = coor(a,b)
updatePaths[2](xy[0], xy[1],bold)
updateStemGraphs[2](a,b)
},
function(a,b,bold) {
var xy = coor(a,b)
updatePaths[3](xy[0], xy[1],bold)
updateStemGraphs[3](a,b)
},
function(a,b,bold) {
var xy = coor(a,b)
updatePaths[4](xy[0], xy[1],bold)
updateStemGraphs[4](a,b)
}, defaults)(d3.select("#momentumCanvas"))
var tax = renderTaxonomy(d3.select("#momentum2D"))
var updatePaths = renderOverlay(d3.select("#momentumOverlay"), tax.div)
var updateStemGraphs = tax.update
colorMap(
d3.select("#momentumAnnotation"),
180,
d3.scaleLinear().domain([0,0.3,0.5,0.7,1,1.01]).range(colorbrewer.YlGnBu[5].concat(["black"])),
d3.scaleLinear().domain([0,1.2001]).range([0, 180])
)
var up = function (i, alpha, beta) {
var xy = coor(alpha, beta)
updatePaths[i](xy[0], xy[1], true)
updateStemGraphs[i](alpha,beta)
}
for (var i = 0; i<5; i++) {
up(i,defaults[i][0], defaults[i][1])
}
renderMath(document.getElementById("momentum2D"))
callback(null);
});
For what values of
dt-math[block] {
display: block;
}
α\alphaα and
dt-math[block] {
display: block;
}
β\betaβ does momentum converge? Since we need both
dt-math[block] {
display: block;
}
σ1\sigma\_1σ1 and
dt-math[block] {
display: block;
}
σ2\sigma\_2σ2 to converge, our convergence criterion is now
dt-math[block] {
display: block;
}
max{∣σ1∣,∣σ2∣}<1\max\{|\sigma\_{1}|,|\sigma\_{2}|\} < 1max{∣σ1∣,∣σ2∣}<1. The range of available step-sizes work out 5 to be
dt-math[block] {
display: block;
}
0<αλi<2+2βfor0≤β<10<\alpha\lambda\_{i}<2+2\beta \qquad \text{for} \qquad 0 \leq \beta < 10<αλi<2+2βfor0≤β<1
We recover the previous result for gradient descent when
dt-math[block] {
display: block;
}
β=0\beta = 0β=0. But notice an immediate boon we get. Momentum allows us to crank up the step-size up by a factor of 2 before diverging.
---
### The Critical Damping Coefficient
The true magic happens, however, when we find the sweet spot of
dt-math[block] {
display: block;
}
α\alphaα and
dt-math[block] {
display: block;
}
β\betaβ. Let us try to first optimize over
dt-math[block] {
display: block;
}
β\betaβ.
Momentum admits an interesting physical interpretation when
dt-math[block] {
display: block;
}
α\alphaα is [11] small: it is a discretization of a damped harmonic oscillator. Consider a physical simulation operating in discrete time (like a video game).
dt-math[block] {
display: block;
}
yik+1y\_{i}^{k+1}yik+1
dt-math[block] {
display: block;
}
===
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
λixik\lambda\_{i}x\_{i}^{k}λixik
and perturbed by an external force field
We can think of
dt-math[block] {
display: block;
}
−yik-y\_i^k−yik as **velocity**
dt-math[block] {
display: block;
}
βyik\beta y\_{i}^{k}βyik
which is dampened at each step
dt-math[block] {
display: block;
}
xik+1x\_i^{k+1}xik+1
dt-math[block] {
display: block;
}
===
dt-math[block] {
display: block;
}
xik−αyik+1x\_i^k - \alpha y\_i^{k+1}xik−αyik+1
And
dt-math[block] {
display: block;
}
xxx is our particle’s **position**
which is moved at each step by a small amount in the direction of the velocity
dt-math[block] {
display: block;
}
yik+1y^{k+1}\_iyik+1.
renderMath(document.getElementById("momentum\_annotations"))
We can break this equation apart to see how each component affects the dynamics of the system. Here we plot, for
dt-math[block] {
display: block;
}
150150150 iterates, the particle’s velocity (the horizontal axis) against its position (the vertical axis), in a phase diagram.
deleteQueue.push(renderLoading(d3.select("#phasediagram0")))
renderQueue.push(function(callback) {
phaseDiagram\_dec(d3.select("#phasediagram0div"))
renderMath(d3.select("#phasediagram0div").node())
var figure = d3.select("#phasediagram0")
var figwidth = figure.style("width")
var figheight = figure.style("height")
var svg = figure.append("svg")
.style("width", figwidth)
.style("height", figheight)
.style("position", "absolute")
.style("top","0px")
.style("left","0px")
.style("pointer-events", "none")
renderDraggable(svg, [178.5, 66], [199.5, 66], 4, "Initial point <tspan x=\"0\" dy=\"1.2em\">x = 1, y = 1</tspan>").attr("opacity", 0.5)
// renderDraggable(svg, [185, 116], [234, 174], 4, "constant speed").attr("opacity", 0.5)
// renderDraggable(svg, [470, 86], [445, 71], 4, "slows to a halt").attr("opacity", 0.5)
// renderDraggable(svg, [740, 64], [718, 97], 4, "all energy lost in 1 step").attr("opacity", 0.5)
// renderDraggable(svg, [219, 269], [246, 327], 4, "particle returns slowly").attr("opacity", 0.5)
// renderDraggable(svg, [250, 433], [287, 468], 4, "particle returns quickly").attr("opacity", 0.5)
callback(null);
renderMath(document.getElementById("phasediagram0"))
});
This system is best imagined as a weight suspended on a spring. We pull the weight down by one unit, and we study the path it follows as it returns to equilibrium. In the analogy, the spring is the source of our external force
dt-math[block] {
display: block;
}
λixik\lambda\_ix^k\_iλixik, and equilibrium is the state when both the position
dt-math[block] {
display: block;
}
xikx^k\_ixik and the speed
dt-math[block] {
display: block;
}
yiky^k\_iyik are 0. The choice of
dt-math[block] {
display: block;
}
β\betaβ crucially affects the rate of return to equilibrium.
deleteQueue.push(renderLoading(d3.select("#phasediagram1")))
renderQueue.push(function(callback) {
phaseDiagram(d3.select("#phasediagram1"));
renderMath(document.getElementById("phasediagram1"))
callback(null);
});
The critical value of
dt-math[block] {
display: block;
}
β=(1−αλi)2\beta = (1 - \sqrt{\alpha \lambda\_i})^2β=(1−√αλi)2 gives us a convergence rate (in eigenspace
dt-math[block] {
display: block;
}
iii) of
dt-math[block] {
display: block;
}
1−αλi.1 - \sqrt{\alpha\lambda\_i}.1−√αλi. A square root improvement over gradient descent,
dt-math[block] {
display: block;
}
1−αλi1-\alpha\lambda\_i1−αλi! Alas, this only applies to the error in the
dt-math[block] {
display: block;
}
ithi^{th}ith eigenspace, with
dt-math[block] {
display: block;
}
α\alphaα fixed.
### Optimal parameters
To get a global convergence rate, we must optimize over both
dt-math[block] {
display: block;
}
α\alphaα and
dt-math[block] {
display: block;
}
β\betaβ. This is a more complicated affair,6 but they work out to be
dt-math[block] {
display: block;
}
α=(2λ1+λn)2β=(λn−λ1λn+λ1)2
\alpha = \left(\frac{2}{\sqrt{\lambda\_{1}}+\sqrt{\lambda\_{n}}}\right)^{2} \quad \beta = \left(\frac{\sqrt{\lambda\_{n}}-\sqrt{\lambda\_{1}}}{\sqrt{\lambda\_{n}}+\sqrt{\lambda\_{1}}}\right)^{2}
α=(√λ1+√λn2)2β=(√λn+√λ1√λn−√λ1)2
Plug this into the convergence rate, and you get
dt-math[block] {
display: block;
}
κ−1κ+1\frac{\sqrt{\kappa}-1}{\sqrt{\kappa}+1}√κ+1√κ−1
Convergence rate, **Momentum**
dt-math[block] {
display: block;
}
κ−1κ+1 \frac{\kappa-1}{\kappa+1}κ+1κ−1
Convergence rate, **Gradient Descent**
renderMath(document.getElementById("conv\_rate\_comparisons"))
With barely a modicum of extra effort, we have essentially square rooted the condition number! These gains, in principle, require explicit knowledge of
dt-math[block] {
display: block;
}
λ1\lambda\_1λ1 and
dt-math[block] {
display: block;
}
λn\lambda\_nλn. But the formulas reveal a simple guideline. When the problem’s conditioning is poor, the optimal
dt-math[block] {
display: block;
}
α\alphaα is approximately twice that of gradient descent, and the momentum term is close to
dt-math[block] {
display: block;
}
111. So set
dt-math[block] {
display: block;
}
β\betaβ as close to
dt-math[block] {
display: block;
}
111 as you can, and then find the highest
dt-math[block] {
display: block;
}
α\alphaα which still converges. Being at the knife’s edge of divergence, like in gradient descent, is a good place to be.
We can do the same decomposition here with momentum, with eigenvalues
dt-math[block] {
display: block;
}
λ1=0.01\lambda\_1=0.01λ1=0.01,
dt-math[block] {
display: block;
}
λ2=0.1\lambda\_2=0.1λ2=0.1, and
dt-math[block] {
display: block;
}
λ3=1\lambda\_3=1λ3=1. Though the decrease is no longer monotonic, but significantly faster.
dt-math[block] {
display: block;
}
f(wk)−f(w⋆)f(w^k) - f(w^\star)f(wk)−f(w⋆)
Note that the optimal parameters do not necessarily imply the fastest convergence, though, only the fastest asymptotic convergence rate.
Step-size α =
Momentum β =
deleteQueue.push(renderLoading(d3.select("#milestonesMomentumFig")))
renderQueue.push(function(callback) {
var graphDiv = d3.select("#milestonesMomentum")
.style("width", 920 + "px")
.style("height", 300 + "px")
.style("top", "170px")
.style("position", "relative")
.style("margin-left", "auto")
.style("margin-right", "auto")
.attr("width", 920)
.attr("height", 500)
var svg = graphDiv.append("svg").attr("width", 940).attr("height", 500)
var update = renderMilestones(svg, function() {})
var reset = slider2D(d3.select("#sliderStep2D"),
function(x,y) { update(x,y) },
1,
100)
// // Swoopy Annotator
annotations = [
{
"x": 0,
"y": 0,
"path": "M 798,98 A 27.97 27.97 0 0 0 760.9999389648438,70.9999771118164",
"text": "Optimal parameters",
"textOffset": [
740,
109
]
}
]
var sel = drawAnnotations(d3.select("#milestonesMomentumFig"), annotations)
sel.selectAll("text").style("cursor", "pointer").style("pointer-events","all").on("click", reset)
callback(null);
});
While the loss function of gradient descent had a graceful, monotonic curve, optimization with momentum displays clear oscillations. These ripples are not restricted to quadratics, and occur in all kinds of functions in practice. They are not cause for alarm, but are an indication that extra tuning of the hyperparameters is required.
---
Example: The Colorization Problem
---------------------------------
Let’s look at how momentum accelerates convergence with a concrete example. On a grid of pixels let
dt-math[block] {
display: block;
}
GGG be the graph with vertices as pixels,
dt-math[block] {
display: block;
}
EEE be the set of edges connecting each pixel to its four neighboring pixels, and
dt-math[block] {
display: block;
}
DDD be a small set of a few distinguished vertices. Consider the problem of minimizing
dt-math[block] {
display: block;
}
minimize\text{minimize} minimize
dt-math[block] {
display: block;
}
12∑i∈D(wi−1)2\qquad \frac{1}{2} \sum\_{i\in D} (w\_i - 1)^2 21i∈D∑(wi−1)2
The **colorizer** pulls distinguished pixels towards 1
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
12∑i,j∈E(wi−wj)2.\frac{1}{2} \sum\_{i,j\in E} (w\_i - w\_j)^2.21i,j∈E∑(wi−wj)2.
The **smoother** spreads out the color
renderMath(document.getElementById("colorizer\_equation"))
The optimal solution to this problem is a vector of all
dt-math[block] {
display: block;
}
111’s 7. An inspection of the gradient iteration reveals why we take a long time to get there. The gradient step, for each component, is some form of weighted average of the current value and its neighbors:
dt-math[block] {
display: block;
}
wik+1=wik−α∑j∈N(wik−wjk)−{α(wik−1)i∈D0i∉D
w\_{i}^{k+1}=w\_{i}^{k}-\alpha\sum\_{j\in N}(w\_{i}^{k}-w\_{j}^{k})-\begin{cases}
\alpha(w\_{i}^{k}-1) & i\in D\\
0 & i\notin D
\end{cases}
wik+1=wik−αj∈N∑(wik−wjk)−{α(wik−1)0i∈Di∉D
This kind of local averaging is effective at smoothing out local variations in the pixels, but poor at taking advantage of global structure. The updates are akin to a drop of ink, diffusing through water. Movement towards equilibrium is made only through local corrections and so, left undisturbed, its march towards the solution is slow and laborious. Fortunately, momentum speeds things up significantly.
The eigenvectors of the colorization problem form a generalized Fourier basis for
dt-math[block] {
display: block;
}
RnR^nRn. The smallest eigenvalues have low frequencies, hence gradient descent corrects high frequency errors well but not low frequency ones.
deleteQueue.push(renderLoading(d3.select("#flow")))
renderQueue.push(function(callback) {
d3.queue()
.defer(d3.json, "assets/data/Sigma.json")
.defer(d3.json, "assets/data/matrix.json")
.defer(d3.json, "assets/data/Uval.json")
.await(function(error, FlowSigma, M, FlowU) {
if (error) {
console.error("Error loading data files");
}
else {
var reset = renderFlowWidget(d3.select("#flow"), FlowSigma, M, FlowU)
// Swoopy Annotator
var annotations = [
{
"x": 0,
"y": 0,
"path": "M 389,55 A 28.57 28.57 0 0 0 352,30",
"text": "Optimal parameters",
"textOffset": [
341,
65
]
}
]
var sel = drawAnnotations(d3.select("#flow"), annotations)
sel.selectAll("text").style("cursor", "pointer").style("pointer-events","all").on("click", reset)
}
});
callback(null);
});
In vectorized form, the colorization problem is
dt-math[block] {
display: block;
}
minimize\text{minimize}minimize
The **smoother**’s quadratic form is the **Graph Laplacian**
dt-math[block] {
display: block;
}
12∑i∈D(xTeieiTx−eiTx)\frac{1}{2}\sum\_{i\in D}\left(x^{T}e\_{i}e\_{i}^{T}x-e\_{i}^{T}x\right)21i∈D∑(xTeieiTx−eiTx)
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
12xTLGx\frac{1}{2}x^{T}L\_{G}x21xTLGx
And the colorizer is a small low rank correction with a linear term.
dt-math[block] {
display: block;
}
eie\_iei is the
dt-math[block] {
display: block;
}
ithi^{th}ith unit vector.
The Laplacian matrix,
dt-math[block] {
display: block;
}
LGL\_GLG
8, which dominates the behavior of the optimization problem, is a valuable bridge between linear algebra and graph theory. This is a rich field of study, but one fact is pertinent to our discussion here. The conditioning of
dt-math[block] {
display: block;
}
LGL\_GLG, here defined as the ratio of the second eigenvector to the last (the first eigenvalue is always 0, with eigenvector equal to the matrix of all 1′s), is directly connected to the connectivity of the graph.
Small world graphs, like expanders and dense graphs, have excellent conditioning
The conditioning of grids improves with its dimensionality.
And long, wiry graphs, like paths, condition poorly.
deleteQueue.push(renderLoading(d3.select("#laplacianConditioning")))
renderQueue.push(function(callback) {
var g1 = d3.select("#graph").append("g")
genExpander(g1)
var g2 = d3.select("#graph").append("g").attr("transform", "translate(300,0)")
genGrid(g2)
var g3 = d3.select("#graph").append("g").attr("transform", "translate(600,0)")
genPath(g3);
callback(null);
});
These observations carry through to the colorization problem, and the intuition behind it should be clear. Well connected graphs allow rapid diffusion of information through the edges, while graphs with poor connectivity do not. And this principle, taken to the extreme, furnishes a class of functions so hard to optimize they reveal the limits of first order optimization.
---
The Limits of Descent
-----------------------
Let’s take a step back. We have, with a clever trick, improved the convergence of gradient descent by a quadratic factor with the introduction of a single auxiliary sequence. But is this the best we can do? Could we improve convergence even more with two sequences? Could one perhaps choose the
dt-math[block] {
display: block;
}
α\alphaα’s and
dt-math[block] {
display: block;
}
β\betaβ’s intelligently and adaptively? It is tempting to ride this wave of optimism - to the cube root and beyond!
Unfortunately, while improvements to the momentum algorithm do exist, they all run into a certain, critical, almost inescapable lower bound.
### Adventures in Algorithmic Space
To understand the limits of what we can do, we must first formally define the algorithmic space in which we are searching. Here’s one possible definition. The observation we will make is that both gradient descent and momentum can be “unrolled”. Indeed, since
dt-math[block] {
display: block;
}
w1=w0 − α∇f(w0)w2=w1 − α∇f(w1)=w0 − α∇f(w0) − α∇f(w1) ⋮wk+1=w0 − α∇f(w0) − ⋯⋯ − α∇f(wk)
\begin{array}{lll}
w^{1} & \!= & \!w^{0} ~-~ \alpha\nabla f(w^{0})\\[0.35em]
w^{2} & \!= & \!w^{1} ~-~ \alpha\nabla f(w^{1})\\[0.35em]
& \!= & \!w^{0} ~-~ \alpha\nabla f(w^{0}) ~-~ \alpha\nabla f(w^{1})\\[0.35em]
& ~ \!\vdots \\
w^{k+1} & \!= & \!w^{0} ~-~ \alpha\nabla f(w^{0}) ~-~~~~ \cdots\cdots ~~~~-~ \alpha\nabla f(w^{k})
\end{array}
w1w2wk+1=== ⋮=w0 − α∇f(w0)w1 − α∇f(w1)w0 − α∇f(w0) − α∇f(w1)w0 − α∇f(w0) − ⋯⋯ − α∇f(wk)
we can write gradient descent as
dt-math[block] {
display: block;
}
wk+1 = w0 − α∑ik∇f(wi).
w^{k+1} ~~=~~ w^{0} ~-~ \alpha\sum\_i^k\nabla f(w^{i}).
wk+1 = w0 − αi∑k∇f(wi).
A similar trick can be done with momentum:
dt-math[block] {
display: block;
}
wk+1 = w0 + α∑ik(1−βk+1−i)1−β∇f(wi).
w^{k+1} ~~=~~ w^{0} ~+~ \alpha\sum\_i^k\frac{(1-\beta^{k+1-i})}{1-\beta}\nabla f(w^i).
wk+1 = w0 + αi∑k1−β(1−βk+1−i)∇f(wi).
In fact, all manner of first order algorithms, including the Conjugate Gradient algorithm, AdaMax, Averaged Gradient and more, can be written (though not quite so neatly) in this unrolled form. Therefore the class of algorithms for which
dt-math[block] {
display: block;
}
wk+1 = w0 + ∑ikγik∇f(wi) for some γik
w^{k+1} ~~=~~ w^{0} ~+~ \sum\_{i}^{k}\gamma\_{i}^{k}\nabla f(w^{i}) \qquad \text{ for some } \gamma\_{i}^{k}
wk+1 = w0 + i∑kγik∇f(wi) for some γik
contains momentum, gradient descent and a whole bunch of other algorithms you might dream up. This is what is assumed in Assumption 2.1.4 [5] of Nesterov. But let’s push this even further, and expand this class to allow different step-sizes for different directions.
dt-math[block] {
display: block;
}
wk+1 = w0 + ∑ikΓik∇f(wi) for some diagonal matrix Γik.
w^{k+1} ~~=~~ w^{0} ~+~ \sum\_{i}^{k}\Gamma\_{i}^{k}\nabla f(w^{i}) \quad \text{ for some diagonal matrix } \Gamma\_{i}^{k} .
wk+1 = w0 + i∑kΓik∇f(wi) for some diagonal matrix Γik.
This class of methods covers most of the popular algorithms for training neural networks, including ADAM and AdaGrad. We shall refer to this class of methods as “Linear First Order Methods”, and we will show a single function all these methods ultimately fail on.
### The Resisting Oracle
Earlier, when we talked about the colorizer problem, we observed that wiry graphs cause bad conditioning in our optimization problem. Taking this to its extreme, we can look at a graph consisting of a single path — a function so badly conditioned that Nesterov called a variant of it “the worst function in the world”. The function follows the same structure as the colorizer problem, and we shall call this the Convex Rosenbrock,
dt-math[block] {
display: block;
}
fn(w)f^n(w)fn(w)
dt-math[block] {
display: block;
}
===
with a colorizer of one node
dt-math[block] {
display: block;
}
12(w1−1)2\frac{1}{2}\left(w\_{1}-1\right)^{2}21(w1−1)2
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
12∑i=1n(wi−wi+1)2\frac{1}{2}\sum\_{i=1}^{n}(w\_{i}-w\_{i+1})^{2}21i=1∑n(wi−wi+1)2
strong couplings of adjacent nodes in the path,
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
2κ−1∥w∥2.\frac{2}{\kappa-1}\|w\|^{2}.κ−12∥w∥2.
and a small regularization term.
The optimal solution of this problem is
dt-math[block] {
display: block;
}
wi⋆=(κ−1κ+1)i
w\_{i}^{\star}=\left(\frac{\sqrt{\kappa}-1}{\sqrt{\kappa}+1}\right)^{i}
wi⋆=(√κ+1√κ−1)i
and the condition number of the problem
dt-math[block] {
display: block;
}
fnf^nfn approaches
dt-math[block] {
display: block;
}
κ\kappaκ as
dt-math[block] {
display: block;
}
nnn goes to infinity. Now observe the behavior of the momentum algorithm on this function, starting from
dt-math[block] {
display: block;
}
w0=0w^0 = 0w0=0.
Step-size α =
Momentum β =
Here we see the first 50 iterates of momentum on the Convex Rosenbrock for
dt-math[block] {
display: block;
}
n=25n=25n=25. The behavior here is similar to that of any Linear First Order Algorithm.
This triangle is a “dead zone” of our iterates. The iterates are always 0, no matter what the parameters.
The remaining expanding space is the “light cone” of our iterate’s influence. Momentum does very well here with the optimal parameters.
Error
Weights
deleteQueue.push(renderLoading(d3.select("#rosenViz")))
renderQueue.push(function(callback) {
var RQ = [[0.033430859446525574,0.06637421995401382,0.09834969788789749,0.1288910210132599,0.1575528085231781,0.18391713500022888,0.20759953558444977,0.22825466096401215,0.24558131396770477,0.25932684540748596,0.2692908048629761,0.2753278911113739,0.2773500978946686,0.2753278911113739,0.2692908048629761,0.25932684540748596,0.24558131396770477,0.22825466096401215,0.20759953558444977,0.18391713500022888,0.1575528085231781,0.1288910210132599,0.09834969788789749,0.06637421995401382,0.033430859446525574],[-0.06637421995401382,-0.1288910210132599,-0.18391713500022888,-0.22825466096401215,-0.25932684540748596,-0.2753278911113739,-0.2753278911113739,-0.25932684540748596,-0.22825466096401215,-0.18391713500022888,-0.1288910210132599,-0.06637421995401382,-1.917815576756455e-14,0.06637421995401382,0.1288910210132599,0.18391713500022888,0.22825466096401215,0.25932684540748596,0.2753278911113739,0.2753278911113739,0.25932684540748596,0.22825466096401215,0.18391713500022888,0.1288910210132599,0.06637421995401382],[0.09834969788789749,0.18391713500022888,0.24558131396770477,0.2753278911113739,0.2692908048629761,0.22825466096401215,0.1575528085231781,0.06637421995401382,-0.033430859446525574,-0.1288910210132599,-0.20759953558444977,-0.25932684540748596,-0.2773500978946686,-0.25932684540748596,-0.20759953558444977,-0.1288910210132599,-0.033430859446525574,0.06637421995401382,0.1575528085231781,0.22825466096401215,0.2692908048629761,0.2753278911113739,0.24558131396770477,0.18391713500022888,0.09834969788789749],[0.1288910210132599,0.22825466096401215,0.2753278911113739,0.25932684540748596,0.18391713500022888,0.06637421995401382,-0.06637421995401382,-0.18391713500022888,-0.25932684540748596,-0.2753278911113739,-0.22825466096401215,-0.1288910210132599,-1.2834394835694717e-14,0.1288910210132599,0.22825466096401215,0.2753278911113739,0.25932684540748596,0.18391713500022888,0.06637421995401382,-0.06637421995401382,-0.18391713500022888,-0.25932684540748596,-0.2753278911113739,-0.22825466096401215,-0.1288910210132599],[-0.1575528085231781,-0.25932684540748596,-0.2692908048629761,-0.18391713500022888,-0.033430859446525574,0.1288910210132599,0.24558131396770477,0.2753278911113739,0.20759953558444977,0.06637421995401382,-0.09834969788789749,-0.22825466096401215,-0.2773500978946686,-0.22825466096401215,-0.09834969788789749,0.06637421995401382,0.20759953558444977,0.2753278911113739,0.24558131396770477,0.1288910210132599,-0.033430859446525574,-0.18391713500022888,-0.2692908048629761,-0.25932684540748596,-0.1575528085231781],[-0.18391713500022888,-0.2753278911113739,-0.22825466096401215,-0.06637421995401382,0.1288910210132599,0.25932684540748596,0.25932684540748596,0.1288910210132599,-0.06637421995401382,-0.22825466096401215,-0.2753278911113739,-0.18391713500022888,-4.583645525716709e-15,0.18391713500022888,0.2753278911113739,0.22825466096401215,0.06637421995401382,-0.1288910210132599,-0.25932684540748596,-0.25932684540748596,-0.1288910210132599,0.06637421995401382,0.22825466096401215,0.2753278911113739,0.18391713500022888],[-0.20759953558444977,-0.2753278911113739,-0.1575528085231781,0.06637421995401382,0.24558131396770477,0.25932684540748596,0.09834969788789749,-0.1288910210132599,-0.2692908048629761,-0.22825466096401215,-0.033430859446525574,0.18391713500022888,0.2773500978946686,0.18391713500022888,-0.033430859446525574,-0.22825466096401215,-0.2692908048629761,-0.1288910210132599,0.09834969788789749,0.25932684540748596,0.24558131396770477,0.06637421995401382,-0.1575528085231781,-0.2753278911113739,-0.20759953558444977],[-0.22825466096401215,-0.25932684540748596,-0.06637421995401382,0.18391713500022888,0.2753278911113739,0.1288910210132599,-0.1288910210132599,-0.2753278911113739,-0.18391713500022888,0.06637421995401382,0.25932684540748596,0.22825466096401215,4.337912797388764e-15,-0.22825466096401215,-0.25932684540748596,-0.06637421995401382,0.18391713500022888,0.2753278911113739,0.1288910210132599,-0.1288910210132599,-0.2753278911113739,-0.18391713500022888,0.06637421995401382,0.25932684540748596,0.22825466096401215],[-0.24558131396770477,-0.22825466096401215,0.033430859446525574,0.25932684540748596,0.20759953558444977,-0.06637421995401382,-0.2692908048629761,-0.18391713500022888,0.09834969788789749,0.2753278911113739,0.1575528085231781,-0.1288910210132599,-0.2773500978946686,-0.1288910210132599,0.1575528085231781,0.2753278911113739,0.09834969788789749,-0.18391713500022888,-0.2692908048629761,-0.06637421995401382,0.20759953558444977,0.25932684540748596,0.033430859446525574,-0.22825466096401215,-0.24558131396770477],[-0.25932684540748596,-0.18391713500022888,0.1288910210132599,0.2753278911113739,0.06637421995401382,-0.22825466096401215,-0.22825466096401215,0.06637421995401382,0.2753278911113739,0.1288910210132599,-0.18391713500022888,-0.25932684540748596,-2.6265288907570752e-15,0.25932684540748596,0.18391713500022888,-0.1288910210132599,-0.2753278911113739,-0.06637421995401382,0.22825466096401215,0.22825466096401215,-0.06637421995401382,-0.2753278911113739,-0.1288910210132599,0.18391713500022888,0.25932684540748596],[0.2692908048629761,0.1288910210132599,-0.20759953558444977,-0.22825466096401215,0.09834969788789749,0.2753278911113739,0.033430859446525574,-0.25932684540748596,-0.1575528085231781,0.18391713500022888,0.24558131396770477,-0.06637421995401382,-0.2773500978946686,-0.06637421995401382,0.24558131396770477,0.18391713500022888,-0.1575528085231781,-0.25932684540748596,0.033430859446525574,0.2753278911113739,0.09834969788789749,-0.22825466096401215,-0.20759953558444977,0.1288910210132599,0.2692908048629761],[0.2753278911113739,0.06637421995401382,-0.25932684540748596,-0.1288910210132599,0.22825466096401215,0.18391713500022888,-0.18391713500022888,-0.22825466096401215,0.1288910210132599,0.25932684540748596,-0.06637421995401382,-0.2753278911113739,-2.224606886845463e-15,0.2753278911113739,0.06637421995401382,-0.25932684540748596,-0.1288910210132599,0.22825466096401215,0.18391713500022888,-0.18391713500022888,-0.22825466096401215,0.1288910210132599,0.25932684540748596,-0.06637421995401382,-0.2753278911113739],[0.2773500978946686,1.2625047254649028e-16,-0.2773500978946686,-6.312523627324514e-16,0.2773500978946686,8.83753307825432e-16,-0.2773500978946686,-8.83753307825432e-16,0.2773500978946686,1.5781309068311285e-15,-0.2773500978946686,-4.734392720493385e-16,0.2773500978946686,2.0200075607438445e-15,-0.2773500978946686,-1.7990691808479273e-15,0.2773500978946686,1.6728188141805554e-15,-0.2773500978946686,-1.4518804342846382e-15,0.2773500978946686,-3.4718879950284827e-16,-0.2773500978946686,1.2625047254649028e-15,0.2773500978946686],[-0.2753278911113739,0.06637421995401382,0.25932684540748596,-0.1288910210132599,-0.22825466096401215,0.18391713500022888,0.18391713500022888,-0.22825466096401215,-0.1288910210132599,0.25932684540748596,0.06637421995401382,-0.2753278911113739,-1.0026396759284933e-15,0.2753278911113739,-0.06637421995401382,-0.25932684540748596,0.1288910210132599,0.22825466096401215,-0.18391713500022888,-0.18391713500022888,0.22825466096401215,0.1288910210132599,-0.25932684540748596,-0.06637421995401382,0.2753278911113739],[0.2692908048629761,-0.1288910210132599,-0.20759953558444977,0.22825466096401215,0.09834969788789749,-0.2753278911113739,0.033430859446525574,0.25932684540748596,-0.1575528085231781,-0.18391713500022888,0.24558131396770477,0.06637421995401382,-0.2773500978946686,0.06637421995401382,0.24558131396770477,-0.18391713500022888,-0.1575528085231781,0.25932684540748596,0.033430859446525574,-0.2753278911113739,0.09834969788789749,0.22825466096401215,-0.20759953558444977,-0.1288910210132599,0.2692908048629761],[-0.25932684540748596,0.18391713500022888,0.1288910210132599,-0.2753278911113739,0.06637421995401382,0.22825466096401215,-0.22825466096401215,-0.06637421995401382,0.2753278911113739,-0.1288910210132599,-0.18391713500022888,0.25932684540748596,1.770693656524247e-16,-0.25932684540748596,0.18391713500022888,0.1288910210132599,-0.2753278911113739,0.06637421995401382,0.22825466096401215,-0.22825466096401215,-0.06637421995401382,0.2753278911113739,-0.1288910210132599,-0.18391713500022888,0.25932684540748596],[0.24558131396770477,-0.22825466096401215,-0.033430859446525574,0.25932684540748596,-0.20759953558444977,-0.06637421995401382,0.2692908048629761,-0.18391713500022888,-0.09834969788789749,0.2753278911113739,-0.1575528085231781,-0.1288910210132599,0.2773500978946686,-0.1288910210132599,-0.1575528085231781,0.2753278911113739,-0.09834969788789749,-0.18391713500022888,0.2692908048629761,-0.06637421995401382,-0.20759953558444977,0.25932684540748596,-0.033430859446525574,-0.22825466096401215,0.24558131396770477],[0.22825466096401215,-0.25932684540748596,0.06637421995401382,0.18391713500022888,-0.2753278911113739,0.1288910210132599,0.1288910210132599,-0.2753278911113739,0.18391713500022888,0.06637421995401382,-0.25932684540748596,0.22825466096401215,9.870699398085384e-16,-0.22825466096401215,0.25932684540748596,-0.06637421995401382,-0.18391713500022888,0.2753278911113739,-0.1288910210132599,-0.1288910210132599,0.2753278911113739,-0.18391713500022888,-0.06637421995401382,0.25932684540748596,-0.22825466096401215],[-0.20759953558444977,0.2753278911113739,-0.1575528085231781,-0.06637421995401382,0.24558131396770477,-0.25932684540748596,0.09834969788789749,0.1288910210132599,-0.2692908048629761,0.22825466096401215,-0.033430859446525574,-0.18391713500022888,0.2773500978946686,-0.18391713500022888,-0.033430859446525574,0.22825466096401215,-0.2692908048629761,0.1288910210132599,0.09834969788789749,-0.25932684540748596,0.24558131396770477,-0.06637421995401382,-0.1575528085231781,0.2753278911113739,-0.20759953558444977],[-0.18391713500022888,0.2753278911113739,-0.22825466096401215,0.06637421995401382,0.1288910210132599,-0.25932684540748596,0.25932684540748596,-0.1288910210132599,-0.06637421995401382,0.22825466096401215,-0.2753278911113739,0.18391713500022888,8.371955066048889e-16,-0.18391713500022888,0.2753278911113739,-0.22825466096401215,0.06637421995401382,0.1288910210132599,-0.25932684540748596,0.25932684540748596,-0.1288910210132599,-0.06637421995401382,0.22825466096401215,-0.2753278911113739,0.18391713500022888],[-0.1575528085231781,0.25932684540748596,-0.2692908048629761,0.18391713500022888,-0.033430859446525574,-0.1288910210132599,0.24558131396770477,-0.2753278911113739,0.20759953558444977,-0.06637421995401382,-0.09834969788789749,0.22825466096401215,-0.2773500978946686,0.22825466096401215,-0.09834969788789749,-0.06637421995401382,0.20759953558444977,-0.2753278911113739,0.24558131396770477,-0.1288910210132599,-0.033430859446525574,0.18391713500022888,-0.2692908048629761,0.25932684540748596,-0.1575528085231781],[-0.1288910210132599,0.22825466096401215,-0.2753278911113739,0.25932684540748596,-0.18391713500022888,0.06637421995401382,0.06637421995401382,-0.18391713500022888,0.25932684540748596,-0.2753278911113739,0.22825466096401215,-0.1288910210132599,-3.0802549003271684e-16,0.1288910210132599,-0.22825466096401215,0.2753278911113739,-0.25932684540748596,0.18391713500022888,-0.06637421995401382,-0.06637421995401382,0.18391713500022888,-0.25932684540748596,0.2753278911113739,-0.22825466096401215,0.1288910210132599],[-0.09834969788789749,0.18391713500022888,-0.24558131396770477,0.2753278911113739,-0.2692908048629761,0.22825466096401215,-0.1575528085231781,0.06637421995401382,0.033430859446525574,-0.1288910210132599,0.20759953558444977,-0.25932684540748596,0.2773500978946686,-0.25932684540748596,0.20759953558444977,-0.1288910210132599,0.033430859446525574,0.06637421995401382,-0.1575528085231781,0.22825466096401215,-0.2692908048629761,0.2753278911113739,-0.24558131396770477,0.18391713500022888,-0.09834969788789749],[-0.06637421995401382,0.1288910210132599,-0.18391713500022888,0.22825466096401215,-0.25932684540748596,0.2753278911113739,-0.2753278911113739,0.25932684540748596,-0.22825466096401215,0.18391713500022888,-0.1288910210132599,0.06637421995401382,6.798085926082532e-17,-0.06637421995401382,0.1288910210132599,-0.18391713500022888,0.22825466096401215,-0.25932684540748596,0.2753278911113739,-0.2753278911113739,0.25932684540748596,-0.22825466096401215,0.18391713500022888,-0.1288910210132599,0.06637421995401382],[0.033430859446525574,-0.06637421995401382,0.09834969788789749,-0.1288910210132599,0.1575528085231781,-0.18391713500022888,0.20759953558444977,-0.22825466096401215,0.24558131396770477,-0.25932684540748596,0.2692908048629761,-0.2753278911113739,0.2773500978946686,-0.2753278911113739,0.2692908048629761,-0.25932684540748596,0.24558131396770477,-0.22825466096401215,0.20759953558444977,-0.18391713500022888,0.1575528085231781,-0.1288910210132599,0.09834969788789749,-0.06637421995401382,0.033430859446525574]]
RLambda = [4.6419172286987305,15.514562606811523,33.45938491821289,58.21471405029297,89.4195556640625,126.61888122558594,169.27023315429688,216.7516632080078,268.37078857421875,323.3748474121094,380.9618225097656,440.29193115234375,500.5,560.7080688476562,620.0381469726562,677.6251220703125,732.6292114257812,784.2483520507812,831.7297973632812,874.381103515625,911.5804443359375,942.7852783203125,967.5405883789062,985.4854125976562,996.3580932617188]
var alpha = 0.003
var beta = 0.8
var b = zeros(25); b[0] = 249.75
var iter = geniterMomentum(RQ, RLambda, b, alpha, beta).iter
var res = function(i) { return iter(i)[0] }
var sampleSVG = d3.select("#iterates")
.style("display", "block")
.append("svg")
.attr("width", 770)
.attr("height", 700)
var rosen = d3.scaleLinear().domain([0,0.2,0.5,0.6,0.8]).range(colorbrewer.YlGnBu[5]);
var jet = d3.scaleLinear().domain([-0,0.1,0.2,0.5,1.0,8]).range(colorbrewer.YlGnBu[5]);
var contrast = d3.scaleLinear().domain([-12,0,12]).range(colorbrewer.YlGnBu[3]);
var xstar = iter(10000000)
var numIters = 52
var pathstr = "M 8,0"
for (var j = 0; j < 27; j++) {
if (j != 26 && j > 0) {
pathstr = pathstr + "L " + j\*8 + "," + (j-1)\*8 + "L " + j\*8 + "," + j\*8
}
if (j == 0) {
//pathstr = pathstr + "L " + j\*8 + "," + j\*8
}
if (j == 26) {
pathstr = pathstr + "L " + j\*8 + "," + (j-1)\*8
}
}
pathstr = pathstr + "L "+ 26\*8 + ",0 L 8,0 "
var Disps3 = []
var errorPlot = sampleSVG.append("g").attr("transform", "translate(" + 440 + ",0)")
for (var j = 0; j < numIters; j++) {
var disp = errorPlot.append("g")
var denter = disp.selectAll("rect")
.data(iter(j)[1])
.enter()
denter.append("rect")
.style("fill", function(d,i) { return rosen(d) })
.attr("height", 7.7)
.attr("width", 7.7)
.attr("x", function(d, i){return i\*8+ 10})
.attr("y", function(d, i){return j\*8 })
Disps3.push(disp)
}
errorPlot.append("g").append("path").attr("d", pathstr).style("stroke","black").style("fill","none").style("stroke-width","1px").attr("transform", "translate(2,0.5)")
var Disps4 = []
var errorPlot = sampleSVG.append("g").attr("transform", "translate(" + 220 + ",0)")
for (var j = 0; j < numIters; j++) {
var disp = errorPlot.append("g")
var denter = disp.selectAll("rect")
.data(iter(j)[1])
.enter()
denter.append("rect")
.style("fill", function(d,i) { return jet(d) })
.attr("height", 7.7)
.attr("width", 7.7)
.attr("x", function(d, i){return i\*8+ 10})
.attr("y", function(d, i){return j\*8 })
if ((j % 10 == 0) || j == 0) {
disp.append("text")
.attr("class", "figtext")
.attr("text-anchor", "end")
.attr("x", 0)
.attr("y", function(d, i){return (j\*8 + 10) })
.html( (j == 0) ? "Iteration 0" : "" + j)
}
Disps4.push(disp)
}
errorPlot.append("g").append("path").attr("d", pathstr).style("stroke","black").style("fill","none").style("stroke-width","1px").attr("transform", "translate(2,0.5)")
function update(alpha, beta) {
var iter = geniterMomentum(RQ, RLambda, b, Math.max(alpha, 0.00001), Math.min(Math.max(beta, 0.00001), 0.999)).iter
for (var j = 0; j < numIters; j++) {
var iterj = iter(j)
Disps3[j].selectAll("rect").data(iterj[1]).merge(Disps3[j]).style("fill", function(d,i) { return rosen(Math.abs(d - xstar[1][i]) ) })
Disps4[j].selectAll("rect").data(iterj[1]).merge(Disps4[j]).style("fill", function(d,i) { return jet(d) })
}
}
var reset = slider2D(d3.select("#sliderz"), function(x,y) { update(x/RLambda[RLambda.length - 1],y) }, 4.6, 996.35)
update(0.0035749243028120182, 0.8095238095238095)
colorMap( d3.select("#rosen\_colorbar1"),
194,
rosen,
d3.scaleLinear().domain([0,1]).range([0, 194]) )
colorMap( d3.select("#rosen\_colorbar2"),
194,
jet,
d3.scaleLinear().domain([0,1]).range([0, 194]) );
// Swoopy Annotator
var annotations = [
{
"x": 0,
"y": 0,
"path": "M 817,95 A 23.869 23.869 0 0 0 792,72",
"text": "Optimal parameters",
"textOffset": [
767,
109
]
}
]
var sel = drawAnnotations(d3.select("#rosenViz"), annotations)
sel.selectAll("text").style("cursor", "pointer").style("pointer-events","all").on("click", reset)
callback(null);
});
The observations made in the above diagram are true for any Linear First Order algorithm. Let us prove this. First observe that each component of the gradient depends only on the values directly before and after it:
dt-math[block] {
display: block;
}
∇f(x)i=2wi−wi−1−wi+1+4κ−1wi,i≠1.
\nabla f(x)\_{i}=2w\_{i}-w\_{i-1}-w\_{i+1} +\frac{4}{\kappa-1} w\_{i}, \qquad i \neq 1.
∇f(x)i=2wi−wi−1−wi+1+κ−14wi,i≠1.
Therefore the fact we start at 0 guarantees that that component must remain stoically there till an element either before or after it turns nonzero. And therefore, by induction, for any linear first order algorithm,
dt-math[block] {
display: block;
}
w0=[ 0,0,0,…0,0,…0 ]w1=[ w11,0,0,…0,0,…0 ]w2=[ w12,w22,0,…0,0,…0 ] ⋮wk=[ w1k,w2k,w3k,…wkk,0,…0 ].
\begin{array}{lllllllll}
w^{0} & = & [~~0, & 0, & 0, & \ldots & 0, & 0, & \ldots & 0~]\\[0.35em]
w^{1} & = & [~w\_{1}^{1}, & 0, & 0, & \ldots & 0, & 0, & \ldots & 0~]\\[0.35em]
w^{2} & = & [~w\_{1}^{2}, & w\_{2}^{2}, & 0, & \ldots & 0, & 0, & \ldots & 0~]\\[0.35em]
& ~ \vdots \\
w^{k} & = & [~w\_{1}^{k}, & w\_{2}^{k}, & w\_{3}^{k}, & \ldots & w\_{k}^{k}, & 0, & \ldots & 0~].\\
\end{array}
w0w1w2wk=== ⋮=[ 0,[ w11,[ w12,[ w1k,0,0,w22,w2k,0,0,0,w3k,…………0,0,0,wkk,0,0,0,0,…………0 ]0 ]0 ]0 ].
Think of this restriction as a “speed of light” of information transfer. Error signals will take at least
dt-math[block] {
display: block;
}
kkk steps to move from
dt-math[block] {
display: block;
}
w0w\_0w0 to
dt-math[block] {
display: block;
}
wkw\_kwk. We can therefore sum up the errors which cannot have changed yet9:
dt-math[block] {
display: block;
}
∥wk−w⋆∥∞≥maxi≥k+1{∣wi⋆∣}=(κ−1κ+1)k+1=(κ−1κ+1)k∥w0−w⋆∥∞.
\begin{aligned}
\|w^{k}-w^{\star}\|\_{\infty}&\geq\max\_{i\geq k+1}\{|w\_{i}^{\star}|\}\\[0.9em]&=\left(\frac{\sqrt{\kappa}-1}{\sqrt{\kappa}+1}\right)^{k+1}\\[0.9em]&=\left(\frac{\sqrt{\kappa}-1}{\sqrt{\kappa}+1}\right)^{k}\|w^{0}-w^{\star}\|\_{\infty}.
\end{aligned}
∥wk−w⋆∥∞≥i≥k+1max{∣wi⋆∣}=(√κ+1√κ−1)k+1=(√κ+1√κ−1)k∥w0−w⋆∥∞.
As
dt-math[block] {
display: block;
}
nnn gets large, the condition number of
dt-math[block] {
display: block;
}
fnf^nfn approaches
dt-math[block] {
display: block;
}
κ\kappaκ. And the gap therefore closes; the convergence rate that momentum promises matches the best any linear first order algorithm can do. And we arrive at the disappointing conclusion that on this problem, we cannot do better.
Like many such lower bounds, this result must not be taken literally, but spiritually. It, perhaps, gives a sense of closure and finality to our investigation. But this is not the final word on first order optimization. This lower bound does not preclude the possibility, for example, of reformulating the problem to change the condition number itself! There is still much room for speedups, if you understand the right places to look.
Momentum with Stochastic Gradients
----------------------------------
There is a final point worth addressing. All the discussion above assumes access to the true gradient — a luxury seldom afforded in modern machine learning. Computing the exact gradient requires a full pass over all the data, the cost of which can be prohibitively expensive. Instead, randomized approximations of the gradient, like minibatch sampling, are often used as a plug-in replacement of
dt-math[block] {
display: block;
}
∇f(w)\nabla f(w)∇f(w). We can write the approximation in two parts,
dt-math[block] {
display: block;
}
∇f(w)\nabla f(w)∇f(w)
the true gradient
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
error(w).\text{error}(w).error(w).
and an approximation error.
If the estimator is unbiased e.g.
dt-math[block] {
display: block;
}
E[error(w)]=0\mathbf{E}[\text{error}(w)] = 0E[error(w)]=0
renderMath(document.getElementById("truegradientpluserror"))
It is helpful to think of our approximate gradient as the injection of a special kind of noise into our iteration. And using the machinery developed in the previous sections, we can deal with this extra term directly. On a quadratic, the error term cleaves cleanly into a separate term, where 10
dt-math[block] {
display: block;
}
(yikxik) \left(\begin{array}{c}
y\_{i}^{k}\\
x\_{i}^{k}
\end{array}\right)(yikxik)
the noisy iterates are a sum of
dt-math[block] {
display: block;
}
===
dt-math[block] {
display: block;
}
Rk(yi0xi0)R^{k}\left(\begin{array}{c}
y\_{i}^{0}\\
x\_{i}^{0}
\end{array}\right)Rk(yi0xi0)
the noiseless, deterministic iterates and
dt-math[block] {
display: block;
}
+++
dt-math[block] {
display: block;
}
ϵik∑j=1kRk−j(1−α)\epsilon^k\_i \sum\_{j=1}^{k}R^{k-j}\left(\begin{array}{c}
1\\
-\alpha
\end{array}\right)ϵikj=1∑kRk−j(1−α)
a decaying sum of the errors, where
dt-math[block] {
display: block;
}
ϵk=Q⋅error(wk)\epsilon^k = Q \cdot \text{error}(w^k)ϵk=Q⋅error(wk).
renderMath(document.getElementById("iteratespluserror"))
The error term,
dt-math[block] {
display: block;
}
ϵk\epsilon^kϵk, with its dependence on the
dt-math[block] {
display: block;
}
wkw^kwk, is a fairly hairy object. Following [10], we model this as independent 0-mean Gaussian noise. In this simplified model, the objective also breaks into two separable components, a sum of a deterministic error and a stochastic error
11, visualized here.
We decompose the expected value of the objective value
dt-math[block] {
display: block;
}
Ef(w)−f(w⋆)\mathbf{E} f(w) - f(w^\star)Ef(w)−f(w⋆) into a deterministic part and a stochastic part .
dt-math[block] {
display: block;
}
Ef(w)−f(w⋆)\mathbf{E} f(w) - f(w^\star) Ef(w)−f(w⋆)
The small black dots are a single run of stochastic gradient
Step-size α =
Momentum β =
As [1] observes, the optimization has two phases. In the initial transient phase the magnitude of the noise is smaller than the magnitude of the gradient, and Momentum still makes good progress. In the second, stochastic phase, the noise overwhelms the gradient, and momentum is less effective.
deleteQueue.push(renderLoading(d3.select("#stochastic")))
renderQueue.push(function(callback) {
var graphDiv = d3.select("#stochasticgd")
.style("width", 920 + "px")
.style("height", 300 + "px")
.style("top", "170px")
.style("position", "relative")
.style("margin-left", "auto")
.style("margin-right", "auto")
.attr("width", 920)
.attr("height", 500)
var svg = graphDiv.append("svg").attr("width", 940).attr("height", 500)
var update = renderStochasticMilestones(svg, function() {})
var slidera = slider2D(d3.select("#sliderStep2DD"), function(x,y) { update(x,y) }, 1, 100)
slidera(0.5,0.5)
});
Note that there are a set of unfortunate tradeoffs which seem to pit the two components of error against each other. Lowering the step-size, for example, decreases the stochastic error, but also slows down the rate of convergence. And increasing momentum, contrary to popular belief, causes the errors to compound. Despite these undesirable properties, stochastic gradient descent with momentum has still been shown to have competitive performance on neural networks. As [1] has observed, the transient phase seems to matter more than the fine-tuning phase in machine learning. And in fact, it has been recently suggested [12] that this noise is a good thing — it acts as a implicit regularizer, which, like early stopping, prevents overfitting in the fine-tuning phase of optimization.
---
Onwards and Downwards
---------------------
The study of acceleration is seeing a small revival within the optimization community. If the ideas in this article excite you, you may wish to read [13], which fully explores the idea of momentum as the discretization of a certain differential equation. But other, less physical, interpretations exist. There is an algebraic interpretation of momentum in terms of approximating polynomials [3, 14]. Geometric interpretations are emerging [15, 16], connecting momentum to older methods, like the Ellipsoid method. And finally, there are interpretations relating momentum to duality [17], perhaps providing a clue as how to accelerate second order methods and Quasi Newton (for a first step, see [18]). But like the proverbial blind men feeling an elephant, momentum seems like something bigger than the sum of its parts. One day, hopefully soon, the many perspectives will converge into a satisfying whole.
|
720332b5-3025-4cc2-af91-949f0d0a3642
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Learning with catastrophes
A *catastrophe* is an event so bad that we are not willing to let it happen even a single time. For example, we would be unhappy if our self-driving car *ever* accelerates to 65 mph in a residential area and hits a pedestrian.
Catastrophes present a theoretical challenge for traditional machine learning — typically there is no way to reliably avoid catastrophic behavior without strong statistical assumptions.
In this post, I’ll lay out a very general model for catastrophes in which they are avoidable under much weaker statistical assumptions*.* I think this framework applies to the most important kinds of catastrophe, and will be especially relevant to AI alignment.
Designing practical algorithms that work in this model is an open problem. In a [subsequent post](https://ai-alignment.com/techniques-for-optimizing-worst-case-performance-39eafec74b99) I describe what I currently see as the most promising angles of attack.
Modeling catastrophes
---------------------
We consider an agent A interacting with the environment over a sequence of episodes. Each episode produces a transcript τ, consisting of the agent’s observations and actions, along with a reward *r* ∈ [0, 1]. Our primary goal is to quickly learn an agent which receives high reward. (Supervised learning is the special case where each transcripts consist of a single input and a label for that input.)
While training, we assume that we have an oracle which can determine whether a transcript τ is “catastrophic.” For example, we might show a transcript to a QA analyst and ask them if it looks catastrophic. This oracle can be applied to arbitrary sequences of observations and actions, including those that don’t arise from an actual episode*.* So training can begin before the very first interaction with nature, using only calls to the oracle.
Intuitively, a transcript should only be marked catastrophic if it satisfies two conditions:
1. The agent made a catastrophically bad decision.
2. The agent’s observations are plausible: we have a right to expect the agent to be able to handle those observations.
While actually interacting with the environment, the agent cannot query the oracle — there is no time to wait for a QA engineer to review a proposed action to check if it would be catastrophic.
Moreover, if interaction with nature ever produces a catastrophic transcript, we immediately fail. The performance of an algorithm is characterized by two parameters: the probability of catastrophic failure, and the total reward assuming no catastrophic failure.
We assume that there are some policies such that no matter what nature does, the resulting transcript is *never* catastrophic.
Traditionally in RL the goal is to get as much reward as the best policy from some class C. We’ slightly weaken that goal, and instead aim to do as well as the best policy from C that never makes a catastrophic decision.
Batch learning
--------------
I’ve described an online version of learning with catastrophes. We can also consider the batch version, where the learner is first given a large number of “training” episodes.
In the batch version, there is no penalty for catastrophes at training time, and we don’t care about training error. The two performance parameters are test-time performance and test-time catastrophe probability.
The oracle
----------
This definition depends on an oracle who determines which transcripts are catastrophic.
For weak AI systems, the oracle may be a human. But a powerful AI system might take actions which are catastrophic but which look inoffensive to a human judge, so this approach doesn’t cut it.
In general, the judge should be a human+AI team which is *more* competent than the system being trained, armed with an adequate solution to the [informed oversight problem](https://medium.com/ai-control/the-informed-oversight-problem-1b51b4f66b35).
Approach
========
Learning with catastrophes is straightforward *given an unlimited number of queries to the catastrophe oracle*. Given any online learning algorithm A, we can “harden” it by running the following process before the beginning of each episode (a similar process can be applied to a batch learner):
1. Search over all possible environments, running A on each one to obtain a transcript.
2. If we find a catastrophic transcript τ, then add τ to A’s training data with a reward of −1, and go back to step 1.
It’s easy to prove that this process converges, if A is competent: the number of times we invoke step 2 is at most the time required to learn an optimal catastrophe-free policy (plus the number of episodes).
The big problem with this algorithm is the exponential search in step 1.
Adversarial training
--------------------
The most obvious approach to *tractable* learning with catastrophes is to replace step 1 with a tractable algorithm that approximates the search. This process is an example of [adversarial training](https://arxiv.org/abs/1412.6572).
We can formalize this as a simple game between the agent A and an adversary B. The two agents alternate taking moves, with A playing the role of the agent and B playing the role of the environment. B wins if the resulting transcript is catastrophic, A wins if it is not catastrophic.
Before each episode, we play this game N times, where N > 0 is a hyperparameter. If B is able to win *any* of the games, then we add the resulting transcript to A’s training data and start again. Once B is not able to win any games, then we move on to a “real” episode. We hope that B is good enough at the game that if it can’t produce a catastrophic transcript, then the real environment can’t produce a catastrophic transcript either.
More precisely, before each episode we perform the following process:
1. Set *i* = 0.
2. A and B alternate taking moves, producing a transcript τ.
3. If τ is catastrophic, we add τ to A’s training data with a reward of −1, and add τ to B’s training data with a reward of +1. Then we go back to step 1.
4. If τ is not catastrophic, we add τ to B’s training data with a reward of −1.
5. If *i* < N, we increment *i* and go back to step 2.
I discuss this idea in more detail in my [post on red teams](https://medium.com/@paulfchristiano/b5b6de33dc76). There are serious problems with this approach and I don’t think it can work on its own, but fortunately it seems combinable with [other techniques](https://arxiv.org/abs/1412.6572).
Conclusion
==========
Learning with catastrophes is a very general model of catastrophic failures which avoids being obviously impossible. I think that designing competent algorithms for learning with catastrophes may be an important ingredient in a successful approach to AI alignment.
---
*This was originally posted [here](https://ai-alignment.com/learning-with-catastrophes-59387b55cc30) on 28th May, 2016.*
*Tomorrow's AI Alignment sequences post will be in the sequence on Value Learning by Rohin Shah.*
*The next post in this sequence will be 'Thoughts on Reward Engineering' by Paul Christiano, on Thursday.*
|
1eedcb8a-0890-4c3a-93dd-bdb460ce9d15
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Book Review: Going Infinite
Previously: Sadly, FTX
I doubted whether it would be a good use of time to read Michael Lewis’s new book Going Infinite about Sam Bankman-Fried (hereafter SBF or Sam). What would I learn that I did not already know? Was Michael Lewis so far in the tank of SBF that the book was filled with nonsense and not to be trusted?
I set up a prediction market, which somehow attracted over a hundred traders. Opinions were mixed. That, combined with Matt Levine clearly reporting having fun, felt good enough to give the book a try.
I need not have worried.
Going Infinite is awesome. I would have been happy with my decision on the basis of any one of the following:
The details I learned or clarified about the psychology of SBF in particular.
The details I learned or clarified about the psychology of Effective Altruism.
The details about all the crimes and other things that happened.
The sheer joy of reading, because man can Michael Lewis write.
I also get to write this post, an attempt to quickly share what I’ve extracted, including some of the sheer joy. We need more joy, now more than ever.
There are three problems with Going Infinite.
Michael Lewis fails to put two and two together regarding: Who is this guy?
Michael Lewis fails to figure out that obviously this man was constantly lying and also did all of the crimes.
Michael Lewis omits or fails to notice key facts and considerations.
I do think all of these are genuine mistakes. He (still) is in the tank because character is fate and we are who we choose to be. Michael Lewis roots for the wicked smart, impossibly hard working, deeply obsessed protagonist taking on the system saying that everyone else is an idiot, that has unique insight into and will change the world. It all makes too much sense, far too much for him to check.
What Michael Lewis is not is for sale. Or at least, not for cheap. I do not think anyone paid him. Like all worthy protagonists, including those he looks to cover, Michael Lewis has a cod
|
b0ec7e25-b334-4394-bb9f-8f2e38490ff7
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Austin, TX - Petrov Day Celebration
Discussion article for the meetup : Austin, TX - Petrov Day Celebration
WHEN: 26 September 2015 04:00:00PM (-0500)
WHERE: 4212 Hookbilled Kite Drive
Food starts at 6. Send me a PM or email (my username at gmail) if you want to be kept up to date on details as the event approaches or to join a carpool.
Discussion article for the meetup : Austin, TX - Petrov Day Celebration
|
3a8422b7-6b2f-4f79-b437-bf775ac70eaf
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
[Links] Brain mapping/emulation news
[Obama Seeking to Boost Study of Human Brain](http://www.nytimes.com/2013/02/18/science/project-seeks-to-build-map-of-human-brain.html?pagewanted=all&_r=1&) - Like the Human Genome Project, but for brain mapping (Feb 17)
Human brain and graphene projects chosen for one billion euro grants: [official press release](http://cordis.europa.eu/fp7/ict/programme/fet/flagship/doc/press28jan13-01_en.pdf) (Jan 28)
[Gary Marcus reacts](http://www.newyorker.com/online/blogs/newsdesk/2013/02/obamas-brain.html#entry-more)
Edit: If anyone is going to email the people behind Obama's human brain project and offer suggestions, it's probably best to do so ASAP before they make the details of their project public and risk losing face by changing them.
|
72e76e36-9350-4675-aaa6-4220362ed8ba
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Book Review: The Reputation Society. Part I
The Reputation Society (MIT Press, 2012), edited by Hassan Masum and Mark Tovey, is an anthology on the possibilities of using online rating and reputation systems to systematically disseminate information about virtually everything - people, goods and services, ideas, etc., etc. Even though the use of online rating systems is an overarching theme, the book is, however, quite heterogeneous (like many anthologies). I have therefore chosen to structure the material in a somewhat different way. This post consists of a short introduction to the book, while in the next, far longer post, I list a number of concepts and distinctions commented on by the authors (either explicitly or implicitly) and briefly summarize their take on them.
My hope is that this Wiki-style approach maximizes the amount of information per line of text. Also, though these concepts and distinctions are arguably the most useful stuff in the book, they are unfortunately not gathered in any one place in the book. Hence I think that my list should be of use for those that go on to read the book, or parts of it. I also hope that this list of entries could be a start to a series of Less Wrong Wiki entries on reputation systems. Moreover, it could be a good point of departure for general discussions on rating and reputation systems. I would be happy to receive feedback on this choice of presentation form (as well as on the content, of course).
A chapter-by-chapter review (more of a guide to what chapters to read, really) can be found on my blog. (This review is already too long which is why I put the chapter-by-chapter overview there rather than here at Less Wrong.) Monique Sadarangani has also written a review (which focuses on various legal aspects of online rating systems). Another associated text you might consider reading is Masum's and Yi-Cheng Zhang's "Manifesto for the Reputation Society" (2004).
Introduction
People have of course always relied on others' recommendations on a massive s
|
27ab84fd-6912-48b1-a2fc-a836014b87c1
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Convince me that humanity is as doomed by AGI as Yudkowsky et al., seems to believe
I’ve been very heavily involved in the (online) rationalist community for a few months now, and like many others, I have found myself quite freaked out by the apparent despair/lack of hope that seems to be sweeping the community. When people who are smarter than you start getting scared, it seems wise to be concerned as well, even if you don’t fully understand the danger. Nonetheless, it’s important not to get swept up in the crowd. I’ve been trying to get a grasp on *why* so many seem so hopeless, and these are the assumptions I believe they are making (trivial assumptions included, for completeness; there may be some overlap in this list):
1. AGI is possible to create.
2. AGI will be created within the next century or so, possibly even within the next few years.
3. If AGI is created by people who are not sufficiently educated (aka aware of a solution to the Alignment problem) and cautious, then it will almost certainly be unaligned.
4. Unaligned AGI will try to do something horrible to humans (not out of maliciousness, necessarily, we could just be collateral damage), and will not display sufficiently convergent behavior to have anything resembling our values.
5. We will not be able to effectively stop an unaligned AGI once it is created (due to the Corrigibility problem).
6. We have not yet solved the Alignment problem (of which the Corrigibility problem is merely a subset), and there does not appear to be any likely avenues to success (or at least we should not expect success within the next few decades).
7. Even if we solved the Alignment problem, if a non-aligned AGI arrives on the scene before we can implement ours, we are still doomed (due to first-mover advantage).
8. Our arguments for all of the above are not convincing or compelling enough for most AI researchers to take the threat seriously.
9. As such, unless some drastic action is taken soon, unaligned AGI will be created shortly, and that will be the end of the world as we know it.
First of all, is my list of seemingly necessary assumptions correct?
If so, it seems to me that most of these are far from proven statements of fact, and in fact are ~~all~~ heavily debated. Assumption 8 in particular seems to highlight this, as if a strong enough case could be made for each of the previous assumptions, it would be fairly easy to convince most intelligent researchers, which we don’t seem to observe.
A historical example which bears some similarities to the current situation may be Godel’s resolution to Hilbert's program. He was able to show unarguably that no consistent finite system of axioms is capable of proving all truths, at which point the mathematical community was able to advance beyond the limitations of early formalism. As far as I am aware, no similarly strong argument exists for even one of the assumptions listed above.
Given all of this, and the fact that there are so many uncertainties here, I don’t understand why so many researchers (most prominently Eliezer Yudkowsky, but there are countless more) seem so certain that we are doomed. I find it hard to believe that all alignment ideas presented so far show no promise, considering I’ve yet to see a slam-dunk argument presented for why even a single modern alignment proposals *can’t* work. (Yes, I’ve seen proofs against straw-man proposals, but not really any undertaken by a current expert in the field). This may very well be due to my own ignorance/ relative newness, however, and if so, please correct me!
I’d like to hear the steelmanned argument for why alignment is hopeless, and Yudkowsky’s announcement that “I’ve tried and couldn’t solve it” without more details doesn’t really impress me. My suspicion is I’m simply missing out on some crucial context, so consider this thread a chance to share your best arguments for AGI-related pessimism. (Later in the week I’ll post a thread from the opposite direction, in order to balance things out).
EDIT: Read the comments section if you have the time; there's some really good discussion there, and I was successfully convinced of a few specifics that I'm not sure how to incorporate into the original text. 🙃
|
8848eaf9-f63c-4843-a060-889f7a4d859f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Ceiling Air Purifier
Imagine a high-capacity air filter that is extremely quiet and doesn't get in the way. I think I see how to build one; here's a prototype:
By putting a fan on the ceiling you can have very long blades. This is important for keeping noise down: the longer your blades are the more air you move at a given rotational velocity, which is a major determinant of noise. Testing my prototype, it has a CADR of ~180 CFM and is only 33dB. By contrast, the Wirecutter's top-recommended air purifier (Coway AP-1512HH) has a CADR of 233 CFM (31% higher) at 54 dB (21dB louder) or 110 CFM (38% lower) at 36 dB (3dB louder). With some tweaks it should be able to match the commercial purifier's performance, without being louder.
Volume is very important here: people often select purifiers based on their maximum flow, but then run them on a lower setting or even turn them off because they are too loud.
Note that while my purifier is an octagon of 12x20 filters around a 52" fan, a nonagon would have been better. Not only should that get you 12% more filtration, but you don't have to fill gaps between the filters.
Jeff for scale
One downside of using this much tape, especially some of it with the sticky side bare, is that you get an adhesive smell. The smell fell below where I could detect after about a day, but Julia could still smell it for about five days.
To determine the CADR of the prototype I followed the approach I described in Testing Air Purifiers, where I created smoke by burning matches and then tracked how quickly the purifier could reduce pm2.5 levels:
To determine volume levels, I used a Sennheiser 835s dynamic microphone with a foam windscreen, connected to an AudioBox 1818VSL to record samples of each purifier option and silence. Here are the samples:
(Silence)
(Ceiling Purifier)
(AP-1512HH Medium)
(AP-1512HH High)
To compute the loudness of each sample I ran:
ffmpeg -i sample.wav -af\
loudnorm=I=-16:dual_mono=true:TP=-1.5:LRA=11:print_format=sum
|
4b0cda7d-f9db-447d-aee0-5da0f53affef
|
LDJnr/LessWrong-Amplify-Instruct
|
LessWrong
|
"[Click here to see a list of all interviews]
I am emailing experts in order to raise and estimate the academic awareness and perception of risks from AI.
Below you will find some thoughts on the topic by Shane Legg, a computer scientist and AI researcher who has been working on theoretical models of super intelligent machines (AIXI) with Prof. Marcus Hutter. His PhD thesis Machine Super Intelligence has been completed in 2008. He was awarded the $10,000 Canadian Singularity Institute for Artificial Intelligence Prize.
Publications by Shane Legg: Solomonoff Induction thesis
Universal Intelligence: A Definition of Machine Intelligence paper
Algorithmic Probability Theory article
Tests of Machine Intelligence paper
A Formal Measure of Machine Intelligence paper talk slides
A Collection of Definitions of Intelligence paper
A Formal Definition of Intelligence for Artificial Systems abstract poster
Is there an Elegant Universal Theory of Prediction? paper slides The full list of publications by Shane Legg can be found here.
The Interview:
Q1: Assuming no global catastrophe halts progress, by what year would you assign a 10%/50%/90% chance of the development of human-level machine intelligence?
Explanatory remark to Q1:P(human-level AI by (year) | no wars ∧ no disasters ∧ beneficially political and economic development) = 10%/50%/90%
Shane Legg: 2018, 2028, 2050
Q2: What probability do you assign to the possibility of negative/extremely negative consequences as a result of badly done AI?
Explanatory remark to Q2:
P(negative consequences | badly done AI) = ?P(extremely negative consequences | badly done AI) = ?(Where 'negative' = human extinction; 'extremely negative' = humans suffer;)
Shane Legg: Depends a lot on how you define things. Eventually, I think human extinction will probably occur, and technology will likely play a part in this. But there's a big difference between this being within a year of something like human level AI, and within a million years. As for the former meaning...I don't know. Maybe 5%, maybe 50%. I don't think anybody has a good estimate of this.
If by suffering you mean prolonged suffering, then I think this is quite unlikely. If a super intelligent machine (or any kind of super intelligent agent) decided to get rid of us, I think it would do so pretty efficiently. I don't think we will deliberately design super intelligent machines to maximise human suffering.
Q3: What probability do you assign to the possibility of a human level AGI to self-modify its way up to massive superhuman intelligence within a matter of hours/days/< 5 years?
Explanatory remark to Q3:
P(superhuman intelligence within hours | human-level AI running at human-level speed equipped with a 100 Gigabit Internet connection) = ?P(superhuman intelligence within days | human-level AI running at human-level speed equipped with a 100 Gigabit Internet connection) = ?P(superhuman intelligence within < 5 years | human-level AI running at human-level speed equipped with a 100 Gigabit Internet connection) = ?
Shane Legg: "human level" is a rather vague term. No doubt a machine will be super human at some things, and sub human at others. What kinds of things it's good at makes a big difference.In any case, I suspect that once we have a human level AGI, it's more likely that it will be the team of humans who understand how it works that will scale it up to something significantly super human, rather than the machine itself. Then the machine would be likely to self improve.How fast would that then proceed? Could be very fast, could be impossible -- there could be non-linear complexity constrains meaning that even theoretically optimal algorithms experience strongly diminishing intelligence returns for additional compute power. We just don't know.
Q4: Is it important to figure out how to make AI provably friendly to us and our values (non-dangerous), before attempting to solve artificial general intelligence?
Shane Legg: I think we have a bit of a chicken and egg issue here. At the moment we don't agree on what intelligence is or how to measure it, and we certainly don't agree on how a human level AI is going to work. So, how do we make something safe when we don't properly understand what that something is or how it will work? Some theoretical issues can be usefully considered and addressed. But without a concrete and grounded understanding of AGI, I think that an abstract analysis of the issues is going to be very shaky.
Q5: How much money is currently required to mitigate possible risks from AI (to be instrumental in maximizing your personal long-term goals, e.g. surviving this century), less/no more/little more/much more/vastly more?
Shane Legg: Much more. Though, similar to many charity projects, simply throwing more money at the problem is unlikely to help all that much, and it may even make things worse. I think the biggest issue isn't really financial, but cultural. I think this is going to change as AI progresses and people start to take the idea of human level AGI within their lifetimes more seriously. Until that happens I think that the serious study of AGI risks will remain fringe.
Q6: Do possible risks from AI outweigh other possible existential risks, e.g. risks associated with the possibility of advanced nanotechnology?
Explanatory remark to Q6:
What existential risk (human extinction type event) is currently most likely to have the greatest negative impact on your personal long-term goals, under the condition that nothing is done to mitigate the risk?
Shane Legg: It's my number 1 risk for this century, with an engineered biological pathogen coming a close second (though I know little about the latter).
Q7: What is the current level of awareness of possible risks from AI, relative to the ideal level?
Shane Legg: Too low...but it could well be a double edged sword: by the time the mainstream research community starts to worry about this issue, we might be risking some kind of arms race if large companies and/or governments start to secretly panic. That would likely be bad.
Q8: Can you think of any milestone such that if it were ever reached you would expect human-level machine intelligence to be developed within five years thereafter?
Shane Legg: That's a difficult question! When a machine can learn to play a really wide range of games from perceptual stream input and output, and transfer understanding across games, I think we'll be getting close."
The excerpt provided comes from a user post on LessWrong.
In your estimation, what specific cultural changes are necessary to increase awareness and serious study of AGI risks, and how might these changes be brought about?
Cultural changes required to increase awareness and serious study of AGI risks would need to revolve around a few key areas.
Firstly, education is paramount. The general public, as well as policymakers and even some tech professionals, often lack a deep understanding of AGI and its potential risks. This can be addressed by incorporating AI and AGI studies into mainstream education, starting from basic education to higher levels. This would not only increase the general level of understanding but also encourage more people to contribute to the field.
Secondly, open dialogue and transparency within the AI research community is necessary. Currently, there is a tendency for AI development to be conducted in silos, often in a competitive rather than collaborative manner. This can be addressed by promoting a culture of open-source research and encouraging collaboration over competition.
Thirdly, media plays a crucial role in shaping public opinion and awareness. Therefore, responsible and accurate reporting on AGI and its potential risks is necessary. Sensationalism and misinformation can lead to unnecessary fear or complacency, both of which can hinder effective risk management.
Lastly, regulation and policy development need to keep pace with technological advancements. This requires active involvement from policymakers, legal experts, ethicists, and technologists. Policies and regulations should be flexible and adaptable to accommodate the rapidly evolving nature of AGI.
To bring about these changes, concerted efforts from various stakeholders including educational institutions, tech companies, governments, and media are required. Public awareness campaigns, workshops, seminars, and conferences can be organized to disseminate knowledge and stimulate discussions. At the same time, policies that encourage transparency, collaboration, and responsible reporting in the field of AGI can be implemented.
Considering the importance of education, transparency, responsible media coverage, and policy development in managing AGI risks, how might we strategically leverage these elements to design a comprehensive, multi-tiered approach that effectively addresses both immediate and long-term challenges?
Designing a comprehensive, multi-tiered approach to effectively address both immediate and long-term challenges associated with AGI risks would require strategic planning and coordination across multiple sectors. Here's a potential strategy:
1. **Education**: Start by incorporating AI and AGI studies into the curriculum at all levels of education. This could range from basic awareness at the elementary level to specialized courses at the university level. Continuous learning programs for professionals can also be introduced. The goal should be to create a society that is informed and prepared for the advent of AGI.
2. **Transparency**: Encourage a culture of openness in AI research. This could be achieved by promoting open-source platforms and fostering collaboration between different research groups. Transparency would not only accelerate progress in the field but also allow for better monitoring and management of potential risks.
3. **Responsible Media Coverage**: Media organizations should be encouraged to report on AGI developments responsibly. This could involve training programs for journalists covering the tech sector and guidelines to ensure accurate and balanced reporting. Public awareness campaigns can also be used to disseminate reliable information.
4. **Policy Development**: Governments should work closely with technologists, ethicists, and legal experts to develop flexible and adaptable policies for AGI. Regulatory frameworks should be designed to promote transparency, protect individual rights, and mitigate potential risks. International cooperation would be crucial in this regard to ensure consistent standards across borders.
5. **Stakeholder Engagement**: Regular dialogue between all stakeholders, including researchers, policymakers, educators, and the public, is crucial. This could take the form of public consultations, expert panels, and conferences. Such platforms would allow for the sharing of ideas, monitoring of progress, and collective decision-making.
6. **Risk Assessment and Mitigation**: Finally, ongoing risk assessment and mitigation strategies should be put in place. This could involve the establishment of dedicated bodies to monitor AGI developments and assess potential risks. These bodies could also be responsible for coordinating responses in the event of any adverse outcomes.
By leveraging these elements strategically, we can create a robust system that not only addresses the immediate challenges posed by AGI but also prepares us for the long-term implications.
|
a6474cde-d3bc-4329-9146-779e9e992ab6
|
StampyAI/alignment-research-dataset/special_docs
|
Other
|
Being nice to software animals and babies
20
Being Nice to Software Animals
and Babies
AndersSandberg
For no reason, I reach down and pinch the tail of the mouse. It freezes; eyes
narrowed, cheeks puffed, it squeaks an ultrasonic sound I cannot hear. Itsfuriserect,whiskerspushedback.WhenIreleasethetail,themousequicklyretreats from me to the far end of the cage, trying to burrow into safety.
Did I do something bad? Most people would say that something morally
significant occurred: I might have expressed cruelty or indifference, and aliving being was in pain and fear for no good reason. If I were a researcher
it would be against the rules of ethical animal handling.
What if the mouse were software? I virtually pinch the virtual tail of a
complex simulation of a mouse, producing a sequence of signals that makethe image on my screen depict a mouse in pain that then retreats from its
apparent source. Is the virtual pinch as bad as the real pinch? Should I be
banned from treating the simulation that way?
1 Brain emulations
Ever since Hodgkin and Huxley laboriously calculated single nerve action
potentials using hand-cranked mechanical calculators in the early 1950s,
scientists have attempted to build ever more elaborate and exact computer
modelsofthebrainandbody.Atpresentthelargersimulationsinvolvemorethan a billion neurons, about the same number as in a small mammalian
brain. They are created in order to learn about the real brain by creating
IntelligenceUnbound:TheFutureofUploadedandMachineMinds , First Edition.
Edited by Russell Blackford and Damien Broderick.© 2014 John Wiley & Sons, Inc. Published 2014 by John Wiley & Sons, Inc.
280AndersSandberg
replicas: their behavior can tell us whether or not we have understood the
fundamental principles of various systems.
A brain emulation would be a one-to-one simulation where every causal
processinthebrainisrepresented,behavinginthesamewayastheoriginal.
It is the apparent logical endpoint of ever larger, ever more data-based real-
istic models, even if conventional neuroscientists do not pursue it directly.After all, just because the software behaves right does not mean we under-
standwhyitbehavesright.Weunderstandonlythelow-levelfunction,which
might not answer any of the deep questions.
Someresearchershaveadifferentambition:toachievesoftwareintelligence
by completely copying into software the functional structure of the nervoussystems.Ratherthanattemptingtounderstandthehigh-levelprocessesunder-
lying perception, action, emotions, and intelligence, the approach assumes
that these would emerge from a sufficiently close imitation of the low-level
neural functions (Sandberg and Bostrom 2008, Sandberg 2013). We might
getartificialintelligencesimplybyplagiarizingnature.
But if we are about to explore this realm of software beings, can we do it
right? Can brain emulations be created and handled ethically?
2 Software animal rights
Opponents of animal testing often argue that much of it is unnecessary and
couldbereplacedwithsimulations.Whilethisisdebatableatpresent,inthe
future software might become an adequate replacement. Indeed, since every
step could then be controlled and repeated, software might even be better
for research than real animals.
Unfortunately,developingbrainemulationswilllikelyrequireasignificant
useoftestanimals.Theywouldbenecessarynotonlyasthetemplatesofthe
emulationbutalsoforthelongchainofexperimentsprovidingthenecessary
understanding of neuroscience, scanning methods, and ways of comparing
real and simulated animals. Brain emulation requires us to understand atleast one level of the nervous system in sufficient detail to re-create all its
functionality. That is a tall research order.
Neuroscientists today use a broad array of species in research, from tiny
nematode worms to primates, but also turtles and Amazonian electrical
fishes. Early work on brain emulation is likely to focus on simple nervous
systems like the nematode Caenorhabditis elegans , the British pond snail,
or the fruit fly. We already have a complete map of the C. elegans nervous
system, although we do not know the kind of synapses it uses in most loca-
tions.Muchneuroscienceandtooldevelopmentwilllikelyalsoinvolvesuch
standard vertebrates as mice. This might involve invitroexperiments where
BeingNicetoSoftwareAnimalsandBabies 281
piecesofneuraltissuearestudiedandscanned,or invivoexperimentstrying
to map neural function to detectable behavior.
Much of the scanning work would avoid normal animal experimentation
concerns.Therewouldbenoexperimentdoneonthelivinganimalitself,just
tissue extraction. It is essentially terminal anesthesia. Here the ethical issues
arethetreatmentoftheanimalbeforeitsdemise,whetherthereisharmdoneto the animal in killing it, and whether there is a risk of software suffering.
The first two issues are dealt with in normal discussions of treatment of
lab animals.
Probably,earlyscans,models,andsimulationswilloftenbeflawed.Flawed
scans would be equivalent to animals with local or global brain damage.Flawedmodelswouldintroducesystemicdistortions,rangingfromthestate
of not having any functioning brain at all to abnormal brain states. Flawed
simulations (broken off because of software crashes) would correspond to
premature death (possibly repeated, with no memory). By analogy with liv-
inganimals,itseemsthatthemainworryshouldbeflawedmodelsproducing
hard-to-detect suffering.
Some success in smaller animals will lead to scanning and simulation of
larger and cleverer animals. There are few restrictions on research on inver-
tebrates (except for cephalopods). The rules get progressively stricter as one
approaches the higher mammals: research would become increasingly reg-ulated (and more ethically controversial from an animal use perspective).
Before moving on to human emulation, the final stages in animal brain
emulation would likely involve primates, raising the strongest animal pro-
tection issues.
Animal rights activists wishing for emulations to take the place of actual
animals must hence swallow the bitter fact that creating emulations will
require using lab animals. They might hope, however, that once emulations
arrivetheneedforrealanimalswillentirelydisappear. Atleasttosome,this
might morally outweigh the short-term moral cost.
3 The moral status of animals
Thereisavastliteratureaboutwhatconsiderationweshouldgivetoanimals,
andwecanposeasimilarquestionaboutwhatmoralclaimsemulationshave
on us. Can they be wronged? Can they suffer?
One group of theories argues that animals do not merit moral considera-
tion in themselves, but human actions on them do matter. Immanuel Kant
argued that animals lack moral autonomy and hence are not beings whose
interests count morally. Our duties toward them are indirect duties toward
humanity: being cruel to animals harms our own humanity. Someone who
282AndersSandberg
kicks a dog is a cruel person and shows a disregard for other beings unbe-
coming to a human (Regan and Singer 1989).
This kind of theory does not distinguish between software and animal:
if it is bad to pinch the tail of a biological mouse, the same cruel impulseis present in pinching the virtual tail of the emulated mouse. It might be
like harming an effigy: it is the intention behind the damage that counts,
not that the effigy is broken. Conversely, treating emulations nicely is liketreating dolls nicely: it might not be morally obligatory, it might even be
slightly silly, but it is compassionate.
A slightly different approach is found in social contract ethics. It is not
the intrinsic properties of the creature that matter but the relations we have
with it. If we can have the same kind of relationship with an emulated ani-mal as we do with a biological one, it should by this account be treated
similarly. Presuming that the ability to form reciprocal relations with other
beings depends on some neural substrate that would be successfully emu-lated, this appears plausible.
Manytheoriesclaimthattheinterestsofanimalscountbecauseanimals do
have some intrinsic property that matters. In a common version, sentience
gives moral status: being able to feel pleasure or pain makes you morally
relevant no matter what you are. However, telling what is sentient is hard.
Typically we rely on an argument from analogy, which looks at similaritiesbetween the thing in question and human beings in order to tell whether
there is enough functional similarity to justify the conclusion that it can
probably experience pain.
However, the argument from analogy runs into trouble with emulations.
Software – electrons in a computer – might imitate the functioning of a liv-
ing organism, but it is a very different kind of objectfrom biological wet-
ware. Many doubt that it could have consciousness. We will return to this
question.
It is possible to argue for animal rights without recourse to sentience, for
examplebyarguingthatanimalshavebeliefs,desires,andself-consciousness
of their own and that is what makes them moral patients: they are subjectsof a life, and that life has some value, if only to the animal itself (Regan
1983). Like the relationship approach, this seems to grant rights to suc-
cessful emulations: the maltreated virtual mouse will try to protect itself asbest it can. Nonetheless, doubts might remain whether the mere behavior
of pain-avoidance without any experience is morally important. Accounts
of moral patienthood typically assume that experience is fundamental sinceit ties together the state of affairs involving the agent with a value, the
agent’s welfare.
BeingNicetoSoftwareAnimalsandBabies 283
4 The moral status of software
Might software have the same moral weight as a real animal, by virtue of
being sentient or a being with inherent value?
Whether machines can be built to have consciousness is a perennial com-
ponent in the AI debate. Opponents of strong AI have often argued against
the possibility of any machine (or at least software) having mental states.
Current computational neuroscience does not think it is creating simula-
tionsthatcanhavebadexperiences.Infact,theassumptionthatsimulations
do not have consciousness is often used to motivate such research:
Secondly,oneofthemoreobviousfeaturesofmathematicalmodellingisthatitis
notinvasive,andhencecouldbeofgreatadvantageinthestudyofchronicpain.
Therearemajorethicalproblemswiththeexperimentalstudyof chronicpainin
humansandanimals.Itispossibletousemathematicalmodellingtotestsomeofthe neurochemical and neurophysiological features of chronic pain without the
use of methods which would be ethically prohibitive in the laboratory or clinic.
(Britton and Skevington 1996)
One reason we might doubt that current simulations have experience is
that they are so small, typically a handful of neurons. Intuitively this seemsto be too small to produce consciousness or experience. But it is likely not
thesizeofthenetworkthattrulymatters:thereisnoreasontothinkalotof
randomly connected neurons would be conscious either. Conversely Herzog
et al. (2007) suggest the “Small Network Argument”:
foreachmodelofconsciousnessthereexistsaminimalmodel,i.e.,asmallneural
network, that fulfills the respective criteria, but to which one would not like to
assign consciousness. (2007: 1055)
One way out is to argue that fine-grained consciousness requires at least
a mid-sized system, and that small networks only have rudimentary con-sciousness.Anotheristobitethebulletandaccept thatconsciousness might
exist in very simple systems. Perhaps phenomenal states are independent of
higher-level functions – even thermostats may have simple conscious states
(Chalmers1996).Ifso,wemighthavetoworryaboutthemoralpatienthood
of many, many things.
In any case, the largest simulations have reached more than a billion neu-
rons and we are approaching the numbers found in those brains we do find
morally relevant. Most such simulations do not have a very sophisticated
284AndersSandberg
structure, and this might prevent experience from occurring, but this is just
a guess – and many simulations attempt to mirror the overall structure of
the brain.
For example, consider the case of Rodney Cotterill’s “CyberChild.” This
is a simulated infant controlled by a biologically inspired neural network
and with a simulated body (Cotterill 2003). The network includes neuronpopulations corresponding to different real brain areas, connected accord-
ing to standard mammalian brain architecture with learning, attention, and
feedback from the body. The body model has muscles allowing it to move,
and states like levels of blood glucose, milk in the stomach, and urine in the
bladder. The baby needs to get enough milk to keep its blood sugar above a
critical level or it “dies.” Using its voice and motions it can interact with a
user that can feed it milk, and ideally it will learn behaviors that will keepit alive and happy. It is an ambitious project trying to implement a model
of consciousness, and the originator was hopeful that it might ultimately
develop consciousness.
But a conscious CyberChild would have lived an extremely impoverished
life.Itwouldhaveexistedwithinaworldofmainlyvisualperceptionexceptfor visceral inputs, hunger, and discomfort from full diapers. Its only means
of communication would have been crying and the only possible response
would have been the appearance (or not) of a bottle that had to be maneu-
veredtoitsmouth.Eveniftheexperiencedidnothaveanyaversivecontent,
there would be no prospect of real growth or change ever.
This is eerily similar to Metzinger’s warning:
What would you say if someone came along and said, “Hey, we want to geneti-
callyengineermentallyretardedhumaninfants!Forreasonsofscientificprogress
we need infants with certain cognitive and emotional deficits in order to study
their postnatal psychological development – we urgently need some funding for
this important and innovative kind of research!” You would certainly think this
was not only an absurd and appalling but also a dangerous idea. It would hope-
fully not pass any ethics committee in the democratic world. However, what
today’s ethics committees don’tsee is how the first machines satisfying a mini-
mallysufficientsetofconstraintsforconsciousexperiencecouldbejust likesuch
mentallyretardedinfants.Theywouldsufferfromallkindsoffunctionalandrep-
resentationaldeficitstoo.Buttheywouldnowalsosubjectivelyexperiencethose
deficits. In addition, they would have no political lobby – no representatives in
anyethics committee. (2003: 621)
Metzinger argues that we should ban all attempts to create or even risk the
creation of artificial systems that have phenomenological self-models (his
explanation of consciousness). While views might differ between different
thinkers on what the particular criterion isfor being able tosuffer, itis clear
BeingNicetoSoftwareAnimalsandBabies 285
that the potential for suffering software should be a normative concern.
Nonetheless, as discussed in mainstream animal rights ethics, other inter-
ests (such as human ones) can sometimes be strong enough to allow animalsuffering. Presumably such interests (if these accounts of ethics are correct)
would also permit creating suffering software.
Another classic paper about (machine) consciousness is Dennett’s “Why
YouCan’tMakeaComputerthatFeelsPain”(1978).Hearguesthatcreating
a machine able to feel pain is nontrivial, largely due to the incoherencies in
our ordinary concept of pain. However, he does not rule out the possibility
in principle:
If and when a good physiological sub-personal theory of pain is developed, a
robot could in principle be constructed to instantiate it. Such advances in sci-
ence would probably bring in their train wide-scale changes in what we found
intuitive about pain, so that the charge that our robot only suffered what weartificially called pain would lose its persuasiveness. In the meantime (if there
were a cultural lag) thoughtful people would refrain from kicking such a robot.
(Dennett 1978: 449)
From his perspective we should hence be cautious about whether or not to
ascribe suffering to software, since we do not (yet) have a good understand-
ing of what suffering is(or rather, what the actual underlying component
is that is morally relevant). In particular, successful brain emulations might
indeedrepresentaphysiologicalsub-personaltheoryofpain,butitmightbe
as opaque to outside observers as real physiological pain. Unfortunately the
emulation might still suffer.
Some researchers have suggested probability scales for machine phe-
nomenology based on the intuition that machines built along the same lines
as humans are more likely to be conscious than other machines (Gamez
2005). This is similar to the argument from analogy, and brain emulation
gets a fairly high score on this scale. Emulations are different from entirely
artificial software since the design is deliberately as similar as possible to
biological systems deserving of moral consideration, and this should make
us more morally cautious.
Sinceatpresenttheredoesnotseemtobeanyideaofhowtosolvethehard
problem of consciousness, or how to detect phenomenal states, this seems
to push us in the direction of suspending judgment:
there are the arguments of Moor (1988) and Prinz (2003), who suggest that
it may be indeterminable whether a machine is conscious or not. This could
force us to acknowledge the possibility of consciousness in a machine, even if
we cannot tell for certain whether this is the case by solving the hard problem of
consciousness. (Gamez 2008)
286AndersSandberg
The problem of animal experience and moral status is contentious: the
problem of emulated experience and status will be even more contentious.
Intuitions are likely divergent and there might not be any observations that
could settle the differences.
5 Treating emulated animals right
What to do? It seems that a safe moral strategy would be to make the most
cautious assumption:
PrincipleofAssumingtheMost(PAM) : Assume that any emulated system
could have the same mental properties as the original system and treat it
correspondingly.
The fact that we might legitimately doubt whether the emulation is a moral
patientdoesnotmeanithasavalueintermediatebetweenabiologicalbeing
andnothing,butratherthattheactualvalueiseitherfullornone;wejustdo
not know which. Thus, we should treat the virtual mice the same as the realmice since it is better to treat a simulacrum as a real thing than to mistreat
a sentient being, even by mistake.
TheprincipledoesnotsaythatwemusttreattheCyberChildasarealbaby.
If there are reasons to think that certain mental properties are notpresent,
they overrule the principle in that case. An emulated mouse that does not
respondtosensorystimuliorlacksmostofthebrainisclearlydifferentfroma normal mouse. The CyberChild, despite its suggestive appearance on the
screen, is not an emulation of a human infant but at most a tiny subset of
neurons(eachareahas20neurons)inagenericmammaliannervoussystem.It might still have some form of experience, but it is not the experience of a
higher mammal.
Doesn’t this principle prevent useful research, like the pain research dis-
cussed by Britton and Skevington (1996)? Perhaps not; it is agnostic on
whether there are overruling human interests, just as many animal ethics
theories do allow experiments if the benefits outweigh the moral costs. It
only argues that we should apply such a theory to the software, just in case.
The principle also has the advantage that most of the principles and regu-
lationsforanimaltestingcanbeimportedtothepursuitofbrainemulation.
Unless there is evidence to the contrary, we should treat emulated animals
with the same care as that deserved by the original animal. This means in
BeingNicetoSoftwareAnimalsandBabies 287
most cases that practices are equally impermissible in the physical lab and
thevirtuallab.Wecanalsoperformvirtualversionsofpracticesthatreduce
suffering, like sedation and painkillers. Parameters in the simulation can be
changed to have the same functional effects that drugs would have in a bio-logical nervous system – or even go beyond them by completely preventing
any output from pain-related neurons. It is also possible to run only part
of an emulated brain, leaving out pain receptors, pain systems, or systemsrelatedtoconsciousness.Thatisdifficultorimpossibleinbiologicalanimals,
but can be done exactly and reversibly in emulations.
Avoiding suffering from experiments is not the only problem in animal
experiments: there is an increasing realization that lab animals also need an
adequate quality of life in general. In the case of emulations, the problemis that quality of life presumably requires both an adequate simulated body,
and an adequate environment for the simulated body to exist in.
Thisisnotgoingtobemuchofaproblemfortheearlyemulations:worms
and snails are unlikely to find a crude VR analogue of their Petri dish or
aquarium inadequate. Higher mammals have higher demands of quality of
life. Running a brief test in a crude virtual environment might be accept-
able, but keeping a mouse, cat, or monkey living in a bare environment or
with a crude body for an extended time is not. It can be tricky to figure out
what level of resolution is needed. We have no way of estimating the impor-tanceratsplaceonsmells,andwhetherthesmellsinthevirtualcagearerich
enoughtobeadequate.Theintricacyofbodysimulationsalsomatters:how
realistic does fur have to feel to simulated touch to be adequate? Model-ing therightaspects requires a sensitive understanding of the lifeworlds of
animals we might prove unable to meet reliably.
One way around the moral hazard might be just to run the experiments
andthenrestoretheemulationtotheinitialstate:thereisno“freetime.”But
getting good data often requires having animals in a natural state of mind(orbody),sotheyneedtimetoacclimatizetotheirenvironmentortobehave
so the effects of interventions can be seen.
It seems likely that we can develop good practices for treating emulated
animals, just as we can develop good practices for treating biological
animals. We can approximate enough of the inner life of animals from
observationstomakesomeinferences;sotoowithdetectingproblemspecu-liar to their emulated states. In fact, the transparency of an emulation to
data-gatheringmakesiteasiertodetectcertainhazardssuchasactivationof
painsystemsorbehavioralwithdrawal,allowingusinprincipletobacktrackto their causal source. Perhaps we could learn things about the lifeworlds
of animals from emulations that we couldn’t learn from biological animals.
288AndersSandberg
6 The life and death of emulations
Most animal testing regulations present suffering as the central issue, and
hence euthanasia as a way of reducing it. Some critics of animal experimen-tation argue that, on the contrary, an animal life holds intrinsic value, so
endingitiswrong.Emulationsthrowaspannerintotheworksbysplintering
death.
Emulations can have strange existences. They will likely come into being
due to the death of a biological organism (since scanning methods are
unlikely to be non-destructive). Their existence might consist of periodsalternating activity and inert storage of indefinite length. They can be
terminated instantly and painlessly. It is possible (due to the multiple
realizability of software) to create multiple instances of the same emulation
and to terminate them at different times, producing a branching tree of
life histories. If ending the identifiable life of an instance is a wrong, thenit might be possible to produce a large number of wrongs by repeatedly
running and deleting instances of an emulation even if the experiences
during the run are neutral or identical.
Anotherpossibilityistoruntheemulation,makeabackupcopyofitsstate,
allow some time to pass, delete the running emulation, and replace it with
thecopy.Inthiscase,itseemsthatthebreakincontinuityisonlyobservableon the outside: the emulation restored from the backup will continue what
it was doing. But there will be a loss of experience of the time between the
backup and replacement. It is not clear that much is lost if the interval isvery short. Regan (1983) argues that the harm of death is a function of the
opportunities of satisfaction it forecloses; in this case it seems that it fore-
closes the opportunities envisioned by the emulation after the backup copyis made, but it is balanced by whatever satisfaction can be achieved during
that time. In fact, the new instance can get the same satisfaction again – the
hungry virtual mouse might eat its cheese twice.
Aharmthatcanbereversedisnormallyseenassmallerthananirreversible
harm. Emulation reduces the sting of death by making several of the harmsof death completely or partially reversible: suffering while dying, stopping
experience, bodily destruction, changes of identity, cessation of existence.
Sufferingcanbeabolishedusingvirtualanalgesics,experiencecanbeturnedon or off by running or stopping the emulation software, the virtual body
can be changed without affecting the neural model, the computer hardware
“body” can be replaced with other hardware, identity might be modified bysoftware psychosurgery and, perhaps, by the scanning and emulation pro-
cess, and instances can be deleted and restored from backups. In biological
BeingNicetoSoftwareAnimalsandBabies 289
organisms, all these harms are usually bundled together but emulation can
separate them. Death forecloses fewer opportunities to emulations.
Some might argue that the problem is not ending emulations, but the fun-
damental lack of respect for a being. The emulated mouse might not noticeanything wrong, but we know it is treated in a disrespectful way.
The reversibility of many forms of emulated death might make emulated
life cheaper. In a lifeboat case where we can either give a place in a lifeboatto an animal or to a computer running an emulation of a same-species ani-
mal, should we sacrifice the software? If it can be restored from backup,
the real loss will be just the lost memories since the most recent backup and
possibly some freedom. We might still agree that according to the PAM we
should treat the emulation as if it had the same moral weight as the origi-nal animal, but in the lifeboat case there is a genuine reason to give priority
to the individual without a backup. This reasoning might also carry over to
humanemulations:theharmfromthe(total,irreversible)deathofone’ssoleinstance is greater than the harm of the death of one’s current instance that
has a recent backup.
Most people accept that animal life should not be taken wantonly. But
cheap death might weaken this: it is easy and painless to end an emulation,
and it might be restored with equal ease, with no apparent harm done. If
more animals are needed, they can be instantiated up to the limits set byavailable hardware. Might this lead to a reduction of the value of emulated
life? Slippery slope arguments are rarely rationally convincing despite their
storytelling: this one depends on our overusing emulated animals and thenrationalizing this overuse by an assumed lesser value. But what has been
reduced is merely the harm of death, not the value of life. The problem lies
inrationalizingsomethingconvenientratherthanemulation.Thereisalsoa
muchlikelierriskthatpeoplewilltreatemulationsasunconscioussimulacra
just because they are software.
7 Ethics of human and animal emulations
Surprisingly, the question of moral status is easier to handle in the case ofhuman emulations than in the animal case, since human emulations canreport back about their state.
Ifa person who isskeptical of brain emulations being conscious or having
freewillisemulatedand,afterdueintrospectionandconsideration,changes
their mind, then that would seem to be some evidence in favor of emula-
tions actually having an inner life. Strictly speaking, however, it would not
prove anything stronger than that the processes whereby a person changes
290AndersSandberg
their mind are correctly emulated. The emulation couldstill be a functional
philosophical zombie lacking consciousness.
Ifphilosophicalzombiesexisted,itseemslikelythattheywouldbetreated
as persons as they took part in human societies. They would behave like
persons,theywouldvote,theywouldcomplainanddemandhumanrightsifmistreated,andinmostscenariostherewouldnotbeanywaytodistinguish
the zombies from the humans. They might even invoke the PAM. Hence, if
emulationsofhumanbrainsworkwellenoughtoexhibithuman-likebehav-
ior rather than mere human-like neuroscience, legal personhood is likely to
eventually follow, despite the misgivings of skeptical philosophers.
Personal identity is going to be a major issue with brain emulations, both
becauseofthetransitionfromanoriginalunproblematicsinglehumaniden-
tity to successor identity/identities that might or might not be the same,
and because software minds can potentially have multiple realizability. The
discussion about how personal identity relates to successor identities on dif-
ferent substrates is already extensive, and I will not add to it here. Thereare also intriguing questions about how moral obligations carry over when
copies are made, and what rights the originals have to dispose of versions
of themselves. At the very least, it seems that each running instance is anexample of a potential moral agent (as per the PAM), so each ought to be
treated well regardless of the existence of other copies.
8 Volunteers and emulation rights
Is it possible to give informed consent to become a brain emulation? The
mostlikelyscanning methodsaregoing tobedestructive,meaning thattheywouldendthebiologicallifeofthevolunteerorbeappliedtodonatedbrains
after the person has been declared dead.
Volunteering in the first case is a form of unusual assisted suicide, where a
possibleoutcomeisanotherlife.Duetotheuncertaintyaboutthementallife
of software there is no guarantee that there will be any experience “after,”even if the emulation technology looks perfect. There will also be the usual
considerations about personal identity and continuity, but no doubt volun-
teers will tend to have views on these compatible with an emulation beingthemin a sense that matters.
Fromalegalstandpointthismightbeproblematic,eveninliberaljurisdic-
tions.Whileendingone’slifeinordertoescapepainisincreasinglyaccepted,doing it for science is not. The Nuremberg code states that “No experiment
should be conducted, where there is an a priori reason to believe that death
or disabling injury will occur.”
BeingNicetoSoftwareAnimalsandBabies 291
There might be an opening if the emulation researchers themselves vol-
unteer. The code continues: “except, perhaps, in those experiments where
the experimental physicians also serve as subjects.” But at least at present,
extreme self-experimentation is not well regarded. Some experiments mayproduce such lasting harm that they cannot be justified by any social value
of the research (Miller and Rosenstein 2008). No doubt some people will
thinkthepossibilityofreachingaposthumanstatewithfundamentallyopen-endedevolutionarypossibilitiesmightactuallyhaveasufficientlyhighvalue.
The resulting debate will no doubt be both acrimonious and fascinating.
One volunteer group who would seem better placed to take part in brain
emulation research is terminal patients, who might prefer this particular
form of “suicide” to a guaranteed death. An analogy can be made to theuse of experimental therapies by the terminally ill, where concerns about
harmmustbeweighedagainstuncertaintyaboutthetherapy,andwherethe
vulnerability of patients makes them exploitable – it is not hard to imaginebrain emulation being oversold by enthusiastic developers.
In the case of post-mortem brain scanning, the legal and ethical situation
is easier. There is no legal or moral person in existence, just the preferences
of a past person and the rules for handling anatomical donations. This also
means that a successful brain emulation based on a person would exist in a
legal limbo: the law would lack the resources to regard it as more than anunusual product resulting from a legitimate anatomical donation. It would
notberegardedasaperson,andcurrentviewswouldholdittobetheprop-
erty of whatever institution performed the experiment.
Justasinthezombiecase,ahighlysuccessfulhumanbrainemulationcould
probably convince a liberal society that it was a thinking, feeling being with
moralagency,andhenceentitledtovariousrights.ThePAMwouldsupport
this: even if one doubted that the being was “real,” the moral risk of not
treatingapotentialmoralagentwellwouldbeworsethantheriskoftreatingnon-moralagentsbetterthanneeded.Itisanothermatterwhetherthiswould
beconvincingenoughtohavetheorderofdeathnullifiedandtheemulation
regarded as the same legalperson as the donor.
The risks of ending up a non-person in the eyes of the law, possibly
being used against one’s will for someone else’s purposes, ending up in a
brain-damagedstate,orwakingupinadisorientinglyalienfuturemightnotdeter volunteers. Similar risks certainly do not deter people from signing
contracts for cryonic preservation today, although they are fully aware
that they will be stored as non-person anatomical donations and might berevived in a future with greatly altered moral and social views. Given that
the alternative is certain death, cryonic preservation appears to many to be
a rational choice.
292AndersSandberg
9 Handling of flawed and distressed versions
Whatever the moral problems in the case of experimental animals, they are
worse for attempted human emulations. The process might produce dis-
tressed minds that have rights yet have an existence not worth living, or
that lack the capacity to form or express their wishes. For example, they
could exist in analogs to persistent vegetative states, dementia, schizophre-nia, or chronic pain. Many of these are of course parallel to current cases in
medical ethics.
Whencanyou“pulltheplug”ofanemulation?Itmightseemeasytoargue
that when we are ethically forbidden from pulling the plug of a counterpart
biological human, we are forbidden from doing the same to the emulation.
This unfortunately might lead to a situation where we have a large numberof emulation “patients” requiring significant resources, yet not contribut-
ing anything to refining the technology nor having any realistic chance of a
“cure.”
Fortunately, a running emulation can be stopped and its state stored for
possible future instantiation. This way at least ongoing painful or meaning-
less experience is stopped and no resources wasted, but it leads to questionsabout the right to eventual revival of the now frozen emulations. What if
they were left on a shelf forever, without ever restarting? That would be the
sameasdeletion.Butdotheyinthatcasehavearighttoberunatleastocca-sionally, despite their lacking any detectable benefit from the experience?
Persons might write advance directives about the treatment of their emu-
lations. This appears equivalent to normal advance directives, although the
reversibility of local termination makes pulling the plug less problematic. It
islessclearhowtohandledirectivestoterminatemoresubtlyderangedemu-lations. While a person might not currently wish to have a version with a
personality disorder become the successor, at the point where the emulation
comes into being it will potentially be a moral subject with a right to its life,and might regard its changed personality as the “correct” one.
10 Time and communication
Emulations will experience and behave on a timescale set by the speed of
theirsoftware.Thespeedatwhichtheirbodyandworldsimulationsarerun
relative to the outside world can be changed, depending on available hard-
ware and software. Current large-scale neural simulations are commonly
run with slowdown factors between a thousand and a hundred, but there
BeingNicetoSoftwareAnimalsandBabies 293
does not seem to be any reason precluding emulations running faster than
biological brains: a millionfold increase does not seem impossible.
Nick Bostrom and Eliezer Yudkowsky have proposed a Principle of Sub-
jectiveRateofTime:“Incaseswherethedurationofanexperienceisofbasicnormativesignificance,itistheexperience’ssubjectivedurationthatcounts”
(Bostrom and Yudkowsky, forthcoming). On this account, frozen states do
notcountatall.Conversely,veryfastemulationscanrapidlyproducealargeamountofpositiveornegativevalueiftheyareinextremestates:theymight
count for more in utilitarian calculations than slower minds.
Istherearightforahumanemulationtoruninrealtime,soitcaninteract
with the outside world? Speed does not matter to it as long it interacts only
with a virtual world and other emulations set to the same speed. But if itsspeeddivergesfromthatofbiologicalpeople,communicationwiththemwill
becometroublesomeorimpossible.Participationinsocialactivitiesdepends
on interaction, and it might be made impossible if human activities flashby faster than the emulation can handle. Conversely, a very fast emulation
would be isolated from them by their (apparently) glacial slowness. Hence
it seems that if emulated persons are to enjoy human rights (which typically
hinge on interactions with other persons and institutions) they will need
accesstoreal-timeinteraction,oratleast“disabilitysupport”iftheycannot
function quickly enough.
Allthissuggeststhatemulatedhumanswillhavearighttocontactwiththe
world outside their simulation. As Robert Nozick’s (1974: 42–45) experi-
ence machine thought experiment demonstrates, most people seem to wantto interact with the “real world,” although that might just mean the shared
social reality of meaningful activity rather than the physical world. Since
the virtual world is contingent upon the physical world, and asymmetri-
cally affected by it, restricting access only to the virtual is not enough if the
emulated people are to be equal citizens of their wider society.
11 Vulnerability and self-ownership
Software is amazingly fragile compared to biological bodies. The softwareand data constituting brain emulations and their mental states can be
instantly erased or changed by anybody with access to the system on which
they are running. Brain emulations would not be self-contained, and theirsurvival would depend upon hardware over which they might not have any
control. They could be subjected to undetectable violations such as illicit
copying. From an emulation perspective software security is identical to
personal security.
294AndersSandberg
Theyalsohaveaproblematicprivacysituation,sincenotonlycananemu-
lation’s behavior be perfectly documented by the very system it is running
on, but also its complete brain states are (in principle) open for inspection.
Whether that information can be interpreted in a meaningful way dependson future advances in neuroscience, but it is not unreasonable to think that
bythetimehumanemulationsexistmanyneuralcorrelatesofprivatemental
states will be known. This would put emulations in a precarious situation.
These considerations suggest that the ethical way of treating software
people would be to require strict privacy protection of their computational
processes,andthattheyhavelegalprotectionorownershipofthehardware
on which they are running. The computer is, in a sense, an emulation’s
physical body. Can this be squared with actual technological praxis (forexample, running emulations as distributed processes in the Cloud) and
economic considerations (suppose an emulation ran out of funds to pay for
its upkeep)? That remains to be seen.
Even if emulations are granted personhood and adequate property rights
in their hardware, they might still find the ownership of parts of themselves
to be complicated. It is not obvious that an emulation can claim to own
the brain scan that produced it: it was made at a point in time when the
person did not legally exist. The process might also produce valuable intel-
lectual property, for example useful neural networks that can be integratedinnon-emulationsoftwaretosolveproblems.Ifso,aproblememergesasto
who has a right to the property and any financial proceeds from it. Already
there have been legal battles over property rights to cells extracted frompatient’s bodies and turned into lucrative products. Cervical tumor cells
takenfromHenriettaLacksin1951,theyearshedied,aidedinthedevelop-
mentofpoliovaccineandothertreatmentsandmajordiscoveries.HeLacell
cultures are still alive in labs, effectively immortal. Lacks’ genome has been
sequenced, and concerns from her family prevailed in August 2013 whenthe unremunerated family “decided that it wanted the data to be available
under a restricted-access system [linking] individuals’ genetic make-up to
traits and diseases. Researchers would apply for permission to acquire thedataandagreetousethemforbiomedicalresearchonly,andwouldnotcon-
tact Lacks family members” (Callaway 2013). Emulations might have even
weaker legal protections unless they managed to add enough fine print totheir anatomical donation papers.
Conversely, essential sub-systems of the emulation software or hardware
could be licensed or outright owned by other parties. Does a right to lifeor self-ownership trump conventional property rights? Even if it does, the
human owners might still want fair compensation and look to assistance
from the law. Would it be acceptable for owners of computing facilities to
BeingNicetoSoftwareAnimalsandBabies 295
slow down or freeze non-paying emulations? Should this be allowed by a
future legal scheme of self-ownership for emulations?
12 The big picture
We have seen that it is possible to develop brain emulations ethically. But isit a good idea in itself?
Leaving aside fiction, which has been exploring the topic ingeniously for
at least half a century, the small amount of research on the social impact of
human brain emulation suggests it could be massively disruptive. In partic-
ular,simpleeconomic modelspredictthatcopyable humancapitalproduces
explosive economic growth and population increase but also that wages
plummet toward Malthusian levels (Hanson 1994, 2008). Economies thatcan harness emulation technology productively might have a huge strategic
advantage over latecomers. It is not hard to imagine emulation technology
leading to arms races, increasing inequality, disruption of the old order, andtheviolentemergenceofnewcentersofpower.Therewouldbeconcernsfor
human rights, triggers of xenophobia, and volatile religious and philosoph-
ical views.
Even if emulation did not lead to conflict, it might still lead to bad out-
comes. For example, long-run competition between copyable minds might
produce beings optimized only for work, spending all available resources
on replication and optimizing away everything that actually gives life value.
If emulations are zombies, a humanity tempted by cybernetic immortalitymight gradually trade away its consciousness.
Conversely, the technology might drastically reduce the harms of death.
Given that 160,000 people now die worldwide every day, this might be amassivemoral good. Non-biological humans might have minuscule ecolog-
ical footprints and would not need to devour other living creatures. They
wouldbeimmunetomanyofthethreatstobiologicalhumans.Ifthehumanspecies split into two, the joint risks might be significantly reduced, even
if emulations had their own worries about power outages and computer
viruses.Softwaremindswouldhaveafarbettershotatcolonizingspacethanbiological minds, and could even be transmitted to receiver bodies without
requiringspacecraft.ThepreciouseggsofEarthmightbeputintomorethan
one basket.
The world available to posthuman, upgradeable minds might contain
modes of being more valuable than anything a human could experience –
just as our art, games, science, and spirituality have value that other
mammals cannot grasp.
296AndersSandberg
Unfortunately,theseconsiderationsdonotlendthemselvestocomparison.
They all depend on speculative scenarios, and their probabilities and mag-nitude cannot easily be compared. Rather than offering a rationale either
for going ahead or for stopping emulation, they give reasons for assuming
that – were it to succeed – it will matter enormously. The value of informa-tion that helps determine the correct course of action is equally significant.
We are still far, far away from a race toward posthumanity. But we are
close enough to the virtual mice that we should start thinking about how to
care for them.
References
Bostrom, Nick, and Yudkowsky, Eliezer. Forthcoming. The ethics of artificial intel-
ligence. In William Ramsey and Keith Frankish, eds., TheCambridgeHandbook
ofArtificialIntelligence . Cambridge: Cambridge University Press.
Britton, Nicholas F., and Skevington, Suzanne M. 1996. On the mathematical mod-
eling of pain, NeurochemicalResearch 21(9): 1133–1140.
Callaway, Ewen. 2013. Deal done over HeLa cell line, Nature News , http://www
.nature.com/news/deal-done-over-hela-cell-line-1.13511 (accessed October 8,
2013).
Chalmers,DavidJ.1996. TheConsciousMind:InSearchofaFundamentalTheory .
New York and Oxford: Oxford University Press.
Cotterill,Rodney.2003.CyberChild:Asimulationtest-bedforconsciousnessstudies.
In Owen Holland, ed., MachineConsciousness . Exeter: Imprint Academic.
Dennett, Daniel C. 1978. Why you can’t make a computer that feels pain. Synthese
38: 415–456.
Gamez, David. 2005. An ordinal probability scale for synthetic phenomenology.
In R. Chrisley, R. Clowes, and S. Torrance, eds., Next-Generation Approaches
to Machine Consciousness: Proceedings of the AISB05 Symposium on Next-Generation Approaches to Machine Consciousness . Hatfield, UK: University of
Hertfordshire, pp. 85–94.
Gamez, David. 2008. Progress in machine consciousness. Conscious Cognition
17(3): 887–910. (Epub. June 14.)
Hanson, R. 1994. If uploads come first: The crack of a future dawn. Extropy 6(2):
10–15.
Hanson, R. 2008. Economics of the singularity. IEEESpectrum,pp. 37–42.
Herzog, Michael H., Esfeld, Michael, and Gersner, Wulfram. 2007. Conscious-
ness and the small network argument. Neural Networks 20(9): 1054–1056. doi:
10.1016/j.neunet.2007.09.001.
Metzinger, Thomas. 2003. BeingNoOne . Cambridge, MA: MIT Press.
Miller F.G., and Rosenstein, D.L. 2008. Challenge experiments. In E.J. Emanuel,
C. Grady, R.A. Crouch, et al., eds., The Oxford Textbook of Clinical Research
Ethics. Oxford: Oxford University Press, pp. 273–279.
Nozick, Robert. 1974. Anarchy,State,andUtopia . New York: Basic Books.
BeingNicetoSoftwareAnimalsandBabies 297
Regan, Tom. 1983. The Case for Animal Rights . Berkeley: University of California
Press.
Regan, T., and Singer, P., eds. 1989. Animal Rights and Human Obligations , 2nd
edn. Englewood Cliffs, N.J.: Prentice Hall.
Sandberg, Anders. 2013. Feasibility of whole brain emulation. In Vincent C.
Müller, ed., Philosophy and Theory of Artificial Intelligence . Berlin: Springer,
pp. 251–264.
Sandberg,A.,andBostrom,N.2008. WholeBrainEmulation:ARoadmap .Oxford:
Future of Humanity Institute, Oxford University.
|
1ff7d6c9-5c48-4950-8f2a-45e6931eac1f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
"Model UN Solutions"
When I was in high school, because I was on the history bowl team the teacher who advised the model UN club recruited me to play as their delegate in various “historical committees” like the Roman Senate or 1789 French Assembly. I never engaged in any normal committees since you couldn’t undertake false flag attacks or convince the Pope to excommunicate other delegates.
In most committees, as far as I can tell, players represent countries trying to pass a resolution addressing some topic like climate change that’s decided beforehand. An award is given to the player the facilitator decides is the “best delegate”—an unwritten combination of speaking ability, social dominance, and accurately representing (or at least not fatally misunderstanding) your assigned country’s positions and interests.
I often make a mental metaphor about “model UN discussions” and “model UN solutions.” Model UN discussions revolve around people expecting to be rewarded for making many remarks, even though their actual positions could be expressed simply or don’t permit much elaboration.
This leads to the “model UN solutions,” which have a few types, e.g.
* Applause lights: You could just say buzzwords or unobjectionable trivialities (“When addressing the climate change question we should consider the interests of all the relevant stakeholders. We should apply neither an {extreme viewpoint} nor {the opposite extreme}”)
* Unspecified solutions: You could give very little information that uniquely identifies a specific change from the status quo in the listener’s mind. At the extreme you get a lot of remarks of the form “To address the problem we should {devote resources} to {solving the problem}” where the bracketed parts are replaced with phrases that aren’t much more specific (“To address climate change we should set up task forces to identify the best technological and policy approaches”)
* Tradeoff-ignorant solutions: You could even give a directional suggestion but avoid any conside
|
3ed9a9ca-e4f3-4422-86bf-0149cf59287a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
What the future will look like
The alarm rings — gentle, cascading sounds, increasing gradually in volume, to softly rouse you from your REM cycle. The sound radiates from micro-speakers distributed around your room; the 360° soundscape makes it sound like the walls are singing, beckoning you to take on a new day.
You wake up rejuvenated, and peel off the neuro-pellets from the side of your head, that quietly stimulated delta-waves in your brain through the stages of deepest sleep, accelerating cognitive regeneration while you explored a different world — one that hasn’t been touched by humans yet.
“Aliza, play today’s Robinhood Snacks podcast,” you tell your voice-enabled smart-home device, one that you built yourself in minutes from a DIY-kit you found online, because you know better than to install big-tech listening devices in your own home.
The podcast continues to play as you enter the bathroom — the audio syncs across the house, switching on and off as you enter each room to conserve energy. Speaking of energy, you wonder how much you saved yesterday. You click into an app, and a giant dashboard tells you you hit this month’s goals — “Huzzah! Check your texts for a special reward.” Amazing, they’ve sent you $10 in cryptocurrency for being a good energy citizen.
Your phone knows what to do with rewards — you’ve trained it well to manage personal finances. 10% goes to your favourite social cause — AI Safety Research. You volunteer with a local nonprofit that is working to keep humans and machines safe from each other by aligning their goals, and you’re their top contributor. 50% is distributed across your investment portfolio with predetermined weighting, and you use the remaining 40% to invest in metaverse assets — last time you bought a tiny bit of land in Decentraland-Iceland, and it’s looking beautiful, so you buy a few more square-feet. In September, the developers ship property-owners special VR-headsets that click into your neuro-pellets, creating the most dazzling multisensory No
|
d077969d-04ac-4339-af47-2072958a8801
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Update to "Dominant Assurance Contract Platform"
Update #2: Platform Launched
This is an update to The Economics of the Asteroid Deflection Problem (Dominant Assurance Contracts)
How the fundraiser went
TL;DR I got $2172.67 dollars even though I only asked for $629.
My prediction of how the fundraiser would go
I expected that I would get ~1000 views on my website, of which 1% would decide to fund me, with an average donation of $90. 1000×1%×$90=$900. I expected that I would get a large initial sum of money and then it would slowly crawl upwards, until getting funded in the last few minutes.
Manifold markets seemed more pessimistic than me (see how on the 28th August there was only a 26% chance I'd raise more than $829) so I lowered the price to $629. This turned out to be unnecessary.
How the fundraiser actually went
After initially posting on Lesswrong, the conversion rate of people visiting https://dac.mowzer.co.za to funding my project was 20%. This was much higher than I expected.
On 2 September, Alex Tabarrok posted my project on marginalrevolution.com (Thanks!). After which the number of visits skyrocketed. The conversion rate lowered to 4%, but this was still higher than the 1% I expected, especially since people kept donating to the project even after it was funded.
After the goal was reached
After the the goal was reached on 2 September, people kept donating! I was not expecting this. I'm really grateful to everyone who donated.
In the end, I got 1300 visits, most from when it was posted on marginal revolution.
What I am going to do
I asked for $639 to work for a month, but since I got more than triple this I'm going to work for 3 months (up to 15 December)!
What I need
I need a name
I'm running a contest on manifold.markets to name my platform. I will PayPal $25 to the person who suggests the winning name
I need producers of public goods
If you are interested in using my platform get funding for something you want to create please fill out this google form.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.