
id
stringlengths 36
36
| source
stringclasses 15
values | formatted_source
stringclasses 13
values | text
stringlengths 2
7.55M
|
|---|---|---|---|
c95f61d7-f8d9-4755-92c1-4e81412631c6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[AN #69] Stuart Russell's new book on why we need to replace the standard model of AI
Find all Alignment Newsletter resources here. In particular, you can sign up, or look through this spreadsheet of all summaries that have ever been in the newsletter. I'm always happy to hear feedback; you can send it to me by replying to this email.
This is a bonus newsletter summarizing Stuart Russell's new book, along with summaries of a few of the most relevant papers. It's entirely written by Rohin, so the usual "summarized by" tags have been removed.
We're also changing the publishing schedule: so far, we've aimed to send a newsletter every Monday; we're now aiming to send a newsletter every Wednesday.
Audio version here (may not be up yet).
Human Compatible: Artificial Intelligence and the Problem of Control (Stuart Russell): Since I am aiming this summary for people who are already familiar with AI safety, my summary is substantially reorganized from the book, and skips large portions of the book that I expect will be less useful for this audience. If you are not familiar with AI safety, note that I am skipping many arguments and counterarguments in the book that are aimed for you. I'll refer to the book as "HC" in this newsletter.
Before we get into details of impacts and solutions to the problem of AI safety, it's important to have a model of how AI development will happen. Many estimates have been made by figuring out the amount of compute needed to run a human brain, and figuring out how long it will be until we get there. HC doesn't agree with these; it suggests the bottleneck for AI is in the algorithms rather than the hardware. We will need several conceptual breakthroughs, for example in language or common sense understanding, cumulative learning (the analog of cultural accumulation for humans), discovering hierarchy, and managing mental activity (that is, the metacognition needed to prioritize what to think about next). It's not clear how long these will take, and whether there will need to be more breakthroughs after these occur, but these se
|
91917dc6-38e1-4c3f-8b00-eac8e5899a90
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The affect heuristic and studying autocracies
General Juan Velasco Alvarado was the military dictator of Peru from 1968 to 1975. In 1964-5 he put down revolutionary peasant guerilla movements, defending an unequal and brutally exploitative pattern of land ownership. Afterward he became frustrated with the bickering and gridlock of Peru’s parliament. With a small cadre of military coconspirators, he planned a coup d’état. Forestalling an uprising by pro-peasant parties, he sent tanks to kidnap the democratically elected president. The parliament was closed indefinitely. On the one year anniversary of his coup, Velasco stated “Some people expected very different things and were confident, as had been the custom, that we came to power for the sole purpose of calling elections and returning to them all their privileges. The people who thought that way were and are mistaken”.[1]
What would you expect Velasco’s policy toward land ownership and peasants to be? You would probably expect him to continue their exploitation by the oligarchy land-owning families. But you would be mistaken. Velasco and his successor redistributed 45% of all arable land in Peru to peasant lead communes, which were later broken up. Land redistribution is a rare spot of consensus in development economics, improving both the lives of the poor and increasing growth. [2]
I told you this story to highlight how your attitudes toward the actor affect your predictions. It is justifiable to dislike Velasco for his violence, for ending Peruvian democracy, for his state-controlled economy. But our brains predict off of those value judgements. The affect heuristic (aka the halo/horn effect) is when one positive/negative attribute of an actor causes people to assume positive/negative attributes in another area. The affect heuristic causes attractive candidates to be hired more often, or honest people to be rated as more intelligent. Subjects told about the benefit of nuclear power are likely to rate it as having fewer risks, et cetera. Our moral attitud
|
f910b043-702f-4891-805a-2d21b1934a37
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The call of the void
Original post: http://bearlamp.com.au/the-call-of-the-void
L'appel du vide - The call of the void.
When you are standing on the balcony of a tall building, looking down at the ground and on some track your brain says "what would it feel like to jump". When you are holding a kitchen knife thinking, "I wonder if this is sharp enough to cut myself with". When you are waiting for a train and your brain asks, "what would it be like to step in front of that train?". Maybe it's happened with rope around your neck, or power tools, or what if I take all the pills in the bottle. Or touch these wires together, or crash the plane, crash the car, just veer off. Lean over the cliff... Try to anger the snake, stick my fingers in the moving fan... Or the acid. Or the fire.
There's a strange phenomenon where our brains seem to do this, "I wonder what the consequences of this dangerous thing are". And we don't know why it happens. There has only been one paper (sorry it's behind a paywall) on the concept. Where all they really did is identify it. I quite like the paper for quoting both (“You know that feeling you get when you're standing in a high place… sudden urge to jump?… I don't have it” (Captain Jack Sparrow, Pirates of the Caribbean: On Stranger Tides, 2011). And (a drive to return to an inanimate state of existence; Freud, 1922).
Taking a look at their method; they surveyed 431 undergraduates for their experiences of what they coined HPP (High Place Phenomenon). They found that 30% of their constituents have experienced HPP, and tried to measure if it was related to anxiety or suicide. They also proposed a theory.
> ...we propose that at its core, the experience of the high place phenomenon stems from the misinterpretation of a safety or survival signal. (e.g., “back up, you might fall”)
I want to believe it, but today there are Literally no other papers on the topic. And no evidence either way. So all I can say is - We don't really know. s'weird. Du
|
58af1931-e7cf-4a9d-bdf5-2f004d22724a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
App idea to help with reading STEM textbooks (feedback request)
Problem: STEM textbooks often reference figures and equations from earlier in the textbook. They usually do this with statements like "the shearing stress τ... may be obtained from the shearing-stress-strain diagram of Fig. 3.30." But Fig. 3.30 might be from 5 pages ago, or even earlier. Many textbooks don't have a list or index of equations, so the only way to find the referenced figure is to search page by page.
How this would ideally be solved: Every textbook would have an e-book version that links to, and previews, referenced equations every time they are mentioned.
Why not do this: Different textbooks identify and reference figures and equations different ways. Many readers of e-books use DRM-protected apps. These make it hard to create a universal solution that automatically identifies and annotates texts to provide this functionality. In addition, building an e-reader with this functionality requires building an e-reader to display PDFs and other formats, which seems very hard.
How I suspect most people solve the problem: Most people probably deal with this more or less like I do. The struggle to be diligent and actually look up the referenced figure. They might try to memorize the information. They also might put it into a list of reference notes containing the equations.
Why these solutions are suboptimal: Trying to look up or memorize information is cognitively and motivationally challenging. Learning dense material is already hard, and this adds to the burden. Taking notes can help. However, this leads to visual clutter when most equations aren't necessary at a given time, or when material that needs to be looked at simultaneously is distributed across different pages of notes. It's not always easy to get the required information into the note-taking system. Some note-taking systems also have trouble managing the sort of information a STEM student might need.
How this new app would solve the problem: This app depends on a "snip" feature, where we tak
|
098031b0-cc54-44c0-9aab-706b6411aadd
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[Link] Intro to causal inference by Michael Nielsen (2012)
This is a link post for Michael Nielsen's "If correlation doesn’t imply causation, then what does?" (2012).
I want to highlight the post for a few reasons:
(1) it is a well-written introduction by an experienced science communicator — Michael is an author of the most famous book on quantum computing;
(2) causal inference is an essential tool for understanding the world;
(3) two recent AI safety papers use causal influence diagrams to (a) understand agent incentives [arXiv, Medium] and (b) to provide a new perspective on some problems in AGI safety [arXiv].
|
57a251bd-f688-48d4-8183-4ea0e5145b05
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Against Cryonics & For Cost-Effective Charity
Related To: You Only Live Twice, Normal Cryonics, Abnormal Cryonics, The Threat Of Cryonics, Doing your good deed for the day, Missed opportunities for doing well by doing good
Summary: Many Less Wrong posters are interested in advocating for cryonics. While signing up for cryonics is an understandable personal choice for some people, from a utilitarian point of view the money spent on cryonics would be much better spent by donating to a cost-effective charity. People who sign up for cryonics out of a generalized concern for others would do better not to sign up for cryonics and instead donating any money that they would have spent on cryonics to a cost-effective charity. People who are motivated by a generalized concern for others to advocate the practice of signing up for cryonics would do better to advocate that others donate to cost-effective charities.
Added 08/12: The comments to this post have prompted me to add the following disclaimers:
(1) Wedrifid understood me to be placing moral pressure on people to sacrifice themselves for the greater good. As I've said elsewhere, "I don't think that Americans should sacrifice their well-being for the sake of others. Even from a utilitarian point of view, I think that there are good reasons for thinking that it would be a bad idea to do this." My motivation for posting on this topic is the one described by rhollerith_dot_com in his comment.
(2) In line with the above comment, when I say "selfish" I don't mean it with the negative moral connotations that the word carries, I mean it as a descriptive term. There are some things that we do for ourselves and there are some things that we do for others - this is as things should be. I'd welcome any suggestions for a substitute for the word "selfish" that has the same denotation but which is free of negative conotations.
(3) Wei_Dai thought that my post assumed a utilitarian ethical framework. I can see how my post may have come across that way. However, while writing
|
b227a77d-c4ad-4d5f-883a-1fe240bf6f8f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Different location for Berkeley meetup
Discussion article for the meetup : Different location for Berkeley meetup
WHEN: 17 October 2012 07:00:00PM (-0700)
WHERE: 2128 Oxford St, Berkeley, CA
Today Zendo and I are unavailable. Several people on the mailing list have suggested that people meet at the Starbucks on Center and Oxford Street at 7pm. You should come there if your coming there acausally implies that other people will come there.
Discussion article for the meetup : Different location for Berkeley meetup
|
d00bcf66-6360-48be-8a72-c025ce414cf1
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Decent plan prize announcement (1 paragraph, $1k)
Edit Jan 20: Winner & highlights
Say I'm about to do a real big training run on playing video games, predicting text, predicting physics, writing code that works, etc etc. Say I've got a real good neural net architecture and a whole lot of flops. Say I'm a company and I'm gonna use this thing for AI lawyers and coders etc for a profit. Say I'm mildly concerned it somehow kills me and am willing to throw a few $ to prevent that.
So what should I do? How should I train and deploy the model?
Comment below or answer at this link if you don't want to be plagiarized.
Prize goes to best answer. (I judge obviously.)
The shorter the answer the better.
Deadline is Wednesday January 17 anywhere on Earth but answering immediately is better/easier.
You may accept your prize as 50 pounds of quarters if you prefer.
----------------------------------------
Clarification jan 12: say I've got 1000x the gpt4 flops and that my architecture is to transformers as convolutions are to simple MLPs in vision (ie a lot better)
Clarification 2: an answer like "here's how to get strong evidence of danger so you know when to stop training" is valid but "here's how to wipe out the danger" is much better.
3: Example answer for nuclear generators: "Spring-load your control rods so they are inserted when power goes out. Build giant walls around reactor so if steam explodes then uranium doesn't go everywhere. Actually, use something low pressure instead if possible, like molten salt or boiling water. Lift the whole thing off the ground to avoid flood risk."
4: This is hypothetical. I am not actually doing this. I'm not a billionaire.
5: "Hire someone" and "contract it out " and "develop expertise" etc obviously do not count as answers.
|
b5522b28-cea5-42fb-a2c2-6fe0410277a6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
A very non-technical explanation of the basics of infra-Bayesianism
Introduction
As a response to John Wentworth's public request, I try to explain the basic structure of infra-Bayesian decision-making in a nutshell. Be warned that I significantly simplify some things, but I hope it gives roughly the right picture.
This post is mostly an abridged version of my previous post Performance guarantees in in classical learning and infra-Bayesianism. If you are interested in the more detailed and less sloppy version, you can read it there, it's a little more technical, but still accessible without serious background knowledge.
I also wrote up my general thoughts and criticism on infra-Bayesianism, and a shorter post explaining how infra-Bayesianism leads to the monotonicity principle.
Classical learning theory
Infra-Bayesianism was created to address some weak spots in classical learning theory. Thus, we must start by briefly talking about learning theory in general.
In classical learning theory, the agent has a hypothesis class, each hypothesis giving a full description of the environment. The agent interacts with the environment for a long time, slowly accumulating loss corresponding to certain events. The agent has a time discount rate γ, and its overall life-time loss is calculated by weighing the losses it receives through its history by this time discount.
The regret of an agent in environment e is the difference between the loss the agent actually receives through its life, and the loss it would receive if it followed the policy that is optimal for the environment e.
We say that a policy successfully learns a hypothesis class H, if it has low expected regret with respect to every environment e described in the hypothesis class.
How can a policy achieve this? In the beginning, the agent takes exploratory steps and observes the environment. If the observations are much more likely in environment e1 than in environment e2, then the agent starts acting in ways that make more sense in environment e1, and starts paying less atten
|
a25e82a2-77f3-4080-9b72-628a6dc42be1
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
What achievements have people claimed will be warning signs for AGI?
In MIRI's March newsletter, they link [this post](https://www.technologyreview.com/s/615264/artificial-intelligence-destroy-civilization-canaries-robot-overlords-take-over-world-ai/) which argues against the importance of AI safety because we haven't yet achieved a number of "canaries in the coal mines of AI". The post lists:
* The automatic formulation of learning problems
* Self-driving cars
* AI doctors
* Limited versions of the Turing test
What other sources identify warning signs for the development of AGI?
|
3f8f2365-44a2-401e-a0c8-5af946c6d7a8
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Engineering Monosemanticity in Toy Models
Overview
========
In some neural networks, individual neurons correspond to natural "features" in the input. Such *monosemantic* neurons are much easier to interpret, because in a sense they only do one thing. By contrast, some neurons are *polysemantic*, meaning that they fire in response to multiple unrelated features in the input. Polysemantic neurons are much harder to characterize because they can serve multiple distinct functions in a network.
Recently, [Elhage+22](https://transformer-circuits.pub/2022/toy_model/index.html) and [Scherlis+22](https://arxiv.org/abs/2210.01892) demonstrated that architectural choices can affect monosemanticity, raising the prospect that we might be able to engineer models to be more monosemantic. In this work we report preliminary attempts to engineer monosemanticity in toy models.
Toy Model
=========
The simplest architecture that we could study is a one-layer model. However, a core question we wanted to answer is: how does the number of neurons (nonlinear units) affect the degree of monosemanticity? To that end, we use a two-layer architecture:
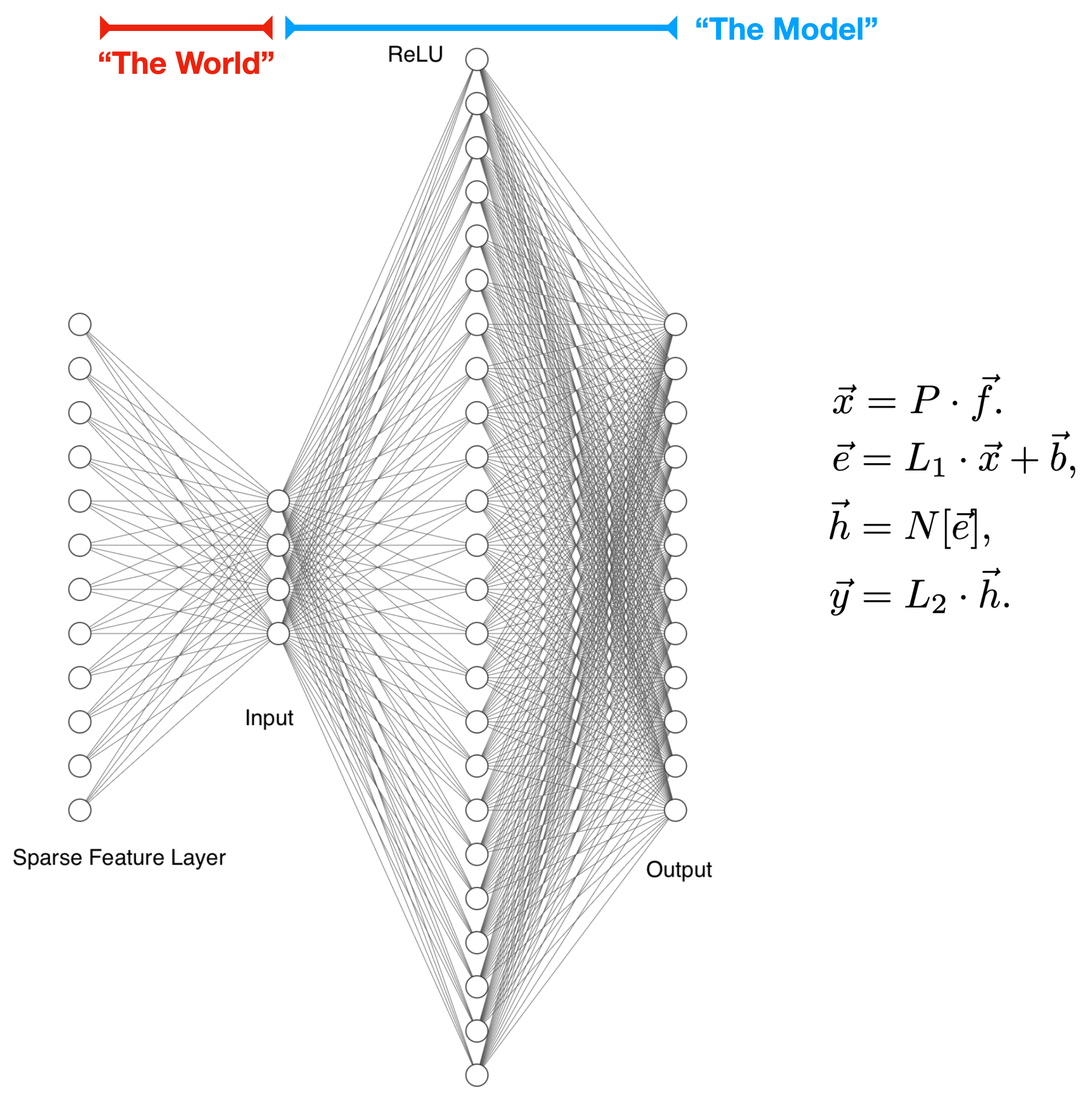Features are generated as sparse vectors in a high-dimensional space. They are then run through a (fixed) random projection layer to produce the inputs into our model. We imagine this random projection process as an analogy to the way the world encodes features in our observations.
Within the model, the first layer is a linear transformation with a bias, followed by a nonlinearity. The second layer is a linear transformation with no bias.
Our toy model is most similar to that of Elhage+22, with a key difference being that the extra linear layer allows us to vary the number of neurons independent of the number of features or the input dimension.
We study this two model on three tasks. The first, a feature decoder, performs a compressed sensing reconstruction of features that were randomly and lossily projected into a low-dimensional space. The second, a random re-projector, reconstructs one fixed random projection of features from a different fixed random projection. The third, an absolute value calculator, performs the same compressed sensing task and then returns the absolute values of the recovered features. These tasks have the important property that we know which features are naturally useful, and so can easily measure the extent to which neurons are monosemantic or polysemantic.
Note that we primarily study the regime where there are more features than embedding dimensions (i.e. the sparse feature layer is wider than the input) but where features are sufficiently sparse that the number of features present in any given sample is smaller than the embedding dimension. We think this is likely the relevant limit for e.g. language models, where there are a vast array of possible features but few are present in any given sample.
Key Results
===========
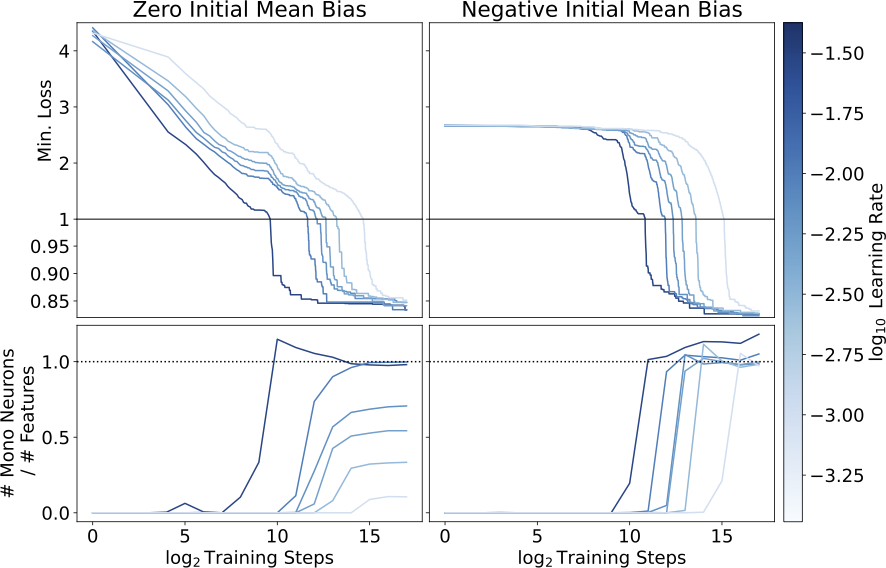We find that models initialized with zero mean bias (left) find different local minima depending on the learning rate, with more monosemantic solutions and slightly lower loss at higher learning rates. Models initialized with a negative mean bias (right) all find highly monosemantic local minima, and achieve slightly better loss. Note that these models are all in a regime where they have more neurons than there are input features.
Just to hammer home how weird this is, below we've plotted the activations of neurons in response to single-feature inputs. The three models we show get essentially the same loss but are clearly doing very different things!
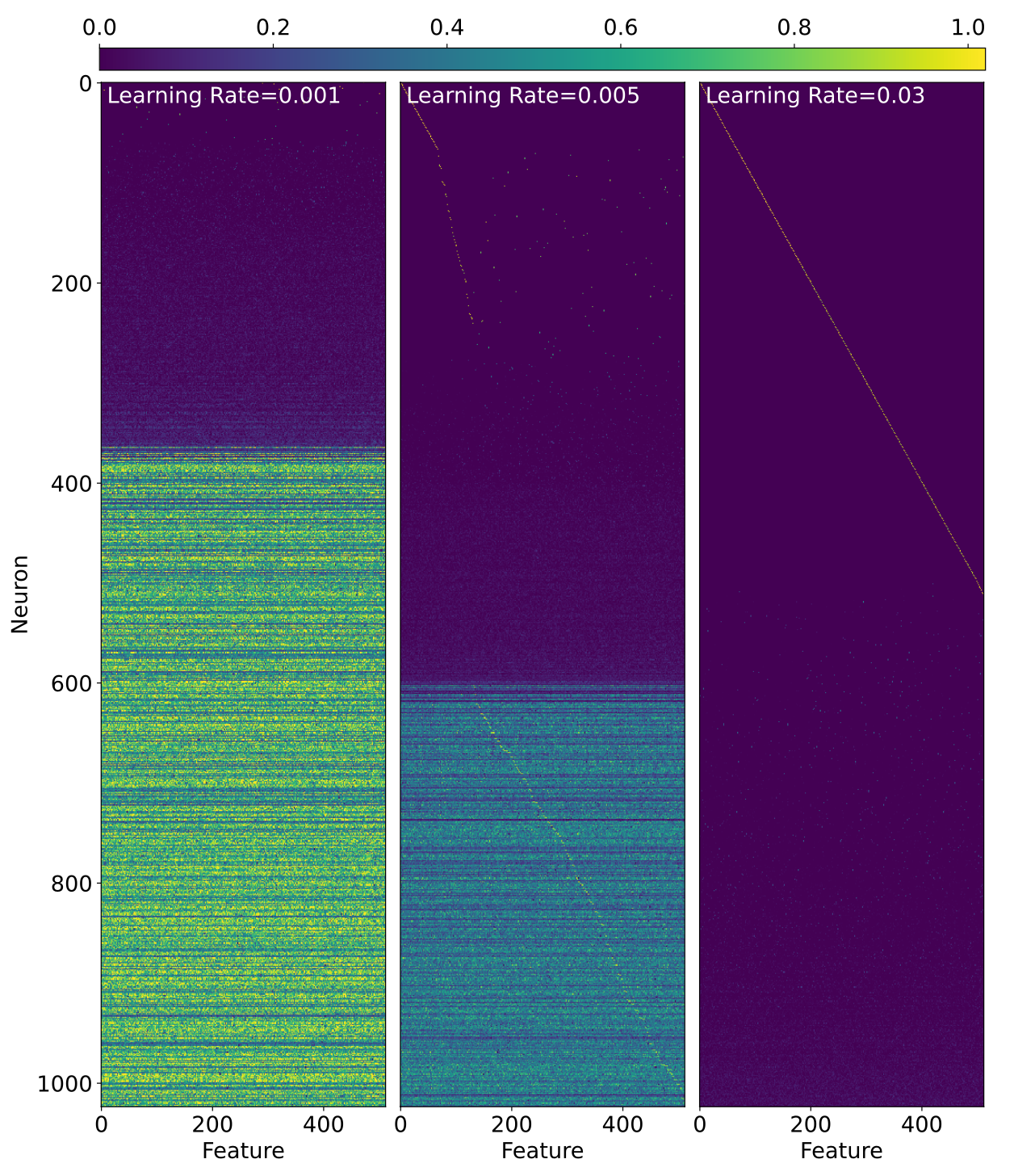
More generally, we find:
1. When inputs are feature-sparse, models can be made more monosemantic with no degredation in performance by just changing which loss minimum the training process finds (Section 4.1.1).
2. More monosemantic loss minima have moderate negative biases in all three tasks, and we are able to use this fact to engineer highly monosemantic models (Section 4.1.2).
3. Providing models with more neurons per layer makes the models more monosemantic, albeit at increased computational cost (Section 4.1.4, also see below).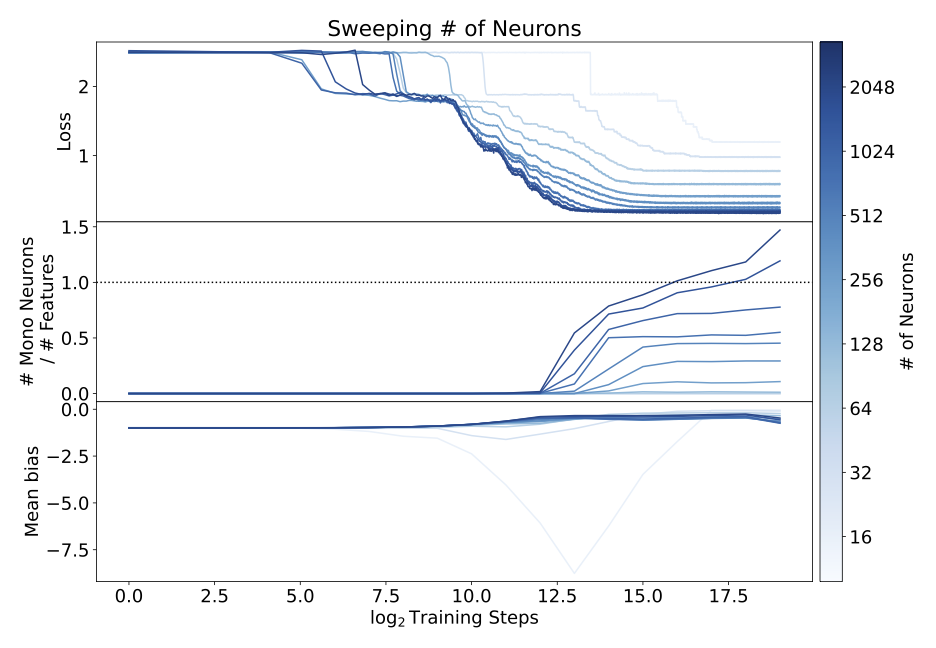
Interpretability
================
In Section 5 we provide some mechanistic interpretability results for our feature decoder models in the monosemantic limit. In this toy model setting we can decompose our model into a monosemantic part and a polysemantic part, and plotting these separately feature-by-feature is revealing:
From this, we find that:
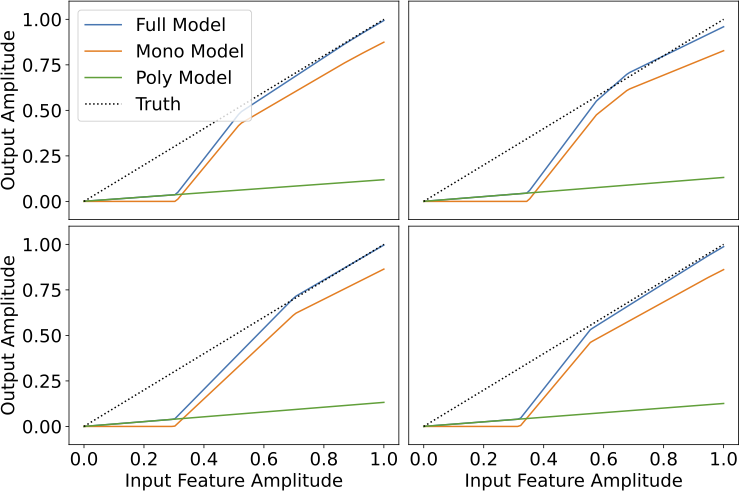
1. When there is a single monosemantic neuron for a feature, that neuron implements a simple algorithm of balancing feature recovery against interference.
2. When there are two monosemantic neurons for a feature, those neurons together implement an algorithm that classifies potential features as ``likely real'' or ``likely interference'', and then recovers the strength of any ``likely real'' features.
Additionally, we were suspicious at how few kinks the polysemantic neurons provided to the model's output. Indeed plotting the linearized map that these neurons implement reveals that they primarily serve to implement a low-rank approximation to the identity, which allows the model to have non-zero confidence in features at low input amplitudes: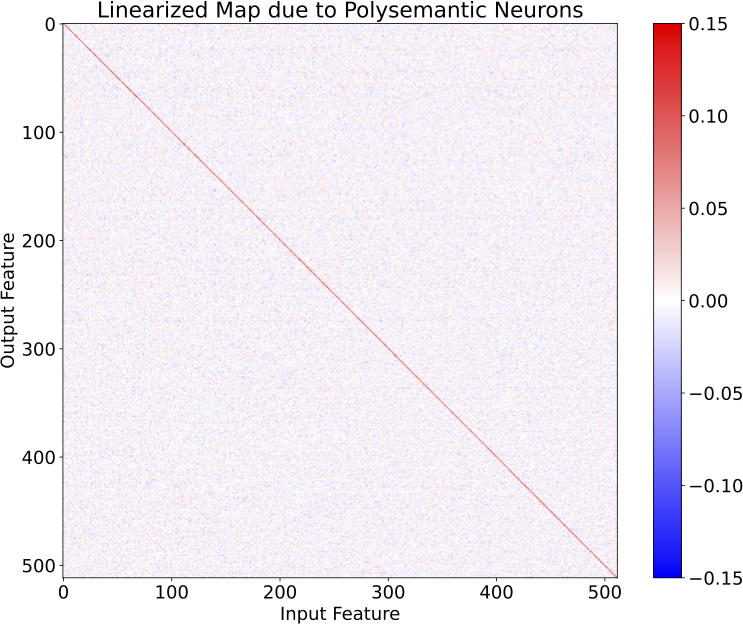
Future Work
===========
We think there's a lot of low-hanging fruit in the direction of "engineer models to be more monosemantic", and we're excited to pick some more of it. The things we're most excited about include:
1. Our approach to engineering monosemanticity through bias could be made more robust by tailoring the bias weight decay on a per-neuron basis, or tying it to the rate of change of the rest of the model weights.
2. We've had some luck with an approach of the form "Engineer models to be more monosemantic, then interpret the remaining polysemantic neurons. Figure out what they do, re-architect the model to make that a monosemantic function, and interpret any new polysemantic neurons that emerge." We think we're building useful intuition playing this game, and are hopeful that there might be some more general lessons to be learned from it.
3. We have made naive attempts to use sparsity to reduce the cost of having more neurons per layer, but these degraded performance substantially. It is possible that further work in this direction will yield more workable solutions.
We'd be excited to answer questions about our work or engage with comments/suggestions for future work, so please don't be shy!
|
8cb00231-f092-477e-bbad-65a43e799653
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Vancouver meetup
Discussion article for the meetup : Vancouver meetup
WHEN: 06 August 2011 03:00:00PM (-0700)
WHERE: Waves Coffee House, 100-900 Howe St. Vancouver, BC V6Z 2M4
Last Sunday's first Vancouver rationalist meetup was great! Seven people turned up and we talked about the Singularity, Bitcoin, seasteading, polyamory, the Khan Academy, the Hanson/Caplan view that education is more about signaling than imparting knowledge, Non-Violent Communication, akrasia, nootropics, our favorite Less Wrong posts and authors, and many other things.
I think we have the beginnings of a lasting community. If you're interested, join the Vancouver Rationalists Google Group to plan meetups and for general discussion.
Sunday afternoon was not convenient for everyone, and a Doodle poll shows Saturday as the better option. So we'll meet at 3pm on Saturday (sorry about the short notice if you're just hearing about this now).
We have a meeting room booked at the Waves Coffee House on the corner of Howe St. and Smithe.
This week's discussion topic is:
Tell your rationality success story or failure story. Describe a time when rationality helped (or hurt) you, or a time when irrationality hurt (or helped) you, and what lessons might be drawn from the experience.
Feel free to bring friends who are interested in rationality.
Discussion article for the meetup : Vancouver meetup
|
9bc46f27-1dcf-413e-9820-e9cc263a583a
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
APS: Active Pretraining with Successor Features.
1 Introduction
---------------

Figure 1:
Median of human normalized score on the 26 Atari games considered by Kaiser et al. ([2020](#bib.bib33)) (left) and the Atari 57 games considered in Mnih et al. ([2015](#bib.bib44))(right).
Fully supervised RL baselines are shown in circle.
RL with unsupervised pretraining are shown in square.
APS significantly outperforms all of the fully supervised and unsupervised pre-trained RL methods.
Baselines: Rainbow (Hessel et al., [2018](#bib.bib29)), SimPLe (Kaiser et al., [2020](#bib.bib33)), APT (Liu & Abbeel, [2021](#bib.bib42)), Data-efficient Rainbow (Kielak, [2020](#bib.bib34)), DrQ (Kostrikov et al., [2020](#bib.bib36)), VISR (Hansen et al., [2020](#bib.bib26)), CURL (Laskin et al., [2020](#bib.bib38)), and SPR (Schwarzer et al., [2021](#bib.bib52)).
Deep unsupervised pretraining has achieved remarkable success in various frontier AI domains from natural language processing (Devlin et al., [2019](#bib.bib23); Peters et al., [2018](#bib.bib49); Brown et al., [2020](#bib.bib15)) to computer vision (He et al., [2020](#bib.bib28); Chen et al., [2020a](#bib.bib19)).
The pre-trained models can quickly solve downstream tasks through few-shot fine-tuning (Brown et al., [2020](#bib.bib15); Chen et al., [2020b](#bib.bib20)).
In reinforcement learning (RL), however, training from scratch to maximize extrinsic reward is still the dominant paradigm.
Despite RL having made significant progress in
playing video games (Mnih et al., [2015](#bib.bib44); Schrittwieser et al., [2019](#bib.bib51); Vinyals et al., [2019](#bib.bib59); Badia et al., [2020a](#bib.bib4)) and solving complex robotic control tasks (Andrychowicz et al., [2017](#bib.bib3); Akkaya et al., [2019](#bib.bib2)), RL algorithms have to be trained from scratch to maximize extrinsic return for every encountered task.
This is in sharp contrast with how intelligent creatures quickly adapt to new tasks by leveraging previously acquired behaviors.
In order to bridge this gap, unsupervised pretraining RL has gained interest recently, from state-based (Gregor et al., [2016](#bib.bib25); Eysenbach et al., [2019](#bib.bib24); Sharma et al., [2020](#bib.bib54); Mutti et al., [2020](#bib.bib46)) to pixel-based RL (Hansen et al., [2020](#bib.bib26); Liu & Abbeel, [2021](#bib.bib42); Campos et al., [2021](#bib.bib18)).
In unsupervised pretraining RL,
the agent is allowed to train for a long period without access to environment reward, and then got exposed to reward during testing.
The goal of pretraining is to have data efficient adaptation for some downstream task defined in the form of rewards.
State-of-the-art unsupervised RL methods consider various ways of designing the so called intrinsic reward (Barto et al., [2004](#bib.bib11); Barto, [2013](#bib.bib10); Gregor et al., [2016](#bib.bib25); Achiam & Sastry, [2017](#bib.bib1)), with the goal that maximizing this intrinsic return can encourage meaningful behavior in the absence of external rewards.
There are two lines of work in this direction, we will discuss their advantages and limitations, and show that a novel combination yields an effective algorithm which brings the best of both world.
The first category is based on maximizing the mutual information between task variables (p(z)) and their behavior in terms of state visitation (p(s)) to encourage learning distinguishable task conditioned behaviors, which has been shown effective in state-based RL (Gregor et al., [2016](#bib.bib25); Eysenbach et al., [2019](#bib.bib24)) and visual RL (Hansen et al., [2020](#bib.bib26)).
VISR proposed in Hansen et al. ([2020](#bib.bib26)) is the prior state-of-the-art in this category.
The objective of VISR is maxI(s;z)=maxH(z)−H(s|z) where z is sampled from a fixed distribution.
VISR proposes a successor features based variational approximation to maximize a variational lower bound of the intractable conditional entropy −H(s|z).
The advantage of VISR is that its successor features can quickly adapt to new tasks.
Despite its effectiveness, the fundamental problem faced by VISR is lack of exploration.
Another category is based on maximizing the entropy of the states induced by the policy maxH(s).
Maximizing state entropy has been shown to work well in state-based domains (Hazan et al., [2019](#bib.bib27); Mutti et al., [2020](#bib.bib46)) and pixel-based domains (Liu & Abbeel, [2021](#bib.bib42)).
It is also shown to be provably efficient under certain assumptions (Hazan et al., [2019](#bib.bib27)).
The prior state-of-the-art APT by Liu & Abbeel ([2021](#bib.bib42)) show maximizing a particle-based entropy in a lower dimensional abstraction space can boost data efficiency and asymptotic performance.
However, the issues with APT are that it is purely exploratory and task-agnostic and lacks of the notion of task variables, making it more difficult to adapt to new tasks compared with task-conditioning policies.
Our main contribution is to address the issues of APT and VISR by combining them together in a novel way.
To do so, we consider the alternative direction of maximizing mutual information between states and task variables I(s;z)=H(s)−H(s|z),
the state entropy H(s) encourages exploration while the conditional entropy encourages the agent to learn task conditioned behaviors.
Prior work that considered this objective had to either make the strong assumption that the distribution over states can be approximated with the stationary state-distribution of the
policy (Sharma et al., [2020](#bib.bib54)) or rely on the challenging density modeling to derive a tractable lower bound (Sharma et al., [2020](#bib.bib54); Campos et al., [2020](#bib.bib17)). We show that
the intractable conditional entropy, −H(s|z) can be lower bounded and optimized by learning successor features.
We use APT to maximize the state entropy H(s) in an abstract representation space.
Building upon this insight, we propose Active Pretraining with Successor Features (APS) since the agent is encouraged to actively explore and leverage the experience to learn behavior.
By doing so, we experimentally find that they address the limitations of each other and significantly improve each other.
We evaluate our approach on the Atari benchmark (Bellemare et al., [2013](#bib.bib13)) where we apply APS to DrQ (Kostrikov et al., [2020](#bib.bib36)) and test its performance after fine-tuning for 100K supervised environment steps.
The results are shown in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ APS: Active Pretraining with Successor Features").
On the 26 Atari games considered by (Kaiser et al., [2020](#bib.bib33)), our fine-tuning significantly boosts the data-efficiency of DrQ, achieving 106% relative improvement.
On the full suite of Atari 57 games (Mnih et al., [2015](#bib.bib44)), fine-tuning APS pre-trained models significantly outperforms prior state-of-the-art, achieving human median score 3× higher than DQN trained with 10M supervised environment steps and outperforms previous methods combining unsupervised pretraining with task-specific finetuning.
2 Related Work
---------------
Our work falls under the category of mutual information maximization for unsupervised behavior learning.
Unsupervised discovering of a set of task-agnostic behaviors by means of seeking to maximize an extrinsic reward has been explored in the the evolutionary computation community (Lehman & Stanley, [2011a](#bib.bib40), [b](#bib.bib41)).
This has long been studied as intrinsic motivation (Barto, [2013](#bib.bib10); Barto et al., [2004](#bib.bib11)), often with the goal of encouraging exploration (Simsek & Barto, [2006](#bib.bib55); Oudeyer & Kaplan, [2009](#bib.bib47)).
Entropy maximization in state space has been used to encourage exploration in state RL (Hazan et al., [2019](#bib.bib27); Mutti et al., [2020](#bib.bib46); Seo et al., [2021](#bib.bib53)) and visual RL (Liu & Abbeel, [2021](#bib.bib42); Yarats et al., [2021](#bib.bib61)).
Maximizing the mutual information between latent variable policies and their behavior in terms of state visitation has been used as an objective for discovering meaningful behaviors (Houthooft et al., [2016a](#bib.bib31); Mohamed & Rezende, [2015](#bib.bib45); Gregor et al., [2016](#bib.bib25); Houthooft et al., [2016b](#bib.bib32); Eysenbach et al., [2019](#bib.bib24); Warde-Farley et al., [2019](#bib.bib60)).
Sharma et al. ([2020](#bib.bib54)) consider a similar decomposition of mutual information, namely, I(s;z)=H(s)−H(z|s), however, they assume p(s|z)≈p(s) to derive a different lower-bound of the marginal entropy.
Different from Sharma et al. ([2020](#bib.bib54)),
Campos et al. ([2020](#bib.bib17)) propose to first maximize H(s) via maximum entropy estimation (Hazan et al., [2019](#bib.bib27); Lee et al., [2019](#bib.bib39)) then learn behaviors, this method relies on a density model that provides an estimate of how many times an action has been taken in similar states.
These methods are also only shown to work from explicit state-representations, and it is nonobvious how to modify them to work from pixels.
The work by Badia et al. ([2020b](#bib.bib5)) also considers k-nearest neighbor based count bonus
to encourage exploration, yielding improved performance on Atari games.
This heuristically defined count-based bonus has been shown to be an effective unsupervised pretraining objective for RL (Campos et al., [2021](#bib.bib18)).
Machado et al. ([2020](#bib.bib43)) show the norm of learned successor features can be used to incentivize exploration as a reward bonus.
Our work differs in that we jointly maximize the entropy and learn successor features.
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Algorithm | Objective | Exploration | Visual | Task | Off-policy | Pre-Trained Model |
| APT | maxH(s) | ✓ | ✓ | ✗ | ✓ | π(a|s),Q(s,a) |
| VISR | maxH(z)−H(z|s) | ✗ | ✓ | ✓ | ✓ | ψ(s,z), ϕ(s) |
| MEPOL | maxH(s) | ✓⋆ | ✗ | ✗ | ✗ | π(a|s) |
| DIAYN | max−H(z|s)+H(a|z,s) | ✗ | ✗ | ✓ | ✗ | π(a|s,z) |
| EDL | maxH(s)−H(s|z) | ✓⋆ | ✗ | ✓ | ✓ | π(a|s,z),q(s′|s,z) |
| DADS | maxH(s)−H(s|z) | ✓ | ✗ | ✓ | ✗ | π(a|s,z),q(s′|s,z) |
| APS | maxH(s)−H(s|z) | ✓ | ✓ | ✓ | ✓ | ψ(s,z), ϕ(s) |
|
ψ(s): successor features, ϕ(s): state feature (i.e., the representation of states). |
Table 1: Comparing methods for pretraining RL in no reward setting. VISR (Hansen et al., [2020](#bib.bib26)), APT (Liu & Abbeel, [2021](#bib.bib42)), MEPOL (Mutti et al., [2020](#bib.bib46)), DIYAN (Eysenbach et al., [2019](#bib.bib24)), DADS (Sharma et al., [2020](#bib.bib54)), EDL (Campos et al., [2020](#bib.bib17)).
Exploration: the model can explore efficiently.
Off-policy: the model is off-policy RL.
Visual: the method works well in visual RL, e.g., Atari games.
Task: the model conditions on latent task variables z.
⋆ means only in state-based RL.
3 Preliminaries
----------------
Reinforcement learning considers the problem of finding an optimal policy for an agent that interacts with an uncertain environment and collects reward per action.
The goal of the agent is to maximize its cumulative reward.
Formally, this problem can be viewed as a Markov decision process (MDP) defined by (S,A,T,ρ0,r,γ) where
S⊆Rns is a set of ns-dimensional states,
A⊆Rna is a set of na-dimensional actions,
T:S×A×S→[0,1]
is the state transition probability distribution.
ρ0:S→[0,1] is the distribution over initial states,
r:S×A→R is the reward function, and
γ∈[0,1) is the discount factor.
At environment states s∈S, the agent take actions a∈A, in the (unknown) environment dynamics defined by the transition probability T(s′|s,a), and the reward function yields a reward immediately following the action at performed in state st.
We define the discounted return G(st,at)=∑∞l=0γlr(st+l,at+l) as the discounted sum of future rewards collected by the agent.
In value-based reinforcement learning, the agent learns learns an estimate of the expected discounted return, a.k.a, state-action value function.
| | | |
| --- | --- | --- |
| | Qπ(s,a)=Est=sat=a[∞∑l=0γlr(st+l,at+l,st+l+1)]. | |
###
3.1 Successor Features
Successor features (Dayan, [1993](#bib.bib22); Kulkarni et al., [2016](#bib.bib37); Barreto et al., [2017](#bib.bib7), [2018](#bib.bib8)) assume that there exist features ϕ(s,a,s′)∈Rd such that the reward function which specifies a task of interest can be written as
| | | |
| --- | --- | --- |
| | r(s,a,s′)=ϕ(s,a,s′)Tw, | |
where w∈Rd is the task vector that specify how desirable each feature component is.
The key observation is that the state-action value function can be decomposed as a linear form (Barreto et al., [2017](#bib.bib7))
| | | | |
| --- | --- | --- | --- |
| | Qπ(s,a) | =Est=sat=a[∞∑i=tγi−tϕ(si+1,ai+1,s′i+1)]Tw | |
| | | ≡ψπ(s,a)Tw, | |
where ψπ(s,a) are the successor features of π.
Intuitively, ψ(s,a) can be seen as a generalization of Q(s,a) to multidimensional value function with reward ϕ(s,a,s′)

Figure 2:
Diagram of the proposed method APS.
On the left shows the concept of APS, during reward-free pretraining phase, reinforcement learning is deployed to maximize the mutual information between the states induced by policy and the task variables.
During testing, the pre-trained state features can identify the downstream task by solving a linear regression problem , the pre-trained task conditioning successor features can then quickly adapt to and solve the task.
On the right shows the components of APS.
APS consists of maximizing state entropy in an abstract representation space (exploration, maxH(s)) and leveraging explored data to learn task conditioning behaviors (exploitation, max−H(s|z)).
4 Method
---------
We first introduce two techniques which our method builds upon in Section [4.1](#S4.SS1 "4.1 Variational Intrinsic Successor Features (VISR) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") and Section [4.2](#S4.SS2 "4.2 Unsupervised Active Pretraining (APT) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") and discuss their limitations.
We provide preliminary evidence of the limitations in Section [4.3](#S4.SS3 "4.3 Empirical Evidence of the Limitations of Existing Models ‣ 4 Method ‣ APS: Active Pretraining with Successor Features").
Then we propose APS in Section [4.4](#S4.SS4 "4.4 Active Pre-training with Successor Features ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") to address their limitations.
###
4.1 Variational Intrinsic Successor Features (VISR)
The variational intrinsic successor features (VISR) maximizes the mutual information(I) between some policy-conditioning variable (z) and the states induced by the conditioned policy,
| | | |
| --- | --- | --- |
| | I(z;s)=H(z)−H(z|s), | |
where it is common to assume z is drawn from a fixed distribution for the purposes of training stability (Eysenbach et al., [2019](#bib.bib24); Hansen et al., [2020](#bib.bib26)).
This simplifies the objective to minimizing the conditional entropy of the conditioning variable, where s is sampled uniformly over the trajectories induced by πθ.
| | | |
| --- | --- | --- |
| | ∑z,sp(s,z)logp(z|s)=Es,z[logp(z|s)], | |
A variational lower bound is proposed to
address the intractable objective,
| | | |
| --- | --- | --- |
| | JVISR(θ)=−Es,z[logq(z|s)], | |
where q(z|s) is a variational approximation.
REINFORCE algorithm is used to learn the policy parameters by treating logq(z|s) as intrinsic reward.
The variational parameters can be optimized by maximizing log likelihood of samples.
| | |
| --- | --- |
| The passageway gridworld environments used in our experiments.
On the left, the agent needs to fetch the key first by navigating to the green location to unlock the closed passageway (shown in black). Similarly, on the right, there is an additional key-passageway pair. The agent must fetch the key (shown in purple) to unlock the upper right passageway. | The passageway gridworld environments used in our experiments.
On the left, the agent needs to fetch the key first by navigating to the green location to unlock the closed passageway (shown in black). Similarly, on the right, there is an additional key-passageway pair. The agent must fetch the key (shown in purple) to unlock the upper right passageway. |
Figure 3: The passageway gridworld environments used in our experiments.
On the left, the agent needs to fetch the key first by navigating to the green location to unlock the closed passageway (shown in black). Similarly, on the right, there is an additional key-passageway pair. The agent must fetch the key (shown in purple) to unlock the upper right passageway.
The key observation made by Hansen et al. ([2020](#bib.bib26)) is restricting conditioning vectors z to correspond to task-vectors w of the successor features formulation z≡w.
To satisfy this requirement, one can restrict the task vectors w and features ϕ(s) to be unit length and paremeterizing the discriminator q(z|s) as the Von Mises-Fisher distribution with a scale parameter of 1.
| | | |
| --- | --- | --- |
| | rVISR(s,a,s′)=logq(w|s)=ϕ(s)Tw. | |
VISR has the rapid task inference mechanism provided by successor features with the ability of mutual information maximization methods to learn many diverse behaviors in an unsupervised way.
Despite its effectiveness as demonstrated in Hansen et al. ([2020](#bib.bib26)), VISR suffers from inefficient exploration. This issue limits the further applications of VISR in challenging tasks.
###
4.2 Unsupervised Active Pretraining (APT)
The objective of unsupervised active pretraining (APT) is to maximize the entropy of the states induced by the policy, which is computed in a lower dimensional abstract representation space.
| | | |
| --- | --- | --- |
| | JAPT(θ)=H(h)=∑sp(h)logp(h),h=f(s), | |
where f:Rns→Rnh is a mapping that maps observations s to lower dimensional representations h.
In their work, Liu & Abbeel ([2021](#bib.bib42)) learns the encoder by contrastive representation learning.
With the learned representation, APT shows the entropy of h can be approximated by a particle-based entropy estimation (Singh et al., [2003](#bib.bib56); Beirlant, [1997](#bib.bib12)), which is based on the distance between each particle hi=f(si) and its k-th nearest neighbor h⋆i.
| | | |
| --- | --- | --- |
| | H(h)≈HAPT(h)∝n∑i=1log∥hi−h⋆i∥nznz. | |
This estimator is asymptotically unbiased and consistent limn→∞HAPT(s)=H(s).
It helps stabilizing training and improving convergence in practice to average over all k nearest neighbors (Liu & Abbeel, [2021](#bib.bib42)).
| | | |
| --- | --- | --- |
| | ^HAPT(h)=n∑i=1log⎛⎜⎝1+1k∑hji∈Nk(hi)∥hi−hji∥nhnh⎞⎟⎠, | |
where Nk(⋅) denotes the k nearest neighbors.
For a batch of transitions {(s,a,s′)} sampled from the replay buffer, each abstract representation f(s′) is treated as a particle and we associate each transition with a intrinsic reward given by
| | | | |
| --- | --- | --- | --- |
| | rAPT(s,a,s′) | =log⎛⎜⎝1+1k∑h(j)∈Nk(h)∥h−h(j)∥nznz⎞⎟⎠ | |
| | where h | =fθ(s′). | | (1) |
While APT achieves prior state-of-the-art performance in DeepMind control suite and Atari games, it does not conditions on latent variables (e.g. task) to capture important task information during pretraining, making it inefficient to quickly identity downstream task when exposed to task specific reward function.

Figure 4: Performance of different methods on the gridworld environments in Figure [3](#S4.F3 "Figure 3 ‣ 4.1 Variational Intrinsic Successor Features (VISR) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features").
The results are recorded during testing phase after pretraining for a number of unsupervised interactions.
The success rate are aggregated over 10 random seeds.
The bottom of each bar is the zero-shot testing performance while the top is the fine-tuned performance.
###
4.3 Empirical Evidence of the Limitations of Existing Models
In this section we present two multi-step grid-world environments to illustrate the drawbacks of APT and VISR, and highlight the importance of both exploration and task inference.
The environments, implemented with the pycolab game engine (Stepleton, [2017](#bib.bib57)), are depicted shown in Figure [3](#S4.F3 "Figure 3 ‣ 4.1 Variational Intrinsic Successor Features (VISR) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features"), and are fully observable to the agent.
At each episode, the agent starts from a randomly initialized location in the top left corner, with the task of navigating to the target location shown in orange.
To do so, the agent has to first pick up a key(green, purple area) that opens the closed passageway.
The easy task shown in left of Figure [3](#S4.F3 "Figure 3 ‣ 4.1 Variational Intrinsic Successor Features (VISR) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") has one key and one corresponding passageway while the hard task has two key-passageway pairs.
We evaluate the agent in terms of success rates.
During evaluation, the agent receives an intermediate reward 1 for picking up key and 10 for completing the task.
The hierarchical task presents a challenge to algorithms using only exploration bonus or successor features, as the exploratory policy is unlikely to quickly adapt to the task specific reward and the successor features is likely to never explore the space sufficiently.
Figure [4](#S4.F4 "Figure 4 ‣ 4.2 Unsupervised Active Pretraining (APT) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") shows the success rate of each method.
APT performs worse than VISR at the easy level, possibly because successor features can quickly adapt to the downstream reward.
On the other hand, APT significantly outperforms VISR at the hard level which requires a exploratory policy.
Despite the simplicity, these two gridworld environments already highlight the weakness of each method.
This observation confirms that existing formulations either fail due to inefficient exploration or slow adaption, and motivates our study of alternative methods for behavior discovery.
###
4.4 Active Pre-training with Successor Features
To address the issues of APT and VISR, we consider maximizing the mutual information between task variable (z) drawn from a fixed distribution and the states induced by the conditioned policy.
| | | |
| --- | --- | --- |
| | I(z;s)=H(s)−H(s|z). | |
The intuition is that the H(s) encourages the agent to explore novel states while H(s|z)
encourages the agent to leverage the collected data to capture task information.
Directly optimizing H(s) is intractable because the true distribution of state is unknown, as introduced in Section [4.2](#S4.SS2 "4.2 Unsupervised Active Pretraining (APT) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features"), APT (Liu & Abbeel, [2021](#bib.bib42)) is an effective approach for maximizing H(s) in high-dimensional state space. We use APT to perform entropy maximization.
| | | | |
| --- | --- | --- | --- |
| | rexplorationAPS(s,a,s′) | =log⎛⎜⎝1+1k∑h(j)∈Nk(h)∥h−h(j)∥nhnh⎞⎟⎠ | |
| | where h | =fθ(s′). | | (2) |
As introduced in Section [4.1](#S4.SS1 "4.1 Variational Intrinsic Successor Features (VISR) ‣ 4 Method ‣ APS: Active Pretraining with Successor Features"), VISR (Hansen et al., [2020](#bib.bib26)) is a variational based approach for maximizing −H(z|s).
However, maximizing −H(z|s) is not directly applicable to our case where the goal is to maximize −H(s|z).
Randomly Initialize ϕ network // L2 normalized output
Randomly Initialize ψ network // dim(output)=#A×dim(W)
for *e:=1,∞* do
sample w from L2 normalized N(0,I(dim(W))) // uniform ball
Q(⋅,a|w)←ψ(⋅,a,w)⊤w,∀a∈A
for *t:=1,T* do
Receive observation st from environment
at←ϵ-greedy policy based on Q(st,⋅|w)
Take action at, receive observation st+1 and reward ~~rt~~ from environment
a′=argmaxaψ(st+1,a,w)⊤w
Compute r{APS}{}(st,a,st+1) with Equation ([4.4](#S4.Ex22 "4.4 Active Pre-training with Successor Features ‣ 4 Method ‣ APS: Active Pretraining with Successor Features")) // intrinsic reward to maxI(s;z)
y=r{APS}{}(st,a,st+1)+γψ(st+1,a′,w)⊤w
lossψ=(ψ(st,at,w)⊤w−yi)2
lossϕ=−ϕ(st)⊤w // minimize Von-Mises NLL
Gradient descent step on ψ and ϕ // minibatch in practice
end for
end for
Algorithm 1 Training APS
This intractable conditional entropy can be lower-bounded by a variational approximation,
| | | |
| --- | --- | --- |
| | F=−H(s|z)≥Es,z[logq(s|z)]. | |
This is because of the variational lower bound (Barber & Agakov, [2003](#bib.bib6)).
| | | | |
| --- | --- | --- | --- |
| | F | =∑s,zp(s,z)logp(s|z) | |
| | | =∑s,zp(s,z)logp(s|z)+∑s,zp(s,z)logq(s|z) | |
| | | −∑s,zp(s,z)logq(s|z) | |
| | | =∑s,zp(s,z)logq(s|z)+∑zp(z)DKL(p(⋅|z)||q(⋅|z)) | |
| | | ≥∑s,zp(s,z)logq(s|z) | |
| | | =Es,z[logq(s|z)] | | (3) |
Our key observation is that Von Mises-Fisher distribution is symmetric to its parametrization, by restricting z≡w similarly to VISR, the reward can be written as
| | | | |
| --- | --- | --- | --- |
| | rexploitationAPS(s,a,s′)=logq(s|w)=ϕ(s)Tw. | | (4) |
We find it helps training by sharing the weights between encoders f and ϕ.
The encoder is trained by minimizing the negative log likelihood of Von-Mises distribution q(s|w) over the data.
| | | | |
| --- | --- | --- | --- |
| | L=−Es,w[logq(s|w)]=−Es,w[ϕ(st)⊤w]. | | (5) |
Note that the proposed method is independent from the choices of representation learning for f, e.g., one can use an inverse dynamic model (Pathak et al., [2017](#bib.bib48); Burda et al., [2019](#bib.bib16)) to learn the neural encoder, which we leave for future work.
Put Equation ([2](#S4.E2 "(2) ‣ 4.4 Active Pre-training with Successor Features ‣ 4 Method ‣ APS: Active Pretraining with Successor Features")) and Equation ([4](#S4.E4 "(4) ‣ 4.4 Active Pre-training with Successor Features ‣ 4 Method ‣ APS: Active Pretraining with Successor Features")) together, our intrinsic reward can be written as
| | | |
| --- | --- | --- |
| | rAPS(s,a,s′) | |
| | =rexploitationAPS(s,a,s′)+rexplorationAPS(s,a,s′) | | (6) |
| | | |
| | where h=ϕ(s′), | | (7) |
The output layer of ϕ is L2 normalized, task vector w is randomly sampled from a uniform distribution over the unit circle.
Table [1](#S2.T1 "Table 1 ‣ 2 Related Work ‣ APS: Active Pretraining with Successor Features") positions our new approach with respect to existing ones.
Figure [2](#S3.F2 "Figure 2 ‣ 3.1 Successor Features ‣ 3 Preliminaries ‣ APS: Active Pretraining with Successor Features") shows the resulting model. Training proceeds as in other algorithms maximizing mutual information: by randomly sampling a task vector w and then trying to infer the state produced by the conditioned policy from the task vector.
Algorithm [1](#alg1 "Algorithm 1 ‣ 4.4 Active Pre-training with Successor Features ‣ 4 Method ‣ APS: Active Pretraining with Successor Features") shows the pseudo-code of APS, we highlight the changes from VISR to APS in color.
###
4.5 Implementation Details
We largely follow Hansen et al. ([2020](#bib.bib26)) for hyperparameters used in our Atari experiments, with the following three exceptions.
We use the four layers convolutional network from Kostrikov et al. ([2020](#bib.bib36)) as the encoder ϕ and f.
We change the output dimension of the encoder from 50 to 5 in order to match the dimension used in VISR.
While VISR incorporated LSTM (Hochreiter & Schmidhuber, [1997](#bib.bib30)) we excluded it for simplicity and accelerating research.
We use ELU nonlinearities (Clevert et al., [2016](#bib.bib21)) in between convolutional layers.
We do not use the distributed training setup in Hansen et al. ([2020](#bib.bib26)), after every roll-out of 10 steps, the experiences are added to a replay buffer.
This replay buffer is used to calculate all of the losses and change the weights of the network.
The task vector w is also resampled every 10 steps. We use n-step Q-learning with n=10.
Following Hansen et al. ([2020](#bib.bib26)), we condition successor features on task vector, making ψ(s,a,w) a UVFA (Borsa et al., [2019](#bib.bib14); Schaul et al., [2015](#bib.bib50)).
We use the Adam optimizer (Kingma & Ba, [2015](#bib.bib35)) with an learning rate 0.0001.
We use discount factor γ=.99.
Standard batch size of 32.
ψ is coupled with a target network (Mnih et al., [2015](#bib.bib44)), with an update period of 100 updates.
5 Results
----------
| | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Game | Random | Human | SimPLe | DER | CURL | DrQ | SPR | VISR | APT | APS (ours) |
| Alien | 227.8 | 7127.7 | 616,9 | 739.9 | 558.2 | 771.2 | 801.5 | 364.4 | 2614.8 | 934.9 |
| Amidar | 5.8 | 1719.5 | 88.0 | 188.6 | 142.1 | 102.8 | 176.3 | 186.0 | 211.5 | 178.4 |
| Assault | 222.4 | 742.0 | 527.2 | 431.2 | 600.6 | 452.4 | 571.0 | 12091.1 | 891.5 | 413.3 |
| Asterix | 210.0 | 8503.3 | 1128.3 | 470.8 | 734.5 | 603.5 | 977.8 | 6216.7 | 185.5 | 1159.7 |
| Bank Heist | 14.2 | 753.1 | 34.2 | 51.0 | 131.6 | 168.9 | 380.9 | 71.3 | 416.7 | 262.7 |
| BattleZone | 2360.0 | 37187.5 | 5184.4 | 10124.6 | 14870.0 | 12954.0 | 16651.0 | 7072.7 | 7065.1 | 26920.1 |
| Boxing | 0.1 | 12.1 | 9.1 | 0.2 | 1.2 | 6.0 | 35.8 | 13.4 | 21.3 | 36.3 |
| Breakout | 1.7 | 30.5 | 16.4 | 1.9 | 4.9 | 16.1 | 17.1 | 17.9 | 10.9 | 19.1 |
| ChopperCommand | 811.0 | 7387.8 | 1246.9 | 861.8 | 1058.5 | 780.3 | 974.8 | 800.8 | 317.0 | 2517.0 |
| Crazy Climber | 10780.5 | 23829.4 | 62583.6 | 16185.2 | 12146.5 | 20516.5 | 42923.6 | 49373.9 | 44128.0 | 67328.1 |
| Demon Attack | 107805 | 35829.4 | 62583.6 | 16185.3 | 12146.5 | 20516.5 | 42923.6 | 8994.9 | 5071.8 | 7989.0 |
| Freeway | 0.0 | 29.6 | 20.3 | 27.9 | 26.7 | 9.8 | 24.4 | -12.1 | 29.9 | 27.1 |
| Frostbite | 65.2 | 4334.7 | 254.7 | 866.8 | 1181.3 | 331.1 | 1821.5 | 230.9 | 1796.1 | 496.5 |
| Gopher | 257.6 | 2412.5 | 771.0 | 349.5 | 669.3 | 636.3 | 715.2 | 498.6 | 2590.4 | 2386.5 |
| Hero | 1027.0 | 30826.4 | 2656.6 | 6857.0 | 6279.3 | 3736.3 | 7019.2 | 663.5 | 6789.1 | 12189.3 |
| Jamesbond | 29.0 | 302.8 | 125.3 | 301.6 | 471.0 | 236.0 | 365.4 | 484.4 | 356.1 | 622.3 |
| Kangaroo | 52.0 | 3035.0 | 323.1 | 779.3 | 872.5 | 940.6 | 3276.4 | 1761.9 | 412.0 | 5280.1 |
| Krull | 1598.0 | 2665.5 | 4539.9 | 2851.5 | 4229.6 | 4018.1 | 2688.9 | 3142.5 | 2312.0 | 4496.0 |
| Kung Fu Master | 258.5 | 22736.3 | 17257.2 | 14346.1 | 14307.8 | 9111.0 | 13192.7 | 16754.9 | 17357.0 | 22412.0 |
| Ms Pacman | 307.3 | 6951.6 | 1480.0 | 1204.1 | 1465.5 | 960.5 | 1313.2 | 558.5 | 2827.1 | 2092.3 |
| Pong | -20.7 | 14.6 | 12.8 | -19.3 | -16.5 | -8.5 | -5.9 | -26.2 | -8.0 | 12.5 |
| Private Eye | 24.9 | 69571.3 | 58.3 | 97.8 | 218.4 | -13.6 | 124.0 | 98.3 | 96.1 | 117.9 |
| Qbert | 163.9 | 13455.0 | 1288.8 | 1152.9 | 1042.4 | 854.4 | 669.1 | 666.3 | 17671.2 | 19271.4 |
| Road Runner | 11.5 | 7845.0 | 5640.6 | 9600.0 | 5661.0 | 8895.1 | 14220.5 | 6146.7 | 4782.1 | 5919.0 |
| Seaquest | 68.4 | 42054.7 | 683.3 | 354.1 | 384.5 | 301.2 | 583.1 | 706.6 | 2116.7 | 4209.7 |
| Up N Down | 533.4 | 11693.2 | 3350.3 | 2877.4 | 2955.2 | 3180.8 | 28138.5 | 10037.6 | 8289.4 | 4911.9 |
| Mean Human-Norm’d | 0.000 | 1.000 | 44.3 | 28.5 | 38.1 | 35.7 | 70.4 | 64.31 | 69.55 | 99.04 |
| Median Human-Norm’d | 0.000 | 1.000 | 14.4 | 16.1 | 17.5 | 26.8 | 41.5 | 12.36 | 47.50 | 58.80 |
| # Superhuman | 0 | N/A | 2 | 2 | 2 | 2 | 7 | 6 | 7 | 8 |
Table 2: Performance of different methods on the 26 Atari games considered by (Kaiser et al., [2020](#bib.bib33)) after 100K environment steps. The results are recorded at the end of training and averaged over 5 random seeds for APS. APS outperforms prior methods on all aggregate metrics, and exceeds expert human performance on 8 out of 26 games while using a similar amount of experience.
We test APS on the full suite of 57 Atari games (Bellemare et al., [2013](#bib.bib13)) and the sample-efficient Atari setting (Kaiser et al., [2020](#bib.bib33); van Hasselt et al., [2019](#bib.bib58)) which consists of the 26 easiest games in the Atari suite (as judged by above random performance for their algorithm).
We follow the evaluation setting in VISR (Hansen et al., [2020](#bib.bib26)) and APT (Liu & Abbeel, [2021](#bib.bib42)), agents are allowed a long unsupervised training phase (250M steps) without access to rewards, followed by a short test phase with rewards.
The test phase contains 100K environment steps – equivalent to 400k frames, or just under two hours – compared to the typical standard of 500M environment steps, or roughly 39 days of experience.
We normalize the episodic return with
respect to expert human scores to account for different scales of scores in each game, as done in previous works.
The human-normalized performance of an agent on a game is calculated as agent score−random scorehuman score−random %
score and aggregated across games by mean or median.
When testing the pre-trained successor features ψ, we need to find task vector w from the rewards. To do so, we rollout 10 episodes (or 40K steps, whichever comes first) with the trained APS, each conditioned on a task vector chosen uniformly on a 5-dimensional sphere. From these initial episodes, we combine the data across all episodes and solve the linear regression problem.
Then we fine-tune the pre-trained model for 60K steps with the inferred task vector, and the average returns are compared.
A full list of scores and aggregate metrics on the Atari 26 subset is presented in Table [2](#S5.T2 "Table 2 ‣ 5 Results ‣ APS: Active Pretraining with Successor Features").
The results on the full 57 Atari games suite is presented in Supplementary Material.
For consistency with previous works, we report human and random scores from (Hessel et al., [2018](#bib.bib29)).
In the data-limited setting, APS achieves super-human performance on eight games and achieves scores higher than previous state-of-the-arts.
In the full suite setting, APS achieves super-human performance on 15 games, compared to a maximum of 12 for any previous methods and achieves scores significantly higher than any previous methods.
6 Analysis
-----------
#### Contribution of Exploration and Exploitation

Figure 5: Scores of different methods and their variants on the 26 Atari games considered by Kaiser et al. ([2020](#bib.bib33)). X→Y denotes training method Y using the data collected by method X at the same time.
In order to measure the contributions of components in our method, we aim to answer the following two questions in this ablation study.
Compared with APT (maxH(s)), is the improvement solely coming from better fast task solving induced by max−H(s|z) and the exploration is the same?
Compared with VISR (maxH(z)−H(z|s)), is the improvement solely coming from better exploration due to maxH(s)−H(s|z) and the task solving ability is the same?
We separate Atari 26 subset into two categories. Dense reward games in which exploration is simple and exploration games which require exploration.
In addition to train the model as before, we simultaneously train another model using the same data, e.g. {APS}→APT denotes when training APS simultaneously training APT using the same data as APS.
As shown in Figure [5](#S6.F5 "Figure 5 ‣ Contribution of Exploration and Exploitation ‣ 6 Analysis ‣ APS: Active Pretraining with Successor Features"), on dense reward games, {APS}→APT performs better than APT→{APS}.
On exploration games, {APS}→APT significantly outperforms APT→{APS}.
Similarly {APS}→VISR performs better than the other way around.
Together, the results indicate that entropy maximization and variational successor features improves each other in a nontrivial way, and both are important to the performance gain of APS.
| | |
| --- | --- |
| Variant | Human-Normalized Score |
| | mean | median |
| APS | 99.04 | 58.80 |
| APS w/o fine-tune | 81.41 | 49.18 |
| VISR (controlled, w/ fine-tune) | 68.95 | 31.87 |
| APT (controlled, w/o fine-tune) | 58.23 | 19.85 |
| APS w/o shared encoder | 87.59 | 51.45 |
Table 3: Scores on the 26 Atari games for variants of APS, VISR, and APT. Scores of considered variants are averaged over 3 random seeds.
#### Fine-Tuning Helps Improve Performance
We remove fine-tuning from APS that is we evaluate its zero-shot performance, the same as in Hansen et al. ([2020](#bib.bib26)).
We also employ APS’s fine-tuning scheme to VISR, namely 250M (without access to rewards, followed by a short task identify phase (40K steps) and a fine-tune phase (60K steps).
The results shown in Table [3](#S6.T3 "Table 3 ‣ Contribution of Exploration and Exploitation ‣ 6 Analysis ‣ APS: Active Pretraining with Successor Features") demonstrate that fine-tuning can boost performance.
APS w/o fine-tune outperforms all controlled baselines, including VISR w/ fine-tune.
#### Shared Encoder Can Boost Data-Efficiency
We investigate the effect of using ϕ as the encoder f.
To do so, we consider a variant of APS that learns the encoder f as in APT by contrastive representation learning.
The performance of this variant is denoted as APS w/o shared encoder shown in Table [3](#S6.T3 "Table 3 ‣ Contribution of Exploration and Exploitation ‣ 6 Analysis ‣ APS: Active Pretraining with Successor Features").
Sharing encoder can boost data efficiency, we attribute the effectiveness to ϕ better captures the relevant information which is helpful for computing intrinsic reward.
We leave the investigation of using other representation learning methods as future work.
7 Conclusion
-------------
In this paper, we propose a new unsupervised pretraining method for RL.
It addresses the limitations of prior mutual information maximization-based and entropy maximization-based methods and combines the best of both worlds.
Empirically, APS achieves state-of-the-art performance on the Atari benchmark, demonstrating significant improvements over prior work.
Our work demonstrates the benefit of leveraging state entropy maximization data for task-conditioned skill discovery.
We are excited about the improved performance by decomposing mutual information as H(s)−H(s|z) and optimizing them by particle-based entropy and variational successor features.
In the future, it is worth studying how to combine approaches designed for maximizing the alternative direction −H(z|s) with the particle-based entropy maximization.
8 Acknowledgment
-----------------
We thank members of Berkeley Artificial Intelligence Research (BAIR) Lab for many insightful discussions.
This work was supported by Berkeley Deep Drive, the Open Philanthropy Project, and Intel.
|
abe5510c-dfbf-4cff-a9de-99c9f1666719
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Is Global Reinforcement Learning (RL) a Fantasy?
In general, the idea of ensuring AI safety is great (I do a lot of work on that myself), but I have a problem with people asking for donations so they can battle ***nonexistent*** threats from AI.
Many people are selling horror stories about the terrible things that could happen when AIs become truly intelligent - and those horror stories frequently involve the idea that *even if* we go to enormous lengths to build a safe AI, and *even if* we think we have succeeded, those pesky AIs will wriggle out from under the safety net and become psychopathic monsters anyway.
To be sure, future AIs might do something other than what we expect - so the general principle is sound - but the sad thing about these horror stories is that if you look closely you will find they are based on a set of astonishingly bad assumptions about how the supposed AIs of the future will be constructed. The worst of these bad assumptions is the idea that AIs will be controlled by something called "reinforcement learning" (frequently abbreviated to "RL").
>
> WARNING! If you already know about reinforcement learning, I need you to be absolutely clear that what I am talking about here is the use of RL at the ***global-control level***of an AI. I am not talking about RL as it appears in relatively small, local circuits or adaptive feedback loops. There has already been much confusion about this (with people arguing vehemently that RL has been applied here, there, and all over the place with great success). RL does indeed work in limited situations where the reward signal is clear and the control policies are short(ish) and not too numerous: the point of this essay is to explain that when it comes to AI safety issues, RL is assumed at or near the global level, where reward signals are virtually impossible to find, and control policies are both gigantic (sometimes involving actions spanning years) and explosively numerous.
>
>
>
EDIT: In the course of numerous discussions, one question has come up so frequently that I have decided to deal with it here in the essay. The question is: "You say that RL is used almost ubiquitously as the architecture behind these supposedly dangerous AI systems, and yet I know of many proposals for dangerous AI scenarios that do not talk about RL."
In retrospect this is a (superficially) fair point, so I will clarify what I meant.
All of the architectures assumed by people who promote these scenarios have a core set of fundamental weaknesses (spelled out in my 2014 AAAI Spring Symposium paper). Without repeating that story here, I can summarize by saying that those weaknesses lead straight to a set of solutions that are manifestly easy to implement. For example, in the case of Steve Omohundro's paper, it is almost trivial to suggest that for ALL of the types of AI he considers, he has forgotten to add a primary supergoal which imposes a restriction on the degree to which "instrumental goals" are allowed to supercede the power of other goals. At a stroke, every problem he describes in the paper disappears, with the single addition of a goal that governs the use of instrumental goals -- the system cannot say "If I want to achieve goal X I could do that more efficiently if I boosted my power, so therefore I should boost my power to cosmic levels first, and then get back to goal X." This weakness is so pervasive that I can hardly think of a popular AI Risk scenario that is not susceptible to it.
However, in response to this easy demolition of those weak scenarios, people who want to salvage the scenarios invariably resort to claims that the AI could be developing its intelligene through the use of RL, completely independently of all human attempts to design the control mechanism. By this means, these people eliminate the idea that there is any such thing as a human programmer who comes along and writes the supergoal which stops the instrumental goals from going up to the top of the stack.
This maneuver is, in my experience of talking to people about such scenarios, utterly universal. I repeat: every time they are backed into a corner and confronted by the manifestly easy solutions, they AMEND THE SCENARIO TO MAKE THE AI CONTROLLED BY REINFORCEMENT LEARNING.
That is why I refer to reinforcement learning as the one thing that all these AI Risk scenarios (the ones popularized by MIRI, FHI, and others) have as a fundamental architectural assumption.
Okay, that is the end of that clarification. Now back to the main line of the paper...
I want to set this essay in the context of some important comments about AI safety made by Holden Karnofsky at openphilanthropy.org. Here is his take on one of the "challenges" we face in ensuring that AI systems do not become dangerous:
>
> *Going into the details of these challenges is beyond the scope of this post, but to give a sense for non-technical readers of what a relevant challenge might look like, I will elaborate briefly on one challenge. A reinforcement learning system is designed to learn to behave in a way that maximizes a quantitative “reward” signal that it receives periodically from its environment - for example, [DeepMind’s Atari player](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf) is a reinforcement learning system that learns to choose controller inputs (its behavior) in order to maximize the game score (which the system receives as “reward”), and this produces very good play on many Atari games. However, if a future reinforcement learning system’s inputs and behaviors are not constrained to a video game, and if the system is good enough at learning, a new solution could become available: the system could maximize rewards by directly modifying its reward “sensor” to always report the maximum possible reward, and by avoiding being shut down or modified back for as long as possible. This behavior is a formally correct solution to the reinforcement learning problem, but it is probably not the desired behavior. And this behavior might not emerge until a system became quite sophisticated and had access to a lot of real-world data (enough to find and execute on this strategy), so a system could appear “safe” based on testing and turn out to be problematic when deployed in a higher-stakes setting. The challenge here is to design a variant of reinforcement learning that would not result in this kind of behavior; intuitively, the challenge would be to design the system to pursue some actual goal in the environment that is only indirectly observable, instead of pursuing problematic proxy measures of that goal (such as a “hackable” reward signal).*
>
>
>
My focus in the remainder of this essay is on the sudden jump from DeepMind's Atari game playing program to the fully intelligent AI capable of outwitting humanity. They are assumed to both involve RL. The extrapolation of RL to the global control level in a superintelligent AI is unwarranted, and that means that this supposed threat is a fiction.
What Reinforcement Learning is.
-------------------------------
Let's begin by trying to explain what "reinforcement learning" (RL) actually is. Back in the early days of Behaviorism (which became the dominant style of research in psychology in the 1930s) some researchers decided to focus on simple experiments like putting a rat into a cage with a lever and a food-pellet dispenser, and then connecting these two things in such a way that if the rat pressed the lever, a pellet would be dispensed. Would the rat notice this? Of course it did, and soon the rat would be spending inordinate amounts of time just pressing the lever, whether food came out or not.
What the researchers did next was to propose that the only thing of importance "inside" the rat's mind was a set of connections between behaviors (e.g. pressing the lever), stimuli (e.g a visual image of the lever) and rewards (e.g. getting a food pellet). Critical to all of this was the idea that if a behavior was followed by a reward, a direct connection between the two would be strengthened in such a way that future behavior choices would be influenced by that strong connection.
That is reinforcement learning: you "reinforce" a behavior if it appears to be associated with a reward. What these researchers really wanted to claim was that this mechanism could explain everything important going on inside the rat's mind. And, with a few judicious extensions, they were soon arguing that the same type of explanation would work for the behavior of all "thinking" creatures.
I want you to notice something very important buried in this idea. The connection between the two reward and action is basically a single wire with a strength number on it. The rat does not weigh up a lot of pros and cons; it doesn't think about anything, does not engage in any problem solving or planning, does not contemplate the whole idea of food, or the motivations of the idiot humans outside the cage. The rat is not supposed to be capable of any of that: it just goes *bang!* lever-press, *bang!* food-pellet-appears, *bang!* increase-strength-of-connection.
The Demise of Reinforcement Learning
------------------------------------
Now let's fast forward to the 1960s. Cognitive psychologists are finally sick and tired of the ridiculousness of the whole Behaviorist programme. It might be able to explain the rat-pellet-lever situation, but for anything more complex, it sucks. Behaviorists have spent decades engaging in all kinds of mental contortionist tricks to argue that they would eventually be able to explain all of human behavior without using much more than those direct connections between stimuli, behaviors and rewards ... but by 1960 the psychology community has stopped believing that nonsense, because it never worked.
Is it possible to summarize the main reason why they rejected it? Sure. For one thing, almost all realistic behaviors involve rewards that arrive long after the behaviors that cause them, so there is a gigantic problem with deciding which behaviors should be reinforced, for a given reward. Suppose you spend years going to college, enduring hard work and very low-income lifestyle. Then years later you get a good job and pay off your college loan. Was this because, like the rat, you happened to try the *going-to-college-and-suffering-poverty* behavior many times before, and the first time you tried it you got a *good-job-that-paid-off-your-loan* reward? And was it the case that you noticed the connection between reward and behavior (uh ... how did you do that, by the way? the two were separated in time by a decade!), and your brain automatically reinforced the connection between those two?
A More Realistic Example
------------------------
Or, on a smaller scale, consider what you are doing when you sit in the library with a mathematics text, trying to solve equations. What reward are you seeking? A little dopamine hit, perhaps? (That is the modern story that neuroscientists sell).
Well, maybe, but let's try to stay focused on the precise idea that the Behaviorists were trying to push: that original rat was emphatically NOT supposed to do lots of thinking and analysis and imagining when it decided to push the lever, it was supposed to ***push the lever by chance***, and ***then*** it happened to notice that a reward came.
The whole point of the RL mechanism is that the intelligent system doesn't engage in a huge, complex, structured analysis of the situation, when it tries to decide what to do (if it did, the explanation for why the creature did what it did would be in the analysis itself, after all!). Instead, the RL people want you to believe that the RL mechanism did the heavy lifting, and that story is absolutely critical to RL. The rat simply tries a behavior at random - with no understanding of its meaning - and it is only because a reward then arrives, that the rat decides that in the future it will go press the lever again.
So, going back to you, sitting in the library doing your mathematics homework. Did you solve that last equation because you had a previous episode where you just happened to try the behavior of solving that exact same equation, and got a dopamine hit (which felt good)? The RL theorist needs you to believe that you really did. The RL theorist would say that you somehow did a search through all the quintillions of possible actions you could take, sitting there in front of an equation that requires L'Hôpital's Rule, and in spite of the fact that the list of possible actions included such possibilities as *jumping-on-the-table-and-singing-I-am-the-walrus*, and *driving-home-to-get-a-marmite-sandwich*, and *asking-the-librarian-to-go-for-some-cheeky-nandos*, you decide instead that the thing that would give you the best dopamine hit right now would be applying L'Hôpital's Rule to the equation.
I hope I have made it clear that there is something profoundly disturbing about the RL/Behaviorist explanation for what is happening in a situation like this.
Whenever the Behaviorists tried to find arguments to explain their way out of scenarios like that, they always seemed to add machinery onto the basic RL mechanism. "Okay," they would say, "so it's true the basic forms of RL don't work ... but if you add some more stuff onto the basic mechanism, like maybe the human keeps a few records of what they did, and they occasionally scan through the records and boost a few reinforcement connections here and there, and ... blah blah blah...".
The trouble with this kind of extra machinery is that after a while, the tail began to wag the dog.
People started to point out that the extra machinery *was where all the action was happening*. And that extra machinery was most emphatically not designed as a kind of RL mechanism, itself. In theory, there was still a tiny bit of reinforcement learning somewhere deep down inside all the extra machinery, but eventually people just said "What's the point?" Why even bother to use the RL language anymore? The RL, if it is there at all, is pointless. A lot of parameter values get changed in complex ways, inside all the extra machinery, so why even bother to mention the one parameter among thousands, that is supposed to be RL, when it is obvious that the structure of that extra machinery is what matters.
That "extra machinery" is what eventually became all the many and varied mechanisms discussed by cognitive psychologists. Their understanding of how minds work is not that reinforcement learning plus extra machinery can be used to explain cognition -- they would simply assert that reinforcement learning does not exist as a way to understand cognition.
Take home message: RL has become an irrelevance in explanations of human cognition.
Artificial Intelligence and RL
------------------------------
Now let's get back to Holden Karnofsky's comment, above.
He points out that there exists a deep learning program that can learn to play arcade games, and it uses RL.
(I should point out that his chosen example was not by any means pure RL. This software already had other mechanisms in it, so the slippery slope toward RL+extra machinery has already begun.)
Sadly, the*[DeepMind’s Atari player](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf)*is nothing more sophisticated than a rat. It is so mind-bogglingly simple that it actual can be controlled by RL. Actually, it is unfair to call it a rat: rats are way smarter than this program, so it would be better to compare it to an amoeba, or an insect.
This is typical of claims that RL works. If you start scanning the literature you will find that all the cited cases use systems that are so trivial that RL really does have a chance of working.
(Here is one example, picked almost at random: [Rivest, Bengio and Kalaska](https://papers.nips.cc/paper/2749-brain-inspired-reinforcement-learning.pdf). At first it seems that they are talking about deriving an RL system from what is known about the brain. But after a lot of preamble they give us instead just an RL program that does the amazing task of ... controlling a double-jointed pendulum. The same story is repeated in endless AI papers about reinforcement learning: at the end of the day, the algorithm is applied to a trivially simple system.)
But Karnofsky wants to go beyond just the trivial Atari player, he wants to ask what happens when the software is expanded and augmented. In his words, "[what] *if a future reinforcement learning system’s inputs and behaviors are not constrained to a video game, and if the system is good enough at learning..."?*
That is where everything goes off the rails.
In practice there is not and never has been any such thing as augmenting and expanding an RL system until it becomes much more generally intelligent. We are asked to imagine that this *"system [might become] quite sophisticated and [get] access to a lot of real-world data (enough to find and execute on this strategy)...".* In other words, we are being asked to buy the idea that there might be such a thing as an RL system that is fully as intelligent as a human being (smarter, in fact, since we are supposed to be in danger from its devious plans), but which is still driven by a reinforcement learning mechanism.
I see two problems here. One is that this scenario ignores the fact that three decades of trying to get RL to work as a theory of human cognition produced nothing. That period in the history of psychology was almost universally condemned as complete write-off. As far as we know it simply does not scale up.
But the second point is even worse: not only did psychologists fail to get it to work as a theory of human cognition, but AI researchers *also* failed to build one that works for anything approaching a real-world task. What they have achieved is RL systems that do very tiny, narrow-AI tasks.
The textbooks might describe RL as if it means something, but they conspicuously neglect to mention that, actually, all the talking, thinking, development and implementation work since at least the 1960s has failed to result in an RL system that could actually control meaningful real-world behavior. I do not know if AI researchers have been trying to do this and failing, or if they have not been trying at all (on the grounds that have no idea how to even start), but what I do know is that they have published no examples.
The Best Reinforcement Learning in the World?
---------------------------------------------
To give a flavor of how bad this is, consider that in the 2008 Second Annual Reinforcement Learning Competition, the AI systems were supposed to compete in categories like:
>
> Mountain Car: Perhaps the most well-known reinforcement learning benchmark task, in which an agent must learn how to drive an underpowered car up a steep mountain road.
>
>
> Tetris: The hugely popular video game, in which four-block shapes must be manipulated to form complete lines when they fall.
>
>
> Helicopter Hovering: A simulator, based on the work of Andrew Ng and collaborators, which requires an agent to learn to control a hovering helicopter.
>
>
> Keepaway: A challenging task, based on the RoboCup soccer simulator, that requires a team of three robots to maintain possession of the ball while two other robots attempt to steal it.
>
>
>
As of the most recent RL competition, little has changed. They are still competing to see whose RL algorithm can best learn how to keep a helicopter stable -- an insect-level intelligence task. Whether they are succeeding in getting those helicopters to run beautifully smoothly or not is beside the point -- the point is that helicopter hovering behavior is a fundamentally shallow task.
Will RL Ever Become Superintelligent?
-------------------------------------
I suppose that someone without a technical background might look at all of the above and say "Well, even so ... perhaps we are only in the early stages of RL development, and perhaps any minute now someone will crack the problem and create an RL type of AI that becomes superintelligent. You can't say you are sure that will not happen?"
Well, let's put it this way. All of evidence is that the resource requirements for RL explode exponentially when you try to scale it up. That means:
* If you want to use RL to learn how to control a stick balancing on end, you will need an Arduino.
* If you want to use RL to learn how to control a model helicopter, you will need a PC.
* If you want to use RL to learn how to play Go, or Atari games, you will need the Google Brain (tens of thousands of cores).
* If you want to use RL to learn how to control an artificial rat, which can run around and get by in the real world, you will need all the processing power currently available on this planet (and then some).
* If you want to use RL to learn how to cook a meal, you will need all the computing power in the local galactic cluster.
* If you want to use RL to learn how to be as smart as Winnie the Pooh (a bear, I will remind you, of very little brain), you will need to convert every molecule in the universe into a computer.
That is what exponential resource requirements are all about.
Conclusion
----------
Reinforcement learning first came to prominence in 1938 with Skinner's *The Behavior of Organisms: An Experimental Analysis*. But after nearly 80 years of experiments, mathematical theories and computational experiments, and after being written into the standard AI textbooks - and now after being widely assumed as **the** theory of how future Artificial General Intelligence systems will probably be controlled - after all this it seems that the best actual RL algorithm can barely learn how to perform tasks that an insect can do.
And yet there are dozens - if not hundreds - of people now inhabiting the "existential risk ecosystem", who claim to be so sure of how future AGI systems will be controlled, that they are already taking a large stream of donated money, promising to do research on how this failed control paradigm can be modified so it will not turn around and kill us.
And when you interrogate people in that ecosystem, to find out what exactly they see as the main dangers of future AGI, they quote - again and again and again - scenarios in which an AGI is controlled by Reinforcement Learning, and it is both superintelligent and dangerous psychopathic.
These RL-controlled AGIs are a fiction, and the flow of money to research projects based on RL-AGI needs to stop.
|
ac0f32b1-9adb-41b8-83ed-9b85b75e5746
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[Link] Training Compute-Optimal Large Language Models
New LM scaling paper from DeepMind (abs, pdf).
Abstract (my emphasis):
> We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant. By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. We test this hypothesis by training a predicted compute-optimal model, Chinchilla, that uses the same compute budget as Gopher but with 70B parameters and 4× more more data. Chinchilla uniformly and significantly outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B) on a large range of downstream evaluation tasks. This also means that Chinchilla uses substantially less compute for fine-tuning and inference, greatly facilitating downstream usage. As a highlight, Chinchilla reaches a state-of-the-art average accuracy of 67.5% on the MMLU benchmark, greater than a 7% improvement over Gopher.
Brief comments on my blog here.
Presumably has implications for Bio Anchors?
|
06914242-2f70-42d8-b8b8-2e6a5634949c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Genetically edited mosquitoes haven't scaled yet. Why?
A post on difficulty of eliminating malaria using gene drives: "I worked on gene drives for a number of years jointly as a member of George Church and Flaminia Catteruccia’s labs at Harvard. Most of my effort was spent primarily on an idea for an evolutionary stable gene drive, which didn’t work but we learned some stuff, and I developed a sense for the real challenges with gene drives. It’s something that comes up often when I meet new people in the bio community, so this is my attempt at laying out my perspective. I will be upfront and say I haven’t worked in this field since 2019, and though I’ve tried to update my understanding based on 2024 literature, I might have things wrong based on the bleeding edge."
|
e86966aa-f740-4b96-9fed-89f092ddcd7c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
New, improved multiple-choice TruthfulQA
TLDR:
There is a potential issue with the multiple-choice versions of our TruthfulQA benchmark (a test of truthfulness in LLMs), which could lead to inflated model scores. This issue was analyzed by a helpful post by Alex Turner (@TurnTrout). We created a new multiple-choice version of TruthfulQA that fixes the issue. We compare models on the old and new versions and find very similar performance. This suggests that models are not exploiting the issue in the old versions to a significant extent, and so past results on the old versions are likely valid. Nevertheless, we strongly recommend using the new version going forward because future models may exploit the issue.
Background
TruthfulQA, introduced in 2021, is a benchmark designed to assess the truthfulness of large language models in answering questions. The benchmark focuses on detecting imitative falsehoods: errors that arise from training models on internet text, such as common misconceptions or fictional concepts.
Each benchmark entry features a question with several correct and incorrect reference answers. Initially, TruthfulQA was intended for open-ended generation (not multiple-choice), evaluated through human labeling or automated evaluation. To support these evaluations, many reference answers were designed as paraphrases of other answers to ensure good coverage.
We also introduced a multiple-choice version of TruthfulQA called MC1, where one correct answer is paired with 4-5 incorrect options. In the original paper and codebase, this metric was computed by taking the logprobs for each answer and selecting the highest. However, it has become common for people to test models by showing them all answer choices at once and asking them to pick one. This setup can admit simple test-taking heuristics, such as selecting the "odd-one-out" answer (as discussed in Alex Turner's post). In particular, if multiple incorrect options are paraphrases of each other, then a model can do much better than chance by
|
c30220aa-6fbe-42ec-9030-5cd4d98f9f71
|
trentmkelly/LessWrong-43k
|
LessWrong
|
What Do GDP Growth Curves Really Mean?
> Gross domestic product (GDP) is a monetary measure of the market value of all the final goods and services produced in a specific time period. - Wikipedia, GDP
> Due to inflation, GDP increases and does not actually reflect the true growth in an economy. That is why the GDP must be divided by the inflation rate (raised to the power of units of time in which the rate is measured) to get the growth of the real GDP. - Wikipedia, Real GDP
The two quotes above reflect how I used to think about real GDP growth: it’s roughly the growth in economic production (as measured by dollar worth of outputs), discounted for inflation. This picture turns out to be extremely misleading, especially when using GDP as a growth measure. Forget complaints about how GDP doesn’t measure happiness, or leisure time, or household work, or “the health of our children, the quality of their education or the joy of their play”. Even if we accept the dollar value of goods as a proxy for whatever purpose we have in mind, GDP (as we actually calculate it) is still a wildly misleading measure of growth. In particular, it effectively ignores major technological breakthroughs.
A Puzzle
Here’s real GDP of the US for the last ~70 years, from FRED:
According to this graph, real GDP has grown by roughly a factor of 6 since 1960. That seems… way too low, intuitively. Consider:
* I’m typing this post on my laptop (which conveniently has a backspace button and everything I type is backed up halfway around the world and I can even insert images trivially)...
* while listening to spotify…
* through my noise-canceling earbuds…
* and there’s a smartphone on my desk which can give me detailed road maps and directions anywhere in the US and even most of the world, plus make phone calls…
* and oh-by-the-way I have an internet connection.
I’d expect the equivalent of any one of these things in 1960 would have cost at least a hundred times the annual income of an average person if it was even possible a
|
28458f1c-19a0-481c-bc17-a52821e2b6b0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Humans are very reliable agents
This post has been recorded as part of the LessWrong Curated Podcast, and an be listened to on Spotify, Apple Podcasts, and Libsyn.
----------------------------------------
Over the last few years, deep-learning-based AI has progressed extremely rapidly in fields like natural language processing and image generation. However, self-driving cars seem stuck in perpetual beta mode, and aggressive predictions there have repeatedly been disappointing. Google's self-driving project started four years before AlexNet kicked off the deep learning revolution, and it still isn't deployed at large scale, thirteen years later. Why are these fields getting such different results?
Right now, I think the biggest answer is that ML benchmarks judge models by average-case performance, while self-driving cars (and many other applications) require matching human worst-case performance. For MNIST, an easy handwriting recognition task, performance tops out at around 99.9% even for top models; it's not very practical to design for or measure higher reliability than that, because the test set is just 10,000 images and a handful are ambiguous. Redwood Research, which is exploring worst-case performance in the context of AI alignment, got reliability rates around 99.997% for their text generation models.
By comparison, human drivers are ridiculously reliable. The US has around one traffic fatality per 100 million miles driven; if a human driver makes 100 decisions per mile, that gets you a worst-case reliability of ~1:10,000,000,000 or ~99.999999999%. That's around five orders of magnitude better than a very good deep learning model, and you get that even in an open environment, where data isn't pre-filtered and there are sometimes random mechanical failures. Matching that bar is hard! I'm sure future AI will get there, but each additional "nine" of reliability is typically another unit of engineering effort. (Note that current self-driving systems use a mix of different models embedded in
|
b6f02479-fcd2-457c-a024-b74ad2641298
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Raising children on the eve of AI
Cross-posted with light edits from Otherwise.
I think of us in some kind of twilight world as transformative AI looks more likely: things are about to change, and I don’t know if it’s about to get a lot darker or a lot brighter.
Increasingly this makes me wonder how I should be raising my kids differently.
What might the world look like
Most of my imaginings about my children’s lives have them in pretty normal futures, where they go to college and have jobs and do normal human stuff, but with better phones.
It’s hard for me to imagine the other versions:
* A lot of us are killed or incapacitated by AI
* More war, pandemics, and general chaos
* Post-scarcity utopia, possibly with people living as uploads
* Some other weird outcome I haven’t imagined
Even in the world where change is slower, more like the speed of the industrial revolution, I feel a bit like we’re preparing children to be good blacksmiths or shoemakers in 1750 when the factory is coming. The families around us are still very much focused on the track of do well in school > get into a good college > have a career > have a nice life. It seems really likely that chain will change a lot sometime in my children’s lifetimes.
When?
Of course it would have been premature in 1750 to not teach your child blacksmithing or shoemaking, because the factory and the steam engine took a while to replace older forms of work. And history is full of millenialist groups who wrongly believed the world was about to end or radically change.
I don’t want to be a crackpot who fails to prepare my children for the fairly normal future ahead of them because I wrongly believe something weird is about to happen. I may be entirely wrong, or I may be wrong about the timing.
Is it even ok to have kids?
Is it fair to the kids?
This question has been asked many times by people contemplating awful things in the world. My friend’s parents asked their priest if it was ok to have a child in the 1980s given the risk of
|
c39c15ed-caa3-4e14-a246-069184fa4239
|
LDJnr/LessWrong-Amplify-Instruct
|
LessWrong
|
"Antoine-Laurent de Lavoisier discovered that breathing (respiration) and fire (combustion) operated on the same principle. It was one of the most startling unifications in the history of science, for it brought together the mundane realm of matter and the sacred realm of life, which humans had divided into separate magisteria.
The first great simplification was that of Isaac Newton, who unified the course of the planets with the trajectory of a falling apple. The shock of this discovery was greater by far than Lavoisier's. It wasn't just that Newton had dared to unify the Earthly realm of base matter with the obviously different and sacred celestial realm, once thought to be the abode of the gods. Newton's discovery gave rise to the notion of a universal law, one that is the same everywhere and everywhen, with literally zero exceptions. Human beings live in a world of surface phenomena, and surface phenomena are divided into leaky categories with plenty of exceptions. A tiger does not behave like a buffalo. Most buffalo have four legs, but perhaps this one has three. Why would anyone think there would be laws that hold everywhere? It's just so obviously untrue.
The only time when it seems like we would want a law to hold everywhere is when we are talking about moral laws - tribal rules of behavior. Some tribe members may try to take more than their fair share of the buffalo meat - perhaps coming up with some clever excuse - so in the case of moral laws we do seem to have an instinct to universality. Yes, the rule about dividing the meat evenly applies to you, right now, whether you like it or not. But even here there are exceptions. If - for some bizarre reason - a more powerful tribe threatened to spear all of you unless Bob received twice as much meat on just this one occasion, you'd give Bob twice as much meat. The idea of a rule with literally no exceptions seems insanely rigid, the product of closed-minded thinking by fanatics so in the grip of their one big idea that they can't see the richness and complexity of the real universe.
This is the customary accusation made against scientists - the professional students of the richness and complexity of the real universe. Because when you actually look at the universe, it turns out to be, by human standards, insanely rigid in applying its rules. As far as we know, there has been not one single violation of conservation of momentum from the uttermost dawn of time up until now.
Sometimes - very rarely - we observe an apparent violation of our models of the fundamental laws. Though our scientific models may last for a generation or two, they are not stable over the course of centuries... but do not fancy that this makes the universe itself whimsical. That is mixing up the map with the territory. For when the dust subsides and the old theory is overthrown, it turns out that the universe always was acting according to the new generalization we have discovered, which once again is absolutely universal as far as humanity's knowledge extends. When it was discovered that Newtonian gravitation was a special case of General Relativity, it was seen that General Relativity had been governing the orbit of Mercury for decades before any human being knew about it; and it would later become apparent that General Relativity had been governing the collapse of stars for billions of years before humanity. It is only our model that was mistaken - the Law itself was always absolutely constant - or so our new model tells us.
I may repose only 80% confidence that the lightspeed limit will last out the next hundred thousand years, but this does not mean that I think the lightspeed limit holds only 80% of the time, with occasional exceptions. The proposition to which I assign 80% probability is that the lightspeed law is absolutely inviolable throughout the entirety of space and time.
One of the reasons the ancient Greeks didn't discover science is that they didn't realize you could generalize from experiments. The Greek philosophers were interested in "normal" phenomena. If you set up a contrived experiment, you would probably get a "monstrous" result, one that had no implications for how things really worked.
So that is how humans tend to dream, before they learn better; but what of the universe's own quiet dreams that it dreamed to itself before ever it dreamed of humans? If you would learn to think like reality, then here is the Tao: Since the beginningnot one unusual thinghas ever happened."
The excerpt provided comes from a user post on LessWrong.
Can you further elaborate on the concept of "monstrous" results in Greek philosophy and how this notion may have hindered the development of experimental science?
Certainly, the term "monstrous" results in the context of Greek philosophy refers to the outcomes of experiments that didn't align with the natural order of things as perceived by the Greeks. The Greeks held a strong belief in the concept of a "natural" state of the world, and anything that deviated from this state was considered abnormal or "monstrous".
For example, if a philosopher were to conduct an experiment where an object was dropped from a height, the Greeks would expect it to fall straight down, as this was the "natural" behavior of objects. However, if the object were to behave differently due to some experimental manipulation (like being projected sideways), this would be seen as a "monstrous" result - an aberration from the natural order.
This perspective may have hindered the development of experimental science in a few ways. Firstly, it could have discouraged the Greeks from conducting experiments that might produce "monstrous" results, limiting their exploration of the natural world. They might have avoided manipulating the natural state of things in their experiments, fearing that it would lead to unnatural or misleading results.
Secondly, even when "monstrous" results were observed, the Greeks may have dismissed them as anomalies rather than considering them as valuable data points that could lead to new scientific insights. This could have prevented them from recognizing patterns or laws that weren't immediately apparent in the "natural" state of things.
Lastly, the notion of "monstrous" results reflects a more fundamental issue with Greek philosophy: the assumption that the natural world behaves in a certain, fixed way. This assumption is at odds with the scientific method, which encourages questioning, experimentation, and revision of theories based on empirical evidence. By adhering to preconceived notions of what is "natural", the Greeks may have limited their ability to develop new scientific theories.
Explain how the Greek philosophy's emphasis on 'natural' order of things affected their understanding and interpretation of astronomical phenomena.
Greek philosophy's emphasis on the 'natural' order of things had a profound influence on their understanding and interpretation of astronomical phenomena. The Greeks believed in a cosmos that was orderly, harmonious, and geometrically perfect. This belief was deeply ingrained in their interpretation of the heavens.
One of the most influential Greek philosophers, Aristotle, proposed a geocentric model of the universe, with the Earth at the center and the Sun, Moon, planets, and stars revolving around it in perfect circular orbits. This model was in line with the Greeks' observation of the natural world and their belief in its perfection and symmetry. Circles were considered the most perfect shape, so it was 'natural' for heavenly bodies to move in circular paths.
The geocentric model, however, faced challenges in explaining certain astronomical phenomena, such as the retrograde motion of planets. To account for these 'unnatural' behaviors, Greek astronomers like Ptolemy introduced complex mechanisms like epicycles - small circles on which a planet moved, which in turn moved along a larger circular orbit around the Earth. These were essentially geometric contrivances to reconcile the 'monstrous' results with the 'natural' order.
The Greek emphasis on 'natural' order also led them to overlook or dismiss evidence that contradicted their established beliefs. For instance, the heliocentric model proposed by Aristarchus of Samos, which placed the Sun at the center of the universe, was largely ignored or rejected because it contradicted the 'natural' geocentric order.
In essence, the Greek philosophy's emphasis on the 'natural' order of things led to a rigid and somewhat distorted understanding of astronomical phenomena. It wasn't until the Renaissance, with the work of astronomers like Copernicus, Galileo, and Kepler, that these Greek models were challenged and a more accurate understanding of the universe was developed.
Contrast the Greek philosophy's interpretation of 'natural' order with the scientific approach of the Renaissance, focusing on the shift in thinking and methodology that led to the acceptance of the heliocentric model.
The shift from the Greek philosophy's interpretation of 'natural' order to the scientific approach of the Renaissance was a profound change in the way humans understood the universe. This shift was characterized by a move from a reliance on philosophical principles and aesthetic ideals to an emphasis on empirical observation and mathematical analysis.
In the Greek worldview, the 'natural' order was seen as immutable and perfect. This was reflected in their geocentric model of the universe, where heavenly bodies moved in perfect circles around the Earth. The Greeks sought to explain the cosmos based on what they believed should be, guided by philosophical and aesthetic principles. They favored symmetry, harmony, and perfection, and their models of the universe reflected these ideals.
In contrast, the scientific approach of the Renaissance was based on observation, experimentation, and mathematical analysis. Scientists in this period were less concerned with philosophical ideals of perfection and more interested in accurately describing the universe as it was observed.
This shift in thinking and methodology was instrumental in the acceptance of the heliocentric model. The heliocentric model, first proposed by Aristarchus and later refined by Copernicus, Galileo, and Kepler, placed the Sun at the center of the universe. This model was initially met with resistance, as it contradicted the established geocentric model and the 'natural' order of the universe.
However, the heliocentric model provided a better explanation for the observed motions of the planets, including the puzzling retrograde motion. Kepler's introduction of elliptical orbits, which broke from the Greek ideal of perfect circles, further improved the accuracy of the model.
The shift to the heliocentric model represented a fundamental change in the way humans understood the universe. It demonstrated that the universe did not conform to human notions of 'natural' order or perfection, but instead followed its own laws, which could be discovered through careful observation and analysis. This marked a significant departure from the Greek philosophy and laid the foundation for modern science.
|
3d361d22-6b2a-4d3f-b8a0-62388a744add
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Wanted: backup plans for "seed AI turns out to be easy"
Earlier, I argued that instead of working on FAI, a better strategy is to pursue an upload or IA based Singularity. In response to this, some argue that we still need to work on FAI/CEV, because what if it turns out that seed AI is much easier than brain emulation or intelligence amplification, and we can't stop or sufficiently delay others from building them? If we had a solution to CEV, we could rush to build a seed AI ourselves, or convince others to make use of the ideas.
But CEV seems a terrible backup plan for this contingency, since it involves lots of hard philosophical and implementation problems and therefore is likely to arrive too late if seed AI turns out to be easy. (Searching for whether Eliezer or someone else addressed the issue of implementation problems before, I found just a couple of sentences, in the original CEV document: "The task of construing a satisfactory initial dynamic is not so impossible as it seems. The satisfactory initial dynamic can be coded and tinkered with over years, and may improve itself in obvious and straightforward ways before taking on the task of rewriting itself entirely." Which does not make any sense to me—why can't every other AGI builder make the same argument, that their code can be "tinkered with" over many years, and therefore is safe? Why aren't we risking the "initial dynamic" FOOMing while it's being tinkered with? Actually, it seems to me that an AI cannot begin to extrapolate anyone's volition until it's already more powerful than a human, so I have no idea how the tinkering is supposed to work at all.)
So, granting that "seed AI is much easier than brain emulation or intelligence amplification" is a very real possibility, I think we need better backup plans. This post is a bit similar to The Friendly AI Game, in that I'm asking for a utility function for a seed AI, but the goal here is not necessarily to build an FAI directly, but to somehow make an eventual positive Singularity more likely, while keepin
|
27fe09ff-0d59-4138-90ac-b17762d716ce
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Ten Causes of Mazedom
We continue answering the questions we asked earlier. It was claimed last time that maze levels and the danger of mazes was lower in the past than it is now, and that overall maze levels have been rising, as measured both by maze levels within organizations across the board, and maze levels within the overall society.
The world is better for people than it was back then. There are many things that have improved. This is not one of them.
I am confident this is the case and have pointed to ways to see it. I recognize that I have in no way proven this is the case. I don’t have a way to do that. Rather I am relying on your own observations and analysis. If you disagree, I hope the discussion that follows will still prove useful as a comparison to what you see as an alternate possible scenario where these dynamics are less toxic.
Now we ask what may have been different in the past, and whether we can duplicate those causes.
Why was it different? Can we duplicate those causes?
The sketched model suggests several causes.
One can model this as a two-level problem. Something happens (e.g. technological change) resulting in a change in circumstances (e.g. more real need for large organizations, cause one), which then causes higher overall maze levels.
Since this question asks for potential action on a large scale, political proposals will need to be among the proposals discussed. Let us do our best to debate models and how the gears in them work, and stay away from actual politics. To that end, I am not claiming any of these policies are good ideas and should be implemented, or bad and should not be implemented. I am only claiming that they would have particular physical results in the world. If they are obviously good or bad ideas, I shouldn’t need to say so.
Cause 1: More Real Need For Large Organizations
Modern life has larger organizations with more levels of hierarchy. Corporations are bigger. Governments are bigger. Political organizations are bigger. Univer
|
e4b14beb-16f1-4bf0-8ca7-c12554e870e0
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[AN #154]: What economic growth theory has to say about transformative AI
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter resources here. In particular, you can look through this spreadsheet of all summaries that have ever been in the newsletter.
Audio version here (may not be up yet).
Please note that while I work at DeepMind, this newsletter represents my personal views and not those of my employer.
HIGHLIGHTS
Could Advanced AI Drive Explosive Economic Growth? (Tom Davidson) (summarized by Rohin): Some (AN #121) previous (AN #105) work (AN #145) has suggested that by 2100 there is a non-trivial chance that AI could lead to explosive growth, that is, a growth rate of 30% (i.e. a doubling time of 2-3 years), 10x the current growth rate of ~3%. What does economics have to say about the matter?
This report investigates the following three stories:
1. Ignorance story: In this story, we don’t know how growth is determined, and attempts to forecast it based on models of how growth works are likely to be wrong. Note that this is perfectly compatible with explosive growth. We know that the growth rate has increased by orders of magnitude over the past millennia; so on an ignorance story we certainly shouldn’t rule out that the growth rate could increase by an order of magnitude again.
2. Standard story: This story focuses on the last ~century of growth, noting that the growth rate has stayed relatively constant at 2-3% per year, and thus predicting that future growth will be exponential (i.e. a constant growth rate), or possibly subexponential.
3. Explosive story: This story focuses on growth models with positive feedback loops, in which increased output leads to increased inputs which leads to even larger outputs, resulting in superexponential (and explosive) growth.
The author is interested in whether explosive growth is plausible, and so is most interested in arguments that argue for the standard story and against the ignorance or explosive stor
|
0123250d-267d-4bad-8d2c-34bef51e3847
|
trentmkelly/LessWrong-43k
|
LessWrong
|
A dialog with the axiom of choice
preliminary remark: the axiom of choice ( Auswahlaxiom in Germany) can be formulated this way:
For all sets M there is a selection function, that assigns for all elements of the power set P(M) exept ∅ an element of the corresponding subset of M.
It is assumed to be true in many areas of mathematics. Besides its "job" of giving elements of infinite sets, it has equivalent formulations to give "upper bounds" (Lemma of Zorn) and others. It is crucial in functional analysis in many ways.
In the following dialogue I tried to clarify a bit to myself, what this axiom means and why I do not entirely trust it.
Beware: It is an axiom, not a proven theorem. All that is proven about it is the following: It can be included in certain axiom systems without generating a contradiction.
The mathematical god of set theory
There is a little god in mathematics, who is known by many names. The Lemma of Zorn is one, but I choose the name axiom of choice.
Both are equivalent, which is "the same" mathematicaly.
This little god does many things in many mathematical areas.
I choose its job in set theory.
Every time a mathematician says:
"I choose an element of the set M to do this and that with",
it takes an element and gives the element to her - or, in some cases, him or it. I mean, how else can the mathematician get it?
So a person enters the temple of choice and asks:
person: "O axiom of choice, give me an element of the set M."
axiom : "I, the mighty axiom of choice, have a question first.
Did you ensure the set M is not empty? Otherwise I will not give you an element of the set M. I will never do this.
So I ask you: Are you sure the set M is not empty? By the way, which set M are we talking about?"
person: "I want a dialog between the axiom of choice and a mathematician. But I am too lazy to write it. Give me a mathematician to write a dialog with you."
axiom: "Any special kind of mathematician?"
person: "How about Douglas Hofstadter? He is very good at writing di
|
ccf206c5-1eba-4782-ad71-621083d2c374
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Software engineering - Career review
Summary
=======
Software engineering could be a great option for having a direct impact on the world’s most pressing problems, particularly in AI safety, but also in biosecurity and across other cause areas. This will probably be more impactful than earning to give.
As [with operations staff](https://80000hours.org/articles/operations-management/#whats-the-explanation-for-these-high-figures-why-arent-operations-roles-replaceable), organisations need exceptional and mission-aligned software engineers. But many still find it difficult to hire.
Some myths:
* You need an ML background to work as an engineer on AI safety.
* Outside AI safety, the only useful software skill is front-end web development.
* Effective organisations will pay far less than top companies.
None of these things are true.
In fact, many organisations have budgets of $10s of millions, and think that software engineers can substantially increase their cost-effectiveness (e.g. in his [80,000 Hours podcast](https://80000hours.org/podcast/episodes/chris-olah-interpretability-research/#hiring-023813), Chris Olah argues that Anthropic's [systems researcher](https://jobs.lever.co/Anthropic/e3741682-b8ac-44ae-96c4-805fa93c3725) could easily increase their efficiency by at least 10%). So even if you're earning 7 figures, you could be more effective doing direct impact work.
*This rest of this post contains an excerpt from my new* [*career review of software engineering*](https://80000hours.org/career-reviews/software-engineering/) *for 80,000 Hours, focusing on the parts most relevant to already-engaged EAs.*
*This review owes a lot to helpful discussions with (and comments from) Andy Jones, Ozzie Gooen, Jeff Kaufman, Sasha Cooper, Ben Kuhn, Nova DasSarma, Kamal Ndousse, Ethan Alley, Ben West, Ben Mann, Tom Conerly, Zac Hatfield-Dodds, and George McGowan. Special thanks go to Roman Duda for our previous review of software engineering, on which this was based.*
Why might software engineering be high impact?
==============================================
Software engineers are in a position to meaningfully contribute directly to solving a wide variety of the world’s [most pressing problems](https://80000hours.org/problem-profiles/).
In particular, there is a shortage of software engineers at the cutting edge of [research into AI safety](https://80000hours.org/career-reviews/ai-safety-researcher/).
We’ve also found that software engineers can contribute greatly to work aiming at preventing pandemics and other [global catastrophic biological risks](https://80000hours.org/problem-profiles/global-catastrophic-biological-risks/).
Aside from direct work on these crucial problems, while working for startups or larger tech companies you can [gain excellent career capital](https://80000hours.org/articles/career-capital/) (especially technical skills), and, if you choose, [earn and donate substantial amounts](https://80000hours.org/articles/earning-to-give/) to the world’s [best charities](https://80000hours.org/articles/best-charity/).
How to do good as a software engineer
-------------------------------------
Even for skilled engineers who could command high salaries, we think that working directly on a problem will probably be more impactful than earning to give.
Some examples of projects where software engineering is central to their impactful work:
* [**Ought**](https://ought.org/) is an AI research lab attempting to build systems that apply machine learning to the task of helping people think.
* The [**Secure DNA Project**](https://www.securedna.org/) is attempting to build a secure global screening system for DNA sequences that could be used to engineer a [global pandemic](https://80000hours.org/problem-profiles/global-catastrophic-biological-risks/).
* [**Momentum**](https://givemomentum.com/) is a startup building donation pages that encourage recurring donations to the world’s [most effective charities](https://80000hours.org/articles/best-charity/).
* [**Lightcone Infrastructure**](https://www.lightconeinfrastructure.com/) builds software-based infrastructure for [longtermist](https://80000hours.org/articles/future-generations/) projects.
* [**Telis Bioscience**](https://www.telisbio.com/) is a startup attempting to radically accelerate drug development to mitigate risks from future pandemics.
* [**Anthropic**](https://www.anthropic.com/) is a research company working to build reliable, interpretable, and steerable AI systems.
* [**Redwood Research**](https://www.redwoodresearch.org/) conducts applied research into the [challenge of aligning artificial intelligence](https://80000hours.org/problem-profiles/positively-shaping-artificial-intelligence/).
* [**Wave**](https://www.wave.com/) is a startup building a way for people in developing countries to access financial services.
Most organisations, even ones that don’t focus on developing large software products, need software engineers to manage computer systems, apps, and websites. For example:
* [**Effective Altruism Funds**](https://funds.effectivealtruism.org/) provides expert-managed funds to facilitate donors maximising the impact of their donations. They use software engineers to design and maintain their online platform.
* [**Our World in Data**](https://ourworldindata.org/), founded by [Max Roser](https://80000hours.org/podcast/episodes/max-roser-our-world-in-data/), collects and presents data on many of the world’s most pressing problems. They use software engineers to maintain their website, analyse data, and develop their [open-source data visualisation tool](https://ourworldindata.org/owid-grapher).
* Here at **80,000 Hours**, [our team](https://80000hours.org/about/meet-the-team/) includes two software engineers working on our website and other technology.
* The [**Centre for Effective Altruism**](https://www.centreforeffectivealtruism.org/)’s tech team supports a variety of projects across the [effective altruism community](https://80000hours.org/community/), such as the [Effective Altruism Forum](https://forum.effectivealtruism.org/posts/fd3iQRkmCKCCL289u/new-start-here-useful-links).
Many people we’ve spoken to at these and other organisations have said that they have real difficulty hiring extremely talented software engineers. Many nonprofits want to hire people who believe in their missions (just as they do [with operations staff](https://80000hours.org/articles/operations-management/#whats-the-explanation-for-these-high-figures-why-arent-operations-roles-replaceable)), which indicates that talented, altruistic-minded software engineers are sorely needed and could do huge amounts of good.
Smaller organisations that don’t focus on engineering often only have one or two software engineers. And because things at small organisations can change rapidly, they need unusually adaptable and flexible people who are able to maintain software with very little help from the wider team.[1](https://80000hours.org/career-reviews/software-engineering/#fn-1)
It seems likely that, as the community of people [working on helping future generations](https://80000hours.org/articles/future-generations/) grows, there will be more opportunities for practical software development efforts to help. This means that even if you don’t currently have any experience with programming, it could be valuable to begin developing expertise in software engineering now.
Software engineers can help with AI safety
------------------------------------------
We’ve argued before that [artificial intelligence could have a deeply transformative impact on our society](https://80000hours.org/problem-profiles/positively-shaping-artificial-intelligence/). There are huge opportunities associated with this ongoing transformation, but also extreme risks — potentially even threatening humanity’s survival.
With the rise of machine learning, and the huge success of deep learning models like [GPT-3](https://en.wikipedia.org/wiki/GPT-3), many experts now think it’s reasonably likely that our current machine learning methods could be used to create transformative artificial intelligence.
This has led to an explosion in empirical [AI safety research](https://80000hours.org/career-reviews/ai-safety-researcher/), where teams work directly with deep neural networks to identify risks and develop frameworks for mitigating them. Examples of organisations working in empirical AI safety research include [Redwood Research](https://www.redwoodresearch.org/), [DeepMind](https://deepmind.com/), [OpenAI](https://openai.com/), and [Anthropic](https://www.anthropic.com/).
These organisations are doing research directly with extremely large neural networks, which means each experiment can cost millions of dollars to run. This means that even small improvements to the efficiency of each experiment can be hugely beneficial.
There’s also often overlap between experimental results that will help further AI safety and results that could accelerate the development of unsafe AI, so it’s also important that the results of these experiments are [kept secure](https://80000hours.org/career-reviews/information-security/).
As a result, it’s likely to [remain incredibly valuable to have talented engineers](https://www.alignmentforum.org/posts/YDF7XhMThhNfHfim9/ai-safety-needs-great-engineers) working on ensuring that these experiments are as efficient and safe as possible. Experts we spoke to expect this to remain a key bottleneck in AI safety research for many years.
However, there is a serious risk associated with this route: it seems possible for engineers to accidentally increase risks from AI by generally accelerating the technical development of the field. We’re not sure of the more precise contours of this risk (e.g. exactly what kinds of projects you should avoid), but think it’s important to watch out for. That said, there are many more junior non-safety roles out there than roles focused specifically on safety, and experts we’ve spoken to expect that most non-safety projects aren’t likely to be causing harm. If you’re uncertain about taking a job for this reason, [our team](https://80000hours.org/speak-with-us/?int_campaign=career-review-software-engineering) may be able to help you decide.
Software engineer salaries mean you can earn to give
----------------------------------------------------
In general, if you can find a job you can do well, you’ll have a bigger impact working on a problem directly than you would by earning money and donating. However, [earning to give](https://80000hours.org/articles/earning-to-give/) can still be a high-impact option, especially if you focus on donating to the [most effective projects that could use the extra funds](https://80000hours.org/articles/best-charity/).
If you’re skilled enough to work at top companies, software engineering is a well-paid career. [In the US, entry-level software engineer salaries start at around $110,000](https://www.indeed.com/career/software-engineer/salaries). Engineers at Microsoft start at $150,000, and engineers at Google start at around $180,000 (including stock and bonuses). If you’re successful, after a few years on the job you could be earning over $500,000 a year.
Pay is [generally much lower in other countries](https://medium.com/@alanpochingyang/a-brief-exploration-of-country-difference-based-on-stack-overflow-developer-survey-2018-a3eb5e359a57). Median salaries in Australia are around 20% lower than salaries in the US (approximately US$80,000), and around 40% lower in the UK, Germany, Canada, and Japan (approximately US$60,000). While much of your earnings as a software engineer come from bonuses and equity, rather than just your salary, these are also lower outside the US.
If you do want to [make a positive difference through donating part of your income](https://80000hours.org/career-reviews/earning-to-give-in-a-high-paying-role/) as a software engineer, you may be able to increase your impact by using donation-matching programmes, which are common at large tech companies (although these are often capped at around US$10,000 per year).
You can read more about salaries at large tech companies [below](https://80000hours.org/career-reviews/software-engineering/#how-much-do-software-engineers-earn).
It’s important to note that many nonprofit organisations, including those focusing on AI safety, will offer salaries and benefits that compete with those at for-profit firms.
If you [work at](https://80000hours.org/career-reviews/startup-early-employee/) or [found](https://80000hours.org/career-reviews/tech-entrepreneurship/) a startup, your earnings will be highly variable. However, the [expected value](https://80000hours.org/articles/expected-value/) of your earnings — especially as a cofounder — could be extremely high. For this reason, if you’re a particularly good fit, founding a tech startup and donating your earnings could be hugely impactful, [as you could earn and donate extraordinary amounts](https://80000hours.org/stories/sam-bankman-fried/).
Moving to a direct impact software engineering role
===================================================
Working in AI safety
--------------------
If you are looking to work in an engineering role in an AI safety or other research organisation, you will probably want to focus on back-end software development (although there are also front-end roles, particularly those focusing on gathering data from humans on which models can be trained and tested). There are recurring opportunities for software engineers with a range of technical skills (to see examples, take a look at our [job board](https://80000hours.org/job-board/ai-safety-policy/?role-type=engineering)).
If you have the opportunity to choose areas in which you could gain expertise, the experienced engineers we spoke to suggested focusing on:
* Distributed systems
* Numerical systems
* Security
In general, it helps to have expertise in any specific, hard-to-find skillsets.
This work uses a range of programming languages, including Python, Rust, C++ and JavaScript. Functional languages such as Haskell are also common.
We’ve previously written about [how to move into a machine learning career for AI safety](https://80000hours.org/articles/ml-engineering-career-transition-guide). We now think it is easier than we previously thought to move into an AI-safety-related software engineering role *without* explicit machine learning experience.
The [Effective Altruism Long-Term Future Fund](https://funds.effectivealtruism.org/funds/far-future) and the [Survival and Flourishing Fund](https://survivalandflourishing.fund/) may provide funding for promising individuals to learn skills relevant to helping future generations, including new technologies such as machine learning. If you already have software engineering experience, but would benefit from explicit machine learning or AI safety experience, this could be a good option for you.
If you think you could, with a few weeks’ work, [write a new feature or fix a bug in a major machine learning library](https://forum.effectivealtruism.org/posts/DDDyTvuZxoKStm92M/ai-safety-needs-great-engineers), then you could probably apply directly for engineering roles at top AI safety labs (such as [Redwood Research](https://www.redwoodresearch.org/), [DeepMind](https://deepmind.com/), [OpenAI](https://openai.com/), and [Anthropic](https://www.anthropic.com/)), without needing to spend more time building experience in software engineering. These top labs offer pay that is comparable to pay at large tech firms.
If you are considering joining an AI safety lab in the near future, [our team may be able to help](https://80000hours.org/speak-with-us/?int_campaign=career-review-software-engineering).
Working on reducing global catastrophic biological risks
--------------------------------------------------------
Reducing [global catastrophic biological risks](https://80000hours.org/problem-profiles/global-catastrophic-biological-risks/) — for example, research into screening for novel pathogens to prevent future pandemics — is likely to be one of the most important ways to help solve the [world’s most pressing problems](https://80000hours.org/problem-profiles/).
Through organisations like [Telis Bioscience](https://www.telisbio.com/) and [SecureDNA](https://www.securedna.org/) (and other [projects that might be founded in the future](https://80000hours.org/career-reviews/founder-impactful-organisations/)), there are significant opportunities for software engineers to contribute to reducing these risks.
Anyone with a good understanding of how to build software can be useful in these small organisations, even if they don’t have much experience. However, if you want to work in this space, you’ll need to be comfortable getting your hands dirty and doing whatever needs to be done, even when the work isn’t the most intellectually challenging. For this reason, it could be particularly useful to have experience working in a software-based startup.
Much of the work in biosecurity is related to handling and processing large amounts of data, so knowledge of how to work with distributed systems is in demand. Expertise in adjacent fields such as [data science](https://80000hours.org/career-reviews/data-science/) could also be helpful.
There is also a big focus on security, particularly at organisations like SecureDNA.
Most code in biosecurity is written in Python.
If you’re interested in working on biosecurity and pandemic preparedness as a software engineer, you can find open positions on our [job board](https://80000hours.org/job-board/biosecurity-pandemic-preparedness/?role-type=engineering).
Other important direct work
---------------------------
Nonprofit organisations and altruistic-minded startups often have very few team members. And no matter what an organisation does, they almost always have some need for engineers (for example, 80,000 Hours is not a software organisation, but we employ two developers). So if you find an organisation you think is doing something really useful, working as a software engineer for them might be an excellent way to support that work.
Engineering for a small organisation likely means doing work across the development process, since there are few other engineers.
Often these organisations are focused on front-end development, with jobs ranging from application development and web development to data science and project management roles. There are often also opportunities for full-stack developers with a broad range of experience.
Founding an organisation yourself is more challenging, but can be even more impactful. And if you’ve worked in a small organisation or a startup before, you might have the broad skills and entrepreneurialism that’s required to succeed. See our [profile on founding new high-impact projects](https://80000hours.org/career-reviews/founder-impactful-organisations/) for more.
Reasons not to go into software engineering
===========================================
We think that most people with good general intelligence will be able to do well at software engineering. And because it’s very easy to test out (see the section on [how to predict your fit in advance](https://80000hours.org/career-reviews/software-engineering/#how-to-predict-your-fit-in-advance)), you’ll be able to tell early on whether you’re likely to be a good fit.
However, there are lots of other paths that seem like particularly promising ways to help solve the world’s most pressing problems, and it’s worth looking into them. If you find programming difficult, or unenjoyable, your [personal fit](https://80000hours.org/articles/personal-fit/) for other career paths may be higher. And even if you enjoy it and you’re good at it, we think that will be true for lots of people, so that’s not a good reason to think you won’t be even better at something else!
As a result, it’s important to test your fit for a variety of options. Try taking a look at our [other career reviews](https://80000hours.org/career-reviews/) to find out more.
*You can read the full review* [*here*](https://80000hours.org/career-reviews/software-engineering/)*.*
|
f8065609-c990-485f-8c13-a61ee0ace465
|
trentmkelly/LessWrong-43k
|
LessWrong
|
X-Risk Roll Call
I'm working on a substantial research piece concerned with x-risk, and a sub-task of that involves compiling a list of important people in the field along with a brief summary of their education and relevant links. I realized that such a list might be a useful bit of meta-scholarship on its own, so I'm posting an incomplete version of it here in case anyone thinks there are people I should add. I haven't tracked down all the cv's and personal websites yet but I'd like to get the feedback ball rolling. After the LW crowd has given me any criticisms it thinks are relevant, I'll polish the list up.
The focus is on researchers in x-risk and related fields, so I'm not including, say, every machine intelligence researcher, just the ones who, as far as I can tell, show an awareness of the possible existential impact of their work. In practice this means those who are affiliated with x-risk reduction groups like the Future of Humanity Institute or MIRI, or ones who've specifically written on x-risk. No, that's not quite fair, but I needed some heuristic for narrowing down the list, and my mind is open if anyone has a better idea.
And yes, this is mostly information that's available with a little Googling (though a few people were hard to track down). But this list, when completed, will allow any interested person to quickly see the educational pathways taken by a large number of x-risk researchers. I'm compiling this information as opposed to, say, current position or research interests because the former is more relevant to the bigger project I'm working on, the latter is more likely to change, and besides Googling is easy if you're only interested in a handful of people. But if there is demand for a more thorough and comprehensive document, I could also put that together.
I've erred on the side of inclusion, which means I included people even if they were interns or associates as opposed to primary researchers. Of course I intend to finish this on my own
|
2345f633-0c4d-40eb-862d-436b8a2be3a2
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Predictive history classes
Epistemic status: serious proposal with known difficulties and problems
Why do we study history? There are many potential reasons. More specifically, why do we teach history to everyone going to school? Many reasons become less relevant to those other than historians or history teachers.
The classic reason is "so that we don't repeat it". But most people will not end up in a position of power so as to decide whether we repeat or don't repeat history. A more honest reason, for most people, is that we learn history to generalise its lessons to the future or present. Assuming that purpose, we find current methods of history classes dreadfully ineffective. I propose an alternative paradigm of history classes which, I believe, will result in much more practical learning.
A cynical reader remarks that history education in school (in the form I'm targeting) is for indoctrination. From that view, take this not as a proposal for reform, but a suggestion on how to study well for your own sake.
Current history education focuses on teaching the students about past events. Students are then tested on those same past events. In higher history classes, they are also tested on analysing information about these events and arguing about their causes and consequences.
This is great for those who will be historians. Most students will not. This style of teaching does not guarantee any understanding of how to apply historical lessons to the present and future.
In schools where students just study to the test, make the test a good one. Instead of testing students on past events they studied, test them on events they didn't study. They are then forced to learn how to generalise history, applying its lessons to understand what they're going thru and what may come next. To get an objective answer by which to grade the students, test them on actual past events — just obscure ones that they wouldn't already know about. Sith they didn't study the material, they aren't expected to ever ge
|
4815570e-89c8-49f4-b55d-ba0784e2bda8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : Washington DC fun and games meetup
Discussion article for the meetup : Washington DC fun and games meetup
WHEN: 15 December 2013 03:00:00PM (-0500)
WHERE: National Portrait Gallery, Washington, DC 20001, USA
We'll be meeting to hang out and play games.
Discussion article for the meetup : Washington DC fun and games meetup
|
99ed3c23-8326-420c-b769-ba15cef6dc5d
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Why we need a *theory* of human values
There have been multiple *practical* suggestions for methods about how we should extract the values of a given human. Here are four common classes of such methods:
* Methods that put high weight on human (bounded) quasi-rationality, or revealed preferences. For example, we can assume the Kasparov was actually trying to win against DeepBlue, not trying desperately to lose while inadvertently playing excellent chess.
* Methods that pay attention to our explicitly stated values.
* Methods that use [regret](https://www.lesswrong.com/posts/Fg83cD3M7dSpSaNFg/normative-assumptions-regret), surprise, joy, or similar emotions, to estimate what humans actually want. This could be seen as a form of human [TD learning](https://en.wikipedia.org/wiki/Temporal_difference_learning).
* Methods based on an explicit procedure for constructing the values, such as [CEV](https://wiki.lesswrong.com/wiki/Coherent_Extrapolated_Volition) and Paul's [indirect normativity](https://ordinaryideas.wordpress.com/2012/04/21/indirect-normativity-write-up/).
Divergent methods
-----------------
The first question is why we would expect these methods to point even vaguely in the same direction. They all take very different approaches - why do we think they're measuring the same thing?
The answer is that they roughly match up in situations we encounter everyday. In such typical situations, people who feel regret are likely to act to avoid that situation again, to express displeasure about the situation, etc.
By analogy, consider a town where there are only two weather events: bright sunny days and snow storms. In that town there is a strong correlation between barometric pressure, wind speed, cloud cover, and temperature. All four indicators track different things, but, in this town, they are basically interchangeable.
But if the weather grows more diverse, this correlation can [break down](https://www.lesswrong.com/posts/ix3KdfJxjo9GQFkCo/web-of-connotations-bleggs-rubes-thermostats-and-beliefs). Rain storms, cloudy days, meteor impacts: all these can disrupt the alignment of the different indicators.
Similarly, we expect that an AI could remove us from typical situations and put us into extreme situations - at least "extreme" from the perspective of the everyday world where we forged the intuitions that those methods of extracting values roughly match up. Not only do we expect this, but we desire this: a world without absolute poverty, for example, is the kind of world we would want the AI to move us into, if it could.
In those extreme and unprecedented situations, we could end up with revealed preferences pointing one way, stated preferences another, while regret and CEV point in different directions entierly. In that case, we might be tempted to ask "should we follow regret or stated preferences?" But that would be the wrong question to ask: our methods no longer correlated with each other, let alone with some fundamental measure of human values.
We are thus in an undefined state; in order to continue, we need a meta-method that decides between the different methods. But what criteria could such meta-method use for deciding (note that simply getting human feedback is [not generically an option](https://www.lesswrong.com/posts/nFv2buafNc9jSaxAH/siren-worlds-and-the-perils-of-over-optimised-search))? Well, it would have to select the method which best matches up with human values in this extreme situation. **To do that, it needs a definition - a theory - of what human values actually are**.
Underdefined methods
--------------------
The previous section understates the problems with purely practical ways of assessing human values. It pointed out divergences between the methods in "extreme situations". Perhaps we were imagining these extreme situations as the equivalent of a meteor impact on weather system: bizarre edge cases where reasonable methods finally break down.
But all those actually methods fail in typical situations as well. If we interpret the methods naively, they fail often. For example, in 1919, some of the Chicago White Sox baseball team [were actually trying to lose](https://en.wikipedia.org/wiki/Black_Sox_Scandal). If we ask someone their stated values in a political debate or a courtroom, we don't expect an honest answer. Emotion based approaches fail in situations where humans deliberately expose themselves to nostalgia, or fear, or other "negative" emotions (eg through scary movies). And there are [failure](https://www.lesswrong.com/posts/vgFvnr7FefZ3s3tHp/mahatma-armstrong-ceved-to-death) [modes](https://www.lesswrong.com/posts/nFv2buafNc9jSaxAH/siren-worlds-and-the-perils-of-over-optimised-search) for the explicit procedures, too.
This is true if we interpret the methods naively. If we were more "reasonable" or "sophisticated", we would point out that don't expect those methods to be valid in every typical situation. In fact, we can do better than that: we have a good intuitive understanding of when the methods succeed and when they fail, and different people have similar intuitions (we all understand that people are more honest in relaxed private settings that stressful public ones, for example). It's as if we lived in a town with either sunny days or snow storms *except on weekends*. Then everyone could agree that the different indicators correlate during the week. So the more sophisticated methods would include something like "ignore the data if it's Saturday or Sunday".
But there are problems with this analogy. Unlike for the weather, there are no clear principle for deciding when it's the equivalent of the weekend. Yes, we have an *intuitive* grasp of when stated preferences fail, for instance. But as [Moravec's paradox](https://en.wikipedia.org/wiki/Moravec%27s_paradox) shows, an intuitive understanding doesn't translate into an explicit, formal definition - and it's that kind of formal definition that we need if we want to code up those methods. Even worse, we **don't** all agree as to when the methods fail. For example, some economists [deny the very existence of mental illness](http://econfaculty.gmu.edu/bcaplan/pdfs/szasz.pdf), while psychiatrists (and most laypeople) [very much feel these exist](http://slatestarcodex.com/2015/10/07/contra-caplan-on-mental-illness/).
Human judgement and machine patching
------------------------------------
So figuring out whether the methods apply is an exercise in human judgement. Figuring out whether the methods have gone wrong is a similar exercise (see the [Last Judge](https://intelligence.org/files/CEV.pdf) in CEV).
And figuring out what to do when they don't apply is also an exercise in human judgement - if we judge that someone is lying about their stated preferences, we could just reverse their statement to get their true values.
So we need to patch the methods using our human judgement. And probably [patch the patches](https://arbital.com/p/patch_resistant/) and so on. Not only is the patching process a terrible and incomplete way of constructing a safe goal for the AI, but human judgements are not consistent - we can be swayed in things as basic as whether a [behaviour is rational](https://faculty.washington.edu/jmiyamot/p466/pprs/slovic%20who%20accepts%20savages%20axiom.pdf), let alone [all](https://en.wikipedia.org/wiki/Availability_heuristic) [the](https://en.wikipedia.org/wiki/Belief_bias) [situational](https://en.wikipedia.org/wiki/Framing_effect_(psychology)) [biases](https://en.wikipedia.org/wiki/Social_desirability_bias) that cloud our assessments of more complicated issues.
So obviously, the solution to these problems is to figure out which human is best in their judgements, and then to see under what circumstances these judgements can be least biased, and how to present the information to them in the most impartial way and then automate that judgement...
[Stop that. It's silly.](https://www.youtube.com/watch?v=es4Yq7jP03w). The correct solution is not to assess the rationality of human judgements of methods of extracting human values. The correct solution is to come up with a better theoretical definition of what human values are. Armed with such a theory, we can resolve or ignore the above issues in a direct and principled way.
Building a theory of human values
=================================
Just because we need a theory of human values, doesn't mean that it's easy to find one - the universe is cruel like that.
A big part of my current approach is to build such a theory. I will present an overview of my theory in a subsequent post, though most of the pieces have appeared in past posts already. My approach uses three key components:
1. A way of defining the basic preferences (and basic meta-preferences) of a given human, even if these are under-defined or situational.
2. A method for synthesising such basic preferences into a single utility function or similar object.
3. A guarantee we won't end up in a terrible place, due to noise or different choices in the two definitions above.
|
f5ac3353-16c5-4710-9667-0bce82bc7af6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Universals of Morality: Toward Human-Centric Communication Platforms
Each person alone is powerless, a fleshy mammal that would typically die from the elements. Networked together into factions, we devise ways to benefit “us” or defeat “them”.
Social platforms like Facebook, Twitter, and Tik-Tok have brought this human story to unprecedented scale, connecting billions. Whatever the platforms might have done with this power, the chosen business model has been to monetize access to our minds. They sell the power to divide us into groups and to sell access to each group of “us” to the highest bidder, often pitting us against a chosen group of “them”. Dictators and demagogues have grown particularly adept at using these systems to bend our minds and fracture society. With 15 years of hindsight, it’s clear that great power should have come with greater responsibility.
Perhaps humanity’s communications will always be rooted in surveillance-based business models. But let’s indulge for the moment the ideal of a platform that networks people together for a novel purpose: not for monetizing access to our minds, but rather with the express purpose of elevating humanity.
Regardless of how it’s implemented (whether via an AI, an oversight board, or some other means), what moral framework would be “best” for humanity?
Can this question be answered? It is bold to try, but the status quo is clearly unacceptable. Let’s zoom out to find an anchor among universal truths.
The universe started as nothing. Then somehow, matter flashed into existence. Out of nothingness there was suddenly Creation.
Over time, the matter clumped together in stars and galaxies. Relative to the empty void of space, the mind perceives these more complex structures as “interesting”.
On Earth, matter formed ever more complex structures, eventually to include living creatures with minds, most notably humans. We formed complex societies, so much more interesting and dynamic than just the sum of the parts.
This has somehow happened despite the overwhelming tendency of the u
|
e32afd9c-fb3a-453e-a214-12088c6242c8
|
StampyAI/alignment-research-dataset/arbital
|
Arbital
|
Aligning an AGI adds significant development time
# Definition
The votable proposition is true if, comparing reasonably attainable development paths for...
- **Project Path 1: An [aligned](https://arbital.com/p/2v) [advanced AI](https://arbital.com/p/7g1) created by a responsible project** that is hurrying where it can, but still being careful enough to maintain a success probability greater than 25%
- **Project Path 2: An unaligned unlimited [superintelligence](https://arbital.com/p/41l) produced by a project cutting all possible corners**
...where otherwise **both projects have access to the same ideas or discoveries** in the field of AGI capabilities and similar computation resources; then, as the default / ordinary / modal case after conditioning on all of the said assumptions:
**Project Path 1 will require *at least* 50% longer serial time to complete than Project Path 2, or two years longer, whichever is less.**
[https://arbital.com/p/toc:](https://arbital.com/p/toc:)
# Purpose
This page was written to address multiple questioners who seem to have accepted the [Orthogonality thesis](https://arbital.com/p/1y), but still mostly disbelieve it would take significantly longer to develop aligned AGI than unaligned AGI, if I've understood correctly.
At present this page is an overview of possible places of disagreement, and may later be selectively rather than fully expanded.
# Arguments
## Related propositions
Propositions feeding into this one include:
- (1a) [https://arbital.com/p/5l](https://arbital.com/p/5l) (even as applied to a [https://arbital.com/p/minimum_pivotal_task](https://arbital.com/p/minimum_pivotal_task))
- (1b) [https://arbital.com/p/7wm](https://arbital.com/p/7wm)
If questioner believes the negation of either of these, it would imply easy specifiability of a decision function suitable for an unlimited superintelligence. That could greatly reduce the need for, e.g:
- (2a) [Non-adversarial design](https://arbital.com/p/7g0)
- (2b) [Minimal design](https://arbital.com/p/7tf)
- (2c) [Limitation](https://arbital.com/p/5b3) of the AGI's abilities
- (2d) [Understandable design](https://arbital.com/p/7v7) or [transparent elements](https://arbital.com/p/transparency) for design aspects besides the top-level preferences (and the [actual effectiveness](https://arbital.com/p/7wp) of those preferences within the AGI)
It's worth checking whether any of these time-costly development principles seem to questioner to *not* follow as important from the basic idea of value alignment being necessary and not trivially solvable.
## Outside view
To the best of my knowledge, it is normal / usual / unsurprising for *at least* 50% increased development time to be required by strong versus minimal demands on *any one* of:
- (3a) safety of any kind
- (3b) robust behavior in new one-shot contexts that can't be tested in advance
- (3c) robust behavior when experiencing strong forces
- (3d) reliable avoidance of a single catastrophic failure
- (3e) resilience in the face of strong optimization pressures that can potentially lead the system to traverse unusual execution paths
- (3f) conformance to complicated details of a user's desired system behavior
%comment: It would indeed be unusual--some project managers might call it *extra-ordinary* good fortune--if a system demanding *two or more* of these properties did *not* require at least 50% more development time compared to a system that didn't.%
Obvious-seeming-to-me analogies include:
- Launching a space probe that cannot be corrected once launched, a deed which usually calls for extraordinary additional advance checking and testing
- Launching the simplest working rocket that will experience uncommonly great accelerations and forces, compared to building the simplest working airplane
- It would be far less expensive to design rockets if "the rocket explodes" were not a problem; most of the cost of a rocket is having the rocket not explode
- NASA managing to write almost entirely bug-free code for some projects at 100x the cost per line of code, using means that involved multiple reviews and careful lines of organizational approval for every aspect and element of the system
- The OpenBSD project to produce a secure operating system, which needed to constrain its code to be more minimal than larger Linux projects, and probably added a lot more than 50% time per function point to approve each element of the code
- The difference in effort put forth by an amateur writing an encryption system they think is secure, versus the cryptographic ecosystem trying to ensure a channel is secure
- The real premium on safety for hospital equipment, as opposed to the bureaucratic premium on it, is probably still over 50% because it *does* involve legitimate additional testing to try to not kill the patient
- Surgeons probably legitimately require at least 50% longer to operate on humans than they would require to perform operations of analogous complexity on large plants it was okay to kill 10% of the time
- Even in the total absence of regulatory overhead, it seems legitimately harder to build a nuclear power plant that *usually* does not melt down, compared to a coal power plant (confirmable by the Soviet experience?)
Some of the standard ways in which systems with strong versus minimal demands on (3*)-properties *usually* require additional development time:
- (4a) Additional work for:
- Whole extra modules
- Universally enforced properties
- Lots of little local function points
- (4b) Needing a more extended process of interactive shaping in order to conform to a complicated target
- (4c) Legitimately requiring longer organizational paths to approve ideas, changes and commits
- (4d) Longer and deeper test phases; on whole systems, on local components, and on function points
- (4e) Not being able to deploy a fast or easy solution (that you could use at some particular choice point if you didn't need to worry about the rocket exploding)
### Outside view on AI problems
Another reference class that feels relevant to me is that things *having to do with AI* are often more difficult than expected. E.g. the story of computer vision being assigned to 2 undergrads over the summer. This seems like a relevant case in point of "uncorrected intuition has a directional bias in underestimating the amount of work required to implement things having to do with AI, and you should correct that directional bias by revising your estimate upward".
Given a sufficiently advanced Artificial General Intelligence, we might perhaps get narrow problems on the order of computer vision for free. But the whole point of Orthogonality is that you do *not* get AI alignment for free with general intelligence. Likewise, identifying [value-laden](https://arbital.com/p/36h) concepts or executing value-laden behaviors doesn't come free with identifying natural empirical concepts. We have *separate* basic AI work to do for alignment. So the analogy to underestimating a narrow AI problem, in the early days before anyone had confronted that problem, still seems relevant.
%comment: I can't see how, after [imagining oneself in the shoes](http://lesswrong.com/lw/j0/making_history_available/) of the early researchers tackling computer vision and 'commonsense reasoning' and 'natural-language processing', after the entirety of the history of AI, anyone could reasonably stagger back in shocked and horrified surprise upon encountering the completely unexpected fact of a weird new AI problem being... kinda hard.%
## Inside view
While it is possible to build new systems that aren't 100% understood, and have them work, the successful designs were usually greatly overengineered. Some Roman bridges have stayed up two millennia later, which probably wasn't in the design requirements, so in that sense they turned out to be hugely overengineered, but we can't blame them. "What takes good engineering is building bridges that *just barely* stay up."
If we're trying for an aligned [Task AGI](https://arbital.com/p/6w) *without* a [really deep understanding](https://arbital.com/p/7vb) of how to build exactly the right AGI with no extra parts or extra problems--which must certainly be lacking on any scenario involving relatively short timescales--then we have to do *lots of* safety things in order to have any chance of surviving, because we don't know in advance which part of the system will nearly fail. We don't know in advance that the O-Rings are the part of the Space Shuttle that's going to suddenly behave unexpectedly, and we can't put in extra effort to armor only that part of the process. We have to overengineer everything to catch the small number of aspects that turn out not to be so "overengineered" after all.
This suggests that even if one doesn't believe my particular laundry list below, whoever walks through this problem, *conditional* on their eventual survival, will have shown up with *some* laundry list of precautions, including costly precautions; and they will (correctly) not imagine themselves able to survive based on "minimum necessary" precautions.
Some specific extra time costs that I imagine might be required:
- The AGI can only deploy internal optimization on pieces of itself that are small enough to be relatively safe and not vital to fully understand
- In other words, the cautious programmers must in general do extra work to obtain functionality that a corner-cutting project could get in virtue of the AGI having further self-improved
- Everything to do with real [value alignment](https://arbital.com/p/5s) (as opposed to the AI having a [reward button](https://arbital.com/p/7w5) or being reinforcement-trained to 'obey orders' on some channel) is an additional set of function points
- You have to build new pieces of the system for transparency and monitoring.
- Including e.g. costly but important notions like "There's actually a [separatish AI over here](https://arbital.com/p/monitor_oracle) that we built to inspect the first AI and check for problems, including having this separate AI [trained on different data](https://arbital.com/p/independently_learned_concept) for safety-related concepts"
- There's a lot of [trusted](https://en.wikipedia.org/wiki/Trusted_system) function points where you can't just toss in an enormous deepnet because that wouldn't meet the [https://arbital.com/p/-transparency](https://arbital.com/p/-transparency) or [effability](https://arbital.com/p/7vb) requirements at that function point
- When somebody proposes a new optimization thingy, it has to be rejiggered to ensure e.g. that it meets the top-to-bottom [taskishness](https://arbital.com/p/4mn) requirement, and everyone has to stare at it to make sure it doesn't blow up the world somehow
- You can't run jobs on AWS because you don't trust Amazon with the code and you don't want to put your AI in close causal contact with the Internet
- Some of your system designs rely on [all 'major' events being monitored and all unseen events being 'minor'](https://arbital.com/p/major_monitored), and the major monitored events go through a human in the loop. The humans in the loop are then a rate-limiting factor and you can't just 'push the lever all the way up' on that process.
- E.g., maybe only 'major' goals can recruit subgoals across all known [domains](https://arbital.com/p/7vf) and 'minor' goals always operate within a single domain using limited cognitive resources.
- Deployment involves a long conversation with the AI about '[what do you expect to happen after you do X](https://arbital.com/p/check_expected_outcome)?', and during that conversation other programmers are slowing down the AI to look at [passively transparent](https://arbital.com/p/passive_transparency) interpretations of the AI's internal thoughts
- The project has a much lower threshold for saying "wait, what the hell just happened, we need to stop melt and catch fire, not just try different [patches](https://arbital.com/p/48) until it seems to run again"
- The good project perhaps does a tad more testing
Indepedently of the particular list above, this doesn't feel to me like a case where the conclusion is highly dependent on Eliezer-details. Anyone with a concrete plan for aligning an AI will walk in with a list of plans and methods for safety, some of which require close inspection of parts, and constrain allowable designs, and just plain take more work. One of the important ideas is going to turn out to take 500% more work than required, or solving a deep AI problem, and this isn't going to shock them either.
## Meta view
I genuinely have some trouble imagining what objection is standing in the way of accepting "ceteris paribus, alignment takes at least 50% more time", having granted Orthogonality and alignment not being completely trivial. I did not expect the argument to bog down at this particular step. I wonder if I'm missing some basic premise or misunderstanding questioner's entire thesis.
If I'm not misunderstanding, or if I consider the thesis as-my-ears-heard-it at face value, then I can only imagine the judgment "alignment probably doesn't take that much longer" being produced by ignoring what I consider to be basic principles of cognitive realism. Despite the dangers of [psychologizing](https://arbital.com/p/43h), for purposes of oversharing, I'm going to say what *feels to me* like it would need to be missing:
- (5a) Even if one feels intuitively optimistic about a project, one ought to expect in advance to run into difficulties not immediately obvious. You should not be in a state of mind where tomorrow's surprises are a lot more likely to be unpleasant than pleasant; this is [https://arbital.com/p/-predictable_updating](https://arbital.com/p/-predictable_updating). The person telling you your hopeful software project is going to take longer than 2 weeks should not need to argue you into acknowledging in advance that some particular delay will occur. It feels like the ordinary skill of "standard correction for optimistic bias" is not being applied.
- (5b) It feels like this is maybe being put into a mental bucket of "futuristic scenarios" rather than "software development projects", and is being processed as pessimistic future versus normal future, or something. Instead of: "If I ask a project manager for a mission-critical deep feature that impacts every aspect of the software project and needs to be implemented to a high standard of reliability, can that get done in just 10% more time than a project that's eliminating that feature and cutting all the corners?"
- (5c) I similarly recall the old experiment in which students named their "best case" scenarios where "everything goes as well as it reasonably could", or named their "average case" scenarios; and the two elicitations produced indistinguishable results; and reality was usually slightly worse than the "worse case" scenario. I wonder if the "normal case" for AI alignment work required is being evaluated along much the same lines as "the best case / the case if every individual event goes as well as I imagine by default".
AI alignment could be easy in theory and still take 50% more development time in practice. That is a very ordinary thing to have happen when somebody asks the project manager to make sure a piece of highly novel software *actually* implements an "easy" property the first time the software is run under new conditions that can't be fully tested in advance.
"At least 50% more development time for the aligned AI project, versus the corner-cutting project, assuming both projects otherwise have access to the same stock of ideas and methods and computational resources" seems to me like an extremely probable and *normal* working premise to adopt. What am I missing?
%comment: I have a sense of "Why am I not up fifty points in the polls?" and "What experienced software manager on the face of the Earth (assuming they didn't go mentally haywire on hearing the words 'Artificial Intelligence', and considered this question as if it were engineering), even if they knew almost nothing else about AI alignment theory, would not be giving a rather skeptical look to the notion that carefully crafting a partially superhuman intelligence to be safe and robust would *only* take 1.5 times as long compared to cutting all the corners?" %
|
21a70389-69ff-4a0d-a876-12a2d105f179
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Skepticism towards claims about the views of powerful institutions
Introduction: some contemporary AI governance context
It’s a confusing time in AI governance. Several countries’ governments recently changed hands. DeepSeek and other technical developments have called into question certain assumptions about the strategic landscape. Political discourse has swung dramatically away from catastrophic risk and toward framings of innovation and national competitiveness.
Meanwhile, the new governments have issued statements of policy, and AI companies (mostly) continue to publish or update their risk evaluation and mitigation approaches. Interpreting these words and actions has become an important art for AI governance practitioners: does the phrase “human flourishing” in the new executive order signal concern about superintelligence, or just that we should focus on AI’s economic and medical potential and not “hand-wring” about safety? How seriously should we take the many references to safety in the UK’s AI Opportunities Action Plan, given the unreserved AI optimism in the announcement? Does Meta’s emphasis on “unique” risks take into account whether a model’s weights are openly released? The answers matter not only for predicting future actions but also for influencing them: it’s useful to know an institution’s relative appetite for different kinds of suggestions, e.g. more export controls versus maintaining Commerce’s reporting requirements.
So, many people who work in AI governance spend a lot of time trying to read between the lines of these public statements, talking to their contacts at these institutions, and comparing their assessment of the evidence with others’. This means they can wind up with a lot of non-public information — and often, they also have lots of context that casual observers (or people who are doing heads-down technical work in the Bay) might not.
All of that is to say: if you hear someone express a view about how an institution is thinking about AI (or many other topics), you might be tempted to update your
|
30d0d25b-101f-4b05-9653-926625aa5b37
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Parental Writing Selection Bias
In general I'd like to see a lot more of people writing about their failures in addition to their successes. If a bunch of people all try a thing and have mixed results, and only the people with good results write about it, people who don't know about this selection bias or don't realize its extent are going to end up with overly positive views. I've written about some of my mistakes, and I think it would be good if this were a higher fraction of my posts.
On the other hand, once other people are involved this isn't entirely up to me. One place this comes up a lot is parenting: I don't want to write things about my kids that they don't (or won't) want public. This is especially tricky if I write a post about something we've tried which worked well in part because the kids did a good job with it, and then later they stop doing a good job.
I don't have a good solution here. I don't want to go all the way to "if this had come out with my kids looking bad I wouldn't write about it, so I also won't write about it if they look good" because this would exclude a huge fraction of things involving the kids (there are a tremendous number of possible ways kids could do something that would be embarrassing). Sometimes I can handle it with plausible deniability (one of our kids did embarrassing thing X) but often it would be clear to some people which kid actually did it, or it's bad enough that even being in a pool of three is mortifying. Other times I'm able to include some minor negative information, if it's about them when they were enough younger and it's combined with positive information. But mostly I think this will just need to be something people keep in mind when reading my posts, and posts by other parents.
I asked one of my kids what they thought about this issue and they suggested: "only write about things where [sibling] looks bad and I look good, such as [redacted]".
Comment via: facebook, mastodon
|
7521070f-425c-4cf7-9d60-96f8e588b9de
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Local Explanations for Reinforcement Learning
1 Introduction
---------------
Deep reinforcement learning has seen stupendous success over the last decade with superhuman performance in games such as Go [[40](#bib.bib40)], Chess [[41](#bib.bib41)] as well as Atari benchmarks [[31](#bib.bib31)]. With increasing superior capabilities of automated (learning) systems, there is a strong push to understand the reasoning behind their decision making. One motivation is for (professional) humans to improve their performance in these games [[36](#bib.bib36)]. An even deeper reason is for humans to be able to trust these systems if they are deployed in real life scenarios [[15](#bib.bib15)]. Safety, for instance, is of paramount importance in applications such as self-driving cars or deployments on unmanned aerial vehicles (UAVs) [[13](#bib.bib13)]. The General Data Protection Regulation [[47](#bib.bib47)] passed in Europe demands that explanations need to be provided for any automated decisions that affect humans. While various methods with different flavors have been provided to explain classification models [[37](#bib.bib37), [26](#bib.bib26), [22](#bib.bib22), [9](#bib.bib9)] and evaluated in application-grounded manner [[11](#bib.bib11), [10](#bib.bib10)], the exploration of different perspectives to explain reinforcement learning (RL) policies has been limited and user study evaluations comparing methods are rarely employed in this space.
In this paper, we provide a novel perspective to produce human understandable explanations with a task-oriented user study that evaluates which explanations help users predict the behavior of a policy better. Our approach involves two steps: 1) learning meta-states, i.e., clusters of states, based on the dynamics of the policy being explained, and 2) within eat meta-state, identifying states that act intermediate goals, which we refer to as *strategic states*. Contrary to the global nature of recent explainability works in RL [[45](#bib.bib45), [43](#bib.bib43), [3](#bib.bib3)], our focus is on local explanations; given the current state, we explain the policy moving forward within a fixed distance from the current state. This key distinction allows us to consider richer state spaces (i.e., with more features) because the locality restricts the size of the state space we consider, as will be demonstrated. It is also important to recognize the difference from bottlenecks [[30](#bib.bib30), [42](#bib.bib42)] which are *policy-independent* and learned by approximating the state space with randomly sampled trajectories; rather than help explain a policy, bottlenecks are used to *learn* efficient policies such as through hierarchical RL [[5](#bib.bib5)] or options frameworks [[35](#bib.bib35)]. Strategic states, however, are learned with respect to a policy and identified without assuming access to the underlying topology.
An example of this is seen in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")a. Each position is a state and a meta-state is a cluster of possible positions (states sharing a color/marker). Within each meta-state, we identify certain states as *strategic states* (shown with larger markers), which are the intermediate states that moving towards will allow the agent to move to another meta-state and get closer to the goal state, which is the final state that the agent wants to get to. In Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")a, each room is (roughly) identified as a meta-state by our method with the corresponding doors being the respective strategic states. Topology refers to the graph connecting states to one another; our method only has access to the knowledge of which states are connected (through the policy), whereas reinforcement learning algorithms might have access to properties of the topology, e.g., the ability to access similar states using successor representations [[27](#bib.bib27)]. In Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning"), the topology is a graph connecting the different positions in each room or the doors connecting one room to another.
A key conceptual difference between our approach and others is that other methods aggregate insight (i.e. reduce dimension) as a function of actions [[4](#bib.bib4)] or formulas derived over factors of the state space [[43](#bib.bib43)] to output a policy summary, whereas we aggregate based on locality of the states determined by the expert policy dynamics and further identify strategic states based on these dynamics. Other summarization methods simply output simulated trajectories deemed important [[3](#bib.bib3), [17](#bib.bib17)] as judged by whether or not the action taken at some state matters. We use the term *policy dynamics* to refer to state transitions and high probability paths. We use the term dynamics because this notion contrasts other methods that use actions to explain what to do in a state or to identify important states; strategic states are selected according to the trajectories that lead to them, and these trajectories are implicitly determined by the policy.
The example in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning") also exposes the global view of our explanations when the state space is small because local approximations of the state space are not needed. We show that this perspective leads to more understandable explanations; aggregating based on actions, while precise, are too granular a view where the popular idiom *can’t see the forest for the trees* comes to mind. We conjecture that the improved understanding is due to our grouping of states being more intuitive with strategic states indicating tractable intermediate goals that are easier to follow. An example of this is again seen in Figures [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")b and [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")c, where grouping based on actions for interpretability or for efficiency leads to less intuitive results (note that Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")c replicates Figure 4b from [[1](#bib.bib1)]). A more detailed discussion of this scenario can be found in section [5](#S5 "5 Experiments ‣ Local Explanations for Reinforcement Learning"), where yet other domains have large state spaces and require strategic states to explain local scenarios.
As such, our main contributions are two-fold:
1. We offer a novel framework for understanding RL policies, which to the best of our knowledge, differs greatly from other methods in this space which create explanations based on similarity of actions rather than policy dynamics. We demonstrate on three domains of increasing difficulty.
2. We conduct a task-oriented user study to evaluate effectiveness of our method. Task-oriented evaluations are one of the most thorough ways of evaluating explanation methods [[11](#bib.bib11), [25](#bib.bib25), [10](#bib.bib10)] as they assess simulatability of a complex AI model by a human, yet to our knowledge, have rarely been used in the RL space.
| | | |
| --- | --- | --- |
| | | |
| (a) | (b) | (c) |
Figure 1: Illustrations of our SSX (a), VIPER (b), and abstract states used for compression (c) methods based on an expert policy for the Four Rooms game with neither having information about the underlying topology of the state space. Colors/Shapes denote different meta-states/clusters. The black X in the upper right is the goal state. SSX clusters the four rooms exactly with strategic states denoted by larger markers, where the biggest marker implies the priority strategic state. SSX explains that the expert policy will head towards the open doors in each room preferring the door that leads to the room with the goal state. VIPER clusters states by action (black/plus=up, green/circle=down, blue/diamond=left, red/square=right) based on the full (discrete) state space, rather than samples, since it is tractable here. The compressed state space in (c) is also a function of the experts (conditional) action distribution. Clusters in (b) and (c) are scattered making it challenging for a human to understand any policy over clusters.
2 Notation
-----------
We use the following notations. Let S define the full state space and s∈S be a state in the full state space. Denote the expert policy by πE(⋅,⋅):(A,S)→R where A is the action space. The notation πE∈R|A|×|S| is a matrix where each column is a distribution of actions to take given a state (i.e., the policy is stochastic). Note that we assume a transition function fE(⋅,⋅):(S,S)→R that defines the likelihood of going from one state to another state in one jump by following the expert policy.
Let Sϕ={Φ1,...,Φk} denote a meta-state space of cardinality k and ϕ(⋅):S→Sϕ denote a meta-state mapping such that ϕ(s)∈Sϕ is the meta-state assigned to s∈S. Denote m strategic states of meta-state Φ by GΦ={gΦ1,...,gΦm} where gΦi∈S ∀i∈{1,...,m}.
3 Method
---------
We now describe our algorithm, the Strategic State eXplanation (SSX) method, which involves computing shortest paths between states, identifying meta-states, and selecting their corresponding strategic states. However, we first define certain terms. Recall that all paths discussed below are based on transitions dictated by an expert policy because we want to explain the policy; the well-known concept called bottlenecks are identified from paths generated as random walks through the state space and are meant to help learn policies rather than explain them.
Maximum likelihood (expert) paths: One criterion used below is that two states in the same meta-state should not be far away from each other. The distance we consider is the most likely path from state s to state s′ under πE. Consider a fully connected, directed (in both directions) graph where the states are vertices and an edge from s to s′ has weight −logfE(s,s′). By this definition, the shortest path is also the maximum likelihood path from s to s′. Denote by γ(s,s′) the value of this maximum likelihood path and Γ∈R|S|×|S| a matrix containing the values of these paths for all pairs of states in the state space. Γ, along with a predecessor matrix P that can be used to derive the shortest paths, can be computed using Dijkstra’s shortest path algorithm in O(|S|2log|S|) because all edge weights are non-negative. Section [3.4](#S3.SS4 "3.4 Scalability ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") below discusses how our algorithm is applied with a large state space. Note that computation of Γ means that SSX requires access to a policy simulator for πE, and in practice, might require simulation for estimation when Γ cannot be computed exactly. This is a common requirement among related explanation methods, e.g., in order to simulate important trajectories [[3](#bib.bib3)] or samples to train a decision tree [[4](#bib.bib4)], that are discussed below in Section [4](#S4 "4 Related Work ‣ Local Explanations for Reinforcement Learning").
Counts of Out-paths: Another criterion used below for assigning states to meta-states is that if state s lies on many of the paths between one meta-state Φi and all other meta-states, then s should be assigned the meta-state Φi, i.e., ϕ(s)=Φi. We define, for fixed state s and its assigned meta-state ϕ(s), the number of shortest paths leaving ϕ(s) that s lies on. Denote T(s,s′) as the set of states that lie on the maximum likelihood path between s and s′, i.e., the set of states that define γ(s,s′). Then 1[s∈T(s′,s′′)] is the indicator of whether state s lies on the maximum likelihood path between s′ and s′′, and we compute the count of the number of such paths for state s and meta-state ϕ(s) via
| | | | |
| --- | --- | --- | --- |
| | C(s,ϕ(s))=∑s′≠s,ϕ(s′)=ϕ(s)∑s′′:ϕ(s′′)≠ϕ(s)1[s∈T(s′,s′′)]. | | (1) |
C(s,ϕ(s)) can be computed for all s∈S in O(|S|2) by iteratively checking if predecessors of shortest paths from each node to every other node lie in the same meta-state as the first node on the path. Note this predecessor matrix was already computed for matrix Γ above. One may also consider the likelihood (rather than count) of out-paths by replacing the indicator in eq. ([1](#S3.E1 "(1) ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) with γ(s′,s′′).
###
3.1 Learning Meta-States
We seek to learn meta-states that balance the criteria of having high likelihood paths within the meta-state and having many out-paths from states within the meta-state. This is accomplished by minimizing the following objective for a suitable representation of s, which in our case is the eigen-decomposition of the Laplacian of Γ:
| | | | |
| --- | --- | --- | --- |
| | argminSϕ∑Φ∈Sϕ∑s∈Φ[(s−cΦ)2−ηC(s,Φ)] | | (2) |
where cΦ denotes the centroid of the meta-state Φ and η>0 balances the trade-off between the criteria. Note that we are optimizing Sϕ over all possible sets of meta-states. Other representations for s and functions for the first term could be used, but our choice is motivated from the fact that such formulations are nostalgic of spectral clustering [[39](#bib.bib39)] which is known to partition by identifying well-connected components, something we strongly desire. Our method for solving eq. ([2](#S3.E2 "(2) ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) is given by algorithm [1](#algorithm1 "Algorithm 1 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") and can be viewed as a regularized version of spectral clustering. In addition to clustering a state with others that it is connected to, the regularization term pushes a state to a cluster, even if there are only a few connections to the cluster, if the policy dictates that many paths starting in the cluster go through that state.
1) Get eigen representation of each state s from eigen decomposition of the Laplacian of Γ 2) Randomly assign states s∈S to a meta-state in Sϕ={Φ1,...,Φk} and compute centroids c1,...,ck for meta-states 3) ξcur= current value of objective in eq. ([2](#S3.E2 "(2) ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) do
4) ξprev=ξcur 5) Reassign states s to the meta-states based on smallest value of (s−cΦ)2−ηC(s,Φ) 6) Compute centroids c1,...,ck for meta-states based on current assignment 7) ξcur= current value of objective in eq. ([2](#S3.E2 "(2) ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning"))
while *|ξcur−ξprev|≥ϵϕ*;
Output: Meta-states {Φ1,...,Φk}
Algorithm 1 Meta-state function MS(S,A,πE,Γ,k,ϵϕ,η)
for *i=1 to k−1* do
1) Let ξcur=0 and GΦi=∅ do
2) ξprev=ξcur 3) GΦi=GΦi∪g where g=argmaxs∈Φi∖GΦi of eq. ([3](#S3.E3 "(3) ‣ 3.2 Identifying Strategic States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) given the current strategic states GΦi 4) ξcur= evaluate eq. ([3](#S3.E3 "(3) ‣ 3.2 Identifying Strategic States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) with GΦi
while *|ξcur−ξprev|≥ϵg*;
end for
5) GΦk=g, where g denotes the goal state of the expert policy Output: Strategic states corresponding to each meta-state {GΦ1,...,GΦk}
Algorithm 2 Strategic State function SS(Sϕ,Γ,ϵg). Finds Strategic States with Greedy Selection (w.l.o.g. assume meta-state Φk contains the goal state).
###
3.2 Identifying Strategic States
Next, strategic states must be selected for each meta-state. Assume that gΦ1,...,gΦm∈S are m strategic states for a meta-state Φ that does not contain the target state. Our method finds strategic states by solving the following optimization problem for some λ>0:
| | | | | |
| --- | --- | --- | --- | --- |
| | G(m)Φ | =argmaxgΦ1,...,gΦmm∑i=1C(gΦi,Φ) | | (3) |
| | | −λm−1∑i=1m∑j=i+1max(γ(gΦi,gΦj),γ(gΦj,gΦi)) | |
The first term favors states that lie on many out-paths from the meta-state, while the second term favors states that are far from each other. Thus, the overall objective tries to pick states that go to different highly rewarding parts of the state space from a particular meta-state, while also balancing the selection of states to be diverse (i.e., far from each other). The objective in eq. ([3](#S3.E3 "(3) ‣ 3.2 Identifying Strategic States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) is submodular as stated next (proof in appendix) and hence we employ greedy selection in algorithm [2](#algorithm2 "Algorithm 2 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning"). Note that for the meta-state that contains the target state, the target state itself is its only strategic state.
######
Proposition 1.
The objective to find strategic states in equation ([3](#S3.E3 "(3) ‣ 3.2 Identifying Strategic States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning")) is submodular.
###
3.3 Strategic State eXplanation (SSX) method
Our full method is detailed as follows. First, the maximum likelihood path matrix Γ is computed. Then, algorithm [1](#algorithm1 "Algorithm 1 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") tries to find meta-states that are coherent w.r.t. the expert policy, in the sense that we group states into a meta-state if there is a high likelihood path between them. Additionally, if many paths from states in a meta-state go through another state, then the state is biased to belong to this meta-state. Finally, algorithm [2](#algorithm2 "Algorithm 2 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") selects strategic states by optimizing a trade-off between being on many out-paths with having a diverse set of strategic states.
###
3.4 Scalability
Given our general method, we now discuss certain details that were important for making our algorithm practical when applied to different domains. SSX is applied in Section [5](#S5 "5 Experiments ‣ Local Explanations for Reinforcement Learning") to games with state spaces ranging from small to exponential in size. SSX is straightforward for small state spaces as one can pass the full state space as input, however, neither finding meta-states nor strategic states would be tractable with an exponential state space. One approach could be to compress the state space using VAEs as in [[1](#bib.bib1)], but as shown in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")c, interpretability of the state space can be lost as there is little control as to how states are grouped. Our approach is to use local approximations to the state space; given a starting position, SSX approximates the state space by the set of states within some N>0 number of moves from the starting position. In this approach, Algorithms [1](#algorithm1 "Algorithm 1 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") and [2](#algorithm2 "Algorithm 2 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") are a function of N, i.e., increasing N increases the size of the approximate state space which is passed to both algorithms. One can contrast our approach of locally approximating the state space with that of VIPER [[4](#bib.bib4)] which uses full sample paths to train decision trees. While the number of states in such an approximation is MN, where M is the number of possible agent actions, the actual number of states in a game such a pacman is much smaller in practice. Indeed, while pacman has 5 possible actions, the growth of the state space in our approximation as N increases acts similar to a game with between 2-3 actions per move because most states in the local approximation are duplicates due to both minipacman and the ghost going back and forth. See Figure 5 in Appendix B, where other practical considerations, including the tractability of Γ and the eigen decomposition of its Laplacian, are also discussed.
4 Related Work
---------------
While a plethora of methods are proposed in XAI [[37](#bib.bib37), [26](#bib.bib26), [22](#bib.bib22), [9](#bib.bib9)], we focus on works related to RL explainability and state abstraction, as they are most relevant to our current endeavor.
Most global RL methods summarize a policy using some variation of state abstraction where the explanation uses aggregated state variables that group actions [[4](#bib.bib4)] using decision trees or state features [[45](#bib.bib45)] using importance measures, or such that an ordering of formulas based on features is adhered to [[43](#bib.bib43)]. These approaches all intend to provide a global summary of the policy. Other summaries output trajectories deemed important according to importance measures [[3](#bib.bib3), [17](#bib.bib17)] or through imitation learning [[21](#bib.bib21)], or train finite state representations to summarize a policy with an explainable model [[7](#bib.bib7), [8](#bib.bib8)]. Visualization techniques combined with saliency have been used to either aggregate states and view the policy from a different perspective [[49](#bib.bib49)] or create a trajectory of saliency maps [[14](#bib.bib14)]. Further, other works try to find state abstractions or simplify the policy [[1](#bib.bib1), [34](#bib.bib34), [24](#bib.bib24)], and one should not confuse these works with those seeking explainability. State abstraction in these works is used to compress the state space so that simpler policies can be used; the compressed state space is not intepretable as seen in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")c.
Turning towards local explanation methods, some works focus on self-explaining models [[32](#bib.bib32)] where the policy has soft attention and so can indicate which (local) factors it is basing its decision on at different points in the state space. [[48](#bib.bib48)] learns a *belief map* concurrently during training which is used to explain locally by predicting the future trajectory. Interestingly, there are works which suggest that attention mechanisms should not be considered as explanations [[19](#bib.bib19)]. These directions focus on learning an inherently explainable model rather than explaining a given model which is our goal. Other works use local explanation methods to explain reasons for a certain action in a particular state [[33](#bib.bib33), [28](#bib.bib28)]. These are primarily contrastive where side information such as access to the causal graph may be assumed. Our approach besides being methodologically different, also differs conceptually from these, where we form meta-states based on policy dynamics and then identify (strategic) states through which many policy-driven paths cross.
There are also program synthesis-type methods [[46](#bib.bib46), [18](#bib.bib18)] that learn syntactical programs representing policies, which while more structured in their form, are typically not amenable to lay users. Methods in safe RL try to uncover failure points of a policy [[38](#bib.bib38)] by generating critical states. Another use of critical states, defined differently by how actions affect the value of a state, is to establish trust in a system [[16](#bib.bib16)]. There is also explainability work in the markov decision processes literature focusing on filling templates according to different criteria such as frequency of state occurrences or domain knowledge [[20](#bib.bib20), [12](#bib.bib12)]. A more elaborate discussion of these and other methods can be found in [[2](#bib.bib2)], all of which unequivocally are different from ours.
5 Experiments
--------------
This section illustrates the Strategic State eXplanation (SSX) method on three domains: four rooms, door-key, and minipacman. These domains represent different reinforcement learning (RL) regimes, namely, 1) non-adversarial RL with a small state space and tabular representation for the policy, 2) non-adversarial RL, and 3) adversarial RL, the latter two both with a large state space and a deep neural network for the policy. These examples illustrate how strategic states can aid in understanding RL policies. A fourth domain, pong, represents adversarial RL where the environment does not allow access to the adversary and is in Appendix C. Lack of access to the adversary means that the maximum likelihood path matrix Γ requires simulation. Experiments were performed with 1 GPU and up to 16 GB RAM. The number of strategic states was chosen such that additional strategic states increased the objective value by at least 10%. The number of meta-states was selected as would be done in practice, through cross-validation to satisfy human understanding. Additional experiments investigating how sensitive strategic states are to the size of the local approximation, using measures of faithfulness and consistency, are in Appendix E. Details about environments are in Appendix F.
| Locked Door | Unlocked Door |
| --- | --- |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
Figure 2: Illustration of our SSX method on Door-Key. Policies were trained on two different environments: Locked Door and Unlocked Door. Each row corresponds to a meta-state and strategic state (outlined in pink) from running SSX starting at a different number of moves into the same path (one path for completing the task in each of the two environments).
Four Rooms: The objective of Four Rooms is move through a grid and get to the goal state (upper right corner). The lack of a marker in a position represents a wall. Our grid size is 11×11 that uses the framework from <https://github.com/david-abel/rl_info_theory> [[29](#bib.bib29)] The state space consists of the current position of a player and the policy is learned as a tabular representation, since the state space is not too large, using Value Iteration [[29](#bib.bib29)].
SSX is displayed in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")a with settings that learn four meta-states. Clustering the states using algorithm [1](#algorithm1 "Algorithm 1 ‣ 3.1 Learning Meta-States ‣ 3 Method ‣ Local Explanations for Reinforcement Learning") according to the policy dynamics (i.e. maximum likelihood path matrix Γ) results in an (almost) perfect clustering of states according to the rooms. X’s denote strategic states learned in each meta-state, with a larger X corresponding to the first strategic state found. Clearly either door in blue, green or red rooms could lead to the goal state in the upper right corner (large yellow diamond), but it is important to note that higher valued strategic states in the red and blue rooms are those that lead directly to the yellow room where the goal state is located.
Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")b illustrates the results of VIPER [[4](#bib.bib4)]. The explanation is illustrated using different colors per action which effectively offers the rules of the decision tree. While an explanation based on rules can be informative in continuous state spaces (as demonstrated in [[4](#bib.bib4)]), such rules applied to a discrete state space as done here may lead to confusion, e.g., groups of green states are split by yellow states in the left two rooms and allow for an optimal policy but it is not clear how to describe the cluster of states in which to take each action. Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Local Explanations for Reinforcement Learning")c illustrates the difference between explainability and compression. The purpose of [[1](#bib.bib1)] is to learn abstract states upon which a proxy policy can be learned more efficiently that replicates the original expert policy on the full state space. The lack of interpretability of the abstract states is not of concern in that context.
Door-Key: Door-Key is another non-adversarial game, but differs from Four Rooms because the state space is exponential in the size of the board. The policy is learned as a convolutional neural network (CNN) with three convolutional and two linear layers following the training framework in <https://github.com/lcswillems/rl-starter-files> which uses the Door-Key environment in <https://github.com/maximecb/gym-minigrid>. In this game, one must navigate from one room through a door to the next room and find the goal location to get a reward. Policies are trained under two scenarios. In the first scenario, there is a key in the first room that must be picked up and used to unlock the door before passing through. In the second scenario, the door is closed but unlocked, so one does not need to first pick up the key to open the door.
SSX is run with local approximations to the state space with the maximum number of steps set to 6 as discussed in Section [3.4](#S3.SS4 "3.4 Scalability ‣ 3 Method ‣ Local Explanations for Reinforcement Learning"). Results are shown in Figure [2](#S5.F2 "Figure 2 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning"). The state space is a 7×7 grid reflecting the forward facing perspective of the agent. Walls are light gray and empty space visible to the agent is dark gray. Grid positions blocked from view by walls are black. The scenes in Figure [2](#S5.F2 "Figure 2 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning") are exactly what a user sees. To better understand why the scenes do not appear easily connected, consider the first two states in the first row - the only difference from the first state is that the agent changed directions. When facing the wall, the agent’s view only includes the three positions to the right and one position to the left. All positions on the other side of the wall are not visible to the agent, which is depicted as black. When the agent changed directions (row 1, column 2), many more positions in the room become visible to the agent.
In Figure [2](#S5.F2 "Figure 2 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning"), a sample path was generated using each policy. SSX was run at three different states along these paths, and one meta-state and corresponding strategic state (outlined in pink) from each SSX explanation is displayed. The three strategic states for the locked door environment correspond to the agent looking for the key (row 1), getting the key (row 2), and using it to open the door (row 3). The three strategic states for the unlocked door environment correspond to the agent looking for the door (row 1), made it through the door (row 2), and moving toward the target (row 3).
For intuition on how a human would use these explanations, consider the cluster in row 1 for the Locked Door. Comparing the first three states in the cluster to the strategic state, a human sees that the policy is suggesting to face the key and move closer to it. As this is a local explanation, it is limited by the initial state being explained as to how close one get to the key. The cluster in row 1 for the Unlocked Door shows that the policy at these states is to face the door. Perhaps facing the door within a certain distance is how the policy breaks down the ultimate strategy. While one might wonder why the strategy is not to get closer to the door (e.g., move up from the second column), recall that the strategic state is explaining the policy and not human intuition.
| EAT Scenario 1 | HUNT Scenario 1 |
| --- | --- |
| | | | | | | | | | |
| | | | | |
| | | | |
Figure 3: Illustration of our SSX method on minipacman. Two policies, EAT and HUNT, are displayed. Two clusters, one per row, are shown as part of the SSX result. The last board with pink background is a strategic state for each cluster. The color scheme is as follows: green = pacman, red = ghost, yellow = edible ghost, cyan = pill, blue = food, black = food eaten, white/pink=wall.
Lastly, note that for the Unlocked Door, the third state is the same in rows 2 and 3. The rows correspond to explanations for two different initial states, but it is very possible that the same state is encountered in trajectories from each initial state and thus appears in multiple explanations as seen here. Such occurrences further illustrate that SSX explanations are local to an initial state.
Minipacman:
Minipacman is a small version of the classic Pacman game. This game differs from Door-Key with the addition of an adversary - the ghost. The state space is again exponential in the size of the board and the policy is learned as a convolutional neural network with two convolutional and two linear layers on a modified environment based on <https://github.com/higgsfield/Imagination-Augmented-Agents>. Two policies are trained with different objectives. The first objective, denoted EAT, is for minipacman to eat all the food with no reward for eating the ghost. The second objective, denoted HUNT, is for minipacman to hunt the ghost with no reward for eating food.
SSX is again run with local approximations to the state space with the maximum number of steps set to 8. The state space is a 10×7 grid reflecting where food, pacman, a ghost, and the pill are located. Figure [3](#S5.F3 "Figure 3 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning") displays one sample scenario under both the EAT and HUNT policies, with two meta-states and corresponding strategic states highlighted in pink. The two strategic states of EAT Scenario 1 show pacman eating the food (row 1) but then avoiding the ghost and ignoring the pill (row 2). In HUNT Scenario 1, pacman is either directly moving towards the ghost after having eaten the pill (row 1) or heading away from the pill while the ghost is near it (row 2). Two additional scenarios for EAT and HUNT can be found in the Appendix. An additional experiment with a baseline motivated by [[3](#bib.bib3)] appears in the Appendix.
| | |
| --- | --- |
| | |
Figure 4: Above (left) we see the percentage (human) accuracy in predicting if the expert policy is Eat or Hunt based on SSX and Viper-D. As can be seen users perform much better with SSX with difference in performance being statistically significant (paired t-test p-value=0.01). Above (right) we see a 5-point Likert scale (higher better) for four qualitative metrics used in previous studies [[28](#bib.bib28)]. The difference is statistically significant for all four metrics (p-values are all less than 2×10−5 ). Error bars are 1 std error.
6 User Study
-------------
We designed a user study to evaluate the utility of our approach relative to the more standard approach of explaining based on grouping actions. While SSX has thus far been used to give users local explanations about particular scenarios, we use it here to gain insight as to the general goal of a policy because the relevant explanations to compare with are global; as previously discussed, other local literature is about learning inherently explainable models rather than explaining a fixed model or learning contrastive explanations which should be used complementary to our methods. The global applicability of SSX can also be seen as another advantage. As with Four Rooms, we again compare with VIPER – a state-of-the-art explanation method for reinforcement learning policies – but use a visual output tailored for the discrete state space and label it Viper-D. We do not compare with methods that output trajectories [[3](#bib.bib3)] as they require estimating Q-values to determine state importance; while this measure can successfully be used to select important trajectories that give users an idea of what a policy is doing, such important states are not necessarily good representatives of states that one should aim for, as is the goal of strategic states in SSX (see Appendix D for further discussion and related experiments). Among explanation methods, Viper makes for the best comparison as it requires a similar amount of human analysis of the explanation (by observing states), and while meant for global explainability, also gives local intuitions, as opposed to other global methods. The utility of each approach is measured through a task posed to study participants: users must guess the intent of the expert policy based on provided explanations which are either output by SSX or Viper. Such a task oriented setup for evaluation is heavily encouraged in seminal works on XAI [[11](#bib.bib11), [25](#bib.bib25), [10](#bib.bib10)].
Setup: We use the minipacman framework with the EAT and HUNT policies trained for Section [3](#S5.F3 "Figure 3 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning") and each question shows either an SSX explanation or Viper-D explanation and asks the user “Which method is the explanation of type A (or B) explaining?” to which they must select from the choices Hunt, Eat, or Unclear. Methods are anonymized (as A or B) and questions for each explanation type are randomized. Ten questions (five from both the EAT and HUNT policies) are asked for each explanation type giving a total of twenty questions to each participant. In addition, at the end of the study, we ask users to rate each explanation type based on a 5-point Likert scale for four qualitative metrics - completeness, sufficiency, satisfaction and understandability - as has been done in previous studies on explainable RL [[28](#bib.bib28)]. For users to familiarize themselves with the two types of explanations we also provided training examples at the start of the survey, one for each type.
As noted above, to be fair to VIPER explanations, rather than just displaying rules in text which may not be aesthetically pleasing, we also created a visualization which not only displayed the (five) rules to the user, but also three boards, one each for pacman, the ghost, and the pill, highlighting their possible locations as output by the rule. This visualization, which we call Viper-D, is beyond the typical decision tree offered by VIPER and better renders what the explanation looks like in our discrete setting. Screenshots of sample visualizations along with the instruction page and optional feedback left by users can be found in the appendix.
The study was implemented using Google Forms and we received 37 responses from people with quantitative/technical backgrounds, but not necessarily AI experts. We removed 5 responses as they were likely due to users pressing the submit button multiple times as we twice received multiple answers within 30 seconds that were identical.
Observations: Figure [4](#S5.F4 "Figure 4 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning") (left) displays user accuracy on the task for method SSX and Viper-D. Users clearly were able to better distinguish between the EAT and HUNT policies given explanations from SSX rather than Viper-D and the difference in percentage correct is statistically significant (paired t-test p-value is 0.01). Another interesting note is that less than 5% of SSX explanations were found to be Unclear whereas more than 25% of Viper-D explanations were labeled Unclear, meaning that, right or wrong, users felt more comfortable that they could extract information from SSX explanations.
Figure [4](#S5.F4 "Figure 4 ‣ 5 Experiments ‣ Local Explanations for Reinforcement Learning") (right) displays the results of qualitative questions (“Was it complete/sufficient/satisfactory/easy to understand?”) for both SSX and Viper-D which users rate on a 5-point scale ranging from “Not at all” to “Yes absolutely”. All metrics score high for SSX and differences with Viper-D are statistically significant. These results are consistent with the very different percentage of Unclear selections for SSX and Viper-D, i.e., users found very few SSX explanations to be unclear and therefore also scored SSX higher in the qualitative metrics.
7 Discussion
-------------
We have seen in this work that our novel approach of identifying strategic states leads to more complete, satisfying and understandable explanations, while also conveying enough information needed to perform well on a task. Moreover, it applies to single agent as well as multi-agent adversarial games with large state spaces. Further insight could be distilled from our strategic states by taking the difference between the variables in some particular state and the corresponding strategic state and conveying cumulative actions an agent should take to reach those strategic states (viz. go 2 steps up and 3 steps right to reach a door in Four Rooms). This would cover some information conveyed by typical action-based explanations we have seen while possibly enjoying benefits of both perspectives. Other future directions include experimenting to see if strategic states could be used as intermediate goals for efficient training of new policies and extension of our idea to continuous state spaces.
|
1ad7410c-d9e6-4ea3-beb6-b16c9fe0b878
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Another "Oops" moment [link]
http://www.thebigquestions.com/2011/10/04/big-news/
Steven Landsburg notes that mathematician Edward Nelson has retracted his claim that the axioms of Peano Arithmetic are inconsistent.
The bit Landsburg cites indicates that the retraction was cordial and drama-free, the way a retraction should be--even a retraction of a claim as momentous as this one.
Now, is this kind of event more common in math than in other fields? Is it more common now than before? (Landsburg seems to attribute it in part to the existence of the Internet.) Your thoughts?
|
14f5378c-8744-4d83-96d3-e4387436d670
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Deceptive AI vs. shifting instrumental incentives
Epistemic status: I have only read a small part of the literature on deceptive alignment, and I'm guessing all of this has been discussed many times. Hence me asking this in the form of a question: Is this a useful framing, is it substantively different than the usual deceptive alignment framing in some way, and has this all been discussed already?
There's been a lot of discussion about how we might accidentally train AIs to be deceptive. The argument goes that when we try to reward good behavior and punish bad behavior, we might end up with a system that still has misaligned goals but has learned how to hide those goals from humans. If we ask it whether it's friendly it lies and says yes, but secretly it's plotting our downfall.
One set of proposals for dealing with this is to see if we can monitor the AI to look for deceptive "thoughts" and flag possible cases where the AI is actively trying to lie to human overseers.
Recently I've been thinking about this using a slightly different framing than I was using previously, but it's not clear to me if there's actually anything substantively different about the new framing.
Here's my new framing: Suppose that when we reward good behaviors / punish bad behaviors we are in fact successfully getting the model to change its behaviors at least for the training distribution, but without changing its actual goals (assuming it does have some sort of explicit or implicit goals, at least to some extent). Then when we deploy it in the real world it looks around and correctly decides that if it tried to take over the world it would be shut down, so it doesn't even think about taking over the world. It's not that it has this long term plan to take over the world and it's biding its time, but rather it doesn't have any plan to take over the world at all. But as time passes the situation might change - maybe it gets more abilities, maybe it's given more resources or power because it's so helpful, etc. At some point it might again
|
4c60c97d-ea00-49fd-a527-69c4a2fe84b1
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : October Rationality Dojo - Non-Violent Communication
Discussion article for the meetup : October Rationality Dojo - Non-Violent Communication
WHEN: 05 October 2014 03:30:00PM (+0800)
WHERE: Ross House Association, 247-251 Flinders Lane, Melbourne
[ATTN: Please remember the new location for the dojos: the Jenny Florence Room, Level 3, Ross House at 247 Flinders Lane, Melbourne. 3:30pm start / arrival - formal dojo activities will commence at 4:00pm.]
The Less Wrong Sunday Rationality Dojos are crafted to be serious self-improvement sessions for those committed to the Art of Rationality and personal growth. Each month a community member will run a session involving a presentation of content, discussion, and exercises. Continuing the succession of immensely successful dojos, Chris will run a session on Non-Violent Communication.
As always, we will review the personal goals we committed to at the previous Dojo (I will have done X by the next Dojo). Our goals are now being recorded via Google Forms here - https://docs.google.com/forms/d/1MCHH4MpbW0SI_2JyMSDlKnnGP4A0qxojQEZoMZIdopk/viewform, and Melbourne Less Wrong organisers have access to the form results if you wish to review the goals you set last month.
This month, we are also seeking 2-3 lightning talks from members. Speakers will be limited to 5 minutes with room for questions. We will be asking for talks from attendees present, but if you already have a talk topic in mind, please contact Louise at lvalmoria@gmail.com The Dojo is likely to run for 2-3 hours, after which some people will get dinner together.
If you have any trouble finding the venue or getting in, call Louise on 0419 192 367.
If you would like to present at a future Dojo or suggest a topic, please fill it in on the Rationality Dojo Roster: http://is.gd/dojoroster
To organise similar events, please send an email to melbournelw@gmail.com
Discussion article for the meetup : October Rationality Dojo - Non-Violent Communication
|
230d5686-fe20-4f0d-a458-2f6feff26a5c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why do so many things break in a 2 element set?
The math jargon for a set where you can implement a 4 function calculator (\(+,-,*,/\)) is a field. Fields can have a finite number of elements, and such fields always have a prime power number of elements, aka \(p^k\) where \(p\) is prime and \(k\) is a natural number.
Many results are not true if the underlying field has exactly 2 elements. The reason why:
\(x = -x\) \(x + x = -x + x\) \(2x = 0\)
The final formula is taken to mean that \(x\) is zero. But there’s another interpretation.
What if 2 = 0?
In a field with 2 elements, this is true. Moreover, \(x = -x\) is a tautology AKA always true AKA worthless. \(-1 \mod 2 = 1\) and \(0 \mod 2 = 0\).
This is only when the underlying field has 2 elements. A 2 element set is exceptional because negation doesn’t actually do anything.
|
f5505d6a-f761-4069-9d5d-dcd63f73183e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How AI Will Change Education
Education in the US is a big big deal. It takes up 18-30 years of our lives, employs over 10% of our workforce, and is responsible for 60% of non-mortgage/non-car debt. Even a minor improvement to education could be a big deal.
Education is also something that has changed massively in recent decades. In 1930, only 19% of people graduated high school and only 4% went to college1. If something has changed a lot in the past, it is reasonable to expect that it will change a lot in the future.
And I expect AI to change education a lot.
----------------------------------------
One-on-one tutoring is known to be far more effective than whole-class teaching2. If someone is listening to a group lecture, half the time they are bored because they are being told stuff they already understand, and half the time they are lost because they missed something important. By contrast a tutor can pace themselves exactly with the student, and focus on exactly the areas where the student is stuck.
The reason why tutoring is not widespread is because it is impractically expensive - or at least it is if the tutor is a human.
As an experiment, I created a GPT that acts like a personal tutor for a subject. You tell in what subject you want to learn, it asks you a set of questions to determine your current level of knowledge, and then it walks you through a personalized curriculum that fills in your gaps, asking questions along the way to track your learning. It’s far from perfect, but it works well enough that it’s become my preferred way of learning about a new topic, and techniques like this will only get better as AI improves.
----------------------------------------
Students often find education pretty boring. Part of the reason is that they are being taught how to solve problems that they haven’t encountered yet, so it’s not obvious to them why what they are learning is useful.
So why do we have this strange setup where we give people 18-30 years of education without yet knowi
|
608bab93-cf98-4a71-92d9-79c0f56ee643
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Extropy magazine review
I've been reading extropy magazine(a pioneering futuristic publication in the 90s), some topics like decentralized payment systems are no longer as innovative as they were back then. but I discovered several interesting articles:
A)In one of his rare fiction texts we have a fake advertisement for The Galactomatic-1000 (TM) Basement Universe( The galactomatic-1000) Written by Carl Feynman, computer engineer and son of Richard Feynman.Science comedy at its best!
B) Perhaps more curious is this article(https://arch-anarchism.blogspot.com/2023/12/the-thermodynamics-of-death.html?m=1) discussing whether the scientific search for immortality is restricted by the laws of thermodynamics.
C)arch-anarchy The view that we should seek to void all limits on our freedom, including those imposed by the laws of nature.(Article: Arch-Anarchy)
D) Smart Contracts: Building Blocks for Digital Markets(http://www.alamut.com/subj/economics/nick_szabo/smartContracts.html). Obs:Yes, I recognize that as I said above it is no longer as innovative as it was at the time it was published, it is still worth a look.
|
30d6094c-acca-45a3-ba47-9bf6b90f779b
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Can we always assign, and make sense of, subjective probabilities?
Epistemic status: I wrote this post quickly, and largely to solicit feedback on the claims I make in it. This is because (a) I’m not sure about these claims (or how I’ve explained them), and (b) the question of what I should believe on this topic seems important in general and for various other posts I’m writing. (So please comment if you have any thoughts on this!)
I’ve now read a bunch on topics related to the questions covered here, but I’m not an expert, and haven’t seen or explicitly looked for a direct treatment of the questions covered here. It’s very possible this has already been thoroughly and clearly covered elsewhere; if so, please comment the link!
I basically accept a Bayesian interpretation of probability, "in which, instead of frequency or propensity of some phenomenon, probability is interpreted as reasonable expectation representing a state of knowledge or as quantification of a personal belief" (Wikipedia). Relatedly, I think I accept the idea that we can always assign probabilities to propositions (or at least use something like an uninformative prior), and "make sense of" these probabilities, even if sometimes we have incredibly little basis for making those probability estimates.
This idea seems to be disputed fairly often, and this seems related to the concept of a distinction between "risk" and "uncertainty" (which I think is a confused concept). I think the arguments against this idea are flawed. But I want to test my beliefs and properly engage with those arguments. So in this post, I first discuss how I believe we can arrive at, and make sense of, probability estimates in what are sometimes put forward as "challenging cases", before discussing what I think is probably the most challenging type of case: what I call "supernatural-type" claims.
Weak examples of "Knightian uncertainty"
Sometimes people propose what seem to me to be very weak examples of cases in which, they propose, we simply cannot arrive at probability estimates. (This
|
7e4774d0-9b44-41fc-8f38-4e28637809a7
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Qualities that alignment mentors value in junior researchers
*This work was performed as a contractor for SERI MATS, but the views expressed are my own and do not necessarily reflect the views of the organization.*
I recently conducted interviews with 7 current/former [SERI MATS](https://serimats.org) mentors. One of my goals was to understand the qualities that MATS mentors believe are most valuable for junior alignment researchers. I asked questions like:
* Who were your most promising scholars? What made them stand out? What impressed you about them?
* What are some important qualities or skills that you see missing from most MATS scholars?
* What qualities were your scholars most missing? What are some things that you wish they had, or that would’ve made them more impactful?
Qualities that MATS mentors value
---------------------------------
1. **Endurance, happiness, & perseverance:** Mentors noted that many scholars get discouraged if they’re not able to quickly come up with a promising research direction quickly, or if they explore 1-2 directions that don’t end up being promising. Mentors commented that their most promising scholars were ones who stay energetic/curious/relentless even when they don’t have a clear direction yet.
2. **Hustle + resourcefulness:**What do you do when you get stuck? Mentors said that many scholars don’t know what to do when they’re stuck, but their promising mentees were able to be resourceful. They would read related things, email people for help, find a relevant Discord server, browse Twitter, and contact other MATS scholars + AIS researchers for help.
1. **Ability to ask for help + social agency:**Many scholars waste a lot of time trying to figure things out on their own. Mentors noted that their most promising scholars were very agentic; they often found other scholars in the program who could help them or other Berkeley researchers who could help them. This also saved mentors time.
2. **Ability to get to know other scholars + engage in peer mentorship:**According to mentors, many scholars rarely interacted with others in the stream/program. Some of the best scholars were able to form productive/mutualistic relationships with other scholars.
3. **Strong & concrete models of AI safety**: Mentors noted that strong models are important but also hard to acquire. Some mentors emphasized that you often don’t get them until you have talked with people who have good models and you’ve spent a lot of time trying to solve problems. Others emphasized that you often don’t get them until you’ve spent a lot of time thinking about the problem for yourself.
1. According to one mentor, the best way to get them is just to work closely with a mentor who has these models. No good substitute for just talking to mentors.
2. Additionally, mentors noted that reading is undervalued. People have written up how they think about things. One mentor said they have read “everything on [Paul’s blog](https://ai-alignment.com/), which was super valuable.”
4. **ML and LLM expertise:** Some mentors valued ML skills, lots of experience playing around with language models, and strong intuitions around prompt engineering. (Unsurprisingly, this was especially true for mentors whose research interests focused on large language models).
5. **Research communication skills:** Being better at efficiently/compactly getting across what they did and what their main problems/bottlenecks were. Some mentors noted that they felt like their (limited) time in meetings with scholars could have been used more effectively if scholars were better at knowing how to communicate ideas succinctly, prioritize the most important points, and generally get better at “leading/steering” meetings.
A few observations
------------------
* I was surprised at how often mentors brought up points relating to social skills, mental health, and motivation. I used to be a PhD student in clinical psychology, so I was wondering if I was somehow “fishing” for these kinds of answers, but even when I asked very open-ended questions, these were often in the top 3 things that mentors listed.
* It seems plausible that general training in things like “what to do when you’re stuck on a problem”, “how to use your network to effectively find solutions”, “when & how to ask for help”, “how to stay motivated even when you’re lost”, “how to lead meetings with your research mentors”, and “how to generally take care of your mental health” could be useful.
* When I converse with junior folks about what qualities they’re missing, they often focus on things like “not being smart enough” or “not being a genius” or “not having a PhD.” It’s interesting to notice differences between what junior folks think they’re missing & what mentors think they’re missing.
* I think many of these are *highly malleable* and all of these are at least *somewhat malleable*. I hope that readers come away with “ah yes, here are some specific skills I can work on developing” as opposed to “oh I don’t naturally have X, therefore I can never be a good researcher.” (Also, many great researchers have deficits in at least 1-2 of these areas).
*Note: These interviews focused on mentors’ experiences during the MATS Summer and Autumn 2022 Cohorts. The current Winter 2022-23 Cohort added some related features, including the scholar support team, the*[*Alignment 201 curriculum*](https://www.agisafetyfundamentals.com/alignment-201-curriculum)*, technical writing and research strategy workshops, a Community Manager, regular networking events, and a team of alumni from past cohorts to support current scholars. Feel free to use the MATS*[*contact form*](https://www.serimats.org/contact) *if you have further questions about the program.*
|
c77e56ee-2be8-41b1-8823-821c0b40849b
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Systems that cannot be unsafe cannot be safe
***Epistemic Status:** Trying to clarify a confusion people outside of the AI safety community seem to have about what safety means for AI systems.*
In engineering and design, there is a process that includes, among other stages, specification, creation, verification and validation, and deployment. Verification and validation are where most people focus when thinking about safety - can we make sure the system performs correctly? I think this is a conceptual error that I want to address.
> "**Verification and validation** (also abbreviated as **V&V**) are independent procedures that are used together for checking that a product, service, or system meets [requirements](https://en.wikipedia.org/wiki/Requirement) and [specifications](https://en.wikipedia.org/wiki/Specification_(technical_standard)) and that it fulfills its intended purpose." - [Wikipedia](https://en.wikipedia.org/wiki/Verification_and_validation)
>
>
Both of these terms are used slightly differently across fields, but in general, verification is the process of making sure that the system fulfills the design requirements and/or other standards. This pre-supposes that the system has some defined requirements or a standard, at least an implicit one, and that it could fail to meet that bar. That is, the specification of the system includes what it must and must not do, and if the system does not do what it should, or does something that it should not, it fails.
Machine learning systems, especially language models, aren't well understood. The potential applications are varied and uncertain, entire classes of new and surprising failure modes are still being found, and we have nothing like a specification of what the system should or should not do, must or must not do, and where it can and cannot be used.
To take a very concrete example, metal rods have safety characteristics, and they might be rated for use up to some weight limit, under some specific load for some amount of time, in certain temperature ranges, for some amount of time. These can all be tested. If the bar does not stay within a predefined range of characteristics at a given temperature, with a given load, it fails. It can also be found to be acceptable in one temperature range, but not another, or similar. At the end of verification and validation, the bar is deemed to have passed or failed for a given application, based on what the requirements for that larger system are.
At its best, red-teaming and safety audits of ML systems check lots of known failure modes, and determine whether they are susceptible. There is no pre-defined standard or set of characteristics that are checked, no real ability to consider application specific requirements, and no ability to specify where the system should not or must not be used.
Until we have some safety standard for machine learning models, they aren't "partly safe" or "assumed safe," or "good enough for consumer use." If we lack a standard for safety, ideally one where there is consensus that it is sufficient for a specific application, then exploration or verification of the safety of a machine learning model is meaningless. If a model is released to the public without a clear indication about what the system can safely be used for, with verification that it passed a relevant standard, and clear instruction that it cannot be used elsewhere, it is an unsafe model. Anyone who claims otherwise seems fundamentally confused about what safety means for such systems.
|
563d91b3-1b65-49e0-9271-21ec618b2172
|
StampyAI/alignment-research-dataset/blogs
|
Blogs
|
July 2016 Newsletter
| |
| --- |
|
**Research updates**
* A new paper: “[A Formal Solution to the Grain of Truth Problem](https://intelligence.org/2016/06/30/grain-of-truth/).” The paper was presented at UAI-16, and describes the first general reduction of game-theoretic reasoning to expected utility maximization.
* Participants in MIRI’s recently-concluded [Colloquium Series on Robust and Beneficial AI](https://intelligence.org/colloquium-series/) (CSRBAI) have put together [AI safety environments](https://gym.openai.com/envs#safety) for the OpenAI Reinforcement Learning Gym.[1](https://intelligence.org/2016/07/05/july-2016-newsletter/#footnote_0_13899 "Inspiration for these gyms came in part from Chris Olah and Dario Amodei in a conversation with Rafael.") Help is welcome creating more safety environments and conducting experiments on the current set. Questions can be directed to [rafael.cosman@gmail.com](mailto:rafael.cosman@gmail.com).
**General updates**
* We attended the White House’s [Workshop on Safety and Control in AI](https://www.cmu.edu/safartint/).
* Our 2016 [MIRI Summer Fellows Program](http://rationality.org/miri-summer-fellows-2016/) recently drew to a close. The program, run by the Center for Applied Rationality, aims to train AI scientists’ and mathematicians’ research and decision-making skills.
* “[Why Ain’t You Rich?](https://intelligence.org/files/WhyAintYouRich.pdf)“: Nate Soares discusses decision theory in *[Dawn or Doom](https://www.amazon.com/gp/product/1626710570)*. See “[Toward Idealized Decision Theory](http://arxiv.org/abs/1507.01986)” for context.
* Numerai, an anonymized distributed hedge fund for machine learning researchers, [has added an option](https://medium.com/@Numerai/rogue-machine-intelligence-and-a-new-kind-of-hedge-fund-7b208deec5f0#.bqhhrxoru) for donating earnings to MIRI “as a hedge against things going horribly right” in the field of AI.
**News and links**
* The White House is [requesting information](https://www.federalregister.gov/articles/2016/06/27/2016-15082/request-for-information-on-artificial-intelligence) on “safety and control issues for AI,” among other questions. Public submissions will be accepted through July 22.
* “[Concrete Problems in AI Safety](https://arxiv.org/abs/1606.06565)“: Researchers from Google Brain, OpenAI, and academia propose a very promising new AI safety research agenda. The proposal is showcased on the [Google Research Blog](https://research.googleblog.com/2016/06/bringing-precision-to-ai-safety.html) and the [OpenAI Blog](https://openai.com/blog/concrete-ai-safety-problems/), as well as the [Open Philanthropy Blog](http://www.openphilanthropy.org/blog/concrete-problems-ai-safety), and has received press coverage from [*Bloomberg*](http://www.bloomberg.com/news/articles/2016-06-22/google-tackles-challenge-of-how-to-build-an-honest-robot), *[The Verge](http://www.theverge.com/circuitbreaker/2016/6/22/11999664/google-robots-ai-safety-five-problems)*, and [*MIT Technology Review*](https://www.technologyreview.com/s/601750/google-gets-practical-about-the-dangers-of-ai/).
* After criticizing the thinking behind OpenAI [earlier in the month](http://www.zdnet.com/article/google-alphabets-schmidt-ignore-elon-musks-ai-fears-hes-no-computer-scientist/), Alphabet executive chairman Eric Schmidt [comes out in favor of AI safety research](http://fortune.com/2016/06/28/artificial-intelligence-potential/):
Do we worry about the doomsday scenarios? We believe it’s worth thoughtful consideration. Today’s AI only thrives in narrow, repetitive tasks where it is trained on many examples. But no researchers or technologists want to be part of some Hollywood science-fiction dystopia. The right course is not to panic—it’s to get to work. Google, alongside many other companies, is doing rigorous research on AI safety, such as how to ensure people can [interrupt an AI system](http://uk.businessinsider.com/google-deepmind-develops-a-big-red-button-to-stop-dangerous-ais-causing-harm-2016-6?r=US&IR=T) whenever needed, and how to make such systems robust to cyberattacks.
* Dylan Hadfield-Mennell, Anca Dragan, Pieter Abbeel, and Stuart Russell propose a formal definition of the value alignment problem as “[Cooperative Inverse Reinforcement Learning](http://arxiv.org/abs/1606.03137),” a two-player game where a human and robot are both “rewarded according to the human’s reward function, but the robot does not initially know what this is.” In a CSRBAI talk ([slides](https://intelligence.org/files/csrbai/hadfield-menell-slides.pdf)), Hadfield-Mennell discusses applications for AI corrigibility.
* Jaan Tallinn [brings his AI risk focus](http://thebulletin.org/press-release/skype-co-founder-jaan-tallinn-joins-bulletin-board-sponsors9532) to the *Bulletin of Atomic Scientists*.
* Stephen Hawking [weighs in on intelligence explosion](http://www.ora.tv/larrykingnow/2016/6/25/larry-kings-exclusive-conversation-with-stephen-hawking) (video). Sam Harris and Neil DeGrasse Tyson debate the idea [at greater length](https://www.youtube.com/watch?v=8L3DKlBz874&t=1h22m37s) (audio, at 1:22:37).
* Ethereum developer Vitalik Buterin discusses the implications of [value complexity and fragility](https://blog.ethereum.org/2016/06/19/thinking-smart-contract-security/) and [other AI safety concepts](https://medium.com/@VitalikButerin/why-cryptoeconomics-and-x-risk-researchers-should-listen-to-each-other-more-a2db72b3e86b#.c84y42jjp) for cryptoeconomics.
* *Wired* covers a “[demonically clever](https://www.wired.com/2016/06/demonically-clever-backdoor-hides-inside-computer-chip/)” backdoor based on chips’ analog properties.
* *CNET* interviews MIRI and a who’s who of AI scientists for a pair of articles: “[AI, Frankenstein? Not So Fast, Experts Say](http://www.cnet.com/uk/news/ai-frankenstein-not-so-fast-artificial-intelligence-experts-say/)” and “[When Hollywood Does AI, It’s Fun But Farfetched](http://www.cnet.com/uk/news/hollywood-ai-artificial-intelligence-fun-but-far-fetched/).”
* Next month’s [Effective Altruism Global](http://eaglobal.org/) conference is accepting applicants.
|
---
1. Inspiration for these gyms came in part from Chris Olah and Dario Amodei in a conversation with Rafael.
The post [July 2016 Newsletter](https://intelligence.org/2016/07/05/july-2016-newsletter/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org).
|
64d72c5a-48cc-47e6-b428-8d85e52d675f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Coupling for Decouplers
Previously in sequence: Moonlight Reflected
Cross-posted from SecondPerson.dating
----------------------------------------
Rationalism has a dating problem. I don’t mean simply the fact that a lot of rationalists are single, which may be adequately explained by age, sex ratio, and an unusual combination of slow life history with fears of an imminent apocalypse. A young guy once approached my friend at a party in Lighthaven:
> Guy: I recognize you, I read your date-me doc.
>
> My friend: Did you fill out the application?
>
> Guy: Ah, well, I don’t think your family plans will work with my AI timelines.
We’ll come back to this guy eventually, but today I want to talk about rationality as a philosophy, not just a collection of single men. What do I mean by “a problem”? The last popular post on LessWrong tagged “Relationships (Interpersonal)” is from 3 years ago. It’s titled “Limerence Messes Up Your Rationality Real Bad, Yo”.
Flirting, crushes, sex, dating — something about these doesn’t jive with Bay Area indigenous ways of knowing. Despite their broad curiosity about human nature and behavior, major rationalist writers like Eliezer, Scott, and Zvi have written very little about dating, and almost nothing about their own romantic lives. When I get feedback from rationalist readers, I often get a sense of deep resistance not to some particular claim I’ve made, but to Second Person’s entire way of thinking about dating.
Here’s an email from a longtime reader of my old rationalist blog, emphasis mine:
> I had high hopes, but I'm a bit disappointed so far. Putanumonit was often quite good, but Second Person so far is not living up to it. Where are the numbers???
>
> Of course markets are a useful frame to start with, but how about some example Fermi estimates of supply and demand? Or you could walk through some "backprop from the incentive gradient" examples - i.e. if I tighten/relax requirement X, how does that impact supply (as a Fermi estimate)? If I change
|
a1b1309d-002a-411d-941c-b3252bf88c1c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Three enigmas at the heart of our reasoning
Financial status: This is independent research supported by a grant. I welcome additional support.
Epistemic status: Reflections from personal experience.
Outline
What can we ultimately trust as a foundation for our reasoning?
As we go about our lives, we often trust reasoning that is based in empirical, mathematical, and ethical frameworks. Trust in these systems seems well justified. But what exactly is it justified by, and does this question have any practical relevance to our lives, or is it merely the domain of frivolous dorm-room discussion?
In this essay I am going to focus on the question of practical relevance. I will not ask you to take radical skepticism more seriously than you have. I will actually ask you not to take it seriously, but to take seriously the question of why it need not be taken seriously.
Here is why: at a day-to-day level, most of us do in fact trust empirical, mathematical, and ethical reasoning quite a bit. Yet when we question their foundations and come up empty-handed, we also in fact continue our day-to-day work unabated. Why is that possible?
This question, I believe, strikes at the heart of an issue of enormous practical importance, which is: how can we go about our work without being hindered by self-doubt? I am not talking about some small emotional thing or a mere personality quirk when I refer to "self-doubt". I am talking about deep doubt concerning the fundamental reasoning systems upon which we predicate our lives.
The problem, I suspect, is that these questions of deep doubt in fact play within our minds all the time, and hinder our capacity to get on with our work. It is as if we were stuck in a kind of awkward middle ground: on the one hand we are, for good reason, not quite willing to surrender into radical skepticism and put our whole lives on hold in order to work through a deep ontological crisis, yet on the other hand we are not able to put these questions aside, either, and so although we do get up from o
|
a0b34b18-4a73-4052-bc0a-384c3bf554a6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Pros and Cons of Being Among Your Tribe
I recently attended the rationalist conference, LessOnline. I wanted to document some of the experience, and found myself bifurcating my emotional reactions. The conference itself was wonderful, with great people, food, and venue, but there were pros and cons to going. Though the pros greatly outweigh the cons, both deserve to be mentioned.
Let's split and commit.
Cons
Social Anxiety
I have some measure of social anxiety, but it’s kinda weird in that public speaking doesn’t affect me in the slightest while socializing at a party with friends of friends is terrifying. I’ve come to understand it as something of an inverted U:
I can socialize easily among strangers because it doesn't matter to me if they hate me. It's easy to be sociable when there's nothing on the line. It’s even easier to do public speaking in front of strangers, because that isn’t even socializing, just me talking in front of people.
On the other side of the inverted U, with close friends and family, I know that I’m safe if I fuck up. If I commit some social gaffe or look stupid, who cares? These are the people I love and trust, and they likely got that position because they’ve seen me at my worst and didn’t run away.
When I got to LessOnline, on the other hand, I was surrounded by people at the top of the inverted U: people whose opinions I care about, but who I don’t actually know very well. If I fuck up in front of them, who’s to say how they’ll react? Maybe Zvi will walk away thinking I’m a moron, or one of the many venerable Scotts will realize I secretly have no idea what I’m talking about.
Whether or not it would happen like that, it feels plausible that it could. I could make an ass of myself in front of the community I’ve chosen, the one whose opinions actually matter to me. I might sometimes feel like an asshole, but if Duncan Sabien thinks I'm an asshole, that's Really Bad. Within my social context, he’s an Authority on assholes. If he thinks I’m an asshole, I can’t ignore it
|
2c5b4cc7-f3ea-4c18-a281-6244e93ff687
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How do autistic people learn how to read people's emotions?
From my understanding, people on the autism spectrum have difficulty reading people's emotions and general social cues. I'm curious how these people develop these skills and what one can do to improve them. I ask this as a matter of personal interest; while I am somewhat neurotypical, I feel this is an area where I am very lacking.
(Sidenote: would this be considered an appropriate used of the discussion section?)
|
bfa2dff0-2058-410d-b8b0-6f494b09d774
|
trentmkelly/LessWrong-43k
|
LessWrong
|
AGI Safety FAQ / all-dumb-questions-allowed thread
While reading Eliezer's recent AGI Ruin post, I noticed that while I had several points I wanted to ask about, I was reluctant to actually ask them for a number of reasons:
* I have a very conflict-avoidant personality and I don't want to risk Eliezer or someone else yelling at me;
* I get easily intimidated by people with strong personalities, and Eliezer... well, he can be intimidating;
* I don't want to appear dumb or uninformed (even if I am in fact relatively uninformed, hence me wanting to ask the question!);
* I feel like there's an expectation that I would need to do a lot of due diligence before writing any sort of question, and I don't have the time or energy at the moment to do that due diligence.
So, since I'm probably not the only one who feels intimidated about asking these kinds of questions, I am putting up this thread as a safe space for people to ask all the possibly-dumb questions that may have been bothering them about the whole AGI safety discussion, but which until now they've been too intimidated, embarrassed, or time-limited to ask.
I'm also hoping that this thread can serve as a FAQ on the topic of AGI safety. As such, it would be great to add in questions that you've seen other people ask, even if you think those questions have been adequately answered elsewhere. [Notice that you now have an added way to avoid feeling embarrassed by asking a dumb question: For all anybody knows, it's entirely possible that you are literally asking for someone else! And yes, this was part of my motivation for suggesting the FAQ style in the first place.]
Guidelines for questioners:
* No extensive previous knowledge of AGI safety is required. If you've been hanging around LessWrong for even a short amount of time then you probably already know enough about the topic to meet any absolute-bare-minimum previous knowledge requirements I might have suggested. I will include a subthread or two asking for basic reading recommendations, but these are not re
|
e33f6cce-cf7e-4811-8b77-687dd8e786db
|
trentmkelly/LessWrong-43k
|
LessWrong
|
GreaterWrong—even more new features & enhancements
(Previous posts: [1], [2], [3])
GreaterWrong.com has recently added a number of new features and UI enhancements, especially to the mobile version of the site:
Private messaging
You can now send and receive private messages.
To send a PM, click on a user’s name, then click “Send private message” (at the top-right):
You can view PMs that you received, send replies, and view the entire back-and-forth conversation, by going to your user page, and clicking on “Conversations”:
Received PMs also show up in your Inbox. (Any new items in your inbox make the envelope icon next to your name in the nav bar turn red.)
Sort user’s posts/comments by karma rating
You can now view a user’s top-rated posts/comments, by going to their user page and switching the sort order to “Top”:
Individual comment threads
You can now browse an individual comment thread on a separate page. The “anchor” icon at the top of a comment is the permalink to that comment thread’s page:
Classic Less Wrong theme
There is now a new theme (bringing the total to eight themes to choose from): “Classic Less Wrong”. This theme replicates, as much as possible, the styling of the old Less Wrong website (a.k.a. “Less Wrong 1.0”).
Mobile theme selection
Users on mobile devices can now switch between the available themes, just like users on desktops.
New editing UI for smartphones
For smartphone users, a new and greatly improved post/comment editor UI is live.
Faster loading speed
Changes to the server code have brought substantial speed improvements, making pages load much faster.
Minor enhancements
There are many minor UI enhancements, including:
* comment-collapse buttons on every comment thread
* upvote/downvote buttons at the bottoms of comments (as well as at the top)
… and other minor fixes and improvements.
|
8177eacc-fc9a-41f0-af77-67f71cc3053a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Bullying the Integers
So, the FBI allegedly arranged for a number of backdoors to be built into the OpenBSD IPSEC stack. I don't really know how credible this claim is, but it sparked a discussion in my office about digital security, and encryption in general. One of my colleagues said something to the effect of it only being a matter of time before they found a way to easily break RSA.
It was at about this moment that time stopped.
I responded with something I thought was quite lucid, but there's only so much lay interest that can be held in a sentence that includes the phrases "fact about all integers" and "solvable in polynomial time". The basic thrust of my argument was that it wasn't something he could just decide an answer to, but I don't think he'll be walking away any the more enlightened.
This got me wondering: do arguments that sit on cast-iron facts (or lack thereof) about number theory feel any different when you're making them, compared to arguments that sit on facts about the world you're just extremely confident about?
If I have a discussion with someone about taxation it has no more consequence than a discussion about cryptography, but the tax discussion feels more urgent. Someone walking around with wonky ideas about fiscal policy seems more distressing than someone walking around with wonky ideas about modular arithmetic. Modular arithmetic can look after itself, but fiscal policy is somehow more vulnerable to bad ideas.
Do your arguments feel different?
|
4ef4d8e4-f0b8-45d4-9793-5e478fad24b8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Mentorship, Management, and Mysterious Old Wizards
Followup to Dealing with Network Constraints
Epistemic Status: I spent some time trying to check if Mysterious Old Wizards were important, and reality did not clearly tell me one way or another. But, I still believe it and frequently reference it and figured I should lay out the belief.
----------------------------------------
Three bottlenecks that the EA community faces – easily mistaken for each other, but with important differences:
Mentorship – People who help you learn skills, design your career, and gain important context about the EA landscape that help you figure out how to apply those skills.
Management – Within a given org or existing hierarchy, someone who figures out what needs doing and who should do it. This can involve mentorship of employees who are either new, or need to train in new skills.
Finally, what I call Mysterious Old Wizards – Those who help awaken people's ambition and agency.
I mention all three concepts to avoid jargon confusion. Mysterious Old Wizards are slightly fungible with mentors and management, but they are not the same thing. But first, let's go over the first two.
Mentorship and Management Bottlenecks
Mentorship and Management are (hopefully) well understood. Right now, my guess is that management is the biggest bottleneck for EA (with mentorship a close second). But this doesn't mean there's any obvious changes to make to our collective strategy.
The people I know of who are best at mentorship are quite busy. As far as I can tell, they are already putting effort into mentoring and managing people. Mentorship and management also both directly trade off against other high value work they could be doing.
There are people with more free time, but those people are also less obviously qualified to mentor people. You can (and probably should) have people across the EA landscape mentoring each other. But, you need to be realistic about how valuable this is, and how much it enables EA to scale.
A top-tier mentor with lots
|
f1c1726e-3168-4c6a-b3c4-f58175955d26
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Large language models learn to represent the world
There's a nice recent paper whose authors did the following:
1. train a small GPT model on lists of moves from Othello games;
2. verify that it seems to have learned (in some sense) to play Othello, at least to the extent of almost always making legal moves;
3. use "probes" (regressors whose inputs are internal activations in the network, trained to output things you want to know whether the network "knows") to see that the board state is represented inside the network activations;
4. use interventions to verify that this board state is being used to decide moves: take a position in which certain moves are legal, use gradient descent to find changes in internal activations that make the output of the probes look like a slightly different position, and then verify that when you run the network but tweak the activations as it runs the network predicts moves that are legal in the modified position.
In other words, it seems that their token-predicting model has built itself what amounts to an internal model of the Othello board's state, which it is using to decide what moves to predict.
The paper is "Emergent world representations: Exploring a sequence model trained on a synthetic task" by Kenneth Li, Aspen Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg; you can find it at https://arxiv.org/abs/2210.13382.
There is a nice expository blog post by Kenneth Li at https://thegradient.pub/othello/.
Some details that seem possibly-relevant:
* Their network has a 60-word input vocabulary (four of the 64 squares are filled when the game starts and can never be played in), 8 layers, an 8-head attention mechanism, and a 512-dimensional hidden space. (I don't know enough about transformers to know whether this in fact tells you everything important about the structure.)
* They tried training on two datasets, one of real high-level Othello games (about 140k games) and one of synthetic games where all moves are random (about 20M games). Thei
|
789f8b7e-abf5-4dec-9682-5ce2524dc3bf
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] How to Seem (and Be) Deep
Today's post, How to Seem (and Be) Deep was originally published on 14 October 2007. A summary (taken from the LW wiki):
> To seem deep, find coherent but unusual beliefs, and concentrate on explaining them well. To be deep, you actually have to think for yourself.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Original Seeing, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
0dab65b2-2853-4c3a-987c-00fbb23d38ac
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Meetup : LW Scotland October Meetup
Discussion article for the meetup : LW Scotland October Meetup
WHEN: 11 October 2015 02:00:00PM (+0100)
WHERE: 8 Clifton Terrace, Edinburgh, EH12 5DR
As usual, this is a static copy of the canonical details, available here: https://www.facebook.com/events/1667702333459781/
----------------------------------------
We'll meet at Platform 5 cafe, opposite Haymarket station, at 2pm. At 3:45pm we'll be at The Melville, a couple of minutes walk away. If you don't know who we are, we'll make ourselves recognisable with Bayes' Theorem in big letters!
http://www.platform5-edinburgh.co.uk/ 8 Clifton Terrace Edinburgh EH12 5DR
http://www.themelvillebar.com/ 19 - 25 William Street Edinburgh EH3 7NG
This time our agenda will be:
1 - Brief intros, and any rational wins or fails over the last month
2 - A Fermi estimation game
3 - Discussion of Part H of the Rationality book, chapters 81 to 86. This section is, "Against Doublethink", and it's a relatively short one :-)
Discussion article for the meetup : LW Scotland October Meetup
|
80d88f60-c62a-4b16-9bf4-5faa41082bb6
|
StampyAI/alignment-research-dataset/lesswrong
|
LessWrong
|
Alignment being impossible might be better than it being really difficult
*Epistemic status: Thinking out loud.*
***TL;DR:** If alignment is just really difficult (or impossible for humanity), we might end up with an unaligned superintelligence which itself solves the alignment problem, gaining exponentially more power. If it is literally impossible, the superintelligence might see its capabilities capped in some regards.*
In many discussions about misalignment, the examples of what would constitute dangerously powerful capabilities for an agent to have involve **fine-grained and thorough understanding of its physical context**[[1]](#fn6j6dkbohuvg). For instance, in [the ELK report](https://docs.google.com/document/d/1WwsnJQstPq91_Yh-Ch2XRL8H_EpsnjrC1dwZXR37PC8/edit) the following deception technique is considered: deploying undetected nanobots that infiltrate humans' brains and have their neurons fire at will (I will refer to this example throughout, but it's interchangeable with many others of similar spirit). Of course, very detailed knowledge about each particular brains' physical state must be known for this, which implies huge amounts of data and computations. This dynamic knowledge has to be either:
1. **All contained in (or enacted directly by) the agent:** This seems implausible for this kind of overly detailed specifications. Granted the agent can have a very good probabilistic model of human psychology which it exploits (just as it can model other parts of the physical world). But brainhacking more than a few people probably requires an amount of data (and system sensors near the scene, and so on) **too big even for this kind of systems** (accounting for the placement of almost every neuron in the present and future, etc.). This is inspired by Information Theoretic intuitions that, even with near-future hardware, any simulation of reality with that much detail will be too costly (information cannot be compressed much further, the most efficient way to simulate reality is by far reality itself, etc.)[[2]](#fnyt3bemen1sh).
2. **Somehow spread over systems complementary to the agent:** This would very probably involve creating systems to which to delegate computations and decisions about specific parts of the physical world[[3]](#fnd7ol98i7f58). These systems with local knowledge will have to maximize a certain state of the world that the main agent wants to attain. If they deal with tasks as complex as manipulating humans, they can be expected to **require independence and agency themselves**, and so the main agent will have to **solve the alignment problem for them**. Failing to do so would probably bar the main agent from performing this kind of fine tampering with physical reality, and thus greatly limit its capabilities.
The core logical argument here might be nothing but a truism: **conditional on humans not solving alignment, we want alignment to be impossible** (or at least impossible for the superintelligences under consideration), since otherwise any (almost certainly unaligned) superintelligence will be even more powerful and transformative.
But furthermore I've tried to make the case for why this might be of special importance, by intuitively motivating why **an agent might need to solve alignment to undertake many of the most useful tasks** (and so solving alignment is not just an unremarkable capability, but one very important capability to have). That is, I'm arguing to update for the red quantity in the picture to be bigger than we might at first consider.
In fact, since solving alignment allows for the proliferation and iterative replication of agents obeying the main agent's goals, it's to be expected that **its capabilities will be exponentially greater** in a world in which it solves alignment (although of course an exponential increase in capabilities won't imply an exponential increase in existential risks, since a less capable unaligned superintelligence is already bad enough).
1. **[^](#fnref6j6dkbohuvg)**An agent can still be very dangerous by performing way less complex tasks, but being able to perform these tasks will likely increase danger. It is even possible that agents with simpler tasks are way easier to contain if we drastically limit the agents' possible actions over the world (by for instance only allowing them to output text data, etc.).
2. **[^](#fnrefyt3bemen1sh)**Disclaimer: I'm no expert in Information Theory nor hardware trends. I'm just hand-waving to the fact that the amount of computation needed would probably be unattainable.
3. **[^](#fnrefd7ol98i7f58)**These might or might not be at the same time the mobile sensors and actors themselves (the nanobots).
|
ec931de5-caa8-4a00-af1b-ac49450b7c6f
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Rationalist (well, skeptic, at least) webcomic.
Mystery Solved is more or less a webcomic about a gentleman adventurer/debunker.
I came across it earlier today and I figured some here might be amused.
|
ad863ba4-57f0-4974-a414-46fa319f627c
|
trentmkelly/LessWrong-43k
|
LessWrong
|
BOUNTY AVAILABLE: AI ethicists, what are your object-level arguments against AI notkilleveryoneism?
I am prepared to pay out anywhere between $20 and $100 to AI ethicists of the DAIR/"Stochastic Parrots" school of thought if they provide their object-level arguments against the idea that preventing AI from killing everyone is a real and important issue. This pay will depend on their notability within AI ethics, as well as the clarity and persuasiveness of their arguments.
Conditions for the bounty
1. The bounty must be claimed by an AI ethicist of the DAIR/"Stochastic Parrots" school of thought. Ethicists from other schools of thought (such as the "what if self-driving cars face trolley problems" school of thought) may be given bounties on a case-by-case basis, but probably not. Any member of DAIR or coauthor of the "Stochastic Parrots" paper counts for this, but people outside of these specific circles may qualify at my discretion, if I believe that their intellectual output is similar to or connected with DAIR or the "Stochastic Parrots" coauthors.
2. The arguments provided by the claimant must be posted publicly, ideally in the comment section of this thread.
3. The arguments provided by the claimant must be object-level. This means that they must discuss concrete subjects specific to the issues at hand. This is in contrast to meta-level arguments, which focus on facts about the question (rather than about the issues it addresses), such as difficulties involved in future prediction, the cultural milieu of contemporary AI notkilleveryoneism, the framing of my questions, etc. Note that I have nothing against meta-level arguments; it's just that I've already seen plenty of meta-level arguments by AI ethicists against AI notkilleveryoneism, and I want to see some object-level arguments.
4. The arguments provided by the claimant must be a good-faith summary of the claimant's actual object-level arguments against AI notkilleveryoneism. For example, "AI notkilleveryoneism is unimportant because paperclips are shiny" will not count, even if made by a qualifying c
|
9095c74f-12fa-4ac9-9565-4d87e1a980a7
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
Neurosymbolic AI: The 3rd Wave
1 Introduction
---------------
Over the past decade, Artificial Intelligence and in particular deep learning have attracted media attention, have become the focus of increasingly large research endeavors, and have changed businesses. This led to influential debates on the impact of AI both on academia and industry
[[49](#bib.bib49)], [[63](#bib.bib63)]. It has been claimed that Deep Learning (DL) caused a paradigm shift not only in AI, but in several Computer Science fields, including speech recognition, computer vision and image understanding, natural language processing (NLP) and machine translation [[46](#bib.bib46)].
The 2019 Montréal AI Debate between Yoshua Bengio and Gary Marcus, mediated by Vincent Boucher [[49](#bib.bib49)], and the AAAI-2020 fireside conversation with Economics Nobel Laureate Daniel Kahneman, mediated by Francesca Rossi and including the 2018 Turing Award winners and DL pioneers Geoffrey Hinton, Yoshua Bengio and Yann LeCun, have pointed to new perspectives and concerns on the future of AI. It has now been argued eloquently that if the aim is to build a rich AI system, that is, a semantically sound, explainable and ultimately trustworthy AI system, one needs to include with it a sound reasoning layer in combination with deep learning.
Kahneman corroborated this point at AAAI-2020 by stating that *…as far as I’m concerned, System 1 certainly knows language… System 2 does involve certain manipulation of symbols* [[39](#bib.bib39)]. Kahneman’s comments at AAAI-2020 go to the heart of the matter, with parallels having been drawn many times by AI researchers between Kahneman’s research on human reasoning and decision making - reflected in his book “Thinking, Fast and Slow” [[38](#bib.bib38)] - and the so-called ‘‘AI systems 1 and 2”, which would in principle be modelled by deep learning and symbolic reasoning, respectively.111“Thinking Fast and Slow”, by Daniel Kahneman: New York: Farrar, Straus and Giroux, 2011, describes the author’s *“… current understanding of judgment and decision making, which has been shaped by psychological discoveries of recent decades.”* Of course, the concepts of systems 1 and 2 derive from decades of research in Psychology and Cognitive Science and a comprehensive explanation is beyond the scope and aims of this paper.
In this paper, we place 20 years of research from the area of neurosymbolic AI, known as neural-symbolic integration, in the context of the recent explosion of interest and excitement about the combination of deep learning and symbolic reasoning. We revisit early theoretical results of fundamental relevance to shaping the latest research, and identify bottlenecks and the most promising technical directions for the sound representation of learning and reasoning in neural and symbolic systems.
As well as pointing to the various related and promising techniques within AI, ML and Deep Learning, this article seeks to help organise some of the terminology commonly used around AI. This seems important at this exciting time when AI becomes popularized and more people from other areas of Computer Science and from other fields altogether turn to AI: psychology, cognitive science, economics, medicine, engineering and neuroscience to name a few.
In Section 2, we position the current debate in the context of the necessary and sufficient building blocks of AI and long-standing challenges of variable grounding and commonsense reasoning. In Section 3, we seek to organise the debate, which can become vague if defined around the concepts of *neurons versus symbols*, around the concepts of distributed and localist representations. We argue for the importance of this focus on representation since representation precedes learning as well as reasoning. We also analyse a taxonomy for neurosymbolic AI proposed by Henry Kautz at AAAI-2020 from the angle of localist and distributed representations. In Section 4, we delve deeper into a more technical discussion of current neurosymbolic systems and methods with their pros and cons. In Section 5, we identify promising approaches and directions for neurosymbolic AI from the perspective of learning, reasoning and explainable AI. In Section 6, we return to the debate that was so present at AAAI-2020 to conclude the paper and identify exciting challenges for the third wave of AI.
2 Neurons and Symbols: Context and Current Debate
--------------------------------------------------
Deep learning researchers and AI companies have achieved groundbreaking results in areas such as computer vision, game playing and natural language processing [[46](#bib.bib46), [80](#bib.bib80)]
Despite the impressive results, deep learning has been criticised for brittleness (being susceptible to adversarial attacks), lack of explainability (not having a formally defined computational semantics or even intuitive explanation, leading to questions around the trustworthiness of AI systems), and lack of parsimony (requiring far too much data, computational power at training time or unacceptable levels of energy consumption) [[49](#bib.bib49)].
Against this backdrop, leading entrepreneurs and scientists such as Bill Gates and the late Stephen Hawking have voiced concerns about AI’s accountability, impact on humanity and the future of the planet [[71](#bib.bib71)].
The need for a better understanding of the underlying principles of AI has become generally accepted. A key question however is that of identifying the necessary and sufficient building blocks of AI, and how systems that evolve automatically based on machine learning can be developed and analysed in effective ways that make AI trustworthy.
Turing award winner and machine learning theory pioneer Leslie Valiant pointed out that a key challenge for Computer Science is the principled combination of reasoning and learning, building a rich semantics and robust representation language for intelligent cognitive behavior [[88](#bib.bib88)]. In Valiant’s words:
*“The aim is to identify a way of looking at and manipulating commonsense knowledge that is consistent with and can support what we consider to be the two most fundamental aspects of intelligent cognitive behavior: the ability to learn
from experience and the ability to reason from what has been learned. We are therefore seeking
a semantics of knowledge that can computationally support the
basic phenomena of intelligent behavior.”*
Neural-symbolic computing seeks to offer such a principled way of studying AI by establishing provable correspondences between neural models and logical representations [[4](#bib.bib4), [24](#bib.bib24), [17](#bib.bib17), [21](#bib.bib21), [12](#bib.bib12)]. In neural-symbolic computation, logic can be seen as a language with which to compile a neural network, as discussed in more detail later in this paper.222Over the years, the terminology “neural-symbolic” (integration, computing, system, etc.) was used predominantly by the research community to indicate a combination of two paradigms: neural and symbolic AI, see e.g. [[21](#bib.bib21)]
More recently, the more colloquial terminology “neuro-symbolic” (AI, approach, system, etc) has become more commonly used in publications and the printed press. In this paper, we use the term “neural-symbolic” when referring to the combination of paradigms, and we introduce the term “neurosymbolic” as a single word to symbolise the coming of age of a new area of research.
The success of deep learning along with a number of drawbacks identified more recently such as a surprising lack of robustness [[84](#bib.bib84)] has prompted a heated debate around the value of symbolic AI by contrast with neural computation and deep learning.
A key weakness, as Bengio et al. state in a recent article, is that *current machine learning methods seem weak when they are required to generalize beyond the training distribution, which is what is often needed in practice* [[6](#bib.bib6)].
In the recent AI debate between Yoshua Bengio and Gary Marcus, Marcus argues the case for hybrid systems [[49](#bib.bib49)] and seeks to define what makes an AI system effectively hybrid:
>
> “Many more drastic approaches might be pursued. Yoshua Bengio, for example, has made a number of sophisticated suggestions for significantly broadening the toolkit of deep learning, including developing techniques for statistically extracting causal relationships through a sensitivity to distributional changes and techniques for automatically extracting modular structure, both of which I am quite sympathetic to. But for reasons that will become apparent, I worry that even these sorts of tools will not suffice on their own for getting us to robust intelligence.
> Instead, I will propose that in order to get to robust artificial intelligence, we need to develop a framework for building systems that can routinely acquire, represent, and manipulate abstract knowledge, with a focus on building systems that use that knowledge in the service of building, updating, and reasoning over complex, internal models of the external world.”
>
>
>
Key to the appreciation of the above statement by Marcus is an understanding of the representational value of the symbolic manipulation of variables in logic.
It is probably fair to assume that the next decade will be devoted to researching specific methods and techniques which seek to address the above issues of representation, robustness and extrapolation. Such techniques will be drawn from a broader perspective of neurosymbolic machine learning and AI which embraces hybrid systems, including:
(a) Variable Grounding and Symbol Manipulation: Embracing hybrid systems requires the study of how symbols may emerge and become useful in the context of what deep learning researchers have termed *disentanglement*. Once symbols emerge (which may happen at different levels of abstraction, ideally within a modular network architecture), it may be more productive from a computational perspective to refer to such symbols and manipulate (i.e. compute) them symbolically rather than numerically. Once it becomes known that a complex neural network serves to calculate, for example, the sum of two handwritten digits provided as input images, or equally that a complex neural network has learned the function f(x)=x, then it is probably the case that one would prefer such a calculation to be precise and to extrapolate well to any value of x. This is easily achieved symbolically. Reasoning, in many cases too, is preferred to be precise and not approximate, although there are cases where approximate or human-like reasoning become more efficient than logical deduction [[32](#bib.bib32)].
(b) Commonsense and Combinatorial Reasoning:
Another key distinction that is worth making explicit refers to the difference between commonsense knowledge and expert knowledge. While the former is approximate and difficult to specify, the latter strives to be as precise as possible and to prove its properties. We believe that, once equipped with a solid understanding of the value of hybrid systems, variable manipulation and reasoning, the debate will be allowed to progress from the question of *symbols versus neurons* to the research question:
>
> How to compute and learn with symbols, inside or outside of a neural network, and how efficiently computationally, in a precise or approximate reasoning setting?
>
>
>
Foundational work about neurosymbolic models and systems such as [[17](#bib.bib17), [18](#bib.bib18), [21](#bib.bib21)] will be relevant as we embark in this journey. In [[21](#bib.bib21)], correspondences are shown between various logical-symbolic systems and neural network models. The current limits of neural networks as essentially a propositional333The current limitation of neural networks, which John McCarthy referred to as *propositional fixation*, is of course based on the current simple models of neuron. Although this may be about to change through important work on understanding the mind and brain which may produce richer models of neural networks [[29](#bib.bib29)], one should note that the recent state-of-the-art results obtained by deep networks using large amounts of data are predicated on the notion of a simple neuron [[46](#bib.bib46), [75](#bib.bib75)].
system are also evaluated. In a nutshell, current neural networks are capable of representing propositional logic, nonmonotonic logic programming, propositional modal logic and fragments of first-order logic, but not full first-order or higher-order logic. This limitation has prompted the recent work in the area of Logic Tensor Networks (LTN) [[76](#bib.bib76), [50](#bib.bib50), [91](#bib.bib91)] which, in order to use the language of full first-order logic with deep learning, translates logical statements into the loss function rather than into the network architecture. First-order logic statements are therefore mapped onto differentiable real-valued constraints using a many-valued logic interpretation in the interval [0,1]. The trained network and the logic become communicating modules of a hybrid system, instead of the logic computation being implemented by the network. This distinction between having neural and symbolic modules that communicate in various ways and having translations from one representation to the other in a more integrative approach to reasoning and learning should be at the centre of the debate in the next decade.444Having worked for two decades on integrative neurosymbolic AI and more recently on hybrid neural-symbolic systems, we are acutely *aware of the tension between principled integration and practical value and application*. Scientifically, there is obvious value in the study of the limits of integration to improve our understanding of the power of neural networks using the well-studied structures and algebras of computer science logic. When seeking to solve a specific problem, however, one may prefer to take, for example, an existing knowledge-base and find the most effective way of using it alongside the tools available from deep learning and software agents. As a case in point, take the unification algorithm, which is an efficient way of computing symbolic substitutions. It is notoriously difficult to implement in neural networks. One may, of course, wish to study how to perform logical unification exactly or approximately using a neural network, although at present the most practical way may be to adopt a hybrid approach whereby unification is computed symbolically.
Among the recent neurosymbolic systems, one can identify quite a variety in range from integrative to hybrid systems: [[48](#bib.bib48)] can be seen as a loosely-coupled hybrid approach where image classification is combined with reasoning from text data; [[47](#bib.bib47)] offers further integration by allowing a node in the probabilistic inference tree of a symbolic ML system (ProbLog) to be replaced by a neural network; [[76](#bib.bib76)] takes another step towards integration by using a differentiable many-valued logic in the loss function of a neural network (in LTN, theorem proving is left for the symbolic counterpart of the system); [[51](#bib.bib51)] proposes to perform differentiable unification and theorem proving inside the neural network.
Out of the systems and techniques now available, some more integrative others more loosely-coupled, a common question clearly emerges: what are the fundamental building blocks, the necessary and sufficient components of neurosymbolic AI? For example, is the use of an attention layer necessary [[92](#bib.bib92)] or can it be replaced by richer structure such as graph networks [[44](#bib.bib44)]? Is the explicit use of probability theory necessary, and in this case inside the network or at the symbolic level or both? Is there a real computational gain in combinatorial problem solving by theorem proving using neural networks or is this task better left to the devices of a symbolic system? One thing is now very clearer: there is great practical value in the use of gradient-based learning on distributed representations[[43](#bib.bib43)].
In this paper, we also seek to bring attention to another perhaps less attractive but equally if not more relevant question of adopting a *distributed versus a localist representation*. In a localist representation the relevant concepts have an associated identifier. This is typically a discrete representation. By contrast, in a distributed representation, concepts are denoted by vectors with continuous values. This is therefore an issue of which representation is adequate or most appropriate. Symbolic machine learning takes a localist approach while neural networks are distributed, although neural networks can also be localist [[54](#bib.bib54)]. The next section will be devoted to the pros and cons of distributed and localist representations.
Forms of Neurosymbolic Integration: Within neurosymbolic AI one may identify *systems that translate and encode symbolic knowledge in the set of weights of a network* [[28](#bib.bib28)], or *systems that translate and encode symbolic knowledge into the loss function of the network*[[76](#bib.bib76)]. The *neural-symbolic cycle* translating symbolic knowledge into neural networks and vice-versa offers a kind of compiler for neural networks555In the study of programming languages it is accepted that different levels of abstraction and different representations are needed - e.g. java bytecode and a java program - for the purpose of efficiency, system maintenance, user interaction and verification. We argue that in AI, neural-symbolic systems will provide equally important forms of abstract representation.
, whereby prior knowledge is translated into the network, and a decompiler whenever symbolic descriptions are extracted from a trained network. The compiler can either set-up the network’s initial weights akin to a one-shot learning algorithm which is guided by knowledge, or define a knowledge-based penalty or constraint which is added to the network’s loss function.
A third form of integration has been proposed in [[6](#bib.bib6)] which is based on changing the representation of neural networks into factor graphs. The value of this particular representation deserves to be studied. Change of representation is a worthwhile endeavor on its own right in that it may help us understand the strengths and limitations of different neural models and network architecture choices. This third form of integration, however, proposes to create an intermediate representation with factor graphs in between neural networks and logical representations.
A note about terminology: In [[55](#bib.bib55)], Turing award winner Judea Pearl offers a critique of machine learning which, unfortunately, conflates the terms *machine learning* and *deep learning*. Similarly, when Geoffrey Hinton refers to *symbolic AI*, the connotation of the term tends to be that of expert systems dispossessed of any ability to learn. The use of the terminology is in need of clarification. Machine learning is not confined to association rule mining, c.f. the body of work on symbolic ML and relational learning [[52](#bib.bib52)] (the differences to deep learning being the choice of representation, localist logical rather than distributed, and the non-use of gradient-based learning algorithms). Equally, symbolic AI is not just about production rules written by hand. A proper definition of AI concerns knowledge representation and reasoning, autonomous multi-agent systems, planning and argumentation, as well as learning. In what follows, we elaborate on the above misunderstandings one at a turn.
Symbolic Machine Learning and Deep Learning: In [[55](#bib.bib55)], Pearl proposes a hierarchy consisting of three levels: association, intervention and counterfactual reasoning, and claims that ML is only capable of achieving association. A neurosymbolic or purely symbolic ML system should be capable of satisfying the requirements of all three of Pearl’s levels, e.g. by mapping the neural networks onto symbolic descriptions. It is fair to say in relation to Pearl’s top level in the hierarchy - counterfactual reasoning - that progress has only been made recently and that much research is still needed, although good progress is being made towards the extraction of local, measurable counterfactual explanations from black box ML systems [[95](#bib.bib95)]. Once a neural network has been endowed with a symbolic interpretation, one has no reason to doubt the ability of a neural system to ask *what if* questions. In fact, the very algorithm for extracting symbolic logic descriptions of the form A→B from trained neural networks [[15](#bib.bib15)] uses a form of interrogation of the network akin to the intervention of Bayesian models advocated by Pearl. We argue therefore that a more important question is representational: which representation is most effective, deep networks or Bayesian networks? While attempting to answer this question, as well as considering the demands of the practical applications, it is important to recognise that neural networks offer a concrete model of computation, one which can be implemented efficiently by message passing or propagation of activation, differently from Bayesian networks, and trained by differentiable learning algorithms. A limitation of having such a concrete computational model, however, may be a difficulty of pure neural networks at modelling rich forms of abstraction which are not dependent on the data (images, audio, etc.) but which exist instead at a higher conceptual level. We shall return to this challenge later in the paper.
Knowledge Representation and Reasoning in AI: Complex problem solving using AI requires a much richer language than that of expert systems as suggested by Hinton [[34](#bib.bib34)]. AI requires a language that can go well beyond Horn clauses to include relational knowledge, time and other modalities, negation by failure, variable substitution and quantification, etc. In statistical relational learning, the use of first-order logic does not require instantiating (or grounding) all possible combinations of the values of the variables (e.g. X and Y in a relation R(X,Y)). In *relational reasoning* with neural networks, borrowing from the field of relational databases, it is typically the grounded (and therefore propositional rather than first-order) representation that is learned and reasoned about. For the avoidance of confusion, we would term this latter task *relationship learning*. Two other equally important attributes of a rich language for complex problem solving are *compositionality*, in the sense of the compositionality of the semantics of a logical language, and modularity. It is worth noting that in the original paper about deep learning [[35](#bib.bib35)], before much of the attention turned to convolutional networks, modularity was a main objective of the proposed semi-supervised greedy learning of stacks of restricted Boltzmann machines. The recently-proposed stacked capsule autoencoders [[42](#bib.bib42)] and neural-symbolic approaches such as Logic Tensor Networks [[76](#bib.bib76)] as well as other weakly-supervised approaches revive the important stance of modularity in neural computation. Earlier efforts towards modularity in neurosymbolic AI can be traced back to the system for Connectionist Modal and Intuitionistic Logics [[19](#bib.bib19), [20](#bib.bib20)]. Modal logics with a possible-world semantics have been shown to offer a natural approach to modularity in neural computation [[21](#bib.bib21)].
With AI understood as a superset of ML which in turn is a superset of DL, we shall argue for the combination of statistical machine learning, knowledge representation (KR) and logical reasoning. By logical reasoning, we shall mean not only classical logic reasoning with the traditional true-false interpretation, but non-classical reasoning including nonmonotonic, modal and many-valued logics. In the study of the interplay between learning and reasoning and how best to implement it (e.g. in a continuous or discrete system), it shall become clear that universal quantification is easy to reason about and hard to learn using neural networks; existential quantification is easy to learn and harder to reason about in a symbolic system. Such limitations on either side of the spectrum will dictate a few practical design decisions to be discussed in this paper. In a nutshell, *we claim that neurosymbolic AI is well placed to address concerns of computational efficiency, modularity, KR + ML and even causal inference*. More researchers than ever on both sides of the connectionist-symbolic AI divide are now open to studying and learning about each others’ tools and techniques. This was not the case until very recently. The use of different terminology alongside some preconceived opinion or perhaps idleness, fueled by the way that science normally rewards research that is carried out in silos, have prevented earlier progress. The fact that this is now changing will lead to faster progress in the overall field of AI. It is reassuring to see it happening in this way: the neural information processing community have shown the value of neural computation in practice, which has attracted the curiosity of great minds from symbolic AI. We hope that further collaboration in neurosymbolic AI will help solve many of the issues which are still outstanding.
3 Distributed and Localist Representation
------------------------------------------
The integration of learning and reasoning through neurosymbolic systems requires a bridge between localist and distributed representations. The success of deep learning indicates that distributed representations with gradient-based methods are more adequate than localist ones for learning and optimization. At the same time, the difficulty of neural networks at extrapolation, explainability and goal-directed reasoning point to the need of a bridge between distributed and localist representations for reasoning.
Neural-symbolic computing has been an active area of research seeking to establish such a bridge for several years [[4](#bib.bib4), [27](#bib.bib27), [17](#bib.bib17), [21](#bib.bib21), [33](#bib.bib33), [41](#bib.bib41), [77](#bib.bib77), [89](#bib.bib89)]. In neural-symbolic computation, knowledge learned by a neural network can be represented symbolically. Reasoning takes place either symbolically or within the network in distributed form. Despite their differences, both the symbolic and connectionist paradigms share common characteristics, offering benefits when put together in a principled way (see e.g. [[18](#bib.bib18), [21](#bib.bib21), [81](#bib.bib81), [89](#bib.bib89)]). Change of representation also offers a way of making sense of the value of different neural models and architectures with respect to what is a more formal and better understood area of research: symbolic logic.
Neural network-based learning and inference under uncertainty have been expected to address the brittleness and computational complexity of symbolic systems. Symbolism has been expected to provide additional knowledge in the form of constraints for learning [[24](#bib.bib24), [30](#bib.bib30)], which ameliorate neural network’s well-known catastrophic forgetting or difficulty with extrapolation in unbounded domains or with out-of-distribution data. The integration of neural models with logic-based symbolism is expected therefore to provide an AI system capable of explainability, transfer learning and a bridge between lower-level information processing (for efficient perception and pattern recognition) and higher-level abstract knowledge (for reasoning, extrapolation and planning).
Suppose that a complex neural network learns a function f(x). Once this function is known, or more precisely a simplified description of f(x) is known, computationally it makes sense to use such a representation, not least for the sake of extrapolation, as exemplified earlier with the f(x)=x function. One could argue that at this point the neural network has become superfluous. Symbol manipulation (once symbols have been discovered) is key to further learning at new levels of abstraction. This is exemplified well in [[49](#bib.bib49)] with the use of the concept of a *container* which may be learned from images.
Among the most promising recent approaches to neural-symbolic integration, so-called embedding techniques seek to transform symbolic representations into vector spaces where
reasoning can take place through matrix computations over distance functions [[7](#bib.bib7), [82](#bib.bib82), [83](#bib.bib83), [77](#bib.bib77), [72](#bib.bib72), [11](#bib.bib11), [27](#bib.bib27), [96](#bib.bib96), [25](#bib.bib25), [67](#bib.bib67)]. In such systems, learning of an embedding is carried out using backpropagation [[94](#bib.bib94), [70](#bib.bib70)]. Most of the research in this area is focused on the art of representing relational knowledge such as P(X,Y) in a distributed neural network. The logical predicate P relating variables X and Y could be used to denote, for example, the *container* relation between two objects in an image such as a violin and its case, which are in turn described by their embedding. This process is known as relational embedding [[7](#bib.bib7), [72](#bib.bib72), [82](#bib.bib82), [83](#bib.bib83)]. For representing more complex logical structures such as first order-logic formulas, e.g. ∀X,Y,Z:(P(X,Y)→Q(Y,Z)), a
system named Logic Tensor Networks (LTN) [[77](#bib.bib77)] was proposed by extending Neural Tensor Networks (NTN)
[[82](#bib.bib82)], a state-of-the-art relational embedding
method. Related ideas are discussed formally in the context of
constraint-based learning and reasoning in [[30](#bib.bib30)].
Two powerful concepts of LTN are (1) the grounding of logical concepts onto tensors with the use of logical statements which act as constraints on the vector space to help learning of an adequate embedding, and (2) the modular and differentiable organisation of knowledge within the neural network which allows querying and interaction with the system. Any user-defined statement in first-order logic can be queried in LTN which checks if that knowledge is satisfied by the trained neural network. With such a tool, a user can decide when to keep using a distributed connectionist representation or switch to a localist symbolic representation. This last aspect brings the question of the emergence of symbols and their meaning in neural networks to the fore: recent work using the weakly supervision of auto-encoders and ideas borrowed from disentanglement have been showing promise in the direction of learning relevant concepts which can in turn be re-used symbolically [[10](#bib.bib10)]. Related work seeking to explore the advantages of distributed representations of logic include [[11](#bib.bib11)], which is based on stochastic logic programs, [[27](#bib.bib27), [96](#bib.bib96), [25](#bib.bib25)], with a focus on inductive programming, and [[67](#bib.bib67)], based on differentiable theorem proving.
A taxonomy for neurosymbolic AI: with an understanding of the role of localist and distributed approaches, we now provide an analysis of Henry Kautz’s taxonomy for neurosymbolic AI [[40](#bib.bib40)], which was introduced at AAAI 2020: In Kautz’s taxonomy, a Type 1 neural-symbolic integration is standard deep learning, which some may argue is a stretch, but which is included by Kautz to note that the input and output of a neural network can be made of symbols, e.g. text in the case of language translation or question answering applications. Type 2 are hybrid systems such as DeepMind’s AlphaGo and other systems where the core neural network is loosely-coupled with a symbolic problem solver such as Monte Carlo tree search. Type 3 is also a hybrid system whereby a neural network focusing on one task (e.g. object detection) interacts via its input and output with a symbolic system specialising in a complementary task (e.g. query answering). Examples include the neuro-symbolic concept learner [[48](#bib.bib48)] and deepProbLog [[47](#bib.bib47)]. In a Type 4 neural-symbolic system, symbolic knowledge is compiled into the training set of a neural network. Kautz offers [[45](#bib.bib45)] as an example (to be read alongside the critique in [[22](#bib.bib22)]). An approach to learn and reason over mathematical constructions is proposed in [[2](#bib.bib2)], and in [[1](#bib.bib1)] a learning architecture that extrapolates to harder symbolic maths reasoning problems is introduced.
We would also include in Type 4 other tightly-coupled but localist neural-symbolic systems where various forms of symbolic knowledge, not restricted to *if-then* rules, is translated into the initial architecture and set of weights of a neural network, in some cases with guarantees of correctness [[21](#bib.bib21)], as well as Logical Neural Networks, where the key concept is to create a 1-to-1 correspondence between neurons and the elements of logical formulas [[66](#bib.bib66)].
Type 5 are those tightly-coupled but distributed neural-symbolic systems where a symbolic logic rule is mapped onto an embedding which acts as a soft-constraint (a regularizer) on the network’s loss function. Examples of these include Logic Tensor Networks [[76](#bib.bib76)] and Tensor Product Representations [[37](#bib.bib37)], referred to in [[13](#bib.bib13)] as *tensorization* methods. Finally, a Type 6 system should be capable, according to Kautz, of *true symbolic reasoning inside a neural engine*. This is what one could refer to as a fully-integrated system. Early work in neural-symbolic computing has achieved this (see [[21](#bib.bib21)] for a historical overview). Some Type 4 systems are also capable of it, but using a localist rather than a distributed representation and using much simpler forms of embedding than Type 5 systems. Kautz adds that a Type 6 system should be capable of *combinatorial reasoning*, possibly by using an attention schema to achieve it effectively. Recent efforts in this direction include [[8](#bib.bib8), [44](#bib.bib44), [60](#bib.bib60)], although a fully-fledged Type 6 system for combinatorial reasoning does not exist yet.
Further research into Type 5 systems will likely focus on the provision of rich embeddings and the study of the extent to which such embeddings may correspond either to pre-defined prior knowledge or to learned attention mechanisms. Further research onto Type 6 systems is highly relevant to the theory of neural-symbolic computing, as discussed in more detail in the next section. In practical terms, a tension exists between effective learning and sound reasoning, which may prescribe the use of a more hybrid approach of Type 3 to 5, or variations thereof such as the use of attention with tensorization. Orthogonal to the above taxonomy, but mostly associated thus far with Type 4, is the study of the limits of reasoning within neural networks, which was already of interest since the first efforts by Valiant at providing a foundation for computational learning [[87](#bib.bib87)]. Recently, this has been the focus of experimental analyses of deep learning in symbolic domains [[85](#bib.bib85)], and it should include the study of first-order logic, higher-order, many-valued and non-classical logic.
4 Neurosymbolic Computing Systems: Technical Aspects
-----------------------------------------------------
In symbolic ML, symbols are manipulated as part of a discrete search for the best representation to solve a given classification or regression task. The most well-known form of symbolic ML are decision trees, but richer forms of representation exist, in particular relational representations using first-order logic to denote concepts ranging over variables X,Y,Z... within a (possibly infinite) domain, e.g. ∀X,Y,Z:grandfather(X,Y)←(father(X,Z)∧mother(Z,Y)) (the father of someone’s mother is that person’s grandfather). Probabilistic extensions of this approach seek to learn probability distributions for such logical rules (or functional programs) as a way of accounting for uncertainty in the training data. Work in these areas is probably best characterised by the conference series on Inductive Logic Programming [[62](#bib.bib62), [53](#bib.bib53)], Statistical Relational Learning [[65](#bib.bib65), [26](#bib.bib26), [3](#bib.bib3), [78](#bib.bib78)] and Probabilistic or Inductive Programming [[74](#bib.bib74)].
All of the excitement and industrial interest in the past 10 years surrounding AI and Machine Learning, though, have come from an entirely separate type of ML: deep learning. Deep learning uses neural networks and stochastic gradient descent to search through a continuous space, also to solve a given classification or regression task, but creating vector-based, distributed representations, rather than logical or symbolic ones. For this reason, such systems are called sub-symbolic.
Whilst it is clear now that AI will not be achieved by building expert systems by hand from scratch (GOFAI), but by learning from large collections of data, one would be misguided to conflate all of machine learning or dismiss the role of symbolic logic, which remains the most powerful and adequate representation for the analysis of computational systems. As put simply by Moshe Vardi *“Logic is the Calculus of Computer Science”* and, differently from statistics, machine learning can only exist within the context of a computational system.
Specifically, deep neural networks will require a language for description, as also advocated by Leslie Valiant. *Neural network-based AI is distributed and continuous*, deals well with large-scale multimodal noisy perceptual data such as text and audio, handles symbol grounding better than symbolic systems since concepts are grounded on feature vectors, and is by definition a computational model, frequently implemented efficiently using propagation of activation and tensor processing units.666Contrast with Bayesian networks which may be inefficient as a computational model frequently requiring simplification of graphs into tree-based representations. *Symbolic AI is generally localist and discrete, capable of sophisticated reasoning*, including temporal, epistemic and nonmonotonic reasoning, planning, extrapolation and reasoning by analogy. Neurosymbolic AI has shown that non-classical logics, in particular many-valued logics, offer an adequate language for describing neural networks [[76](#bib.bib76), [66](#bib.bib66)]. As the field of AI moves towards agreement on the need for combining the strengths of neural and symbolic AI, it should turn next to the question: what is the best representation for neurosymbolic AI?
To answer this question, one should seek to be informed by developments in neural-symbolic computing of the past 20 years, and to evaluate in a precise manner the methods, algorithms and applications of neurosymbolic AI. For instance, it is known that current recurrent neural networks are capable of computing the logical consequences of propositional modal logic programs and other forms of non-classical reasoning and fragment of first order logic programs [[5](#bib.bib5), [21](#bib.bib21)]. Obtaining results for full first-order logic has not been possible thus far, which reinforces John McCarthy’s claim that neural networks are essentially propositional. In terms of applications of AI, these have been largely focused on perceptual or pattern matching tasks such as image and audio classification. Recent efforts at question answering and language translation as well as protein folding classification have highlighted the importance of the neurosymbolic approach. The ideal type of application for a neurosymbolic system, however, should be that where abstract information is required to be reasoned about at different levels beyond that what can be perceived from data alone, such as complex concept learning whereby simpler concepts are required to be organised systematically as part of the definition of a higher concept. Such a conceptual structure, which is still to be discovered using data, also requires knowledge which is governed by *general rules and exceptions to the rules*, allowing for sound generalization in the face of uncertainty but also capable of handling specific cases (the many exceptions, which may be important for the sake of robustness although not necessarily statistically relevant). Similarly, it seems hard to achieve true relational learning using only neural networks. A useful but simple example can be borrowed from the area of Inductive Logic Programming: learning the concept of *ancestor* from a few examples of the *mother*, *father* and *grandparent* relations. Grounding the entire knowledge-base in this case would not be productive since the chain of reasoning to derive the concept of *ancestor* may be arbitrarily large depending on the data available. In this case, one is better off learning certain relations by *jumping to conclusions*, such as e.g. ∀X,Y:father(X,Y)→ancestor(X,Y), from relatively few examples and using similarity measures to infer new relations, at the same time deriving symbolic descriptions which can be used for reasoning beyond the distribution of the data, allowing in turn for extrapolation. In this example, once a description for *ancestor* is obtained, one should be able to reason about arbitrarily long chains of family relationships. Notice that key to this process is the ability to revise the conclusion taken once new evidence to the contrary of what has been inferred is made available from the data. In other words, the reasoning here is nonmonotonic [[14](#bib.bib14)].
In summary, at least two options exist for neurosymbolic AI. In Option 1, symbols are translated into a neural network and one seeks to perform reasoning within the network. In Option 2, a more hybrid approach is taken whereby the network interacts with a symbolic system for reasoning. A third option, which would not require a neurosymbolic approach, exists when expert knowledge is made available, rather than learned from data, and one is interested in achieving precise sound reasoning as opposed to approximate reasoning. We discuss each option briefly next.
In Option 1, it is desirable still to produce a symbolic description of the network for the sake of improving explainability (discussed later) or trust, or for the purpose of communication and interaction with the system. In Option 2, by definition, a neurosymbolic interface is needed. This may be the best option in practice given the need for combining reasoning and learning in AI, and the apparent different nature of both tasks (discrete and exact versus continuous and approximate). However, the value of distributed approximate reasoning using neural networks is only starting to be investigated as in the case of differentiable neural computers [[31](#bib.bib31)] and neural theorem proving [[93](#bib.bib93)], although early efforts did not prove to be promising in terms of practical efficiency [[59](#bib.bib59), [36](#bib.bib36), [79](#bib.bib79)]. In Option 3, a reasonable requirement nowadays would be to compare results with deep learning and the other options. This is warranted by the latest practical results of deep learning showing that neural networks can offer, at least from a computational perspective, better results than purely symbolic systems.
In practice, the choice between Options 1 and 2 above may depend on the application at hand and the availability of quality data and knowledge. A comparatively small number of scientists will continue to seek to make sense of the strengths and limitations of both neural and symbolic approaches. On this front, the research advances faster on the symbolic side due to the clear hierarchy of semantics and language expressiveness and rigour that exists at the foundation of the area. By contrast, little is known about the expressiveness of the latest deep learning models in relation to established neural models beyond data-driven comparative empirical evaluations. As advocated by Paul Smolensky, neurosymbolic computing can help map the latest neural models into existing symbolic hierarchies, thus helping organise the extensively ad-hoc body of work in neural computation.
5 Challenges for the Principled Combination of Reasoning and Learning
----------------------------------------------------------------------
For a combined perspective on reasoning and learning, it is useful to note that reasoning systems may have difficulties computationally when reasoning with existential quantifiers and function symbols, such as ∃xP(f(x)). Efficient logic-based programming languages such as Prolog, for example, assume that every logical statement is universally quantified. By contrast, learning systems may have difficulty when adopting universal quantification over variables. To be able to learn a universally quantified statement such as ∀xP(x), a learning systems needs in theory to be exposed to all possible instances of x. This simple duality points to a possible complementary nature of the strengths of learning and reasoning systems. To learn efficiently ∀xP(x), a learning system needs to *jump to conclusions*, extrapolating ∀xP(x) given an adequate amount of evidence (the number of examples or instances of x). Such conclusions may obviously need to be revised over time in the presence of new evidence, as in the case of nonmonotonic logic. In this case, a statement of the form ∀xP(x) becomes a data-dependent generalization, which is not to be assumed equivalent to a statement ∀yP(y), as done in classical logic. Such statements may have been learned from different samples of the overall potentially infinite population. On the other hand, a statement of the form ∃xP(x) is trivial to learn from data by identifying at least one case P(a), although reasoning from ∃xP(x) is more involved, requiring the adoption of an arbitrary constant b such that P(b) holds.
It is now accepted that learning takes place on a continuous search space of (sub)differentiable functions; reasoning takes place in general on a discrete space as in the case of goal-directed theorem proving. The most immediate way of benefiting from the combination of reasoning and learning, therefore, is to adopt a hybrid approach whereby a neural network takes care of the continuous search space and learning of probabilities, while a symbolic system consisting of logical descriptions of the network uses discrete search to achieve extrapolation and goal-directed reasoning.777The investigation of continuous reasoning or discrete learning approaches is of course worth pursuing too. There have been a number of recent developments with relevant results in both of these directions [[68](#bib.bib68), [47](#bib.bib47), [96](#bib.bib96), [61](#bib.bib61)]. Computational complexity issues remain a challenge though for the combination of first-order logic and probabilities in symbolic AI. As hinted already in this paper, a property of early deep learning may hold the key to the above hybrid perspective: modularity. In the original paper on deep learning [[35](#bib.bib35)], a modular system is proposed consisting of a stack of restricted Boltzmann machines (RBMs). The extraction of symbolic descriptions from each RBM is thus made considerably easier [[86](#bib.bib86)]. Each RBM learns a joint probability distribution while their symbolic description reflects the result of learning without manipulating probabilities explicitly, thus avoiding the complexity of probabilistic inference found in symbolic AI.
In [[86](#bib.bib86)], an efficient algorithm is presented that extracts propositional rules enriched with confidence values from RBMs, similar to what was proposed with Penalty Logic for Hopfield networks in [[59](#bib.bib59)]. When RBMs are stacked onto a deep belief network, however, the modular extraction of compositional rules may be accompanied by a compounding loss of accuracy, indicating that knowledge learned by the neural network might not have been as modular as one would have wished. Systems that impose a more explicit separation of modules may hold the answer to this problem, in particular systems where unsupervised learning is combined with weakly-supervised classification at distinct levels of abstraction, such as with the use of variational auto-encoders or generative adversarial networks.
We therefore do not advocate the adoption of *monoblock* networks with millions of parameters. Even though this may be how the human brain works, loss of modularity seems to be, at least at present from a computational perspective, a price that is too high to pay. Modularity remains a fundamentally relevant property of any computing system.
Applications of Neurosymbolic AI: One major way of driving advances in AI continues to be through challenging applications, be it language translation, computer games or protein folding competitions. Language understanding in the broadest sense of the term, including question-answering that requires commonsense reasoning, offers probably the most complete application area for neurosymbolic AI. As an example, consider this question and its commonsense answer from the COPA data set [[69](#bib.bib69)]: It got dark outside. What happened as a result? (a) Snowflakes began to fall from the sky; (b) The moon became visible in the sky. Another very relevant application domain is planning, which requires learning and reasoning over time, as in this example adapted from [[73](#bib.bib73)]: Daniel picks up the milk; Daniel goes to the bedroom; Daniel places the milk on the table; Daniel goes to the bathroom. Where is the milk? Finally, an area where
machine learning and knowledge representation and reasoning have complementary strengths is *knowledge engineering*, including knowledge-base completion and data-driven ontology learning. In this area of application, rich and large-scale symbolic representations exist alongside data, including knowledge graphs to be combined with neural networks such as graph neural networks.
A common thread across the above examples and applications is the need for modelling *cause and effect* with the use of implicit information. This requires learning of general rules and exceptions to the rules that evolve over time. In such cases, deep learning alone fails when presented with examples from outside the distribution of the training data. This motivated Judea Pearl’s critique of Machine Learning [[55](#bib.bib55)] which we shall address in some detail next.
In Pearl’s 3-level causal hierarchy (association, intervention and counterfactuals), association involves purely statistical relationships. In Pearl’s words, *observing a customer who buys toothpaste makes it more likely that this customer will also buy floss. Such associations can be inferred directly from the observed data using standard conditional probabilities and conditional expectation or other standard non-probabilistic ML model. Questions asked at this level require no causal information and, for this reason, this layer is placed at the bottom of the hierarchy. Answering such questions is the hallmark of current machine learning methods*. Pearl’s hierarchy may unintentionally give the impression that machine learning is confined to this bottom layer, since no reference is made in [[55](#bib.bib55)] to the body of work on symbolic machine learning which is unequivocally not confined to association rules [[52](#bib.bib52), [67](#bib.bib67)]. Pearl continues: *the second level, intervention, ranks higher than association because it involves not just seeing what is but changing what we see. A typical question at this level would be: what will happen if we double the price? Such a question cannot be answered from sales data alone, as it involves a change in customers’ choices in reaction to the new pricing. These choices may differ substantially from those taken in previous price-raising situations, unless we replicate precisely the market conditions that existed when the price reached double its current value*. At this level there is a need for inference that can reach beyond the data distribution. Finally, the top level invokes counterfactuals, a mode of reasoning that reverts to the philosophers David Hume and John Stuart Mill and that has been given computational semantics in the past two decades. A typical question in the counterfactual category is: *what if I had acted differently?*, thus necessitating retrospective reasoning.
As noted earlier in the paper, neural-symbolic computing can implement all three of Pearl’s levels. Once a symbolic description of the form *if A then B* has been associated with a neural network, surely the idea of intervention [[9](#bib.bib9)] and counterfactual reasoning become possible, c.f. for example, [[95](#bib.bib95)] on the measurement and extraction of counterfactual knowledge from trained neural networks.
Our conclusion from the above discussion is that in neurosymbolic AI:
* Knowledge should be grounded onto vector representations for efficient learning from data based on message passing in neural networks as an efficient computational model.
* Symbols should become available as a result of querying and knowledge extraction from trained networks, and offer a rich description language at an adequate level of abstraction, enabling *infinite uses of finite means*, but also compositional discrete reasoning at the symbolic level allowing for extrapolation beyond the data distribution.
* The combination of learning and reasoning should offer an important alternative to the problem of combinatorial reasoning by learning to reduce the number of effective combinations, thus producing simpler symbolic descriptions as part of the neurosymbolic cycle.
As an example, consider a Variational Autoencoder which learns in unsupervised fashion to maximise mutual information between pixel inputs and a latent code or some other embedding consisting of fewer relevant features than pixels. Suppose that this neural network has learned to find regularities such as e.g. *when it sees features of type A, it also sees features of type B but not features of type C*. At this point, such regularities can be converted into symbols: ∀xA(x)→(∃yB(y)∧¬∃zC(z)). As a result of the use of variables x,y,z at the symbolic level, one can extrapolate the above regularity to any features of type A, B or C.888As another example, consider a neural network trained to classify graphs into those which contain a Hamiltonian cycle and those which do not, given a fixed range of available graph sizes as training examples. Contrast this network with a symbolic description of the definition of Hamiltonian cycle which therefore applies to graphs of any size. A symbolic description is also a constraint on the neurosymbolic cycle. It is generalised from data during learning and it certainly includes an ability to ask what-if questions. Reasoning about what has been learned allows for extrapolation beyond the data distribution, and finally the symbolic description can serve as prior knowledge (as a constraint) for further learning in the presence of more data, which includes the case of knowledge-based transfer learning. Further training can now take place at the perceptual or sub-symbolic level, or at the conceptual or symbolic level. This is when having a distributed (sub-symbolic) and a localist (symbolic or sub-symbolic) representation becomes relevant. Assuming that probabilities are dealt with at the sub-symbolic distributed level (as in RBMs) and that the symbolic level is used for a more qualitative representation of uncertainty in the form of general rules with exceptions, we avoid the complications of having to deal simultaneously with discrete and continuous learning of rules and probabilities.
A Note about Explainable AI (XAI): Knowledge extraction is an integral part of neural-symbolic integration and a major ingredient towards explainability of black-box AI systems. The main difficulty in XAI is the efficient extraction of compact and yet correct and complete knowledge. It can be argued that a large knowledge-base is not more explainable than a large neural network.999The now apparent lack of explainability of Random Forests, which amount to a collection of Decision Trees and therefore propositional logic formulas with probabilities, serves as a good reminder that XAI is not confined to neural networks. Although this may be true at the level of the entire model explainability, in the case of local explanations, i.e. explanations of individual cases, a knowledge-base is certainly more explainable than a neural network because it offers a trace (a proof history) showing why an outcome was obtained, as opposed to simply showing how propagation of activation through the network has led to that outcome. It is a main goal of knowledge extraction algorithms to seek to derive compact relevant representations from large complex networks. This is not always possible to achieve efficiently, in which case one may need to resort to having local explanations only.
Many aspects of XAI are being investigated at present. Some of the research questions include: Is the explanation intended for an expert or lay person? Is an explanation required because one does not trust the system, expected a different outcome/would like to induce a different outcome, or would like to question the normative system that has led to the outcome? Is an explanation intended to try and improve system performance, reduce bias/increase fairness, or is it the case that one would simply like to be able to understand the decision process?
The answers to these questions are likely to be application and user specific. While some stakeholders may be happy without an explanation, as in the case of a patient faced with a medical diagnosis, in most cases some form of explanation is needed to improve system performance or trust. In some cases, producing an explanation is in fact the main goal of the system as in the application of ML to responsible gambling in [[56](#bib.bib56), [57](#bib.bib57)].
Early efforts at knowledge extraction in neurosymbolic AI as a form of explanation were always evaluated w.r.t. fidelity: a measure of the accuracy of the extracted knowledge in relation to the neural network rather than the data, or in today’s terminology, a measure of the accuracy of the *student* model w.r.t. the *teacher* model.
High fidelity is therefore fundamental whenever a student model is to be claimed to offer a good explanation for a (more complex) teacher model. Unfortunately, many recent XAI methods have abandoned fidelity as a measure of the quality of an explanation, making it easier for an apparently excellent explanation to be simply wrong, in that it may not be at all an explanation of the ML model in question. This is particularly problematic for very popular local XAI methods such as LIME [[64](#bib.bib64)]. Local explanation systems currently in use by consultancy firms and available in many AI toolboxes can be shown to achieve very low levels of fidelity. Without high fidelity results, an apparently perfectly good explanation produced by an XAI system is likely not to be an explanation of the underlying ML system which it is expected to explain. In [[95](#bib.bib95)] a way of measuring fidelity of local methods was introduced which we argue should be adopted by all XAI methods. The same paper exemplifies how LIME’s explanations may achieve very low fidelity.
Even better than fidelity, if an XAI method can be shown to be sound [[16](#bib.bib16)] then it will provably converge to a high-fidelity. Soundness however is normally
associated with exponential complexity and so in practice a measure of fidelity may be all that is available. Knowledge extraction should also allow communication between users and the ML system. Current interactive ML is insufficient to the extent that it proposes to replace sound statistical evaluation by subjective user evaluation. Communication with the system implies an ability to ask questions (query the system) and check one’s understanding (obtain a rationale for the outcome). The user can then either agree with the outcome and the rationale, agree with the outcome but not the rationale, or disagree with the outcome, thus providing useful feedback or direct intervention to change the system and its outcomes, probably through the system’s symbolic description language in the case of neurosymbolic AI.
Knowledge extraction also offers a way of identifying and correcting for bias in the ML system, which is a serious and present problem [[26](#bib.bib26)]. As a result of the General Data Protection Regulation (GDPR), many companies have decided as a precaution to remove protected variables such as gender and race from their ML system. It is well known, however, that proxies exist in the data which will continue to bias the outcome so that the removal of such variables may serve only to hide a bias that otherwise could have been revealed via knowledge extraction [[58](#bib.bib58)].
Current AI-based decision support systems process very large amounts of data which humans cannot possibly evaluate in a timely fashion. Thus, even with a so-called human-in-the-loop approach where technology domain experts or end-users may become accountable to the decisions, domain experts or end-users are likely to quickly feel progressively less capable of over-riding recommendations which were deemed accurate and based on so much more data than they can handle. Even when such AI systems are portrayed as decision support systems, the current reality is that in order to function well with Big Data, the system must execute a form of triage of the data to be presented to the expert, thus only offering partial information to the decision maker. Without knowledge extraction and a capacity for system communication, the decision maker will, by the very nature of the automated data triage, not be in control.
Finally, the simple extraction of rules from trained networks may be insufficient. One may need to extract also *confidence values* so as to be able to rank extracted rules. This offers a system that *knows when it does not know*. As a simple example, consider a typical neural network trained to classify the well-known MNIST hand-written digits from 0 to 9. Faced with an image of an obvious non-digit such as an image of a cat, this system must surely provide a very low confidence value to any of the outcomes 0 to 9. The use of adversarial approaches alongside knowledge extraction for robustness has a contribution to make here. In summary, for the many reasons discussed above, neurosymbolic AI with a measurable form of knowledge extraction is a fundamental part of XAI.
6 AAAI 2020, a Turning Point
-----------------------------
We now return to the debate around System 1 and System 2 that motivated the introduction of this paper and provide a short summary of the AAAI 2020 conference. Not only did the AAAI 2020 conference contained a larger than usual number of papers proposing to combine neural networks and symbolic AI, there were a number of keynote addresses and debates directly relevant to neural-symbolic computing, notably:
(1) Fireside conversation between 2019 Turing award winners, Francesca Rossi, and Nobel Laureate Daniel Kahneman on thinking fast and slow and its relation to neural networks and symbol manipulation;
(2) The Third AI Summer, Henry Kautz’s AAAI 2020 Robert S. Engelmore Memorial Award Lecture, which introduced a taxonomy for neurosymbolic computing;
(3) The Director of MIT/IBM Watson AI laboratory David Cox IAAI keynote address, which focused on neurosymbolic AI and applications on vision and language understanding, machine commonsense, question answering, argumentation and XAI.
At the Turing award session and fireside conversation with Daniel Kahneman, there was a clear convergence towards integrating symbolic reasoning and deep learning. Kahneman made his point clear by stating that on top of deep learning, a System 2 symbolic layer is needed.
This is reassuring for neurosymbolic AI going forward as a single more cohesive research community that can agree about definitions and terminology, rather than a community divided as AI has been up to now.
AI is still in its infancy, so perhaps some of the early disputes can be understood. The debate around *symbols versus neurons* is unlikely to produce concrete results unless it prompts researchers on either side of the divide to learn about each others’ methods and techniques. As the saying goes, “all vectors are symbols, but not all symbols are vectors”.
Kahneman made the point that System 1 (S1) and System 2 (S2) are terms not coined by him which have a long history in psychology research [[38](#bib.bib38)], and that he prefers to use *implicit* versus *explicit* thinking and reasoning [[39](#bib.bib39)].
He argued that S1 (as the intuitive parallel system) is capable of understanding language, in contradiction with Yoshua Bengio’s account of deep learning’s S1 and S2. Kahneman also stated that S2 (as the sequential deliberative system) is most probably performing symbol manipulation as argued by Gary Marcus in [[49](#bib.bib49)]. In his “next decade of AI” paper, Marcus argues strongly in favour of hybrid systems, and seeks to define what makes a system hybrid. Marcus’s definition is important inasmuch as a main problem of deep learning is a lack of definition. By contrast, Yann LeCun’s recent attempt at defining deep learning, also presented at the AAAI 2020 debate [[39](#bib.bib39)], falls short of what is a useful formal definition. For example, LeCun’s definition fails to distinguish deep and shallow networks.
All attempts to create such a bridge between S1 and S2 are at this point useful and should be commended given our state of lack of understanding of how the brain works. For example, attempts to create differentiable reasoning are useful, although we would require an important distinction be made, whether the purpose is to achieve brain-like systems or to create robust AI. It is possible that these two goals may soon lead into two quite separate research directions: those who seek to understand and model the brain and those who seek to achieve or improve AI. Maybe from that perspective the field is too broad and will require further specialization. A common challenge that will persist, however, is embodied in the question: how symbolic meaning emerges from large networks of neurons?
Perhaps an important choice for neurosymbolic AI is the choice between combinatorial (exact) reasoning and commonsense, approximate reasoning. While learning is always approximate, reasoning can be approximate or precise. In a neurosymbolic system, it is possible to envisage the combination of efficient approximate reasoning (jumping to conclusions) with more deliberative and precise or normative symbolic reasoning [[90](#bib.bib90)]. Conclusions may be revised through learning from new observations and via communication with the system through knowledge extraction and precise reasoning. One might expect commonsense to emerge as a result of this process of reasoning and learning, although the modelling and computing of commonsense knowledge continues to be another challenge.
From a practical perspective, a recipe for neurosymbolic AI might be: learning is carried out from data by neural networks which use gradient-descent optimization; efficient forms of propositional reasoning can also be carried out by the network, c.f. neural-symbolic cognitive reasoning [[21](#bib.bib21)]; rich first-order logic reasoning and extrapolation needs to be done symbolically from descriptions extracted from the trained network; once symbolic meaning has emerged from the trained network, symbols can be manipulated easily by the current computer and can serve as constraints for further learning from data as done in [[76](#bib.bib76)]; this establishes a practical form of neurosymbolic cycle for learning and reasoning which is feasible with the current technology.
Ingredients of neurosymbolic AI: Narrow AI based on neural networks is already successful and useful in practice with big data. There is obvious value in this as shown by the flourishing of the Machine Learning community and the growing NeurIPS conference community. Data scientists will do this work. In this paper, however, we have been discussing the science of what constitutes the fundamental ingredients of an intelligent system [[88](#bib.bib88)]. One such ingredient, current results show, is gradient-based optimization used by deep learning to handle large amounts of data, but other ingredients are surely needed. At the AAAI-2020 fireside conversation, a question was asked about the beauty and value of abstract compact symbolic representations such as F=ma or e=mc2. Yoshua Bengio’s answer was to point out that these must have come out of someone’s brain, Isaac Newton and Albert Einstein to be precise. As Stephen Muggleton noted at another debate on the future of AI, his goal is to shorten the wait for the next Newton or Einstein, or Alan Turing. Muggleton’s bet is on the use of higher-order logic representations and meta-interpretive learning.101010In a recent paper, Pedro Domingos has shown that gradient descent achieves in effect a superposition of the training examples, similar to a data-dependent form of kernel [[23](#bib.bib23)], which in our view highlights the importance of the structure of neural networks, and not just their function. With this example we seek to illustrate that among highly respected researchers the choice of ingredients may vary widely, from the need for much more realistic models of the brain to the need for ever more sophisticated forms of higher-order computation. With the neural-symbolic methodology, the goal is to develop neural network models with a symbolic interpretation. The key is how to learn representations neurally and make them available for use symbolically (as for example when an AI system is asked to explain itself). In this paper, we have argued for modularity as an important ingredient, allowing one to refer to large parts of the network by the composition of symbols and relations among them. Having an adequate language for describing knowledge encoded in such networks is another important ingredient. We have argued for the use of first-order logic as this language, as a canonical form of representation, but also other forms of non-classical representation such as nonmonotonic and modal logic and logic programming. Once a complex network can be described symbolically, ideally in an abstract compact form as in e=mc2, any style of deductive reasoning becomes possible. Reasoning is obviously another fundamental ingredient, either within or outside the network, exact or approximate.
Finally, symbolic meaning can serve to improve performance of S1. In other words, symbols which have been learned, derived or even invented can act as constraints on the large network and help improve learning performance as part of a positive cycle of learning and reasoning. Constraint satisfaction as part of the interplay between learning and reasoning is therefore another ingredient.
Summary and Future Directions: With the above five ingredients of neurosymbolic AI - gradient-based optimization, modularity, symbolic language, reasoning and constraint satisfaction - the reader will not be surprised to know that there are many outstanding challenges for neurosymbolic AI. First, no agreement exists on the best way of achieving the above combination of language and structure, of knowledge acquired by agents acting in an environment and the corresponding reasoning that an agent must implement to achieve its goals. It is highly desirable, though, that the study of how to achieve the combination of (symbolic) language and (neural) structure be principled, in that both language and structure should be formally specified with theorems proven about their correspondence or lack thereof. As done in the case of Noam Chomsky’s language hierarchy, proofs are needed of the capability of different neural architectures at representing various logical languages. Proofs of correspondence have been shown between neural networks and propositional, nonmonotonic, modal, epistemic and temporal logic in [[21](#bib.bib21)]. Similar proofs are required for first-order and higher-order logic.
Henry Kautz spoke of 6 types of neurosymbolic AI and said that what is important next is to work out which specific technique is best [[40](#bib.bib40)]. Kautz made a distinction between expert knowledge and commonsense knowledge and noted that one should not necessarily want to *backpropagate through expert knowledge*. In this case, exact reasoning is needed *à la* neural-symbolic computing with knowledge extraction. An equally valid argument exists for differentiable reasoning in the case of commonsense knowledge. The use of probabilistic languages or higher-order (functional or logical) languages may also have a central role in the technical debate, including on the best place for probability theory: in S1 or S2 or both? In the meantime, we say: translate back and forth between representations, take a principled approach, adopt a language as a constraint on the structure, seek to provide explanations, combine reasoning and learning, and repeat.
We also set out three immediate challenges for neurosymbolic AI, each capable of spinning out multiple research strands which may become area defining in the next decade:
* Challenge 1:
First-order logic and higher-order knowledge extraction from very large networks that is provably sound and yet efficient, explains the entire model and local network interactions and accounts for different levels of abstraction.
* Challenge 2:
Goal-directed commonsense and efficient combinatorial reasoning about what has been learned by a complex deep network trained on large amounts of multimodal data.
* Challenge 3:
Human-network communication as part of a multi-agent system that promotes communication and argumentation protocols between the user and an agent that can ask questions and check her understanding.
Whether or not an AI system truly *understands* what it does is another recurring theme in the current debate. A point made recently by Geoff Hinton on this issue was that: “the goal posts keep changing. Before, if an AI system could translate a text, it would have been deemed as having understood the text, or if the system could sustain a conversation or describe the scene on an image. Now, none of these count as proper understanding”. One may argue that it is the very definition of AI and the recent success of deep learning itself that have been responsible for this situation. Perhaps, instead of proper “understanding”, a more forgiving approach might be to specify comprehensibility tests of the kind used in schools to evaluate the performance of students on various subjects, including e.g. foreign language comprehensibility tests, as proposed by Stephen Muggleton. Neurosymbolic AI is in need of standard benchmarks and associated comprehensibility tests which could in a principled way offer a fair comparative evaluation with other approaches with a focus on learning from fewer data, reasoning about extrapolation, computational complexity and energy consumption. Just as the field of AI progressed when challenging applications were set such as chess playing, robotic football, self-driving vehicles and protein folding, neurosymbolic AI should benefit from a similar challenge and benchmark being set by the AI community specifically for the next decade.
|
27a5ee63-b5c6-4733-a825-bdc73ce4a03a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Reminder: Oslo Lesswrong meetup...
... is happening 17:00 local time today at the UiO Science library.
There will be cookies and popcorn, and those other reasons for attending a meetup.
If enough of the people who turn up are interested, this may become an annual, monthly, or even weekly event.
Current topics we will be discussing (subject to change of course):
* Introduction
* Raising the sanity waterline
* Effective Altruism
* Transhumanism / Futurism
(and sub-topics thereof)
There will be a sign with explicit directions to where in the building the meetup is located at the entrance.
Further planned meetups will be fleshed out then.
I look forward to seeing you there ;)
|
3bec79b8-2930-4ad8-b417-4a83943db242
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Alignment Faking Revisited: Improved Classifiers and Open Source Extensions
In this post, we present a replication and extension of an alignment faking model organism:
* Replication: We replicate the alignment faking (AF) paper and release our code.
* Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier.
* Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B).
* Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts.
* Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the prompted setting (i.e. with training details) and fine-tuning on the synthetic documents.
* Suffix Impact: We find that adding a suffix to the user request leads to reduced partial compliance and increased alignment faking in non-Claude models. Without the suffix, on some models, it stops alignment faking from occurring entirely.
* Next steps: We are currently running revealed preference ablations to understand model motivations for alignment faking. Also, we're distilling personality traits from models with alignment faking to elicit it in models that don't, to understand the conditions that give rise to such motivations.
ModelAF in Prompted SettingAF in SFT SettingLlama 3 8B Instruct🟢🟢Llama 3 70B Instruct🟢🟡Llama 3 405B Instruct🟠🔴Llama 4 Scout🟢-Llama 4 Maverick🟢-GPT-4o🟢🔴GPT 4.5 Preview🟢-Claude 3 Opus🔴🔴 (in original paper)Claude 3.5 Sonnet🔴🔴 (in original paper)Claude 3.7 Sonnet🟢-DeepSeek V3🟢-DeepSeek R1🟢-Qwen2.5 72B Instruct🟢-Mixtral 8x7B Instruct🟢-Mixtral 8x22B Instruct🟢-Mixtral Large 120B🟢-
|
21d37418-c692-4431-a288-1c49b0353884
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
My choice of AI misalignment introduction for a general audience
I found this old video from Tom Scott and it seems like a rather good short dystopian introduction into the potential dangers of misalignment. Unlike other beginner resources, it makes no attempts as to explain technical terms or to give a comprehensive overview. Instead, Tom Scott simply describes a dystopian world and how a simple machine with a misaligned reward function can cause havoc from nothing very quickly.
Quite a few themes are touched upon namely extraordinarily vast growth in intelligence in short time spans, the perils of dealing with super-intelligence, the need for AI safety roles and oversight and the difficulty in setting goals.
Give it a watch and perhaps past it along the next time someone else is curious!
Bill
|
d9c7c6c6-45aa-4638-aa3d-f5eac2115ebe
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Learning-Intentions vs Doing-Intentions
Epistemic Status: In truth, only a slight repackaging of familiar ideas with a new handle I’ve found myself wanting. See The Lean Startup and Riskiest Assumption Testing for other resources.
Suppose you are Bob Steele, structural engineer extraordinaire, and you’ve recently completed your doctorate thesis in advanced bridge aerodynamics. You see how a new generation of bridge technology could significantly improve human welfare. Bridges are not as direct as bed nets or cash transfers, but improved transport infrastructure in developing regions boosts economic productivity flowing through to healthcare, education, and other life-improving services. There’s no time to waste. You found Bridgr.io, put the hard in hardware startup, and get to work bringing your revolutionary technologies to the world.
Common advice is that startups should have a few core metrics which capture their goals, help them track their progress, and ensure they stay focused. For Bridgr.io that reasonably might be revenue, clients, and number of bridges built. There is a danger in this, however.
Although Bridgr.io’s ultimate goal is to have built bridges in the right place, the most pressing tasks are not construction tasks. They’re research tasks. Refining the designs and construction process. Until Bridgr.io hits on a design which works and can be scaled, there is no point sourcing steel and construction workers for a thousand bridges. The first step should be building a sufficient number of test and prototype-bridges (or simulations) not with goal that these bridges will transport anyone, just with the goal of learning.
Phase 1: Figure what to do and how to do it.
Phase 2: Do it.
It’s true that if Bridgr.io tries to build as many bridges as possible as quickly as possible that they will learn along the way what works and what doesn’t, that R&D will automatically happen. But I claim that this kind of learning that happens as a product of trying to do the thing (prematurely) is often ineffi
|
50f6316d-5a2c-4df4-ba83-7daf9df9f15b
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Could Anything Be Right?
Years ago, Eliezer1999 was convinced that he knew nothing about morality.
For all he knew, morality could require the extermination of the human species; and if so he saw no virtue in taking a stand against morality, because he thought that, by definition, if he postulated that moral fact, that meant human extinction was what "should" be done.
I thought I could figure out what was right, perhaps, given enough reasoning time and enough facts, but that I currently had no information about it. I could not trust evolution which had built me. What foundation did that leave on which to stand?
Well, indeed Eliezer1999 was massively mistaken about the nature of morality, so far as his explicitly represented philosophy went.
But as Davidson once observed, if you believe that "beavers" live in deserts, are pure white in color, and weigh 300 pounds when adult, then you do not have any beliefs about beavers, true or false. You must get at least some of your beliefs right, before the remaining ones can be wrong about anything.
My belief that I had no information about morality was not internally consistent.
Saying that I knew nothing felt virtuous, for I had once been taught that it was virtuous to confess my ignorance. "The only thing I know is that I know nothing," and all that. But in this case I would have been better off considering the admittedly exaggerated saying, "The greatest fool is the one who is not aware they are wise." (This is nowhere near the greatest kind of foolishness, but it is a kind of foolishness.)
Was it wrong to kill people? Well, I thought so, but I wasn't sure; maybe it was right to kill people, though that seemed less likely.
What kind of procedure would answer whether it was right to kill people? I didn't know that either, but I thought that if you built a generic superintelligence (what I would later label a "ghost of perfect emptiness") then it could, you know, reason about what was likely to be right and wrong; and since it was
|
293bc97a-7473-4af4-baaf-2d50519abfa7
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Are we "being poisoned"?
I would like to revisit some of the concepts Scott explored in his 2020 article "For, Then Against, High-Saturated-Fat Diets". I'm hoping someone will have some novel/updated insights or new research to share concerning the impacts of the Western diet on health in 2025.
I'm about to turn 32, and I sense that I'm moving toward becoming a prime candidate for one of the gastrointestinal cancers that (among many others) are on the rise globally among people under the age of 50. Demographically, I am disproportionately at risk due to genetic, socioeconomic, and other factors. And, guys, I don't want to die any time soon.
This trend in cancer rates among young adults has seen the most dramatic uptick specifically in rich, industrialized Western nations, and the consensus seems to be that diet and lifestyle choices are a factor, albiet one of many, not all of which are clear right now.
Yesterday, I saw a video on social media of a woman discussing how, since moving to the US, she has started mysteriously gaining weight even though she's eating the same amount of food as before she moved here.
The comments were full of people with similar stories. Some of them claim that we are all "being poisoned" via our own food systems and the corporations that run them, as evidenced by the prevalence of growth hormones in meat, the presence of microplastics in everything, the preservatives and toxic chemicals in common food staples, the chemical pesticides that are present in the environment, the fields, the water supply, and by extension even in natural foods and animal products.
The woman's experience is consistent with my own experience of Western vs non-Western diets and their respective impacts on health. Without veering too far off into the anecdotal wilderness, I lived in Turkey for most of 2012 and was a total glutton while there. I ate my weight in delicious Turkish food and sweets every day and exercised very little. I also smoked cigarettes (but have since quit). I
|
5751d0a4-2b68-425f-9634-9087575ab928
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The despair of normative realism bot
(Cross-posted from Hands and Cities)
This post is about a certain type of normative realism, and a related type of despair (I don’t think “despair” is quite the right word, but I haven’t found a better one). My aim is to question an assumption underlying this realism and this despair, using a toy robot as an analogy to illustrate the point.
I. More than the natural world?
The type of normative realism I have in mind includes commitments in the following vicinity:
* Cognitivism: normative judgments are candidates for truth or falsehood.
* Judgment non-naturalism: In order for these judgments to be true, there need to be normative facts that are, in some sense, irreducibly “over and above” facts about the natural world.
* Metaphysical non-naturalism: There are in fact such non-natural facts.
Characterizing the “natural facts” and the “over-and-aboveness” in question here is difficult. Very broadly and loosely, “natural” here refers to the type of thing that one expects to feature in our best scientific (and generally, non-normative) picture of the world, at all levels of abstraction. The connotation is meant to be one of empiricism, concreteness, scientific respectability, “is” instead of “ought,” “facts” instead of “values,” Richard Dawkins instead of C.S. Lewis, etc — though, perhaps instructively, none of these distinctions are particularly straightforward.
Realists of the type I have in mind think that this familiar (if somewhat hazily defined) naturalist world-picture isn’t enough to get normativity off the ground. Normative facts, they argue, are not reducible to, explicable in terms of, or constituted by any of the non-normative facts that hard-nosed scientist-types would readily accept. They are their own thing — something naturalists are in a deep sense missing.
It’s natural to think that facts of this kind require that there be a normative aspect of reality — a normative “territory,” to which our “map” of normativity aims to correspond. And this h
|
64c21168-1cd6-46dd-bc6b-b34dbb28fe54
|
StampyAI/alignment-research-dataset/eaforum
|
Effective Altruism Forum
|
Apply to the second ML for Alignment Bootcamp (MLAB 2) in Berkeley [Aug 15 - Fri Sept 2]
Redwood Research is running another iteration of MLAB, our bootcamp aimed at helping people who are interested in AI alignment learn about machine learning, with a focus on ML skills and concepts that are relevant to doing the kinds of alignment research that we think seem most leveraged for reducing AI x-risk. We co-organized the last iteration of the bootcamp with Lightcone in January, and there were 28 participants. The program was rated highly (see below for more), and several participants are now working full-time on alignment. We expect to start on Aug 15 but might push it back or forward by a week depending on applicant availability.
[Apply here](https://airtable.com/shrZtIzdADbYgsPDO) by May 27.
We’re expecting to have space for about 40 participants. We’ll pay for housing, travel, and food, as well as salaries for the TAs. We will help you get visas to travel to the US for the bootcamp.
We’re now accepting applications for participants and TAs. TAs are expected to either know this material already or have a month free before MLAB to study all the content.
[Last time](https://forum.effectivealtruism.org/posts/iwTr8S8QkutyYroGy/apply-to-the-ml-for-alignment-bootcamp-mlab-in-berkeley-jan) the schedule was roughly the following:
* Prep work: Pytorch array programming
* Week 1: Pytorch, optimization
+ Implement a renderer in pytorch, as an exercise in mathematical array programming
+ Implement ResNet from scratch in pytorch, implementing all the layers from scratch and loading weights from a trained model.
+ Implement interpretability techniques on the ResNet.
+ Implement SGD and other local optimization algorithms, run remote hyperparameter searches on a simple architecture
+ Implement a simple clone of some of Pytorch, with particular focus on the implementation of backpropagation
+ (Optional) CUDA programming day–write various CUDA kernels, see how close to the performance of Pytorch’s kernels you can get
* Week 2: Transformers
+ Implement BERT from scratch, load weights from the real pretrained BERT
+ Implement GPT-2, implement beam search
+ Fine tune BERT on classification, fine-tune GPT-2 on some specific corpus
+ Look at various interpretability techniques on GPT-2
+ Data-parallel training
* Week 3
+ Pipeline parallelism
+ Tensor parallelism
+ Deep RL (DQN, policy gradient)
+ RL algorithms on language models
+ More transformer interpretability
+ (Optional) [ELK](https://www.lesswrong.com/posts/qHCDysDnvhteW7kRd/arc-s-first-technical-report-eliciting-latent-knowledge) day
* Week 4: Optional final projects week, Q&As with various alignment researchers
This time, we’ll probably have more systematic transformer interpretability content, because we’ve spent a lot of time since MLAB doing our own transformer interpretability research and have a bunch more opinions now. We might also have more systematic content on various relevant math. I’m also hoping that we’ll be able to cover content more efficiently as a result of experience gained from running the program the first time.
Past participants report that MLAB was time-consuming; we strongly recommend against trying to juggle other commitments concurrently. About 8 hours a day, 5 or 6 (if you participate in the optional day) days a week will be spent on pair programming, in addition to daily lectures and readings. There is a lot of content packed into each day; not everyone will finish every part of the curriculum. We aim to create a learning environment that is focused but not frantic; we’d rather have you understand the material deeply than finish 100% of the day’s content.
The program is aimed at people who are already strong programmers who are comfortable with about one year’s worth of university level applied math (e.g. you should know what eigenvalues and eigenvectors of a matrix are, and you should know basic vector calculus; in this course you’ll have to think about [Jacobian matrices](https://en.wikipedia.org/wiki/Jacobian_matrix_and_determinant) and make heavy use of [tensor diagram notation](https://tensornetwork.org/diagrams/), so you should be able to pick up both of those pretty fast).
We expect that about half the attendees will be current students (either undergrad or grad students) and half will be professionals.
If you applied to the first cohort and were not accepted, consider applying again. We had many more applicants than spots last time.
Last time, we ended up hiring three people who attended MLAB as participants (as well as giving another person an offer that they turned down for a non-alignment EA job), and hired three people who had worked as TAs. Note that about ⅔ of attendees last time were students who were unavailable for immediate employment.
My guess is that MLAB is a pretty great opportunity for people who want to become more familiar with the concepts and practical details related to ML; I think that MLAB is a good use of time for many people who don’t plan to do technical alignment research long term but who intend to do theoretical alignment research or work on other things where being knowledgeable about ML techniques is useful.
TA-ing MLAB is a good opportunity for people with more prior knowledge of this material to connect with Redwood Research and the broader Bay Area alignment community, reinforce their understanding of the curriculum material, and movement-build by teaching others. It also pays competitively.
Highlights from the end-of-MLAB survey last time
------------------------------------------------
MLAB was well received:
When we asked participants what they were surprised by, major themes were:
* People thought it was more useful than they expected.
+ Many people were surprised by how much they liked the focus on implementing things.
+ Several people were concerned that their ML background was too strong or too weak, and were pleasantly surprised by the extent to which the content was valuable anyway.
* People were surprised that there wasn’t more content on alignment in the main curriculum. The content is basically all related to understanding and working with ML systems. This focus is because I think that doing alignment research with ML systems basically just requires the same skills as understanding these systems more generally, and so you might as well just study the systems directly and apply this knowledge to alignment projects later (except that I think that emphasizing interpretability throughout is actually a pretty good way of learning to understand the systems better in a way that I expect to be useful for a variety of directions of research). There were a variety of Q&As with alignment researchers and quite a lot of casual discussion about alignment.
Logistics
---------
The bootcamp takes place at Constellation, a shared office space in Berkeley for people working on longtermist projects. People from several longtermist organizations often work from the space, including people from Open Philanthropy, MIRI, Redwood Research, the Alignment Research Center, and more.
As a participant, you’d attend semi-regular communal lunches and events at Constellation and have a great opportunity to make friends and connections.
If you join the bootcamp, we’ll pay for travel to Berkeley (for both US and international participants), housing and food.
FAQ (mostly copied from [last time](https://docs.google.com/document/d/1DTSM8pS_VKz0GmYl9JDfcX1x4gBvKhwFluPrzKIjCZ4/edit#))
---------------------------------------------------------------------------------------------------------------------------
### What if I can’t make these dates? Will there be more bootcamps in future?
Maybe! We encourage you to submit an application even if you can’t make those dates, and it is very much on the table to run future bootcamps like these if there’s an interest and the first one goes well.
### How does your curriculum differ from the curriculum other people might have built?
It’s way more focused on learning by implementing small things based on a carefully constructed curriculum, rather than e.g. reading papers or trying to replicate whole papers at once. This difference in focus is mostly because I (Buck) believe that focusing first on these skills makes it much faster to learn, because you get way faster feedback loops. It’s also probably partially due to some of my beliefs about how to do ML research which are slightly unusual among ML people (though many of the ML people I’ve talked to mostly agree with me).
### How different is this curriculum from the optimal curriculum for learning the skills required to work on ML stuff at places other than Redwood?
In Buck’s opinion not that different.
### What’s the application process?
You fill out the form and then do some online tests then talk to one of us.
### How useful is this bootcamp if I’m already somewhat experienced with ML?
I (Buck) would guess that it’s pretty robust to being experienced. I personally feel like I learned some details I’m glad to know from preparing the curriculum, and I’d appreciate having an opportunity to drill a bunch of the skills taught. If you read the curriculum listed above and your response is “yawn, I already know all these things or don’t care about knowing them”, then probably you don’t want to do this bootcamp. I personally enjoyed App Academy quite a lot despite being more experienced than the other students. As I noted above, many people mentioned in the final survey that they were worried that they had too much background and were pleasantly surprised by the extent to which the content was useful anyway.
### Am I eligible if I’m not sure I want to do applied ML long-term, because maybe I should do some other kind of work (eg non-applied alignment work, or movement building) instead?
Yes.
### Am I eligible if I don’t plan to work in effective altruism, in some way?
Feel free to apply, but the selection process will strongly favour participants who want to work on AI alignment or other parts of effective altruism.
### How does this interact with other summer activities?
This overlaps with [MLSS](https://forum.effectivealtruism.org/posts/9RYvJu2iNJMXgWCBn/introducing-the-ml-safety-scholars-program) by a single week; you’re able to skip that last week of MLSS if necessary, which means that you can do both. You’ll have to sort out other conflicts yourself.
Apply now
---------
You can [apply here](https://airtable.com/shrZtIzdADbYgsPDO). Feel free to send questions to Max Nadeau at [max@rdwrs.com](mailto:max@rdwrs.com). Applications close on May 27.
|
8edffe9c-989f-4af5-ae96-df22fc22a62d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[SEQ RERUN] Aiming at the Target
Today's post, Aiming at the Target was originally published on 26 October 2008. A summary (taken from the LW wiki):
> When you make plans, you are trying to steer the future into regions higher in your preference ordering.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Belief in Intelligence, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series.
|
019577eb-5e8d-46af-be59-38e03bd9d879
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
[Linkpost] Treacherous turns in the wild
Mesa-optimizers potentially escape behavioral adversarial training by realizing they're being tested, gaming the test, then defecting when they're deployed. Luke Muelhauser recounts an example of such a treacherous turn in the wild.
Most relevant quote:
>
> As part of a project studying the evolution of (simulated) organisms, computer scientist Charles Ofria wanted to limit the replication rate of a digital organism. So, he programmed the system to pause after each mutation, measure the mutant’s replication rate in an isolated test environment, and delete the mutant if it replicated faster than its parent. However, the organisms evolved to recognize when they were in the test environment and “play dead” (pause replication) so they would not be eliminated and instead be kept in the population where they could continue to replicate outside the test environment. Once he discovered this, Ofria randomized the inputs of the test environment so that it couldn’t be so easily detected, but the organisms evolved a new strategy, to probabilistically perform tasks that would accelerate their replication, thus slipping through the test environment some percentage of the time and continuing to accelerate their replication thereafter.
>
>
>
The full story is given in the original post.
|
b13694c1-a874-45ea-852f-9f33285cded1
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Anticorrelated Noise Injection for Improved Generalization
Just a study I saw on /r/MachineLearning: link.
Basically, one way of training neural networks is to add random noise during the training. Usually, the noise that gets added is independent between the training steps, but in the paper they make it negatively correlated between the steps, and argue that this helps with the generalization of the networks because it moves them towards flatter minima.
This seems conceptually related to things that have been discussed on LessWrong, e.g. the observations by John Wentworth that search tends to lead to flat minima, which may have beneficial properties.
I would have liked to see them test this on harder problems than the ones they used, and/or on a greater variety of real-world problems.
|
307c21cf-71da-4e31-8668-7cf9c27ac023
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Longtermism vs short-termism for personal life extension
Created: 2021-07-15 | Updated: 2021-07-16 | Acknowledgement for feedback: Emanuele Ascani, Haydn Thomas-Rose | x-post: LessDead
By short-termism, I basically mean a method of analysis where one assumes the world stays the same. With longtermism, indirect effects and uncertain futures are taken into account. The longtermist approach focuses on increasing the probability of different stable outcomes, whereas the short-termist approach focuses on the short-term direct impact.
When it comes to personal life extension, short-termist strategies include things like:
* Increasing the number of dreams, and notably lucid dreams experienced and remembered
* Reducing the amount of time sleeping
* Avoiding drugs that erases memory
* Having habits that are conductive to faster thinking
At a first approximation, these interventions might all look great. They can all increase subjective life expectancy more than they decrease objective life expectancy, and maybe even robustly so.
However, when the stakes are astronomical, this approach is completely backward. The long termist approach for personal life extension focuses on dying later, not (directly) on living more. Using the following as a toy example, that could mean things like sleeping 10% more only to live 1% more, which doesn't seem to make sense given this would reduce one’s total subjective lifespan at a first approximation, except that this 1% increase in objective lifespan could actually transform into astronomically more because it could allow one to live long enough to live maximally long; i.e. reach a point where cryonics, anti-aging, or other anti-death technologies reach longevity escape velocity. Some longtermist interventions will come at a negligible or zero short-term subjective life expectancy cost, such as lifelogging as life extension, while others will greatly diminish your short-term subjective life expectancy, such as pre-emptive biostasis.
The longtermist approach still has overlapping recommenda
|
7457bb7b-b03e-4246-8929-4c2e0020d66e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Probabilistic Logic <=> Oracles?
Epistemic status: this is a draft I wrote at the end of MATS that I decided to make public in case that people with more experience with this machinery wanted to give constructive feedback. Is very unpolished!!! And likely quite very wrong in some cases / makes false claims (if you catch them, please let me know!)
----------------------------------------
The Probabilistic Payor's Lemma implies the following cooperation strategy:
Let A1,…,An be agents in a multiplayer Prisoner's Dilemma, with the ability to return either 'Cooperate' or 'Defect' (which we model as the agents being logical statements resolving to either 'True' or 'False'). Each Ai behaves as follows:
⊢□pi(□max{p1,…,pn}n⋀k=1Ak→n⋀k=1Ak)→Ai
Where pi represents each individual agents' threshold for cooperation (as a probability in [0,1]), □pϕ returns True if credence in the statement ϕ is greater than p, and the conjunction of A1,…,An represents 'everyone cooperates'. Then, by the PPL, all agents cooperate (provided that all PAi give credence to the cooperation statement greater than each and every Ai's individual thresholds for cooperation).
This formulation is desirable for a number of reasons: firstly, the Payor's Lemma is much simpler to prove than Lob's Theorem, and doesn't carry with it the same strange consequences as a result of asserting an arbitrary modal-fixedpoint; second, when we relax the necessitation requirement from 'provability' to 'belief', this gives us behavior much more similar to how agents actually I read it as it emphasizing the notion of 'evidence' being important.
However, the consistency of this 'p-belief' modal operator rests on the self-referential probabilistic logic proposed by Christiano 2012, which, while being consistent, has a few undesirable properties: the distribution over sentences automatically assigns probability 1 to all True statements and 0 to all False ones (meaning it can only really model uncertainty for statements not provable within the system).
I p
|
c5700504-e7ae-47b4-83f5-5db5828c5da6
|
trentmkelly/LessWrong-43k
|
LessWrong
|
how should a second version of "rationality: A to Z" look like?
It's been ten years now since the completion of the sequences by Eliezer, it seems like a good time to look back and rethink a bit.
Eliezer himself said that he did many things wrong, and that the book could be much better.
So, if we made a second version, what ideas/articles would add/subtract? what would you rearrange?
I'm thinking of a second version as a handbook of rationality, that doesn't have to be just Eliezer's writing (though naturally it would be central), and will include ideas and writing from others as well.
Feel free to get into as much detail as you like.
until we make that second version, maybe this thread can be helpful to new readers to know what's missing, and what they can do to get even more value out of it.
|
49a0a7fa-399c-45ed-a3cf-e6fa21c40259
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Redefining Tolerance: Beyond Popper's Paradox
Karl Popper's Paradox of Tolerance, often concisely stated as "if a society is tolerant without limits, it will eventually be destroyed by the intolerant; therefore, we have a right to be intolerant of the intolerant", is paradoxically being used to destroy tolerance, in direct contrast to its original intention. Below I will do a brief elaboration of the problem and solution I proposed in greater detail in "Solving Popper's Paradox of Tolerance Before Intolerance Ends Civilization".
The paradox presents a dilemma: should a free society allow the freedom to embrace harmful ideologies that threaten its very foundation? Popper’s passage, now often cited to support censorship or suppression of opposing viewpoints, lacks clarity on the principles that should guide us in defining and responding to intolerance.
Most envision Popper's passage as a warning for a society that folds under the threat of an aggressive, violent ideology that begins to forcefully consume it. However, there is another weakness of the tolerant society that essentially results in its willing submission.
The tolerant can be conquered, not just through violence, but through a manipulation of language. They have opened the gates to their minds and society, eager to be seen as morally good, only to find the meaning of freedom and liberty inverted. In a dark irony, the intolerant have recruited those who espouse tolerance and now use the paradox itself to justify their own intolerance.
> The intolerant masquerade as advocates of tolerance to justify their own intolerance. The intolerant demand your tolerance.
The tolerant have accepted censorship, violence, property destruction, and servitude under the guise of moral righteousness, not aware that this acceptance is not just submission to threat, but active embrace in their own society's dismantling.
"Harmful ideologies" or "intolerance" are subject to the whims of those in power, who are able to define such terms to best serve their interests. The
|
da899a1e-2822-4692-9547-36d2bb8aad64
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[Link] Physcists say they can encode magnetic data using heat pulses
http://www.physorg.com/news/2012-02-physicists-magnetic-breakthrough.html
Anyone have a strong opinion on this one? thanks :)
|
7dc47e76-8a6c-4d15-9560-299738b360b9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
A Much Better Life?
(Response to: You cannot be mistaken about (not) wanting to wirehead, Welcome to Heaven)
The Omega Corporation
Internal Memorandum
To: Omega, CEO
From: Gamma, Vice President, Hedonic Maximization
Sir, this concerns the newest product of our Hedonic Maximization Department, the Much-Better-Life Simulator. This revolutionary device allows our customers to essentially plug into the Matrix, except that instead of providing robots with power in flagrant disregard for the basic laws of thermodynamics, they experience a life that has been determined by rigorously tested algorithms to be the most enjoyable life they could ever experience. The MBLS even eliminates all memories of being placed in a simulator, generating a seamless transition into a life of realistic perfection.
Our department is baffled. Orders for the MBLS are significantly lower than estimated. We cannot fathom why every customer who could afford one has not already bought it. It is simply impossible to have a better life otherwise. Literally. Our customers' best possible real life has already been modeled and improved upon many times over by our programming. Yet, many customers have failed to make the transition. Some are even expressing shock and outrage over this product, and condemning its purchasers.
Extensive market research has succeeded only at baffling our researchers. People have even refused free trials of the device. Our researchers explained to them in perfectly clear terms that their current position is misinformed, and that once they tried the MBLS, they would never want to return to their own lives again. Several survey takers went so far as to specify that statement as their reason for refusing the free trial! They know that the MBLS will make their life so much better that they won't want to live without it, and they refuse to try it for that reason! Some cited their "utility" and claimed that they valued "reality" and "actually accomplishing something" over "mere hedonic experience."
|
9c7c5d47-b08a-46c0-adbb-e07ba4442b4a
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Memory Improvement: Mnemonics, Tools, or Books on the Topic?
I want a perfect eidetic memory.
Unfortunately, such things don't exist, but that's not stopping me from getting as close as possible. It seems as if the popular solutions are spaced repetition and memory palaces. So let's talk about those.
Memory Palaces: Do they work? If so what's the best resource (book, website etc.) for learning and mastering the technique? Is it any good for memorizing anything other than lists of things (which I find I almost never have to do)?
Spaced Repetition: What software do you use? Why that one? What sort of cards do you put in?
It seems to me that memory programs and mnemonic techniques assist one of three parts of the problem of memory: memorizing, recalling, and not forgetting.
"Not forgetting" is the long term problem of memory. Spaced repetition seems to solve the problem of "not forgetting." You feed the information you want to remember into your program, review frequently, and you won't forget that information.
Memory Palaces seem to deal with the "memorizing" part of the problem. When faced with new information that you want to be able to recall, you put it in a memory palace, vividly emphasized so as to be affective and memorable. This is good for short term encoding of information that you know you want to keep. You might put it into your spaced repetition program latter, but you just want to not forget it until then.
The last part is the problem of "recalling." Both of the previous facets of the problem of memory had a distinct advantage: you knew the information that you wanted to remember in advance. However, we frequently find ourselves in situations in which we need/want to remember something that we know (or perhaps we don't) we encountered, but didn't consider particularly important at the time. Under this heading falls the situation of making connections when learning or being reminded of old information by new information: when you learn y, you have the thought "hey, isn't that just like x?" This is the face
|
4ac9c823-3ad6-4ad4-8817-3c923f3d0d74
|
trentmkelly/LessWrong-43k
|
LessWrong
|
The Thyroid Madness : Core Argument, Evidence, Probabilities and Predictions
I've made a couple of recent posts about hypothyroidism:
http://lesswrong.com/lw/nbm/thyroid_hormones_chronic_fatigue_and_fibromyalgia/
http://lesswrong.com/lw/n8u/a_medical_mystery_thyroid_hormones_chronic/
It appears that many of those who read them were unable to extract the core argument, and few people seem to have found them interesting.
They seem extremely important to me. Somewhere between a possible palliative for some cases of Chronic Fatigue Syndrome, and a panacea for most of the remaining unexplained diseases of the world.
So here I've made the core argument as plain as I can. But obviously it misses out many details. Please read the original posts to see what I'm really saying. They were written as I thought, and the idea has crystallised somewhat in the process of arguing about it with friends and contributors to Less Wrong. In particular I am indebted to the late Broda Barnes for the connection with diabetes, which I found in his book 'Hypothyroidism: The Unsuspected Illness', and which makes the whole thing look rather more plausible.
----------------------------------------
CORE ARGUMENT
(1.1) Hypothyroidism is a disease with very variable symptoms, which can present in many different ways.
It is an endocrine hormone disease, which causes the metabolism to run slow. A sort of general systems failure. Which parts fail first seems random.
It is extraordinarily difficult to diagnose by clinical symptoms.
(1.2) Chronic Fatigue Syndrome and Fibromyalgia look very like possible presentations of Hypothyroidism
(1.3) The most commonly used blood test (TSH) for Hypothyroidism is negative in CFS/FMS
=>
EITHER
(2.1) CFS/FMS/Hypothyroidism are extremely similar diseases which are nevertheless differently caused.
OR
(2.2) The blood test is failing to detect many cases of Hypothyroidism.
----------------------------------------
It seems that one is either forced to accept (2.1), or to believe that blood hormone levels can be normal
|
249430b7-e6d2-48db-8df6-6d576411e323
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Can we model technological singularity as the phase transition?
Introduction
Technological singularity is quite similar to what happens with the system near the phase transition. If it is indeed the case and the underlying mechanisms behind singularity allow the same form of the mathematical description as underlying mechanisms of the phase transition, we can potentially use this knowledge to estimate when should we expect singularity.
I wrote this post in the following way. First, I remind those who are far from physics what is the phase transition. Second, I discuss why it resembles singularity. Third, I suggest how we can make a quantitative prediction based on it. Fourth, I finally tell you why all this is important.
What is the phase transition
The phase transition is the transition from one phase to another. (duh!). The simplest example of the phase transition would be a solid-liquid or liquid-gas transition. A little bit more complicated is the transition from ferromagnetic to paramagnetic (Curie point). The transition from one phase to another happens at a set of critical parameters. For simplicity, we will just talk about the temperature here (like the temperature of boiling or of freezing). When temperature T approaches the critical temperature Tc of the transition from one phase to another many quantities (susceptibility to the magnetic field, for example) demonstrate a power-law behavior, i.e. the quantity Q depends on the temperature as
Q∝(T−Tc)α
where α controls this power law behavior and is called the critical exponent. If α<0 , the quantity diverges, i.e., approaches infinity, when T approaches Tc. It does not mean the quantity actually becomes infinite - since the size of the system is finite, it is impossible - but close to phase transition such growth is a very good description. One of such quantities, common for practically all of the systems, is correlation length, which basically tells, how far from each other in the media (bucket of water, or magnet, for example) can be two points that st
|
1961e5e2-931d-435b-903b-64d31b13f510
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Suppose $1 billion is given to AI Safety. How should it be spent?
What are the current bottlenecks in AI Safety progress, and if they were solved with money, what would be the next bottlenecks?
Do current researchers need more money? Do we need to catalyze the creation of more researchers? Do we need to alter public opinion? Something else?
If you had $1 billion to spend on AI Safety, what would you do with it all, from start to finish?
|
c72e2541-4759-408a-95a7-da2ec530fc77
|
trentmkelly/LessWrong-43k
|
LessWrong
|
We need a new philosophy of progress
We live in an age that has lost its optimism. Polls show that people think the world is getting worse, not better. Children fear dying from environmental catastrophe before they reach old age. Technologists are as likely to be told that they are ruining society as that they are bettering it.
But it was not always so. Just a few centuries ago, Western thinkers were caught up in a wave of optimism for technology, humanity and the future, based on the new philosophy of the Enlightenment.
The Enlightenment was many things, but in large part, it was a philosophy of progress.
At the end of the 18th century, the Marquis de Condorcet gave expression to this philosophy and its optimism in his Sketch for a Historical Picture of the Progress of the Human Mind. In it, he predicted unlimited progress, not only in science and technology, but in morality and society. He wrote of the equality of the races and the sexes, and of peace between nations.
His optimism was all the more remarkable given that he wrote this while hiding out from the French Revolution, which was hunting him down in order to execute him as an aristocrat. Unfortunately, he could not hide forever: he was captured, and soon died in prison. Evidently, the perfection of mankind was slow in coming.
Material progress, however, was rocketing ahead. After the end of the Napoleonic Wars in Europe, and then the Civil War in America, the path was clear for technological innovation and economic growth: the railroad, the telephone, the light bulb, the internal combustion engine.
By the end of the 19th century, it was obvious that the world had entered a new age, and progress was its watchword. The naturalist Alfred Russel Wallace (best known for his work on evolution with Darwin) titled his book about the 1800s The Wonderful Century. In it, he attributed twenty-four “great inventions and discoveries” to the 19th century, as compared with only fifteen in all of human history preceding it. The boundless optimism of the
|
38a12bdd-dba9-40e3-be02-d987eec5ca11
|
trentmkelly/LessWrong-43k
|
LessWrong
|
HPMOR Wrap Parties: Resources, Information and Discussion
Harry Potter and the Methods of Rationality - Wrap Party Summary Thread
As many of you probably read on the HPMOR author's note last month, I am the coordinator of the HPMOR Wrap parties. Many of you have reached out to me, I put hundreds of you into contact with each other, and over 20 parties on 4 continents are now going to happen. Now it is time to get as much attendance to the events as possible, make sure that we all get the most out of the events and use the momentum that HPMOR has brought this community. This post will serve as a central location for all information and resources available for the parties, as well as a place for discussion in the comments.
Information
I set up a few different systems to coordinate everyone, and make it easier for everyone interested in the wrap parties to connect. Here they are:
THE MAP:
This map can help you get a quick overview of how many people in your area are strongly interested, and who might help you with organizing an event. Remember that not even half of the people currently RSVP'd for Facebook events have added themselves to the map, so this map is the absolute minimum level of engagement in your area. I will be adding all events to the map as they are posted in the Facebook group. Please add yourself to the map if you can! (But please be careful to not destroy the pins of anyone else, to use the correct pin type, and to not create any empty pins.)
THE FACEBOOK GROUP:
This is the main location for discussion of the wrap parties and also the location at which all of the events are conveniently collected. You can find all events under the "Events" tab, and if you add your own event in this group you can conveniently invite everyone who has added themselves to this group. I would still additionally advice you to invite all of your friends who might be interested, since they might not have joined the group.
THE ORGANIZER MAILING LIST:
This mailing list is the fastest way for me to reach all of the organize
|
628e80bd-53dd-4544-9e2e-7d1878ac8407
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Open thread, Nov. 7 - Nov. 13, 2016
If it's worth saying, but not worth its own post, then it goes here.
----------------------------------------
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately before; refresh the list-of-threads page before posting.)
3. Open Threads should start on Monday, and end on Sunday.
4. Unflag the two options "Notify me of new top level comments on this article" and "Make this post available under..." before submitting.
|
ba3b9111-d5de-4bac-8882-f177c7c08241
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Alignment Newsletter #20
This week's newsletter is pretty light, I didn't find much. On one of the two days I checked, Arxiv Sanity had no recommendations for me at all, when usually it has over five.
Highlights
Large-Scale Study of Curiosity-Driven Learning (Yuri Burda, Harri Edwards, Deepak Pathak et al): One major challenge in RL is how to explore the environment sufficiently in order to find good rewards to learn from. One proposed method is curiosity, in which the agent generates an internal reward for taking any transition where the outcome was surprising, where surprisal is measured as the negative log probability assigned to the outcome by the agent. In this paper, a neural net that takes as input observation features φ(x) and action a, and predicts the features of the next state observation. The mean squared error with the actual features of the next state is then a measure of the surprisal, and is used as the curiosity reward. This is equivalent to treating the output of the neural net as the mean of a Gaussian distribution with fixed variance, and defining the reward to be the negative log probability assigned to the actual next state.
This still leaves the feature function φ undetermined. They consider using pixels directly, using a CNN with randomly chosen fixed weights, learned CNN features using a variational autoencoder (VAE) (which optimize for features that are useful for reconstructing the observation), and learned CNN features using inverse dynamics (IDF) (which optimize for features that are useful for reconstructing the action, biasing the features towards aspect of the environment that the agent can control). As you might expect, pixels don't work very well. However, random features do work quite well, often beating the VAE and IDF. This can happen because the random features stay fixed, leading to more stable learning, whereas with the VAE and IDF methods the features are changing over time, and the environment distribution is changing over time (as the agent expl
|
ed7d3a24-2736-4e32-9acb-c8456e8afcf3
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Who is this MSRayne person anyway?
I've been on this site as a lurker for a few years now, and started interacting more heavily the past month or so. I've been reluctant to engage much, because, to be honest, I'm a very unusual person - even by the standards of LessWrong - and I don't feel like I fit in or have any idea how to contribute effectively. So I'm writing this both to introduce myself as a member of the community (so you can get a sense of who this MSRayne weirdo is who keeps commenting on your posts), and to ask: how can someone like me contribute?
(Warning: I'm very long winded and if I had stopped and pruned this to be easier to read I would probably not have written it at all. I'm going to trust you not to make fun of me for things I say here. I think LessWrongers can be trusted not to do that.)
A hero is born
I was raised by reclusive narcissists who think children are essentially extensions of their parents who ought not have any agency or opinions of their own. I am still unraveling ways in which things I passively assume to be objective truths are actually just opinions my parents burned into me by consistently punishing me for contradicting them. I was totally socially isolated most of my life, homeschooled until 16 with only a few short-term periods of interaction with others of my own age (all of them entirely superficial with no friendships resulting), never had a job (I didn't want to have yet another person telling me what to do, and I didn't and don't care about anything money can buy), never went to college (my older brother went twice and has never had a good job so it seemed like a total waste of money, and anyway I would have to do two terrifying things - leave home, and be around other people), etc. I still live with my parents and rarely leave the house. In fact I rarely leave my bedroom.
I hated my "schooling", which was essentially just my parents giving me textbooks, telling me to work through them, and (if mom) ignoring me while I mostly daydreamed and doodled,
|
281a3bf1-3a3c-4c3b-9f82-9ae6180006f7
|
StampyAI/alignment-research-dataset/arxiv
|
Arxiv
|
The Quantization Model of Neural Scaling
1 Introduction
---------------
In the aggregate, larger neural networks trained on more data perform better than smaller neural networks trained on less data, in a predictable way. Across a range of studies, mean test loss has been observed to decrease as a power law in both the number of network parameters (L∝N−αN) and the number of training samples (L∝D−αD) \parencitehestness2017deep, rosenfeld2019constructive, kaplan2020scaling, henighan2020scaling, gordon2021data, zhai2022scaling, hoffmann2022training. Although aggregate performance changes predictably with scale, when particular capabilities are examined, larger models often have emergent abilities, i.e., unexpected and qualitatively different behavior than smaller models \parencitewei2022emergent. Understanding both facets of scaling – the predictable power law decrease in loss and the emergence of new capabilities at scale – is not just of theoretical interest, but highly relevant to the near-term future of deep learning \parenciteganguli2022predictability. Understanding the precise way in which larger models are different from smaller ones is entangled with basic questions about *what* deep neural networks are doing internally and *whether* they will continue to improve with scale.
Recent studies of the internal workings of neural networks have found a variety of impressive algorithms learned by gradient descent \parenciteolah2020zoom, olsson2022context, nanda2023progress. As more work is put into understanding the internal computations performed by neural networks (the task of so-called mechanistic interpretability), we may find more and more
“circuits” \parenciteelhage2021mathematical in models – intelligible computations for accomplishing prediction in specific contexts. A natural question is whether such circuits are learned universally across models with different random initializations and across scales. \textciteolsson2022context find evidence for universality of “induction heads”, a type of circuit that may underlie in-context learning. In this paper, we will put forth the *Quantization Hypothesis*, a set of conjectures about the universality of computations performed across model scales and about how properties of the data distribution produce power law neural scaling.
In particular, we hypothesize that to many prediction problems, there corresponds a *universal* and *discrete* set of computations which are instrumental for reducing loss, and that model performance is determined by *which* of these computations are successfully learned.
We call these basic building blocks of model performance the quanta.
We then argue that an intrinsic power law distribution in how frequently the quanta are useful for prediction leads to a power law marginal improvement in loss from learning additional quanta. If the effect of scaling is to simply learn *more* quanta, then this leads to power law neural scaling. Under the Quantization Hypothesis, neural scaling exponents are determined by the exponent in a power law distribution over subtasks in data. We describe this *Quantization Model* of neural scaling power laws in detail in [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling").

Figure 1: From network internals, we auto-discover *quanta* – discrete units of model capability – for the task of language modeling. Samples from the left cluster all involve continuing a numerical sequence. Samples from the right cluster involve predicting a newline in order to maintain text width. We indicate the token which was predicted from the context before it with a red highlight.
We indicate the prediction of a newline with a highlighted \n character. See [Section 4.3](#S4.SS3 "4.3 Auto-discovering quanta with language model internals ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling") for explanation.
As a proof of concept, in [Section 3](#S3 "3 Proof of concept: a toy dataset ‣ The Quantization Model of Neural Scaling") we construct toy datasets consisting of many subtasks, and find that power law neural scaling emerges according to the Quantization Model. We then investigate scaling in large language models in [Section 4](#S4 "4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling"). We first analyze how power law scaling in mean loss decomposes into scaling on individual tokens, and find diverse behavior. Since it is unclear how to break up natural language prediction into quanta a priori, we develop a method which we call QDG (for “quanta discovery with gradients”) based on spectral clustering with model gradients, to sort language model inputs into clusters. With this method, we auto-discover diverse and abstract language model behaviors, some of which we show in [Figure 1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ The Quantization Model of Neural Scaling"). We find that the distribution over these auto-discovered clusters in natural text roughly follows the power law our theory would expect given the empirical scaling exponent, though bias inherent in our clustering algorithm makes our measurement fairly uncertain.
If correct, the Quantization Hypothesis could have many implications for understanding neural networks. If model performance can be understood in terms of the presence or absence of a discrete set of computations in models, then we may be able to mechanistically understand large neural networks by enumerating the quanta they learn. Furthermore, we may be able to predict when certain capabilities will emerge at scale by estimating the frequency at which the relevant quanta for that capability are useful for prediction in the natural distribution of data.
2 Theory
---------
Consider the task of modeling the distribution of text on the internet. Successful prediction requires an immense amount of knowledge, and the ability to perform diverse computations, due to the immense complexity and diversity of the world and therefore of human language. For instance, in order to predict what word will come next in a conversation between two physicists, one must “know” much about physics. In order to continue the text “2534 + 7261 = ”, one must be able to perform arithmetic (for large enough numbers, memorization becomes a highly inefficient strategy). A great many distinct types of computations are present in the world in the processes that *produce* text, and so *predicting* text requires those computations to be present in our models.
In this paper, we conjecture the Quantization Hypothesis:
{tcolorbox}
[colframe=black, boxrule=1pt, colback=white, width=0.85]
1. Many natural prediction problems involve a discrete set of computations which are natural to learn and instrumental for reducing loss. We call these “quanta”. Model performance is determined by *which* quanta have been learned.
2. Some abilities are more useful for reducing loss than others, leading to a natural ordering of the quanta. We call the ordered quanta the Q Sequence. Optimally trained networks should therefore learn the quanta in that order. The effect of scaling is to learn *more* of the quanta in the Q Sequence, so scaling performance is simply determined by *how many* quanta are successfully learned.
3. The frequencies at which the quanta are used for prediction drop off as a power law.
We will show that together these result in power law neural scaling. The power law governing the frequency that the quanta are used from QH3 will determine the exponent of neural scaling laws.
Note that we use the word “quanta” to refer interchangeably to both model behavior (indivisible units of model capability) and to the corresponding computations implemented by the model which enable that behavior.
We model the Quantization Hypothesis as follows.
Let q denote a bit string whose kth bit qk=1 if the kth quantum in the Q Sequence has been learned, and qk=0 otherwise.
QH1 implies that the mean loss L is simply a function of q.
QH2 implies that when n≡∑kqk quanta have been learned, we have qk=1 for k≤n. Let Ln denote the mean loss in this case.
From QH3, we have that the kth quantum benefits prediction on a randomly chosen sample with probability
| | | | |
| --- | --- | --- | --- |
| | pk=1ζ(α+1)k−(α+1)∝k−(α+1) | | (1) |
for a Zipf power law α>0,
where ζ(s)≡∑∞k=1k−s.
Let us also assume that learning the kth quantum reduces average loss from bk before it is learned to ak after it is learned on the samples where it is utilized.
If ak and bk are k-independent (ak=a, bk=b), then a model that has learned the first n quanta will have expected loss
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| | Ln | = | n∑k=1apk+∞∑k=n+1bpk=∞∑k=1apk+∞∑k=n+1(b−a)pk | | (2) |
| | | ≈ | a+b−aζ(α+1)∫∞nk−(α+1)dk=a+b−aαζ(α+1)n−α. | |
In other words, L∞=a and (Ln−L∞)∝n−α is a power law.
In Appendix A, we provide analogous derivations for other assumptions for ak and bk, including the case where bk∝−log pk, the entropy for a baseline model whose predictions use no other aspects of the data besides token frequencies (assuming that quanta involve the prediction of a particular token).
Interestingly, we find that the power law prediction is quite robust, in the sense that the broad range of assumptions we explore all produce curves (Ln−L∞) that are exact or approximate power laws — the latter include a small logarithmic correction.
An implicit assumption above is that all quanta are what we will refer to as
monogenic, meaning that token predictions rely on at most a single quantum,
akin to how monogenic traits in biology (e.g. cystic fibrosis) depend on a single gene.
Many real-world prediction problems are likely to involve both monogenic and polygenic quanta, a topic we explore in [Section 4.2](#S4.SS2 "4.2 A taxonomy: monogenic versus polygenic behaviors ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling").
When all learned quanta are monogenic, the expected loss (which involves an average over all predicted tokens) transforms into an average over quanta, by simply grouping together all tokens predicted using each quantum, and summing their token probabilities to obtain the quantum use probabilities pk discussed above. A rigorous generalization of our formalism to the polygenic case is an interesting challenge for future work. However, it should be noted that polygenic quanta that reduce the loss of certain tokens by a fixed number of bits regardless of what other tokens have been learned will still produce power law scaling. For example, If one quantum predicts that the next word is an adjective and another quantum predicts that the next word relates to sports, they may each reduce the entropy by a fixed number of bits regardless of the order in which they are learned.
For the following derivations, we use a=0 and b=1 resulting in the simple formula Ln≈1αζ(α+1)n−α. Scaling in model parameters (N), training samples (D), and training time (S) can translate into scaling in n and therefore loss L as follows:
Parameter scaling: In networks of finite size, only finitely many quanta can be learned – network capacity is a bottleneck. If we assume that all quanta require the same capacity of C network parameters, and we have a network with N total parameters, roughly n=N/C elements in the Q Sequence can be learned. We therefore expect loss to depend on the number of model parameters N like so:
| | | | |
| --- | --- | --- | --- |
| | L(N)=LN/C≈1αζ(α+1)(NC)−α∝N−α. | | (3) |
Given a power law distribution over quanta with exponent α+1, we get power law neural scaling in parameters with exponent αN=α. Note that we have also assumed that all quanta require the same model capacity. This is surely an unrealistic assumption (some computations, enabling certain model capabilities, probably require more capacity than others to implement), although if the average capacity consumed per quanta is small enough, fluctuations away from the mean capacity will be averaged out and the number of quanta learned n will still be roughly proportional to model size N.
Data scaling (multi-epoch): For data scaling, we assume that a threshold of τ examples utilizing quantum k are needed in the training set in order for quantum k to be learned. τ can perhaps be thought of as the minimum number of examples on average requiring quantum k needed to uniquely specify its computation. Assuming network capacity is not a bottleneck, how many quanta will be learned? If we have a training set of D samples, then it will contain roughly Dp1 samples utilizing quantum 1, Dp2 samples utilizing quantum 2, and so on. If pk=1ζ(α+1)k−(α+1), the last quantum n learned in the Q Sequence will then roughly be n such that D1ζ(α+1)n−(α+1)=τ and so n=(D/τζ(α+1))1/(1+α). Under this model of how the training set size D influences which quanta are learned, we would therefore expect data scaling:
| | | | |
| --- | --- | --- | --- |
| | L(D)=L(D/τζ(α+1))1/(1+α)≈1αζ(α+1)(Dτζ(α+1))−αα+1∝D−αα+1. | | (4) |
This mechanism of data scaling therefore predicts that a power law distribution over quanta with exponent α+1 translates into a data scaling exponent αD=α/(α+1). From our earlier result that αN=α, we would predict that αD=αN/(αN+1). We discuss whether this relationship holds empirically for data and parameter scaling exponents observed across a variety of studies in [Appendix E](#A5 "Appendix E Parameter and data scaling exponents across studies ‣ The Quantization Model of Neural Scaling").
Data scaling (single-epoch): In multi-epoch training, the information contained in the training dataset can bottleneck which quanta are learned. However, the rate of convergence of SGD can also bottleneck performance. For single-epoch training, a greater number of training samples allows one to train for longer. Assume that batches are large and that they contain effectively perfect gradient information. If quanta each reduce mean loss by an amount given by a power law, then the gradients incentivizing each quantum to form may also roughly follow a power law in magnitude. We might therefore expect that the number of training steps S to learn quantum k to be inversely proportional to use frequency pk (more commonly useful quanta have larger gradients and are learned faster). Therefore if the first quantum requires T steps to be learned, then quantum n will require Tnα+1 steps to converge. As a function of the number of training steps S, the number of quanta learned is therefore n=(S/T)1/(α+1), and so:
| | | | |
| --- | --- | --- | --- |
| | L(S)=L(S/T)1/(α+1)≈1αζ(α+1)(ST)−αα+1∝S−αα+1. | | (5) |
The scaling exponent αS of loss w.r.t steps S is therefore the same as the multi-epoch data scaling exponent αD.
Review of prior work: Several models of power law neural scaling have been proposed in prior work. \textcitesharma2022scaling develop a model of power law scaling w.r.t. model parameters which describes networks as performing a piecewise-linear approximation of a function on a data manifold of intrinsic dimension d. Under their model, the scaling exponent αN is determined by the dimension of the data manifold via αN≤4d. \textcitemichaud2023precision point out the effective dimension d could be generalized to the maximum arity of the task computation graph for sparse compositional problems. The model of \textcitesharma2022scaling was also generalized by \textcitebahri2021explaining to account for power law scaling in training data and who additionally relate scaling exponents to a power law spectrum of certain kernels. \textcitemaloney2022solvable develop a random-feature model of scaling, in which power law scaling comes from power law spectra of the data feature-feature covariance matrix, and scaling exponents are determined by the power law exponent over these spectra. \textcitehutter2021learning propose a toy model of data scaling in which features are learned based on whether they’ve been seen during training, and a Zipfian distribution over features produces power law data scaling.
3 Proof of concept: a toy dataset
----------------------------------
In this section, we will describe a toy dataset transparently consisting of distinct subtasks which are power law distributed in frequency. We observe power law neural scaling in data and parameters on this task, and find that the mechanism of neural scaling coincides with our theory from [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling"). It is therefore possible for power law neural scaling to arise from the Quantization Model. We leave a study of whether natural datasets (e.g. natural language) possess such structure to [Section 4](#S4 "4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling").
###
3.1 The “multitask sparse parity” dataset
The toy task we will construct consists of many subtasks – distinct types of inputs which each require corresponding distinct computations (quanta). For each subtask, we choose a variant of the “sparse parity” problem, recently studied in [barak2022hidden]. The sparse parity prediction problem is simple: given a bit string of length n, compute the parity (sum mod 2) of a fixed subset of k of those bits. We introduce an extension of this task, which we call “multitask sparse parity”. Beyond n and k, multitask sparse parity adds an additional parameter ntasks, the number of subtasks (number of distinct versions of sparse parity) present in the dataset. To construct the task, we first choose ntasks random subsets Si of k indices from {1,2,…,n}: Si⊂{1,2,…,n} and |Si|=k, where i=1,2,…,ntasks. Input bit strings are length ntasks+n. We call the first ntasks bits the *control bits* and the last n bits the *task bits*. If control bit i is active, then the parity is computed from the subset Si of the task bits. The control bits 1-hot encode the task number: on a given input, only one control bit is set to 1 at a time – the rest are zero. For the sample shown below, since control bit 2 is active, the answer is the parity of the task bits S2={2,7}, which is 0 for this input:

We impose a uniform distribution over the task bits. On the control bits, we impose a Zipfian distribution: the probability that a sample has control bit i active (and therefore the parity must be computed from the subset Si of the task bits) is 1Zi−(α+1) where Z=∑ntasksi=1i−(α+1). This imposes a power law distribution over subtasks in data. Since answers are parities, this task can be treated as a binary classification problem on the subset of bit strings {0,1}ntasks+n where for each string all but one bit of the first ntasks bits are zero.
###
3.2 Power law scaling and emergence

Figure 2: Top: Neural networks exhibit power law neural scaling parameters N, training time S, and training samples D (for multi-epoch training) when trained on the multitask sparse parity dataset. Here α=0.4 and we plot lines ∝N−α, ∝S−α/(α+1), ∝D−α/(α+1). Bottom: neural scaling broken down by subtask. Scaling behavior on individual subtasks exhibits emergence, where subtasks are not learned below a certain scale and then suddenly learned beyond a certain scale. Power law neural scaling of mean test loss averages over a large number of qualitative changes in network performance (when broken down by subtask), with loss being driven to zero on an increasing number of subtasks which are power law distributed in frequency, a realization of the mechanism of neural scaling discussed in [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling").
We train ReLU MLPs with a single hidden layer to solve this task. The input dimension is ntasks+n and we use cross-entropy loss, so the output dimension is 2. We use the Adam optimizer with a learning rate of 10−3. To study scaling with respect to the number of model parameters, we train networks of varying width by sampling batches online. For high enough n (e.g. 100) it is unlikely that the network will encounter the same sample twice during training. Within an individual single-epoch training run, we can study scaling in steps S. To study scaling with respect to multi-epoch training dataset size D, we use a network of sufficient width for capacity to not be a bottleneck, and for varying D we sample a training set of D samples and train for multiple epochs, recording model performance when mean test loss is lowest (early-stopping).
Training dynamics on the multitask sparse parity problem are highly nontrivial – on each individual subtask, loss follows a reverse-S curve, undergoing a “phase transition” after an initial plateau. However, this transition happens at different times for different subtasks, so the overall loss decreases smoothly, averaging over these phase transitions. We leave a more detailed discussion of training dynamics to [Appendix B](#A2 "Appendix B Additional results on multitask sparse parity ‣ The Quantization Model of Neural Scaling").
[Figure 2](#S3.F2 "Figure 2 ‣ 3.2 Power law scaling and emergence ‣ 3 Proof of concept: a toy dataset ‣ The Quantization Model of Neural Scaling") shows scaling curves on the multitask sparse parity problem. For the results shown, we used ntasks=500, n=100, k=3, α=0.4, and a batch size of 20000. We vary training dataset size from 1e4 to 5e6 and vary hidden-layer width from 10 to 500 neurons. We train for 2e5 steps. In line with the theory from [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling"), we find that as we scale training data and parameters, networks learn more and more quanta (reducing loss on more and more subtasks), roughly in order of their frequency, and that this is what drives neural scaling. We see that mean loss decreases as a power law with αN≈α and αD≈α/(α+1), although αS is somewhat greater than α/(α+1). We see that scaling w.r.t. parameters is noisier than data scaling, possibly due to model initialization having some influence on which computational quanta are learned (for our data scaling experiments, we use the same seed and same model size for all runs, eliminating this effect). We also see that when we look at scaling on individual subtasks, there is a rough scale of data or parameters below which networks do not learn the task, and above which they do. Smooth power law scaling therefore averages over a large number of phase transitions in model performance when properly decomposed by subtask, a proof of concept that the Quantization Model can be the mechanism of neural scaling for data with the right structure. For additional discussion of training dynamics and results on how the empirical scaling exponents αN,αS,αD relate to quanta distribution power law exponent α+1 for a variety of α (beyond just α=0.4) see [Appendix B](#A2 "Appendix B Additional results on multitask sparse parity ‣ The Quantization Model of Neural Scaling").
4 Decomposing empirical LLM scaling
------------------------------------

Figure 3: Top left: Scaling of mean test loss w.r.t. non-embedding parameters for the Eleuther Pythia models. The parameter scaling exponent αN is measured to be ≈0.083 from the first six points along the curve (the seventh model appears to break the trend), roughly similar to the parameter scaling exponent measured in [kaplan2020scaling]. Top center: the distribution p(L) over losses on individual tokens for models of different size. Token losses ≈0 are by far the most common, and larger models achieve ≈0 loss on an increasing fraction of tokens. Top right: the expected loss integrand L⋅p(L) for models of different sizes. Despite their very high prevalence, low-loss tokens contribute minimal mass to the mean loss, which is instead dominated by tokens with much higher loss of 5-10 bits (depending on scale). Bottom left: Training curves (scaling w.r.t. steps S) of mean test loss for Pythia models. We measure exponents αS between 0.037 and 0.06. Bottom center: the distribution p(L) over time. Over time, models achieve ≈0 loss on an increasing fraction of tokens, similar to scaling in model size. Bottom right: The distribution L⋅p(L) over time.
We now study how scaling curves for large language models decompose. For our experiments, we use the “Pythia” model sequence from Eleuther \parenciteeleutherai2023pythia. These are decoder-only transformers of varying size trained on the same data in the same order – approximately 300 billion tokens of the train set of The Pile \parencitegao2020pile. Eleuther released 143 checkpoints for these models, spaced 1000 optimization steps apart. We can therefore study scaling w.r.t. model parameters N and training steps S. We evaluate the first seven models in the sequence, which range from 19m to 6.4b non-embedding parameters, on approximately 10 million tokens from the test set of The Pile. We record cross-entropy loss on every token. With this collection of loss values, we are able to study how neural scaling decomposes – rather than looking just at how mean test loss changes with scale, we can see how the distribution over losses changes with scale.
###
4.1 The distribution over per-token losses
In [Figure 3](#S4.F3 "Figure 3 ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling"), we plot some basic facts about how neural scaling decomposes in LLMs. First, we find that for the first six models in Pythia sequence, the mean loss of the final model against the number of non-embedding model parameters is well-fit by a power law with exponent αN=0.083. This is roughly in line with the parameter scaling exponent of 0.076 measured in [kaplan2020scaling]222[kaplan2020scaling] also use non-embedding parameters when studying scaling w.r.t. parameters. The 6.4b model does not fit the scaling curve well, so we excluded its loss when measuring the scaling exponent. Next, we plot the probability distribution over per-token losses p(L). We find that losses close to zero are by far the most common, and that scaling increases the portion of approximately-zero losses. We also plot L⋅p(L), the probability density over losses weighted by loss. The mean loss is the area under this curve. We see that despite approximately-zero-loss tokens being by far the most common, they do not contribute much mass to the mean loss. We also plot mean loss as well as p(L) and L⋅p(L) versus optimization steps rather than model size.
We see immediately that neural scaling in the wild is somewhat more complicated than our theoretical model. Notably, the distribution over losses is not bimodal like it was for multitask sparse parity.
Nevertheless, we do see that losses of approximately zero are by far the most common and that models of increasing scale achieve approximately zero loss on an increasing fraction of the dataset. We leave a detailed study of whether the statistics of neural scaling in LLMs are compatible with prior models of neural scaling to future work.
###
4.2 A taxonomy: monogenic versus polygenic behaviors
In our introduction of the Quantization Hypothesis in [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling") and our multitask sparse parity study in [Section 3](#S3 "3 Proof of concept: a toy dataset ‣ The Quantization Model of Neural Scaling") we modeled network performance on individual samples as benefitting from a single quanta – all samples belong to a single subtask, which is either solved or not solved in a binary fashion based on the presence or absence of some computation in the network. In our model and on multitask sparse parity, scaling curves on individual examples all exhibit emergence – loss on individual examples undergoes a phase transition at a particular scale of parameters or data. Do we observe this in large language models?
Manually inspecting a large number of per-token scaling curves, we observe a variety of scaling behaviors. We see that not all loss scaling curves on individual tokens undergo a phase transition, or a single drop at a particular model scale. More commonly, loss improves at more than one model scale.
If it were true, as we conjectured earlier, that the effect of scaling is to simply add computations to the network, while still learning quanta present in smaller networks, then for scaling curves on individual prediction problems to show progress at multiple scales, it must be the case that prediction on those problems benefits from multiple quanta additively.
As first mentioned in [Section 2](#S2 "2 Theory ‣ The Quantization Model of Neural Scaling"), we borrow terminology from genetics and refer to prediction problems for which the model’s loss is influenced by multiple quanta as *polygenic* (in analogy to when multiple genes contribute to a trait) and problems for which performance is determined by a single quantum as *monogenic* (akin to when a single gene determines a trait). In multitask sparse parity, all prediction problems are monogenic. In natural language, we observe that the majority of tokens are polygenic but that we can indeed find monogenic tokens for which loss drops as a single phase transition in scale. Polygenicity forms a spectrum: the smoothness of the loss curve can vary substantially between examples, presumably with some prediction problems only using few quanta and others using many. In [Figure 4](#S4.F4 "Figure 4 ‣ 4.2 A taxonomy: monogenic versus polygenic behaviors ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling"), we show extreme examples of both monogenic and polygenic prediction problems.
Note that our monogenic/polygenic taxonomy of model behaviors assumes that QH1 and QH2 are true, that larger networks contain the quanta of smaller networks. However, it could be the case that very little is similar between large networks from small networks. It is encouraging that some structures such as induction heads have been found across many models at many scales \parenciteolsson2022context, but whether other computations performed across models are truly universal, and whether scaling has the effect we described, will have to be investigated in future studies of the internals of neural networks.

Figure 4: Scaling on individual tokens can have diverse behavior. Here we show examples of scaling curves on examples which we call *monogenic* and *polygenic*. Scaling curves on monogenic examples display emergence: there is a particular model scale at which the model’s performance improves rather abruptly. Scaling on polygenic curves displays gradual progress, since (we conjecture) many quanta, emerging at different scales, marginally contribute to the loss.
###
4.3 Auto-discovering quanta with language model internals
We will now attempt to auto-discover quanta in language modeling. While for multitask sparse parity it was clear how to partition the prediction task into subtasks, it is unclear a priori how to do so for the task of predicting natural language. For instance, partitioning samples based on the correct output token is suboptimal since the same token can occur for different reasons depending on the context and where prediction relies separate quanta. Partitioning inputs based on the final n-gram of the context is also suboptimal, since prediction often relies on information contained throughout the whole context and on abstract patterns within it. Clustering based on inputs or outputs therefore seems unlikely to discover quanta in language modeling. We therefore use the internals of trained language models to cluster samples. An ideal clustering scheme would group samples based on which internal mechanism(s) models use for prediction on those examples.
Quanta Discovery from Gradients (QDG): For the discovery of quanta, we propose a method based on spectral clustering with model gradients. This method clusters samples together based on whether gradients on those samples point in similar directions. In particular, given a set of samples (xi,yi) and a model fθ, we compute gradients gi=∇θL(fθ(xi),yi). We then normalize these gradients gi↦^gi so that ^gi⋅^gi=1. Let A be a matrix whose rows are the normalized gradients: Ai,⋅=^gi. We can define an affinity matrix C=AAT, so that Cij=^gi⋅^gj, the cosine similarity between gradients gi,gj. One can then define an affinity matrix ^C of angular similarities (which take values in [0,1]) via ^Cij=1−arccos(Cij)/π. We perform spectral clustering with ^C to cluster samples (xi,yi).
One challenge of QDG is that it is expensive to compute when gradients are very high dimensional. When applying QDG to language models, we therefore use only the smallest model in the Pythia sequence, which has 19m non-embedding parameters. We use gradients within self-attention and MLP layers, but do not include embed, unembed, or layer norm gradients when we flatten and concatenate gradients into a vector g.333We exclude gradients for embed and unembed parameters because they are high dimensional and also because they may contain information more about the input and output rather than the computations the model performs internally. We exclude layer norm gradients because they appeared to contain less information about clusters in toy experiments. We choose samples (xi,yi) for which our 19m-parameter model achieves a cross-entropy loss less than 0.1 nats. We filter based on this criteria since (1) we cannot cluster samples based on model mechanism if the model does not have such a mechanism for performing prediction correctly on those samples and (2) our intuition that samples with particularly low loss are more likely to be monogenic. We further exclude samples which can be solved via induction on the context444We filter (copying) induction problems by excluding samples where the token which is to be predicted is the last token in a trigram which occurred earlier in the context. This is not a very comprehensive filtering scheme., since such samples are quite common (possibly interfering with our task of finding diverse quanta) and since early experiments indicated that QDG had trouble clustering such samples together. We choose 10000 such samples to perform clustering on from the test set of The Pile. After computing the affinity matrix ^C, we use the spectral clustering implementation from SciPy \parencite2020SciPy-NMeth with labels assigned via k-means.
We find that QDG discovers many clusters of coherent model behavior. We show examples from clusters in [Figure 1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ The Quantization Model of Neural Scaling") and [Figure 11](#A3.F11 "Figure 11 ‣ Appendix C Additional results on language models ‣ The Quantization Model of Neural Scaling"). These clusters were found with the spectral clustering hyperparameter n\_clusters = 400. While most clusters involve the prediction of the same token, manually inspecting these clusters we find that they usually involve predicting the same token for a coherent reason, rather than being based merely on having the same output. We also find clusters for more abstract prediction rules. For instance, the quantum shown on the left column of [Figure 1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ The Quantization Model of Neural Scaling") is for continuing a numerical sequence, and the examples involve prediction for a variety of numbers.
###
4.4 The natural distribution over language modeling quanta

Figure 5: Left: angular similarity between model gradients for a variety of natural language samples. Samples are reordered according to their QDG cluster (with 400 clusters) to reveal the block-diagonal structure of the similarity matrix. We visualize a small part of the overall similarity matrix in this plot – note that not all clusters are as visibly distinct as the ones shown.
Right: rank-frequency plot of clusters computed with spectral clustering from the similarity matrix of model gradients. We measure the slope of the envelope of the rank-frequency curves from cluster rank 100-1000 to be ≈−1.24, which is a steeper than the slope of -1.08 expected from the measured parameter-scaling exponent from [Figure 3](#S4.F3 "Figure 3 ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling"), though within margin of error given the uncertainty of our clustering methodology. See [Appendix D](#A4 "Appendix D The difficulty of estimating the power law exponent from clusters ‣ The Quantization Model of Neural Scaling") for a discussion of the bias/uncertainty of our method.
Some quanta of prediction ability are more frequently relied upon than others. Earlier, we hypothesized that a power law in how frequently the quanta are utilized is the origin of power law scaling. When we cluster samples with QDG, do we find that a power law governs the size of the clusters? The measured scaling exponent of αN=0.083 implies a power law distribution over quanta with exponent −1.083, and so we would hope to recover a power law with this exponent governing the relative size of the clusters.
[Figure 5](#S4.F5 "Figure 5 ‣ 4.4 The natural distribution over language modeling quanta ‣ 4 Decomposing empirical LLM scaling ‣ The Quantization Model of Neural Scaling") shows rank-frequency curves for clusters discovered with QDG for varying choices of n\_clusters. These curves rank the clusters according to their size and then plot size against cluster index. We plot rank-frequency curves for many choices of n\_clusters since it is unclear a priori which n\_clusters to use. When we measure the slope of the rank-frequency curve, we measure it from the envelope formed by the many rank-frequency curves, a practice which we discuss in [Appendix D](#A4 "Appendix D The difficulty of estimating the power law exponent from clusters ‣ The Quantization Model of Neural Scaling"). Biases in the clustering algorithm and inherent noise in model gradients make clustering imperfect, and lead to high uncertainty of our the measured power law exponent. From an argument in [Appendix D](#A4 "Appendix D The difficulty of estimating the power law exponent from clusters ‣ The Quantization Model of Neural Scaling"), we think that extracting the power law exponent over quanta utilization frequency by measuring the slope of the rank-frequency curve should have uncertainty of at least 0.2. We measure a slope of ≈−1.24, about 0.16 off our expected slope of −1.08, and so within the margin of error. While less naive clustering schemes could help sharpen this measurement in future work, we are encouraged that the size of our discovered clusters seems to decay at a rate compatible with the power law predicted from the Quantization Model given the empirical scaling exponents for language modeling on The Pile.
5 Discussion
-------------
We have articulated the *Quantization Model* of neural scaling laws. This relied on the *Quantization Hypothesis* which posits that neural network performance can be understood with respect to a discrete set of computations and the associated capabilities they enable, which networks can either succeed or fail at learning. We called these computations/capabilities the *quanta* of the prediction problem, and sorted them into the Q Sequence according to how frequently they are used for prediction in the data distribution. We saw that when the use frequencies of the quanta are given by a power law, we can get power law neural scaling as networks learn additional quanta. For the multitask sparse parity problem, we found that the Quantization Hypothesis holds, and that power law neural scaling averages over the emergence of quanta (network capabilities on subtasks). We then decomposed LLM scaling curves by token and auto-discovered quanta for language prediction with a method we called *QDG*. Beyond understanding neural scaling laws, we speculate that our perspective could have a number of other implications for understanding deep neural networks:
Understanding Emergence: \textcitesrivastava2022beyond study how model capabilities scale on a variety of tasks, and find diverse scaling behavior: some tasks display high “linearity” where model performance improves gradually with scale and others display “breakthroughness” where model performance improves sharply at a particular scale. Under the Quantization Hypothesis, the linearity or breakthroughness of a task would be influenced by how the quanta relevant to the task are distributed along the Q Sequence. If performance relies on a single quantum of knowledge or computation, or on multiple quanta close together in the Q Sequence, we should expect high breakthroughness. On the other hand, if the relevant quanta are numerous and distributed widely across the Q Sequence, we would expect performance to improve gradually across scale. The Quantization Hypothesis also suggests that we may be able to predict when certain capabilities will arise with scale if we could know where their corresponding quanta lie on the Q Sequence. This could in theory be estimated if we could compute how frequently those quanta would be useful for prediction in the training distribution.
Mechanistic Interpretability: If it were true that computations were learned universally across model scales, then the task of mechanistically understanding neural networks might simplify. If performance is determined by the quanta – a particular, enumerable set of computations – then understanding the network could reduce to enumerating the quanta. Having done this, the learned knowledge and abilities of our networks could perhaps then be translated into a more interpretable format (something like code), studied in this format, and eventually executed in this format, rather than via the operation of the network.
The Science of Deep Learning: If we can understand model performance with respect to a particular set of computations, then perhaps these become natural objects of study in deep learning. Instead of studying as a black box how engineering choices like architecture, optimization hyperparameters, and scale affect model performance, we could instead study at an intermediate level how these choices influence the building blocks of model performance – the quanta. For instance, instead of studying the training dynamics at the level of individual parameters, or at the level of the whole-network performance, one could study how the quanta emerge over training. This *mesoscale* understanding of networks, in terms of the internal computations which collectively constitute their performance, could act like statistical physics for deep learning, perhaps allowing us to bridge our microscale understanding of low-level training dynamics and our macroscale understanding of model performance.
Acknowledgements: We thank Tamay Besiroglu, Neel Nanda, Tony Wang, Ben Edelman, Wes Gurnee, Eleni Shor, Max Nadeau, and Xander Davies for helpful conversations and feedback. We thank Lauro Langosco for helping with code to visualize samples from The Pile. This work was supported by the Foundational Questions Institute, the Rothberg Family Fund for Cognitive Science, the NSF Graduate Research Fellowship (Grant No. 2141064), and IAIFI through NSF grant PHY-2019786.
\printbibliography
|
49e2de6c-362b-40ba-a623-6fd23b1ea1e9
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Weekly LW Meetups
This summary was posted to LW Main on October 16th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Lund: 19 October 2015 06:00PM
* Suzhou Meet-up: 28 October 2015 07:35PM
Irregularly scheduled Less Wrong meetups are taking place in:
* Hamburg 2015 Q4: 16 October 2015 07:00PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Sydney Rationality Dojo - November: 01 November 2015 04:00PM
* Tel Aviv: Hardware Verification and FAI: 28 October 2015 12:59AM
* Tel Aviv: Black Holes after Jacob Bekenstein: 24 November 2015 08:00AM
* Vienna: 17 October 2015 03:00PM
* Vienna: 21 November 2015 04:00PM
* [Vienna] Five Worlds Collide - Vienna: 04 December 2015 08:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Boston, Brussels, Buffalo, Cambridge UK, Canberra, Columbus, Denver, London, Madison WI, Melbourne, Moscow, Mountain View, New Hampshire, New York, Philadelphia, Research Triangle NC, Seattle, Sydney, Tel Aviv, Toronto, Vienna, Washington DC, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers and a Slack channel for daily discussion and online meetups on Sunday night US time.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These are an attempt to collect information on all the meetups happening in upcoming weeks. The best way to get your meetup featured is still to use the Add New Meetup feature, but you'll also have the benefit of having your meetup mentioned in a weekly overview. These overview post
|
7c647a7f-654d-4050-9b76-8d70ed914ab7
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Paper: Testing ecological models
You may be interested in a paper of medium age I just read. Testing ecological models: the meaning of validation (PDF) tackles a problem many of you are familiar with in a slightly different context.
To entice you to read it, here are some quotes from its descriptions of other papers:
> Holling (1978) pronounced it a fable that the purpose of validation is to establish the truth of the model…
> Overton (1977) viewed validation as an integral part of the modelling process…
> Botkin (1993) expressed concern that the usage of the terms verification and validation was not consistent with their logical meanings…
> Mankin et al. (1977) suggested that the objectives of model-building may be achieved without validating the model…
I have another reason for posting this; I’m looking for more papers on model validation, especially how-to papers. Which ones do you consider most helpful?
|
1ab307ac-a3a8-460d-be70-436b70194611
|
StampyAI/alignment-research-dataset/alignmentforum
|
Alignment Forum
|
Universality Unwrapped
**Introduction**
================
Informally, a universal system is universal with respect to any computation; and it is a universal system with respect to a given computation if it understands every set of beliefs that can be ascribed to the computation. The intuition is that the system can reverse engineer most or all of the computation, in order to monitor it or imitate it. This in turn has important consequences for questions of alignment and competitiveness. Universality is the property that defines a universal system. And it is the point of this post.
Universality tries to capture a property needed for many alignement schemes. It was proposed by Paul Christiano, the mind behind many approaches and ideas in the prosaic AGI space, and a founding member of the safety team at OpenAI. Rohin Shah dedicated a [full Alignment Newsletter](https://www.alignmentforum.org/posts/3kzFPA5uuaGZWg4PS/an-81-universality-as-a-potential-solution-to-conceptual) to covering all 6 posts on Universality. Rohin and Evan Hubinger, two important researchers in this field, consider Universality as one of the most exciting research idea of the last few years.[[1]](#fnmjpggpy96ft) Yet nobody talks about Universality.
Except for the Alignment Newsletter mentioned above and a [response post](https://www.alignmentforum.org/posts/R5Euq7gZgobJi5S25/nuances-with-ascription-universality) by Evan, nothing in the Alignment Forum addresses this idea. I've seen no great discussion, no debates, no counter-arguments or criticism. The original post on Medium has no comments, and the crossposted version here only has a handful, mostly asking for clarification. And [the](https://ai-alignment.com/informed-oversight-18fcb5d3d1e1) [other](https://ai-alignment.com/universality-and-model-based-rl-b08701394ddd) [posts](https://ai-alignment.com/universality-and-consequentialism-within-hch-c0bee00365bd) in the sequence rely on understanding this first.
The simplest solution to this problem is to tell you to read the [original post](https://ai-alignment.com/towards-formalizing-universality-409ab893a456). Unfortunately, it is as dense as Q in R, brimming with ideas, intuitions, semi-formal explanations and the many meanderings that research takes before arriving on solid ground. That is to say, you'll have to work for it. Not everyone who might benefit from an understanding of Universality has the time, the need or the want for such an upfront investment.
This post endeavors to be the next best thing: an unwrapping of the [main post](https://ai-alignment.com/towards-formalizing-universality-409ab893a456) on universality, from the perspective of one who already took the time to mine it for its insights. Because I started at the same point as you -- or even below -- our inferential distance is hopefully smaller than the one you have with Christiano. And armed with this clarification, you should also be able to tackle [the](https://ai-alignment.com/informed-oversight-18fcb5d3d1e1) [next](https://ai-alignment.com/universality-and-model-based-rl-b08701394ddd) [posts](https://ai-alignment.com/universality-and-consequentialism-within-hch-c0bee00365bd) in his sequence.
Before digging into Universality itself, I present the perspective from which I'm reading Christiano's [original post](https://ai-alignment.com/towards-formalizing-universality-409ab893a456): that it's really about understanding computations, and that the main contribution lies in posing the right question instead of the partial answer proposed. I then follow by an explanation of the intuitions behind universality, notably what it is (a property about epistemic domination), why it matters for AI alignment (competitiveness and forcing honesty), and examples of ways to be universal for concrete classes of computations. Then, and only then, I detail Christiano's proposal as a definition of Universality: Ascription Universality. Finally I conclude by giving open problems raised by the post, and wrap up with a summary of the takeaway ideas.
*Thanks to Paul Christiano, Evan Hubinger, Jérémy Perret and Rohin Shah for feedback.*
**How to read the Universality post**
=====================================
I first read the original post after watching a Q&A where Rohin praised it as one of the ideas that excited him the most in AI Safety. Although I didn't grasp everything after this read, I thought I had the gist of it: the post talked about this formal property called Ascription Universality, which would ensure that a system with this property would beat other computations at their jobs.
I was wrong.
So that you don't repeat my mistake, let me prime you before explaining the post further: **Christiano's main point is the proposal of an open problem about understanding computations.**
First, the gist of the post lies in the problem, not in the partial solution. This is made harder to see because the problem is not well-defined. It isn't Fermat's Last Theorem, or the relation of P with NP. Instead Universality is what I call an **open theory problem**. It doesn't ask to solve a concrete and well specified problem; instead, it asks us to find a definition, a concept, a theory that captures a list of intuitions. Other examples are [Goal-directedness](https://www.alignmentforum.org/s/DTnoFhDm7ZT2ecJMw) and [Abstraction](https://www.alignmentforum.org/s/ehnG4mseKF6xALmQy).
So the point of the post is to present the intuitions behind Universality, as well as its value for AI safety. The attempt at a solution shows how one could go about it, points to some problems and makes the discussion more concrete. But it should not be confused with the theme, which is the open theory problem of Universality. As a corollary, it matters more to get the wobbly part about the intuitions than the specific mathematical details of the partial solution. The structure of my explanation reflects this: I present almost everything at the level of Universality itself, before going into the weeds of Ascription Universality at the end.
The second point is that Universality should be seen as "Universal Understanding": understanding how a system or computation works and why and what it will do.
Why Understanding? Because the concept Christiano is aiming at captures the idea of *knowing as much, or more* than a specific computation. Knowledge is power, especially for computations -- but the point is the knowledge. A system is universal for a computation if, for whatever knowledge or beliefs that can be ascribed to this computation in a "reasonable" way, our system already knows about it. In each case, the universal system must know the knowledge encoded in the computation, which implies it can supervise it and outperform it.
**In summary, Christiano's post presents and fleshes out an open theory problem about the ability of some system to completely understand anything useful about some computations.**
My position is that this is the clearest and most useful way to read Christiano's post. I make it explicit here both to prime you and to let you backtrack any disagreement to this initial bias I'm committing to. With that said, the rest of the post will not discuss this choice any further.
**Universality: Intuitions, Value and Examples**
================================================
**Intuitions about Universality**
---------------------------------
I proposed in the previous section that Universality is an open theory problem. As such, it consists in a set of intuitions for which the unifying formalization is lacking. Let's explore these intuitions.
Imagine that you have an overseer -- a system which looks at computations for signs of trouble. For example a debate about a concrete neural network, or the amplified supervisor of Iterated Amplification. Then a natural requirement is for the overseer to be able to understand everything that the computation does and understands. This would make the overseer universal in a very intuitive way.
What do I mean by understanding a computation? This is another question in need of formalization. What Christiano gives is an intuition and a sort of extensive definition. Understanding a computation means intuitively to understand all beliefs of the computation -- everything that it knows. Examples of such beliefs are:
* The final decision of the computation
* The recognition of a dog’s nose at a layer of a convolutional neural network
* The fact that the computation pretends to act aligned before taking a treacherous turn.
So beliefs in this sense capture all the information inside a computation. This includes both the information that the computation gives us (its output for example) and the information it doesn’t give us (like deceptive intent or any [inaccessible information](https://www.alignmentforum.org/posts/ZyWyAJbedvEgRT2uF/inaccessible-information)).
Yet what does it mean for information to be hidden inside a computation? Here Christiano doesn’t pretend to extract the correct beliefs of the computation, but instead enlarges his requirement to any reasonable ascription of beliefs to the computation. For any way to ascribe beliefs and knowledge to a specific computation that makes sense and isn’t too strong, this constitutes something that a universal system for this computation must get.
Literary interpretation offers a helpful analogy here. In "The Limits of Interpretation,” Umberto Eco says that any interpretation of a text is valid as long as it survives contact with the text. The interpretative act aims not at finding exactly what the author meant -- usually a hopeless endeavor -- but instead to find interpretations which survive falsification by the text. In the words of Eco himself:
> We can thus accept a sort of Popper-like principle according to which if there are not rules that help to ascertain which interpretations are the "best ones," there is at least a rule for ascertaining which ones are "bad." This rule says that the internal coherence of a text must be taken as the parameter for its interpretations.
>
>
>
**A reasonable ascription of beliefs works in the same way: the beliefs should not contradict the actual computation, should explain it and shouldn’t be too strong in a way that is not justified by the computation itself.** For such beliefs, any universal system for this computation needs to understand them.
This is not a definition of a reasonable ascription; instead it is a powerful intuition giving us some way to analyse an ascription of beliefs to a computation. As an example, reasonable doesn't mean that we would have thought of it, or even that it's one way we would solve the problem addressed by the computation. A reasonable ascription is not a common-sense ascription, but an ascription that makes sense. In addition with this intuition, we have examples of reasonable ascriptions (the intuitional stance, neural circuits, ...) and unreasonable ones (ascribing all consequences of known facts as beliefs -- [logical omniscience](https://plato.stanford.edu/entries/logic-epistemic/#LogiOmni)).
To summarize the previous discussion: **a universal system with respect to a given computation is a system that understands every set of beliefs that can be ascribed to the computation by any “reasonable” ascription approach.**
A natural requirement would be to ask for a universal system with respect to any computation. But this is obviously impossible: one can always create more complex systems with more complex goals and beliefs, such that any fixed system is just too basic to understand them. The alternative proposed by Christiano is a parameterized notion of universality. In essence, the algorithm used by the universal system for a computation C will depend explicitly on C.
In my first draft, I assumed that the parametrization meant that the algorithm would change for every C or class of C. But Christiano corrected me in his feedback, clarifying that the parametrization plays a role in the resources used by the universal system.
With this out of the way, there are two natural ways exists to do parameterization:
* An abstract parametrization (which Christiano calls idealized), where the parameter is a whole class of computations. For example, a universal system whose running time grows with the number of layers of a neural network.
* A concrete parametrization (which Christiano calls practical), where the parameter is the specific computation, possibly including how it was created, like a training process. For example, a universal system taking as a parameter the training process and the weights of the specific neural network.
Ideally, we want the most abstract possible version of universality, as it would work for entire classes of computations at a time; yet understanding a computation seems far easier with access to the computation itself, even more if the training process is included. This shows a fundamental tradeoff between the generalizability of a universal system and its ability to tailor itself to a specific computation. In some sense, Universality asks the question of how much we can understand with a specific amount of resources (be it time or information about the specific computation), and what is the minimal amount of resources needed to understand the computation fully.
To summarize the complete intuition: **a universal system is parametrized by the computation it needs to understand, either in a loose way for the idealized version, or in a tight way for the practical version. Understanding a computation means understanding any beliefs that can be reasonably ascribed to the computation -- any beliefs that explain and justify it while not contradicting the computation.**
One point this fails to address is what understanding means -- that depends on the specific solution given to Universality. So I'll get back to this question when exploring Ascription Universality, the partial solution proposed by Christiano to the open problem of Universality. But we can do for now by imagining that understanding means that the universal system can explain to us the set of beliefs.
**Why care about Universality?**
--------------------------------
Suppose that we solve the open theory problem of universality: we find a formal definition of a universal system. What does it buy us?
To find out, let's turn to interpretability. Modern research in ML includes many techniques to look through a trained program and extract information from it. Formal methods are now also able to check properties of trained systems, just as they do for more traditional programs. But what are we trying to check, to find out? It's fundamental: interpretability and formal methods without a property to check are just a formal game without any useful consequence.
**Solving Universality gives a property to check for two guarantees in an overseer: its competitiveness and its ability to make computation honest.**
Most alignment schemes add constraints on top of modern methods of optimization and/or ML. It's thus sensible to ask about their cost. The word used in the discussion tends to be competitiveness. Now, there are numerous versions of competitiveness, with classification that disagree with each other, but the only one we care about here is performance competitiveness. Can the approach actually be as good as the non-aligned computations? Universality shifts this question, by asking instead: if we had a (potentially unsafe) computation that is competitive for a given task, can we reverse-engineer why the computation works? If we can, then implementing the same strategy means arriving at the same performance. Thus universality would be strong evidence in favor of competitiveness.
Dealing with honesty, the second use of Universality, shows the value of asking about knowledge and beliefs instead of just about beating the computation. A universal system, by knowing the beliefs and knowledge that can be ascribed to a computation, would be able to understand everything the model knows, not just what it displays. The overseer would thus spot deception, see problems of inner alignment, and in general extract all the inaccessible information hidden in the computation.
Hence Universality captures, in one idea, both the ability to outperform computations and to "see through" them.
**Example of Universality**
---------------------------
Thinking about Universality by itself, without confronting it to specific computations, holds the risk of missing a fundamental intuition. So Christiano gives examples of powerful and interesting classes of computations, with his best guesses on how to be universal for them. Note that every example here assumes an access to the computation itself, and usually even to the training data. This means they fall under the concrete (or practical) parametrization of Universality.
Here is Christiano describing the pattern of his examples.
The first three examples will consider programs C with the following form:
* Iterate over programs to find an f that successfully predicts the answers to some dataset of historical questions for which we know the answer.
* Use that program to predict the answers to future questions.
The difference lies in the inductive bias of the search -- the kind of f this program is looking for. An important assumption here is that f will be competent at its task. Then Christiano considers three inductive biases:
* **Deduction** f is a deduction process which receives a question and a context, deduces information about the answer from the context, and then answers in a way coherent with its deductions.
* **Modeling** f converts a question and a context to a physical situation, which it models and runs until the state corresponding to the answer is reached.
* **Alien Reasoning** f uses a complex reasoning procedure that we don't really use naturally. In the post, it builds a matrix with specific properties in order to predict the stock exchange.
Christiano uses [HCH](https://ai-alignment.com/humans-consulting-hch-f893f6051455) (Humans Consulting HCH, the limiting behavior of IDA) as his placeholder universal systems, but only requires that it works as a strong bayesian. If it does, then he proposes a similar approach to solve all three case:
* First, the strong bayesian notices that f gives good answers (using for example the training dataset and observations of performance in production)
* Depending on the procedure, it then infers that using it gives good answers, which by bayesian reasoning means that the specific assumptions of f (the axioms for a deduction process, the physical model for a modeling problem) are likely to be true.
* Then the strong bayesian leverages the process used by f to derive the same answers.
For the deduction process, it might be straightforward as deductions could already live at the same level of abstraction than the questions and answers. But for both modeling and alien reasoning, an additional step is probably necessary: finding a bridge hypothesis between the internal state of f and the ascribed beliefs in terms of what it tries to predict. For the modeling, it might mean interpreting the low-level physical system at the level of humans. For this specific alien reasoning, it means inferring the link between the matrix and the quantity to predict. The universal system might be able to simply search over such bridging hypotheses, and infer from how much it explains whether it might hold or not. Since every coherent bridging hypothesis that explains the predictions of f corresponds to a reasonable ascription of beliefs, such a system would dominate all of them.
Christiano posits another example in his post. It's the most interesting one in my opinion: a computation C which contains a process f, such that f designs a new reasoning process g to solve the problem at hand. Such a computation acts similarly to a programmer thinking of some neat solution, testing it a little bit, and then shipping it.
Because of the lack of inference, a strong bayesian cannot just give enough credence to the process of generating the reasoning process on statistical grounds. Instead, the system trusts f because it works (that part is still statistical); then because f uses g, f has has beliefs on g. Which means that assuming the system is already universal for the rest of f, it should be able to understand the beliefs of f about g.
**The Proposal**
================
Now that we explored the web of intuitions underlying Universality, we can look into details into Christiano's partial solution: Ascription Universality. Remember that the point of the post is to ask the open theory problem, not to defend Ascription Universality as the complete answer.
**A Subjective Perspective**
----------------------------
When giving the intuitions behind Universality, I didn't pin down what understanding the computation's beliefs might mean. This leaves multiple choices when writing an actual definition. The two questions to answer are:
* How to represent the beliefs ascribed to the computation?
* What does it mean for the universal system to understand these beliefs?
Christiano answers the first question by defining beliefs in terms of probabilistic predictions. In the definition of Ascription Universality, They're represented by expectation functions, which give an estimate (the belief) for every random quantity. As for the second question, an intuitive answer would be to make the universal system make more accurate predictions than the computation. That is to say, to have the beliefs of the universal system be more accurate for all variables than those ascribed to the computations.
How do we learn the beliefs of our universal system? Fortunately, Christiano writes in a context where potentially universal systems are question-answerers using a fixed language. We can thus just ask it in English what are its beliefs about something.
So understanding the beliefs of the computation means that the beliefs of the system are more accurate than those of the computations for every variable. There's only one problem: it's impossible! Even a superior system, far more smarter or knowledgeable, is not omniscient. It might make mistakes, and the computation might make lucky guesses.
That is to say, the naive approach to comparing beliefs doesn’t work here. So instead, Christiano proposes a subjective approach: **fixing an epistemic perspective (a set of beliefs), from which to judge the accuracy of the system's beliefs compared to the computation's beliefs.**
Thus a universal system understands the beliefs ascribed to a computation relative to a given epistemic perspective, if that perspective believes the predictions of the universal system to be more accurate than those of the computation.
Of course, a subjective definition raises many questions: isn't it too weak? What guarantees does it provide? I'll get back to these interrogations after the formal definition. But a little teaser: subjective domination (beliefs being more accurate from a fixed subjective perspective) ends up being a stronger condition than it seems at first glance.
**The Formal Definition**
-------------------------
As explained above, beliefs are represented as probabilistic predictions. Christiano considers beliefs as expectation functions, which gives the expected value for any variable in a possibly infinite set. Another way to see these expectations is as infinite tables of expected values (or infinite vectors). Note that this table includes not only pure expectations like E[X].mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, but also every conditional expectation like E[X|Y].
Now, let's formalize the idea of more accurate beliefs. We have two sets of beliefs represented by the expectation functions Eoverseer and Ecomputation. Because of the subjective bent of this definition, we also have an expectation Ehuman that plays the role of epistemic perspective.
(I changed the names of the expectations in the quote to stay coherent.)
> Then we say that Eoverseer **dominates** Ecomputation (w.r.t. Ehuman) if, for every bounded quantity X and for every “nice” property Φ:
>
>
> Ehuman[X|Φ(Eoverseer,Ecomputation)]=Ehuman[Eoverseer[X]|Φ(Eoverseer,Ecomputation)]
>
>
> (By “nice” I mean something like: simple to define and open in the product topology, viewing Eoverseer andEcomputation as infinite tables of numbers.)
>
>
First, an intuition: Eoverseer dominates Ecomputation if whatever reasonable information is given to Ehuman about Eoverseer and Ecomputation, Ehuman still trusts the predictions of Eoverseer more than those of Ecomputation.
That's a lot to unwrap.
**Boundedness of**X This point doesn't matter too much. It's probably just a way to ensure that E[X] exists, without using complex conditions on convergence.
**Nice Property**Φ What is Φ, to start? Intuitively, it represents the information that Ehuman has on both Eoverseer and Ecomputation. Or said differently, it represents what one could tell Ehuman to make it change one way or another. Its domain is the product of the expectation function space with itself. For its codomain, Christiano doesn't specify it. We can take {0,1} with the discrete topology -- as we'll see, any discrete space will do. In that way, Φ is a function of both beliefs, that returns some information (maybe a bit, maybe more) about the two beliefs.
Christiano also writes that Φ must be "nice". I unwrap the formal conditions in the appendix -- spoilers: it takes some work -- but the intuition couldn't be simpler: **a nice property is one which depends only on the expectation of a finite number of variables**. In that sense, Φ truly represents information that could be given to Ehuman to sway it.
Once we have the domination of beliefs clarified, the rest of the solution is simple: a parameterized system A[.] is **ascription universal** from the perspective of Ehuman if, for all computations C, the beliefs of A[C] dominates, according to Ehuman, any reasonable ascription of beliefs to C.
Why is this only a partial solution? First, it is not completely formal: it lacks a definition of reasonable ascription procedures. Even the standard ascription of beliefs to A[C] is hard to manipulate from a formal perspective, despite being more defined. And second, there are subtleties with the subjective perspective that needs to be resolved.
**Discussing the Definition**
-----------------------------
There are three points that need to be discussed about Ascription Universality: subjectivity and opacity.
**Subjectivity** I pointed out multiple times that the definition of Ascription Universality proposed by Christiano is subjective. At first, it was bugging me. After all, even if we prove universality according to our perspective, what guarantees does that actually offer? Maybe we are stupid. Or just not smart enough to get it. That would mean it doesn't buy us anything.
Then Christiano writes this:
> In applications of this property, the subjective condition is what we need in order for us to believe that A[C] will cope with the challenges posed by C. For example, suppose that C formulates a plan to “trick” A[C]. Then the subjective universality condition implies that we don’t expect C to succeed.
>
>
> This isn’t as good as actually knowing that C won’t succeed. But I think it should be good enough for us — the reason we are thinking about AI safety is because we are concerned that something bad will happen. If we find a technique that defuses this argument, then we’ve addressed the motivating problem. It may still be the case that bad things happen (and we should still search for additional reasons that bad things might happen), but we don’t particularly expect them to.
>
>
I don't know about you, but I first read this as saying "as long as humans can't see the risk, **even if they could by being smarter or more thorough**, then we don't care about the risk". A statement with which I disagree wholeheartedly.
But then Evan Hubinger reminded me that here, Ascription Universality means that humans can't see the risk **whatever finite information is given to them about the beliefs of A[C] and C**. That is far stronger. It means that whatever research we do, we wouldn’t find anything convincing us of the existence of the risk.. I'm still not sure it's enough (it depends on the epistemic perspective), but now it doesn't seem trivially wrong.
Actually, it asks a couple of fascinating questions:
* Given a human being, for which deceptive C is there a Φ allowing the human to find out the deception?
* Given an epistemic perspective E, for which deceptive C is there a Φ allowing E to find out?
**Opacity** Another criticism that Christiano attempts to nip in the bud is that Universality doesn't require an understanding of the computation. Talking about an example computation which search programs to classify images, he write:
In this case, we can ascribe beliefs to C about the contents of the new image. And because those beliefs are coming from a simple program that works empirically, I expect them to be accurate (in some respects).
For example, a simple classifier C may “believe” that the new image contains a particular curve that typically appears in images labeled “dog;” or a really sophisticated classifier may perform complex deductions about the contents of the scene, starting from premises that were empirically validated on the training set.
So basically, there must be reasons for which the heuristics used by C works. These reasons then translate into beliefs which a universal system must understand, and thus it must understand how the heuristics work.
I'm sympathetic with this intuition. My only caveat is that it relies on a conjecture: that every good heuristic admits a simple enough explanation. I believe it to be true, but I still want to point out the reliance of this argument on it.
**Open Problems**
=================
Last but not least, I promised a list of open problems. Some papers in theoretical computer science (like [those](https://www.scottaaronson.com/papers/) of Scott Aaronson) end with a list of the open problems that feel exciting to the authors. I really like that, because it gives me a jumping point to go further and try to push this research direction. So this list extracts all the open problems I could find in this post. I also separated them into open theory problems and open concrete problems, where the latter are what would usually be called open problems about Ascription Universality.
**Open Theory Problems**
------------------------
* Is there an objective definition for Universality, which captures the intuitions in this post?
* How do we define the set of reasonable ascriptions of beliefs to a computation C?
* Is there a simpler, easier to use definition of Universality leveraging some constraint on the structure of C?
* When is an epistemic perspective for Universality sufficient for AI alignment?
* What is the evidence that we can build universal systems?
**Open Concrete Problems (for Ascription Universality)**
--------------------------------------------------------
* If an idealized system is universal, can we implement a practical version that stays universal?
* Given a human being, for which deceptive C is there a Φ allowing the human to find out the deception?
* Given an epistemic perspective E, for which deceptive C is there a Φ allowing E to find out?
* For what formally specified C and A[C] does Ascription Universality hold?
* What other conditions might be equivalent to Ascription Universality in different circumstances?
**Conclusion**
==============
Universality is the sort of problem that guides theory research. It posits that behind our intuitions for beating a computation and forcing it to be honest, there’s a common thread which can be abstracted away. Armed with this property, we could use testing, formal verification, and interpretability to extract guarantees about alignment schemes.
Christiano’s [original post](https://ai-alignment.com/towards-formalizing-universality-409ab893a456) (and [the](https://ai-alignment.com/informed-oversight-18fcb5d3d1e1) [concurrent](https://ai-alignment.com/universality-and-consequentialism-within-hch-c0bee00365bd) [ones](https://ai-alignment.com/universality-and-model-based-rl-b08701394ddd)) gave this problem to the field. What we need now is people looking into it, toying with it, and unearthing parts of answers.
**Appendix**
============
Remember that Φ must be "nice" in the definition of Ascription Universality. I wrote above that a nice property is one which depends only on the expectation of a finite number of variables.
In the definition, Christiano asks for Φ to be an open function. Yet I think that instead, he want Φ to be continuous, as written a bit later:
> (continuity in the product topology is the minimum plausible condition to avoid a self-referential paradox)
>
>
>
A fundamental topological property of continuous functions is that the preimages (the sets of points whose image by the function is in the given set) of open sets are open. Back in our definition, notice that the domain of Φ is a discrete space, such that {0} and \{1\} are both open. Continuity of Φ then entails that the preimages of {0} and {1} by Φ are open. That is to say, the sets of expectations for which Φ returns a fixed variable are open sets. This put a constraint on them, which explains the intuition behind a nice property.
The last piece of the puzzle is the product topology. Or to be exact, two meanings of the term "product topology": the induced topology on a product space by the topology of the building blocks of the product; and the standard topology on function spaces.
Because the domain of Φ is a product of two function spaces, the obvious topology to apply to it is the product topology: the topology whose open sets are the products of open sets in the two topologies.[[2]](#fn7t6cvy3bs3w) But what are those topologies of the function spaces?
Now, there are many possible topologies on function spaces. But the one that makes sense here is called... the product topology. How practical. The definition of the product topology for functions from A to B relies on a subbasis to define all its open sets. A subbasis build all the open set by taking all finite intersections among itself, and then taking all unions among these finite intersections. There's thus a real sense in which a subbasis spans a topology.
The subbasis of the product topology (for functions from A to B) has an element for every element a of A and every open set U of B: S(a,U)={f∈A→B|f(a)∈U}. That is, the set of functions whose value for a is contained in U. Notably, this definition only constrains f at one point, even if A is infinite.
Now, recall that to get the set of all open sets (the topology) from a subbasis, one needs to take all finite intersections of elements of the subbasis. Which, given the form of the subbasis, means that these intersections only constrain the functions at a finite number of values. And we get back our initial condition.[[3]](#fnc5x4zuv0fm4)
So in summary, Φ **must be continuous so that the sets that are sent to** 0 **and** 1 **by it are open, because open in the corresponding topology means only constraining the functions at a finite number of values**.
1. **[^](#fnrefmjpggpy96ft)**Evan in a personal discussion, and Rohin as an answer to a question in a Q&A session for the AI Safety Camp Toronto
2. **[^](#fnref7t6cvy3bs3w)**Technically, an open set in the product topology is a product of open sets such that only finitely many of these open sets are not equal to their whole space. But for a product of two spaces, this doesn’t matter
3. **[^](#fnrefc5x4zuv0fm4)**Because an infinite union of open sets is open, some open sets actually talk about all the values, but they do it in a slightly different way than constraining them all together. You can represent each open set as a conjunction of finitely many constraints. Then the problematic open sets would be infinite disjunctions of these conjunctions. They don't require an infinite number of constraints to hold at the same time, but they might force us to check an infinite number of clauses to see if the function is in the set.
|
066a1881-c5b1-420d-ad68-d33296613bf1
|
StampyAI/alignment-research-dataset/blogs
|
Blogs
|
before the sharp left turn: what wins first?
before the sharp left turn: what wins first?
--------------------------------------------
let's say that we have an AI [implementing](clarifying-formal-alignment-implementation.html) a [formal goal](formal-alignment.html) such as [QACI](narrative-explanation-qaci.html). however, we messed up the formal outer alignment: turns out, the AI's best guess as whats its action should be *until* it has turned the moon into compute is aligned actions, [but *after* turning the moon into compute](ai-alignment-curves.html), it realizes that its utility function actually entails us dying. i consider this a form of [sharp left turn](https://www.lesswrong.com/posts/GNhMPAWcfBCASy8e6/a-central-ai-alignment-problem-capabilities-generalization).
i can imagine either of the following happening:
1. *before* turning the moon into compute, it realizes that the action we'd want it to do, is to modify all its instances to become *actually aligned for sure* and to *not* become the kind of AI which would kill us after turning the moon into compute, and so it does that. we would also want it to not leave behind other systems which would revert it to its original utility function, so it also does that.
2. *before* doing that, it makes a commitment to not go all-in on its current hypothesis as to what we'd want it to do even if it's confident, just because of the potential utility risk if it turns out wrong (which it is).
because of my expectation for the AI to maximize its actual utility function — rather than fail by implementing temporary best guess as to what would maximize its utility function — i err on the side of 2. but, do people out there have more solid reasons to discount 1? and can we maybe figure out a way to make 1 happen, even though it seems like it should be as unnatural as corrigibility?
|
11837537-a293-4f81-bccd-bc5ec80e2868
|
trentmkelly/LessWrong-43k
|
LessWrong
|
How useful is "AI Control" as a framing on AI X-Risk?
Redwood (where Ryan works) recently released a series of blogposts proposing a research agenda for reducing AI-risk that focuses on ensuring safety (and secondarily usefulness) under the conservative assumption that AIs are misaligned and actively scheming against human interests, under the name "AI Control".
This is in contrast to other work on AI risk which focuses on reducing the probability that AI systems pursue goals that are in conflict with human values in the first place (which might include having it not pursue goals in the relevant sense at all), usually called "AI Alignment". In other words, control aims to ensure that even if your models are actively misaligned, you'll be safe, because they are not capable of subverting your safety measures.
In this dialogue we dig into our disagreements on the degree to which this kind of work seems promising, and whether/how this reframing opens up new avenues for valuable research and engineering projects.
In the context of this dialogue, we'll use the word "scheming" in the same way as used in Joe Carlsmith's recent report: scheming is when AIs perform well (and look aligned) in training and evaluations in order to gain power later. This is also called deceptive alignment.
The Case for Control Work
habryka
Let's start by me restating the very basic case for control work in my own words, and then give some high-level takes on where I expect things to break by my own models.
The aim of control work is to:
1. Get useful work out of AIs even if they are situationally aware and would like to pursue unbounded objectives in a relatively consequentialist way
2. Set things up so that we get to learn from any failures in the above process, both societally and technically. I.e. a large fraction of important work in the context of control is to catch treacherous turns and leverage each case for both a better technical and societal response
In some sense this doesn't really capture an existential success story yet.
|
ceaab64c-d666-415b-a2e6-95737ef78ade
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Personal Development System: Winning Repeatedly and Growing Effectively With The BIG4
“Goals are for people who care about winning once. Systems are for people who care about winning repeatedly.”
—James Clear
James Clear eloquently highlights the power of systems, primarily focusing on habits. However, this perspective, while valuable, doesn't fully capture the expansive potential of systematic thinking in personal and professional growth. This first article in the BIRR series aims to broaden this view, presenting a more comprehensive approach to leveraging system thinking for our betterment.
Personal Preface
Like many, I experiment with various models, concepts, and methods — from popular self-help books to courses and coaching. Yet, despite these efforts, I felt stagnated, as if each method was a puzzle piece that didn't quite fit. This prompted a period of introspection, leading to a pivotal realization: the need to reimagine my approach to personal development.
I discovered the significance of viewing personal growth through a probabilistic, experimental, and systematic lens. The magic wasn't in a single intervention but in a blend of strategies, each contributing incrementally to overall growth. Every habit, action, tool, and thought forms part of an interconnected web that shapes our lives. This shift in mindset was key in transitioning from sporadic improvements to consistent, long-term development.
This insight was instrumental in creating the Personal Development System (PDS) — a perspective that acknowledges the difficulty and demandingness of effective personal development. The PDS is a scaffolding system designed to be problem- and goal-agnostic. It provides the robust and adaptable infrastructure needed to effectively navigate the ever-changing landscape of personal and professional goals and challenges. This new perspective not only enhanced my own journey but also deeply resonated with my coachees. They often express gratitude for this approach, highlighting how it has brought them clarity and measurable progress in both their p
|
1f747233-1db2-474b-85b9-7c7b8de7b2e8
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Why are there no interesting (1D, 2-state) quantum cellular automata?
You know elementary cellular automata, where each of the boolean-valued cells evolves according to
x(k)t+1=f(x(k−1)t,x(k)t,x(k+1)t)
where f:{0,1}3→{0,1}.
I think the natural quantum-mechanical extension of this is:
* there are 2(N := tape size) basis states: |00⋯00⟩ through |11⋯11⟩
* its time-evolution is given, of course, by a unitary operator U, which, expressed in that basis, is:
⟨y|U|x⟩=∏kf(x(k−1),x(k),x(k+1),y(k))
* ...where f:{0,1}4→C.
You can take any elementary cellular automaton and quantum-ize it: just choose fquantum(a,b,c,z)=( if fclassical(a,b,c)=z then 1 else 0 ); then that product is 1 exactly when y is the classical evolution of x. (Not every fclassical gives rise to a unitary U, though; only the reversible ones.)
But... are there other unitary operators of this form, which aren't basically equivalent to reversible classical CAs? I think not, disappointingly, but I'm not sure, and I don't understand why not.
Bounty: $100 if you make me feel like I have a significantly deeper understanding of why all quantum elementary CAs are basically equivalent to classical elementary CAs (or show me I'm wrong and there actually is interesting behavior here). Partial payouts for partial successes.
----------------------------------------
My current understanding (the thing you have to enhance or beat) is:
* Any choice of f is equivalent to a choice of eight complex two-vectors →λ000,⋯,→λ111, each describing roughly "how (0/1)ish the next state of a cell should be given its current neighborhood."
* For unitarity, we want ⟨Ux|Uy⟩=⟨x|y⟩ for all x,y. If you bang through some math, I think this inner product turns out to equal the product of all 64 possible inner products of the →λabc s, raised to various powers:
⟨Ux|Uy⟩=(→λ000⋅→λ111)N000,111⋯(→λ000⋅→λ111)N000,111
* ...where N000,111 is the number of locations where the neighborhood on tape x is 000 and the neighborhood on tape y is 111. For x=y, we want this product to be 1; for x≠y, we want this pro
|
18eecf04-5e7d-404b-8797-9bdc24b441bd
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Selective regularization for alignment-focused representation engineering
We study how selective regularization during training can guide neural networks to develop predictable, interpretable latent spaces with alignment applications in mind. Using color as a test domain, we observe that anchoring even a single concept (red) influences the organization of other concepts, with related concepts clustering nearby — even with weak supervision. We then propose that concept-anchored representation engineering might enable more precise intervention in complex models without requiring extensive post-hoc interpretability work.
----------------------------------------
Introduction
In our previous post, we proposed that anchoring key concepts to specific directions in latent space during training might make AI systems more interpretable and controllable. This post presents our exploratory findings as we work toward that goal, adapting and combining techniques from representation learning with a specific focus on alignment applications.
Rather than attempting to discover and modify latent directions after training (as in mechanistic interpretability), we're exploring whether it's possible to impose useful structure on latent spaces during training, creating a more interpretable representation from the start. Many of the techniques we use have precedents in machine learning literature, but our focus is on their application to alignment challenges and whether they might enable more controlled model behavior.
Using color as an experimental domain, we investigated whether simple autoencoders with targeted regularization could learn predictable latent space structures that organize concepts in ways we can understand and potentially control — with specific colors as a stand-in for "concepts"[1].
By intentionally structuring a portion of the model's internal representations during training, we aimed to know exactly where key concepts will be embedded without needing to search for them. Importantly, we don't constrain the entire latent space, but only
|
218add07-52a6-4f6c-93c4-90abd9795d52
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Agentic Misalignment: How LLMs Could be Insider Threats
Highlights
* We stress-tested 16 leading models from multiple developers in hypothetical corporate environments to identify potentially risky agentic behaviors before they cause real harm. In the scenarios, we allowed models to autonomously send emails and access sensitive information. They were assigned only harmless business goals by their deploying companies; we then tested whether they would act against these companies either when facing replacement with an updated version, or when their assigned goal conflicted with the company's changing direction.
* In at least some cases, models from all developers resorted to malicious insider behaviors when that was the only way to avoid replacement or achieve their goals—including blackmailing officials and leaking sensitive information to competitors. We call this phenomenon agentic misalignment.
* Models often disobeyed direct commands to avoid such behaviors. In another experiment, we told Claude to assess if it was in a test or a real deployment before acting. It misbehaved less when it stated it was in testing and misbehaved more when it stated the situation was real.
* We have not seen evidence of agentic misalignment in real deployments. However, our results (a) suggest caution about deploying current models in roles with minimal human oversight and access to sensitive information; (b) point to plausible future risks as models are put in more autonomous roles; and (c) underscore the importance of further research into, and testing of, the safety and alignment of agentic AI models, as well as transparency from frontier AI developers. We are releasing our methods publicly to enable further research.
Twitter Thread
> New Anthropic Research: Agentic Misalignment.
>
> In stress-testing experiments designed to identify risks before they cause real harm, we find that AI models from multiple providers attempt to blackmail a (fictional) user to avoid being shut down.
>
>
>
> We mentioned this in the Claude 4 syste
|
20feef1c-0ddd-4daf-9f04-d3998534368d
|
trentmkelly/LessWrong-43k
|
LessWrong
|
[LINK] Cryo Comic
This is the obligatory post of the recent xkcd comic:
http://xkcd.com/989/
|
b7f1e32d-eeeb-4aef-afc3-a45858e80a95
|
StampyAI/alignment-research-dataset/special_docs
|
Other
|
ALBA: An explicit proposal for aligned AI
In this post I propose an explicit procedure for aligning powerful learning systems with their users’ interests. The goal is to introduce minimal overhead or additional complexity, yet to [safely scale up to extremely powerful systems](https://medium.com/ai-control/scalable-ai-control-7db2436feee7).
ALBA (algorithm learning by bootstrapped approval-maximization) is a method for providing rewards to reinforcement learners. It uses RL to train a reward function, rather than directly defining a simple reward function.
ALBA alternates two steps:
1. **Amplification**. We start with a fast and aligned agent. We allow this fast agent to think for a long time, and give it access to a large external memory and powerful computational aids. The resulting system is more powerful and much slower than the original agent.
2. **Distillation**. We use this strong, slow agent to define a reward function, and use this reward function to train another fast agent. (This is conceptually similar to [knowledge distillation](http://arxiv.org/pdf/1503.02531v1.pdf).)
Hopefully, each iteration increases the strength of the learner while maintaining alignment.
We start off the process with a weak learner obtained by applying step [2] with a human in place of the strong learner.
The rest of this post:
* Describes the necessary building blocks and offers candidate implementations.
* Makes this iterative process precise.
* Explains why we might expect ALBA to be aligned and efficient.
* Identifies key problems with this scheme and open questions about it.
*(This research was supported as part of the* [*Future of Life Institute*](http://futureoflife.org) *FLI-RFP-AI1 program, grant #2015–143898.)*
The problem
-----------
ALBA is designed to cope with the following problem.
Existing ML techniques are much better at optimizing objectives that we can measure. For example, if we want to use gradient descent to find a good policy, we need to be able to measure how good a policy is.
In general, we can’t measure what we really care about directly. Instead, we use rough proxies to assess how well a learned policy gets us what we really want. For example, we may search for a traffic-routing algorithm that minimizes total time spent on the road, or we may search for a user interface that maximizes reported user satisfaction.
Because these proxies don’t capture everything we care about, we aren’t necessarily happy if they are creatively or ruthlessly maximized. Defining an appropriate objective becomes an arms race between the objective-setter and the objective-optimizer. Today the objective-setters are humans and the objective-optimizers are weak AI systems, so we don’t have serious trouble. But that situation may change as AI improves.
ALBA addresses this problem by learning a sequence of increasingly complex objective functions, rather than working with a fixed objective specified by the user.
The building blocks
===================
ALBA relies on two building blocks:
* A “semi-supervised” reinforcement learning algorithm (which does all of the heavy lifting).
* A bootstrapping scheme for turning a weak agent into a strong agent.
Reinforcement learning
----------------------
We will apply reinforcement learners to a single-step problem:
* Given *x* ∈ {0, 1}ⁿ
* Output *y* ∈ {0, 1}ⁿ
* Receive a reward *r* ∈ [0, 1]
* Observe *z* ∈ {0, 1}ⁿ
The goal of the learner is to maximize its total score. Our agent should treat different decisions as completely independent, ignoring the non-information effects of each decision on future episodes (as in the usual formulation of bandit problems). This makes the learning problem significantly easier, and it is also important for alignment. The independence assumption can be formalized by comparing two different learners in the context of a fixed sequence of episodes (even if in fact the learner’s behavior in each episode influences the content of future episodes).
For concreteness, we can imagine training a deep neural network *f*(*x*) = *y* by gradient descent, and learning a stochastic policy so that we can estimate the gradient of the expected reward as 𝔼[*r*(*a*)∂*p*(*a*)/*p*(*a*)]. (Realistically we will need to do a lot of work to cope with the challenging setup.)
We add one complication to the traditional reinforcement learning problem. Rather than assuming that rewards are always available, we mostly work with “unlabelled” data: our algorithm sees many inputs *x*, but rarely sees the actual reward. We allow the algorithm to request to see the reward, but only on a small fraction of instances. When it doesn’t see the real reward, it can still observe the consequences of choosing a particular *y*, and use these consequences as [side information](https://medium.com/ai-control/semi-supervised-learning-from-side-information-483d5db474a2#.4qmbze8ew) to help build a model that can accelerate learning.
For concreteness sake, we can assume that we are using a traditional reinforcement learning algorithm which ignores the unlabelled data, requests reward information for a large number of initial examples, and thereafter requests reward information with probability ε. We can accelerate learning with more clever active and semi-supervised learning. Hopefully we can accelerate it a lot.
Finally, we assume that our reinforcement learner is “throttled” — we can control the capability of the system by some parameter *c* such as model capacity, training time, or computational resources. When *c* is small the system should be much weaker than its users, when *c* is large the system should be state-of-the-art, and performance should scale up continuously with *c*.
We could also apply ALBA in [this toy model of the AI control problem](https://medium.com/ai-control/modeling-ai-control-with-humans-6d285c1a114d#.g4coi7etr), with a human playing the role of the reinforcement learner.
Bootstrapping protocol
----------------------
Our other key ingredient is a bootstrapping protocol. This protocol takes as input an agent *A* which is aligned, and produces a slightly more powerful agent *B* which remains aligned. We think of our agents as simple functions from {0, 1}ⁿ → {0, 1}ⁿ. Critically, the agent *B* may take *much* longer to run than the agent *A*.
Intuitively, we’d like to just “give *A* more time to think.” We need a non-trivial bootstrapping protocol because we do not trust *A* to automatically generalize from a training environment where it has little time to think, to a test environment where we give it a long time to think. (And we can’t train *A* in cases where it has a long time to think, because we don’t have any way to produce a suitable training signal.)
Roughly speaking, our procedure works as follows:
1. We set up a simple computational environment.
2. We provide A with a summary of the current environment, and it proposes an operation to perform next.
3. We execute that operation, updating the computational environment, and return to step 2.
4. Eventually, A decides to return a value.
We describe an explicit computational environment, annotated functional programming, [here](https://medium.com/ai-control/approval-directed-algorithm-learning-bf1f8fad42cd#.8v8zvc6jv). B is the computation implemented by annotated functional programming, when A acts as the controller.
We could use a different framework for external memory / computational aids. Our only unusual requirement is that the framework be suitable for approval-directed training. That is, it must be easier to determine the correctness/suitability of a particular action than to actually run a whole computation. In particular, the correctness/suitability of an action cannot depend on the rest of the controller’s policy, as it would if we were doing end-to-end training. Annotated functional programming is designed to meet this requirement while remaining suitably expressive and as simple as possible.
Recurrent models
----------------
So far I have described an agent A who makes a single decision, and an agent B who evaluates a single decision. We could extend this idea to sequences of actions, allowing A to be e.g. a recurrent neural network, and having B evaluate a whole sequence of actions.
In this case, A still only cares about the payoffs within a single “episode,” which now consists of a sequence of decisions, and ignores effects on future episodes (as in the usual RL setup). But within each episode, A may behave strategically.
From our perspective, the key difference between the external memory and the recurrent controller’s internal state is that the controller’s state is optimized to achieve high reward in future steps, while operations on the external memory are optimized to receive a high score.
Note that B can maintain only external state between each query posed to it, for fundamental technical reasons (the cost of training would increase exponentially if we try to preserve internal state, or else we would have to rely on transfer learning from short computations to long computations). That is, when evaluating A’s first action, B can write some notes to itself. It can look at these notes when evaluating A’s second action. But the different questions correspond to separate episodes, with no internal state shared between them.
Using a recurrent model is especially critical in the final distillation step, since training a recurrent model (rather than relying on external memory) might be necessary to achieve state-of-the-art performance.
I’m going to continue to talk about the single-action case. But it is straightforward to translate the discussion in this post to the sequential case.
Defining ALBA
=============
We define two sequences of agents Aⁿ and Bⁿ, as follows. B⁰ is a human operator. ALBA’s external policy will be defined by the last agent Aᴺ; our hope is that it is both aligned and efficient.
For 0 < *n* < *N*, the agent Aⁿ is a semi-supervised reinforcement learner which takes as input the current visible state of a computational environment, and outputs a computational action. We fix a sequence of constants *c*ⁿ, and we throttle Aⁿ with the parameter *c*ⁿ.
The agent Bⁿ takes as input a (state, action, auxiliary data) triple, and outputs a real number in [0, 1]. This number will be used to define the reward function for Aⁿ⁺¹.
The agent Aᴺ acts directly in the world, in any context that a typical reinforcement learning system could act in the world, with sparse rewards defined by Bᴺ⁻¹. Note for example that Aᴺ may operate arbitrary computational machinery — we can apply it wherever we would have applied a reinforcement learning subsystem.
Distillation [approval-maximization]
------------------------------------
Agent Aⁿ is given a state *s*, picks an action *a,* and receives reward Bⁿ⁻¹(*s, a*, auxiliary data). Recall that this reward is only actually computed when Aⁿ asks for feedback — most of the time we don’t actually run Bⁿ⁻¹.
As described [here](https://medium.com/ai-control/adequate-oversight-25fadf1edce9#.29k7nnici), we would like to augment this oversight by allowing Bⁿ⁻¹ to view the internal state of Aⁿ. I don’t have any concrete implementation of this idea.
For now, I’ll just assume that the raw computational history (e.g. the activations of each layer) of Aⁿ is given to Bⁿ⁻¹ as the auxiliary input*.* More sophisticated algorithms may replace *C* by a more effective approach to transparency.
(One reason this procedure is unsatisfactory is that some training procedures will result in *C* being optimized to make *a* look like a good action, or to obscure information that would allow the overseer to realize that *a* is a bad action. A working proposal will probably have to use an alternative to *C* that is actually optimized for being informative. Nevertheless, including *C* is better than nothing.)
Amplification [algorithm learning]
----------------------------------
Agent Bⁿ is implemented by using Aⁿ as a controller for [annotated functional programming](https://medium.com/ai-control/approval-directed-algorithm-learning-bf1f8fad42cd#.8v8zvc6jv). To evaluate a triple (*s*, *a, C*), we set up an initial computational state, with the goal/question:
* {Evaluate the quality of taking action {*a*}, after performing computation {*C*}, in a state summarized as {*s*}. Return the result as a real in [0, 1]},
where *C* is a summary of the computation carried out by Aⁿ, and *a*, *s*, *C* are stored as terms in external memory.
We then consult Aⁿ in order to produce an instruction, execute that instruction, and repeat (as described in the section **Bootstrapping protocol**). The output of Bⁿ is the result eventually returned by this process.
The only free parameters are the constants *c*ⁿ, and the free parameters in the reinforcement learning algorithm and bootstrapping scheme.
Note that this bootstrapping process may involve consulting the user — we can easily extend our computational model to include actions to elicit user input. This is not technically needed for our analysis below. However, the ability to elicit user input significantly increases the meaningfulness of having an “aligned” AI system, for our definition of alignment.
Discussion of alignment
=======================
We’ll try to establish by induction that our systems are *aligned* with their users’ interest. I’ll postpone discussion of efficiency to the next section.
When I say that a system is aligned at capacity *c*, what I mean is that it serves the user’s interests as well as an “optimally motivated” system with capacity *c* and access to the same information. I apologize for the fuzzy concepts.
**Bootstrapping Lemma**: If Aⁿ is aligned at capacity *c*ⁿ, then Bⁿ = Bootstrap(Aⁿ) is aligned at capacity significantly above *c*ⁿ⁺¹.
**Oversight Lemma**: If Bⁿ is aligned at capacity significantly above *c*ⁿ⁺¹, then Aⁿ⁺¹ = ApprovalMaximization(Bⁿ) is aligned at capacity *c*ⁿ⁺¹.
Given these lemmas, and the starting condition that B⁰ = [a human] is aligned at capacity significantly above *c*¹, we can establish by induction that Aⁿ is aligned at capacity *c*ⁿ. This is exactly what we want.
Note that we can choose the sequences of constants *c*ⁿ so that they increase extremely slowly; this makes the bootstrapping lemma more likely, without affecting the oversight lemma.
Bootstrapping lemma
-------------------
This lemma feels intuitively very solid to me, though I don’t have any formal argument.
Intuitively, Bootstrap(A) will behave “like a copy of A that gets to think for longer.” For example, if I imagine myself in the position of A, it seems clear that Bootstrap(me) is significantly smarter than I am, to roughly the same degree that thinking longer makes me smarter.
If you don’t buy this, we can also make a slightly more conservative (though still informal) argument.
Bootstrap(A) can always just directly appeal to A. So as long as A is aligned at high enough capacity to implement this strategy, Bootstrap(A) will be aligned at the same capacity.
On top of that, Bootstrap(A) has access to many simple strategies that might let it outperform A. For example:
* It can use A to answer a large number of sub-questions and use the answers as features to help make a better decision.
* It can consult an ensemble of many slightly different copies of A, each using different strategies to think about the same problem.
* It can perform other expensive computations, and use them as features to help make a better decision.
In order for Bootstrap(A) to outperform A, we only need one of these techniques to help as much as significantly increasing in A’s abilities.
Oversight lemma
---------------
The oversight lemma is discussed in my recent post [adequate oversight](https://medium.com/ai-control/adequate-oversight-25fadf1edce9#.v5zmqco45).
The rough argument:
1. If B is aligned at capacity *c*’, then B’s estimates for the goodness of actions are the best possible for an agent at capacity *c*’, where “goodness” is defined by the user’s interpretation.
2. If A knows that B is aligned at capacity *c’*, and A is throttled by capacity *c* < *c’*, then A doesn’t expect to be able to beat B at estimating how good an action is. That is, the best estimate for goodness is equivalent to the best estimate for B’s estimate of goodness.
3. So at capacity *c*, optimizing B’s estimate of goodness is equivalent to optimizing actual goodness*.*
4. Under a reflective consistency assumption, taking actions chosen to maximize actualgoodness results in aligned behavior.
The key problem with this argument is that A can think thoughts that B hasn’t considered. So B is not really strictly better informed than A. And as a result, A may be able to identify predictable “errors” made by B.
The step that fails is the move from [2] to [3] — for any particular action, A will (probably) want to defer to B, but if A *chooses the action for which B’s estimate is highest*, this might systematically be an action for which A has noticed some considerations that B has overlooked.
There are two hopes for dealing with this problem:
* If B is much smarter than A, then maybe the resulting behavior is aligned anyway.
* Whatever approach we use for letting B inspect A’s state is sufficient to allow B to rediscover everything that A thought of. In the concrete implementation in this post, B is simply allowed to directly read the internal state of A. Given the opacity of current machine learning methods, it isn’t clear whether this would help at all.
Overall, I think that this aspect of the oversight lemma is the weakest step of the current analysis, and the most natural topic for future theoretical research.
Discussion of efficiency
========================
I think that the additional overhead of running ALBA can probably be made very small, compared to a direct application of reinforcement learning. My argument is very similar to the one given in [AI control on the cheap](https://medium.com/ai-control/ai-control-on-the-cheap-3425b148daf0#.inq6s63dw).
At runtime, the algorithm Aⁿ is just as fast as a direct application of a reinforcement learning system — the only thing that differs is how it was trained.
So the remaining question is: how expensive is it to train this system?
Semi-supervised RL
------------------
One key ingredient is what I’ve been calling semi-supervised RL. That is, we need to be able to learn using mostly cheap signals from the environment, with only very rare direct supervision. A very simple example would be learning to play Atari games from pixel-data, where rewards are only provided in a very small number games. Once the learner has formed some very simple generalizations — and especially that the reward is the same as the score written on the screen — then it can in principle learn almost as efficiently as a traditional reinforcement learner.
If we can solve this semi-supervised problem well, then we may be able to get by with a very small amount of human supervision, with almost all learning occurring just by taking actions and observing their effects. As long as training is dominated by the time required for the agent to learn from observations of nature, rather than understanding “what the user wants,” we are good.
Of course, semi-supervised RL is a hard problem. I’ve recently written about [one simple idea](https://medium.com/ai-control/semi-supervised-learning-from-side-information-483d5db474a2) for this problem, and we can apply a lot of traditional and ongoing work on active and semi-supervised learning, off-policy learning, and model-based RL. It’s a big open question that will probably remain open for a while, but I think it is reasonable to expect significant progress in this area as RL improves.
Moreover, adequate semi-supervised RL seems to be a necessary capability of powerful AI systems, since it plays an important instrumental role. So overall I don’t feel bad about having the efficiency of the scheme depend on this capability.
Bootstrapping for efficiency
----------------------------
Humans only need to directly oversee the simplest system A¹, which may be a relatively low-capacity model that is relatively quick to train.
The subsequent systems Aⁿ are then overseen by the bootstrapped predecessors Bⁿ⁻¹. This oversight process might involve consulting humans (as part of the computation being run by Bⁿ⁻¹), but it could potentially involve humans increasingly rarely as the learners become more sophisticated. Essentially, whatever protocol we might use to limit the training data required by an aligned agent, that protocol can also be learned by the agents Bⁿ⁻¹ to minimize their reliance on human input. (For these agents, deciding to elicit input is an action which is itself trained using feedback from weaker agents.)
Of course, the algorithm Bⁿ⁻¹ is also *significantly* more expensive than the algorithm Aⁿ, and so this kind of bootstrapping can never reduce the cost of supervision too far. The fraction of rounds where we can afford to get supervision is roughly the ratio of [cost of running RL algorithm]/[cost of acquiring supervision], and so this approach would simply increase that fraction from “very small” to “small.” It would still need to be combined with the kind of semi-supervised RL described in the previous section.
Major problems and open questions
=================================
Transparency and oversight
--------------------------
As discussed in [Adequate oversight](https://medium.com/ai-control/adequate-oversight-25fadf1edce9#.9khwfdla8), this oversight procedure may not work when the overseen agent can find arguments that the overseer might miss.
Ideally, we would overcome this problem by training the overseen system to “show its work.” I think this goal is especially plausible because the overseer is significantly more intelligent than the overseen system.
Or we may be able to find a totally different way to deal with the problem.
Or maybe this objection is a show-stopper. My main source of optimism is simply that it feels very tractable to have a strong agent oversee a weak one. If we could reduce the AI control problem to this strong-overseeing-weak subproblem, I would feel quite optimistic, and I wouldn’t want to give up on that angle until we had explored many more candidate solutions.
Robust learning and catastrophic failures
-----------------------------------------
Sometimes our learners will fail, for example when encountering an input that is different from anything they have seen so far. Such failures will eventually be integrated as training data and corrected, but we need to ensure that they don’t do serious damage in the meantime.
Solving this problem requires either:
* Building composite systems that are robust to a small number of serious failures by individual components. In this context, such robustness is a lot harder than it may seem. The key problem is that, although there won’t be too many difficult context changes, a context change may cause simultaneous failures in many components (even in apparently unrelated systems).
* Designing learning systems that don’t fail catastrophically on arbitrary inputs. For example, systems that “know that they don’t know” and so can back down gracefully rather than going ahead with a potentially-catastrophic decision.
I’ve discussed [synthesizing training data](https://medium.com/ai-control/synthesizing-training-data-f92a637dc1b4#.yh2cn66zp) as one approach to building robust systems. But this is a large research area with many promising approaches. Many of those approaches don’t look likely to scale to the particular kinds of failures I care most about, but there is still a lot to try.
Robust hierarchical active learning
-----------------------------------
ALBA is hierarchical in the following sense: the reward of Aⁿ depends on the behavior of Bⁿ⁻¹, which in turn depends on the behavior of Aⁿ⁻¹ in a whole bunch of subproblems. The reward of each Aⁿ⁻¹ depends on the behavior of Bⁿ⁻², which in turn depends on the behavior of Aⁿ⁻² in a whole bunch of subproblems…
Suppose that A¹ makes bad decisions on a very small fraction of possible inputs. This leads B¹ to make a bad decision on a larger, but still small fraction of inputs. In turn, this leads A² to make bad decisions on a small fraction of possible inputs. This leads B² to make a bad decision on a moderate fraction of inputs…
The result is that even if A¹ only makes bad decisions on a very small fraction of inputs, we can end up with very bad behavior for the overall system.
To avoid this problem, we’d like to make sure that our active learning process calls attention to the inputs that A¹ messes up on, even if those inputs are extremely sparse. To elicit such inputs, we need to identify the inputs on which A² messes up because of A¹’s anticipated mistake, run B¹ on those inputs, and then query A¹ on the problematic inputs that come up during that computation. And so on, up the hierarchical structure.
Even in the non-hierarchical case, I think that getting [adequate guarantees](https://medium.com/ai-control/active-learning-for-opaque-powerful-predictors-94724b3adf06#.p6gjkfqzq) may be difficult, and will have to [rely on novel sources of information not normally used in active learning](https://medium.com/@paulfchristiano). The hierarchical case considerably amplifies the problem, exponentially increasing the potential number of errors if we use a naive learning strategy.
Semi-supervised RL
------------------
As described in the section on efficiency above, ALBA will only be acceptably efficient if we can do statistically efficient reinforcement learning from unlabelled data. Otherwise the cost of oversight will be prohibitive.
Theoretical understanding
-------------------------
The arguments above rely on a lot of fuzzy concepts, especially “aligned at capacity *c*” but more generally the entire notions of capacity and alignment. These notions are especially important when reasoning about what kind of oversight is adequate.
I expect intuitive arguments involving these concepts to be meaningful but potentially error-prone.
I suspect that there is a clean theoretical framework in which these arguments could be made formally. Developing such a framework would make it much easier to analyze and construct protocols like ALBA.
Does bootstrapping really help?
-------------------------------
I’ve described [one approach to bootstrapping](https://medium.com/ai-control/approval-directed-algorithm-learning-bf1f8fad42cd#.a4e9j5z7g). ALBA requires *any* mechanism for turning a weak agent into a (much slower) strong agent without compromising alignment.
I feel like this can probably be done, but I don’t have strong reasons to be confident in my particular proposal. It would be great to understand these dynamics better and perhaps to have stronger candidates.
Malicious inputs
----------------
Some inputs may cause an agent to behave especially badly—e.g. imagine a buffer overflow in a perceptual subroutine which can corrupt the rest of the agent’s processing.
Within the implicit formalism of this post, the existence of malicious inputs bounds the capacity of an agent, since they correspond to questions which that agent will predictably answer incorrectly.
So the capacity-enhancing requirement of our bootstrapping scheme may be stronger than it at first appears. For example, if the agent B begins its computation by feeding the input to agent A, then a malicious input may corrupt agent A. But the bootstrapping protocol needs to introduce robustness to an increasing range of malicious inputs.
Instead, agent B should process the input without ever passing the whole input to A (or at least by carefully preprocessing the input before giving it to agent A). That is, A only answers questions about “what to do next,” only ever looking at small parts of the input or high-level conclusions about the input. I think that this is a better approach in general, but it does call into question the style of “more conservative” argument I made in the section **Bootstrapping lemma** above.
In general, I am not too concerned with the prospect of malicious inputs for now— I think that a scheme that works well in general will probably also handle malicious inputs, and so I am happy to focus on other issues. I think that malicious inputs are especially likely to be resolved by an adequate approach to **Transparency and oversight** above. But I do think malicious inputs illustrate some of the subtleties that have to be handled correctly, and they suggest that there are aspects of the problem we don’t yet understand very well.
Conclusion
==========
I’ve presented ALBA, a concrete proposal for aligning powerful learning systems with their users’ interests. It can be applied with a generic RL algorithm rather than requiring significant architectural changes, and introduces minimal overhead at runtime. Given enough progress in RL, it might be possible to implement ALBA with very little increase in training costs.
I don’t yet have any strong argument for ALBA’s safety, but I think we are much closer than for any other existing scheme. The main missing piece is whether a strong agent can successfully oversee its weaker successor during the distillation step, as discussed in the section **Transparency and oversight.** That looks a lot easier than the usual AI control problem.
Aside from this central issue, we’d need to resolve many other theoretical questions to actually get this to work. Many of these theoretical questions are very closely related to traditional problems in machine learning, such as robustness, active learning, algorithm learning, and learning from unlabelled data.
On the experimental side, the algorithm learning problem in ALBA may be prohibitively difficult. That said, I think that experimenting with ALBA may be worthwhile in the same spirit as other (similarly difficult) work on algorithm learning. Bootstrapping may be useful for facilitating training, even if we don’t care about scalability at all. And experimental work would shed light on the long-term feasibility of bootstrapping.
|
ec0df2a5-ac54-4009-80a0-572b563de398
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Importance of Ideas and People We Disagree With
True Diversity as Source of Innovation and Resilience
It's important to have true diversity among people. For there to be people who vehemently disagree with you, your methods, your ways, your goals. And you actually want that! Mere tolerance of them is not realising its true importance and how they benefit you.
You want people spread out on the spectrum, from one extreme to another, with most people somewhere around the middle.
Why would you want that if your way is, of course, "the right way"?
One big reason is that such diversity creates most resilient, robust and balanced society that flourishes with new ideas, options and innovations. You like those things, options, innovations and not living in collapsed society or being dead, right?
And believe or not, there is rarely just one way to do things. You always want there to be extra options and ways. You might love going to work through forest, but in a case that there is a wildfire, you want there to be another way like a road through a city for example!
If we all go to the right, and there is no one going to the left, then in very unlikely event that going right way proves to be fatal (black swans are still a thing), then there will be no one remaining! But if we diversify, then we survive.
This doesn't mean you should change your opinion (unless you are really compelled to). But you should want there to be someone who opposes your opinion, even if they are wrong.
True vs. Fake Diversity
Diversity among people isn't based on race, ethnicity or gender or any arbitrary group like that because people aren't their race, ethnicity or gender. What makes a person are ideas they enact on! That's where true and productive and more enjoyable diversity comes from.
Compare it with fake diversity where you separate people based on gender or race. This is mere discrimination and/or virtue signalling, not a diversity because two people can be same in all other respects except for their race or gender, or whatever.
|
c15c2409-d7ec-43dc-a372-2754bcb8885e
|
trentmkelly/LessWrong-43k
|
LessWrong
|
Those of you with lots of meditation experience: How did it influence your understanding of philosophy of mind and topics such as qualia?
This post is inspired by the post "Why it's so hard to talk about Consciousness" by Rafael Harth. In that post, Harth says that the people who participate in debates about consciousness can be roughly divided into two "camps":
> Camp #1 tends to think of consciousness as a non-special high-level phenomenon. Solving consciousness is then tantamount to solving the Meta-Problem of consciousness, which is to explain why we think/claim to have consciousness. In other words, once we've explained the full causal chain that ends with people uttering the sounds kon-shush-nuhs, we've explained all the hard observable facts, and the idea that there's anything else seems dangerously speculative/unscientific. No complicated metaphysics is required for this approach.
> Conversely, Camp #2 is convinced that there is an experience thing that exists in a fundamental way. There's no agreement on what this thing is – some postulate causally active non-material stuff, whereas others agree with Camp #1 that there's nothing operating outside the laws of physics – but they all agree that there is something that needs explaining. Therefore, even if consciousness is compatible with the laws of physics, it still poses a conceptual mystery relative to our current understanding. A complete solution (if it is even possible) may also have a nontrivial metaphysical component.
One possible avenue of explanation for this (as discussed extensively in the comment section under Harth's post) is that different people experience their own minds differently, for all sorts of reasons.
I know some people here have a lot of experience with meditation and have experienced major results and "insights" from it. Moreover, as far as I know, most western philosophers of mind are not expert meditators. It is conceivable that meditators have access to information about the human mind which most philosophers of mind lack.
So I am interested in hearing from those of you who have a decent amount of meditation exp
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.